



Оглавление
- Предисловие
- Пробный этап
- Выявленные сложности пробного этапа
- Замедление загрузки
- Расследование причины взаимоблокировок
- Настройка logcfg.xml
- Сбор логов
- Поиск файла лога ТЖ по ошибке из ЖР
- Последовательность действий в Notepad++
- Анализ события TDEADLOCK: Поиск Участников
- Анализ схемы взаимоблокировки
- Анализ контекстов выполнения кода
- Алгоритм потока загрузки данных в 1С:Документооборот 3
- Причина замедления/остановки загрузки объектов
- Медленная обработка таблицы данных
- Исправления и оптимизация
- Результаты оптимизации
- Проблема продолжения в ДО3 запущенных процессов в ДО2
- Заключение
Предисловие
Уважаемые читатели, мы продолжаем историю про миграцию данных из «1С:Документооборот» редакции 2.1 в 3.0.
Перед прочтением рекомендуем ознакомиться с первой частью статьи.
В ней мы коснулись теоретических основ блока миграции и разобрали некоторые его особенности. А также привели ряд «болевых точек» на которые стоит обратить внимание перед стартом этого процесса.
Теперь же мы сфокусируемся на анализе и способах устранения трудностей, с которыми мы сами столкнулись в процессе пробного этапа миграции.
Пробный этап
Под пробным этапом здесь следует понимать предварительное тестирование процесса. Хочется немного акцентировать внимание на этом моменте. Тестировать ведь можно по-разному — начиная от демо-базы с минимальными данными, заканчивая тестом на многолетней рабочей базе. В какой полноте это делать и на каких мощностях — это предстоит определить.
Наша цель состояла в общем из двух пунктов:
- Получить оценочное время миграции, чтобы корректно запланировать регламентные работы уже для реальной базы. А также понять узкие места блока миграции, если они есть, и по-возможности исправить.
- Проверить фактические результаты миграции, чтобы иметь возможность предотвратить ошибки.
В нашем случае, чтобы получить замеры и результаты максимально приближенные к реальным, тестовая миграция проводилась на полной копии продуктивной базы, и на абсолютно таких же мощностях, на которых работает продуктив.

Всегда ли возможен такой подход? Полагаем ряд целей тестирования можно закрыть и не воспроизводя ситуацию продуктива 1 в 1. Например, время миграции можно попробовать оценить экстраполяцией количества объектов, и/или разницы мощностей тестового и продуктивного контура.
Выявленные сложности пробного этапа
В конце прошлой статьи мы упомянули о ряде сложностей, выявленных при тестировании. Напомним о них:
- Существенное замедление скорости загрузки на стороне ДО3.
- Формирование огромного количества объектов «Рабочие группы для перехода».
- Отображение файлов в карточках документов при интеграции с ERP.
- Мигрированные, но не завершенные активные процессы на стороне ДО3.
И ещё ряд других.
Сегодня мы подробно расскажем о том, как мы поработали над оптимизацией процесса миграции в целом, а также о нюансах «переезда» бизнес-процессов в новую базу.
Предупреждение
Хотим заранее упредить возможные вопросы. Ряд материалов с реального проекта на момент написания статьи был не доступен, поэтому каждый этап — от воспроизведения самой проблемы до её детального анализа и выработки решения — был реализован и наглядно представлен на основе тестовой демо-базы, что в точности повторяет наш опыт и подходы, испытанные на реальном проекте. Итоговые данные сопоставимы с данными реальных проектов.
Замедление загрузки
Как мы обозначили выше, одной из целей пробной миграции было понять сколько времени займет процесс на продуктивной базе. Заказчиком была озвучена комфортная длительность миграции в 2 недели. И увы, первый запуск показал, что пробная миграция в этот срок не укладывается. Более того, за это время она дошла где-то до половины процесса загрузки на стороне ДО3. И как мы позже выяснили, на некотором этапе было отмечено резкое падение скорости загрузки.
Для полноценного понимания контекста этой проблемы и последующего анализа её причин, сначала рассмотрим методологию отслеживания прогресса миграции.
Средства мониторинга
После запуска пробной миграции, мы вели постоянный контроль за её ходом. В этом нам помогали следующие штатные средства:
- Основной инструмент — обработка «Миграция данных из предыдущей версии».
На первой вкладке в ней можно наблюдать индикацию прогресса загрузки в реальном времени:

На вкладке «Журнал» можно отслеживать события загрузки, в которых можно увидеть количество загруженных объектов и длительность их записи в секундах, давая представление о производительности:

Для подробного анализа событий и своевременного реагирования на проблемы также можно использовать Журнал регистрации. С его помощью можно просматривать все фактические операции по добавлению и изменению объектов миграции, а также оперативно выявлять и локализовать критические ошибки:

Наблюдаемая ситуация
Мы рассмотрели штатные средства мониторинга миграции. Теперь вернёмся к ключевой проблеме.
Примерно на уровне отметки «Загружено» 40-50% мы заподозрили неладное. Оно выражалось в следующем:
Прогресс — индикация «зависла» на одном значении на длительное время:

Журнал — заметили, что последнее принятое сообщение на вкладке «Журнал» датировалось почти сутками ранее, хотя обычно новые записи появлялись с частотой ~5 минут:
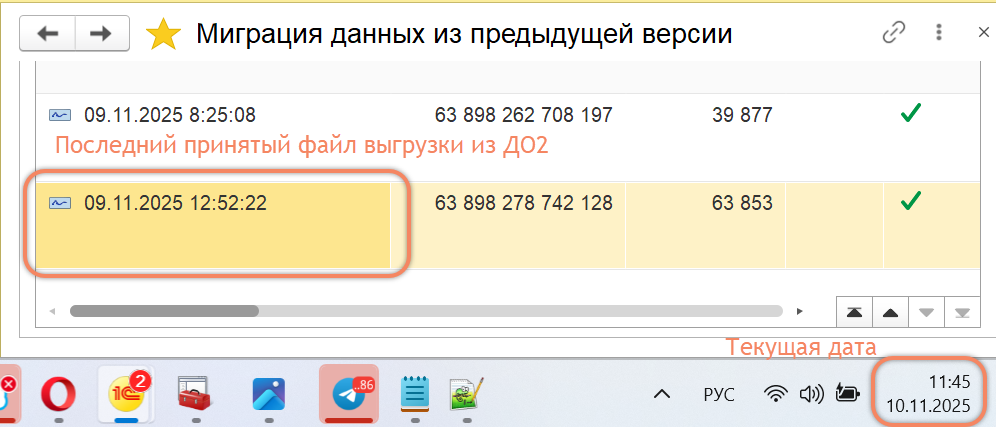
Записи в ЖР — также было обнаружено, что в журнале регистрации фиксировались только изменения регистров отметок времени. Это расходится с ожидаемым поведением, поскольку при нормальной загрузке миграцией должны присутствовать события добавления/изменения самих загружаемых объектов:

Потоки загрузки — и ещё одна аномалия, которую обнаружили — в списке фоновых заданий оставался активным лишь один поток регламентного задания «Миграция с предыдущей версии. Загрузка»:

При этом в нормальном состоянии как правило работает 5 потоков загрузки:

Первое что мы сделали в попытке понять причины — посмотрели в журнал регистрации на предмет ошибок. Там обнаружили множество событий с ошибками записи, относящихся к подсистеме «отметок времени». О ней мы подробно рассказывали в первой части.


Комментарий этих событий содержал текст: «Конфликт блокировок при выполнении транзакции: Неустранимый конфликт блокировок».
Это позволило сделать вывод о наличии управляемых взаимоблокировок. И мы начали с расследования этой проблемы.
Расследование причины взаимоблокировок
Для детального изучения конфликтов блокировок нам потребуется собрать данные технологического журнала по следующим событиям:
- TLOCK — фиксирует транзакционные блокировки в управляемом режиме, предоставляя информацию об объекте блокировки и контексте её установки.
- TDEADLOCK — позволяет выявить взаимоблокировки в управляемом режиме и определить конфликтующие соединения.
На всякий случай, включим в сбор ещё два события:
- TTIMEOUT — отслеживает превышения максимального времени ожидания транзакционной блокировки.
- EXCP — исключительные ситуации приложений системы «1С:Предприятие», которые штатно не обрабатываются и могут послужить причиной аварийного завершения серверного процесса или подсоединенного к нему клиентского процесса, для получения информации об исключениях.
Настройка logcfg.xml
По выбранным событиям создаем конфигурационный файл logcfg.xml с следующими настройками:
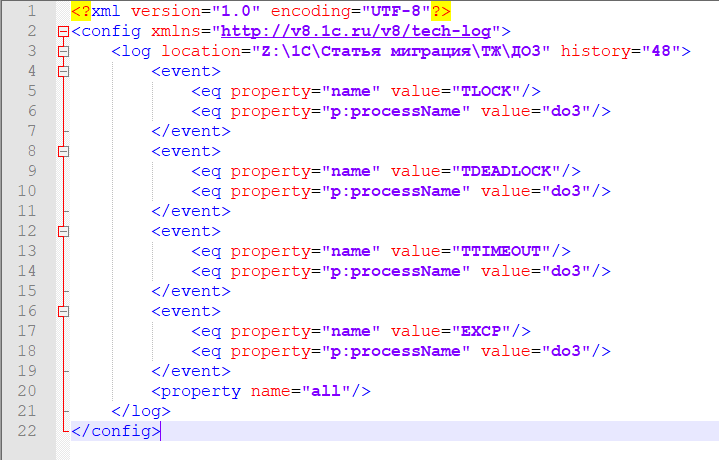
В полях:
- location — указываем путь сохранения логов;
- history — устанавливаем срок хранения в часах;
- p:processName — устанавливаем имя исследуемой базы ДО3;
- property name="all" — указываем сбор всех свойств событий.
Помещаем созданный файл в папку conf по пути установки платформы 1С:Предприятие, например, в нашем случае это был: «C:\Program Files\1cv8\conf\».
Сбор логов
В течение минуты после помещения «logcfg.xml» в папку «conf» начинается запись логов в указанной в настройке папке:

Логи с искомыми нами событиями собираются в папках процессов rphost:
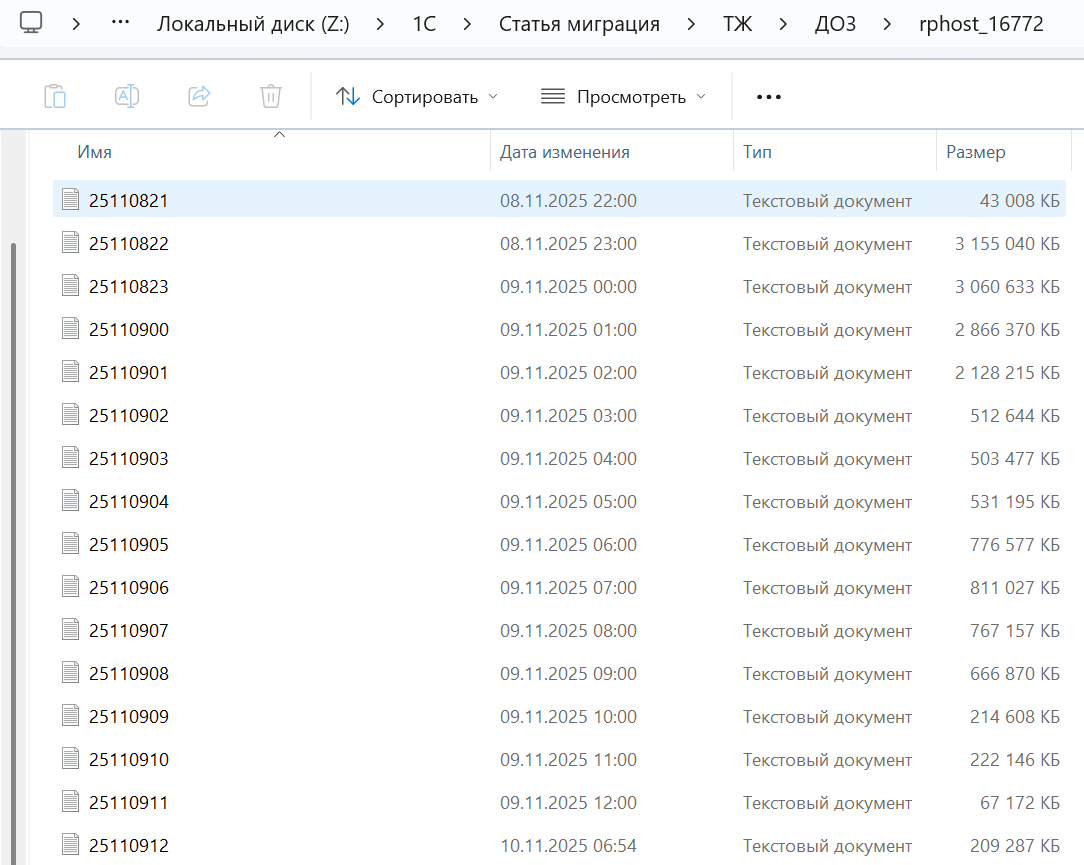
Номер папки «rphost», например, «16772» обозначает PID процесса ОС:
В наименовании файлов логов указываются дата и время в формате: «Год, Месяц, День, Час», например: 25110821 — где 25 (2025), 11 (Ноябрь), 08 (День), 21 (Час):

Примечание
Напоминаем, что при сборе логов технологического журнала нужно держать в голове, что файлы логов могут иметь внушительный размер. Соответственно на диске должно быть достаточно свободного места. Выбранный нами набор событий как правило не генерирует большой объем и мы спокойно ставим в logcfg период сбора history равный двум дням, но, к примеру, если бы мы собирали логи по запросным событиям DBMSSQL/DBPOSTGRS, имело бы смысл сократить период до 2-4 часов, иначе бы логи заняли всё доступное пространство:

Поиск файла лога ТЖ по ошибке из ЖР
Логи ТЖ собраны. Теперь их нужно проанализировать.
Как правило в таких случаях применяются инструменты bash, либо специализированные программные комплексы типа «1С‑Рарус: Мониторинг производительности».
В нашем случае для разнообразия воспользуемся программой Notepad++. В этом редакторе тоже можно искать текст с применением регулярных выражений. Ознакомиться с деталями можно по ссылке (npp-user-manual.org/docs/searching/) в разделе Regular Expression.
В качестве отправной точки возьмём запись об ошибке, зафиксированную в Журнале регистрации 09.11.2025 в 0:17:15, и попробуем найти связанное с ней событие взаимоблокировки:

Сначала определим ключевые параметры поиска:
- Тип события: TDEADLOCK (взаимоблокировка).
- Время события: 09.11.2025 0:17:15.
Это позволяет нам сформировать точную маску имени файла лога: 25110900.log (25-й год, 11-й месяц, 09-е число, первый час суток). - Номер сеанса: 5352.
Приготовим наше поисковое выражение. Оно будет выглядеть так:
Разберем выражение:
- ^17:15 — Обозначает начало строки с точным временем 17:15.
- .* — Поиск любых символов, пропускающий данные до следующего элемента в пределах одной строки.
- TDEADLOCK — Искомое имя события взаимоблокировки.
- SessionID=5352 — Точное совпадение с номером сеанса.
Последовательность действий в Notepad++
1. Открываем Notepad++ и переходим в меню Поиск -> Поиск в файлах (или используем Ctrl+Shift+F):

2. В открывшемся окне заполним поля следующим образом:
- Вставим в поле «Найти» подготовленное регулярное выражение.
- Укажем имя файла определенное ранее 25110900.log в поле «Фильтры».
- Укажем путь к головной папке выгрузки логов ТЖ в поле «Папка».
- В «Режим поиска» выберем Регулярное выражение.
- Установим флажок «Во всех подпапках».
- Нажмем кнопку «Найти все».

Внимание! Отключите флаг «. - новая строка», если он включен. Данная опция расширяет действие «.» (точки) на переносы строк, позволяя ей находить многострочные совпадения.
3. В случае обнаружения лог-файла размером более 2 ГБ появится диалоговое окно с запросом на его открытие. Подтвердим действие:
4. После завершения поиска в нижней части Notepad++ отобразится панель с результатами. Двойной клик по результату поиска откроет лог-файл, позиционируя нас на найденной строке. В нашем случае, был найден единственный файл с искомой строкой:

При внимательном рассмотрении видно — сразу после TDEADLOCK зафиксировано событие EXCP, демонстрирующее совпадение по:
- SessionID (5352);
- ConnectID (18265);
- Context (‘ОбщийМодуль.ОтметкиВремени.Модуль : 1311 : РазобратьОчередь(Истина); ОбщийМодуль.ОтметкиВремени.Модуль : 1606 : Набор.Записать();’).
Описание ошибки (Descr) «Конфликт блокировок при выполнении транзакции: Неустранимый конфликт блокировок» из Журнала Регистрации подтверждает, что мы успешно идентифицировали нужный файл и запись взаимоблокировки.
Анализ события TDEADLOCK: Поиск Участников
Перейдем к анализу, чтобы понять, какие конкретные операции привели к этому состоянию.
Для нас в событии TDADLOCK в первую очередь интересно свойство «DeadlockConnectionIntersections», оно однозначно показывает двух участников и их взаимные ожидания:
- Соединение с ID 18265 ожидало ресурс, который был заблокирован соединением ID 17300.
- Соединение с ID 17300 ожидало ресурс, который был заблокирован соединением ID 18265.

Теперь последовательно найдем и проанализируем обе пары блокировок, используя регулярные выражения.
Шаг 1. Сначала найдем блокировку по номеру соединения жертвы, соединения ожидания виновника и пространству, составим выражение:
Находим первое событие TLOCK жертвы после события взаимоблокировки:

Шаг 2. Дальше найдем TLOCK виновника по номеру соединения виновника и пространству:
Находим последнюю по времени блокировку виновника перед событием TDEADLOCK:

Продолжим поиск второй пары блокировок.
Шаг 3. Найдем TLOCK виновника по номеру соединения виновника, соединения ожидания жертвы и пространству:
Fld9307=127:904914133359ce6811f067c48bc9258a'.*WaitConnections=18265
Находим запись:
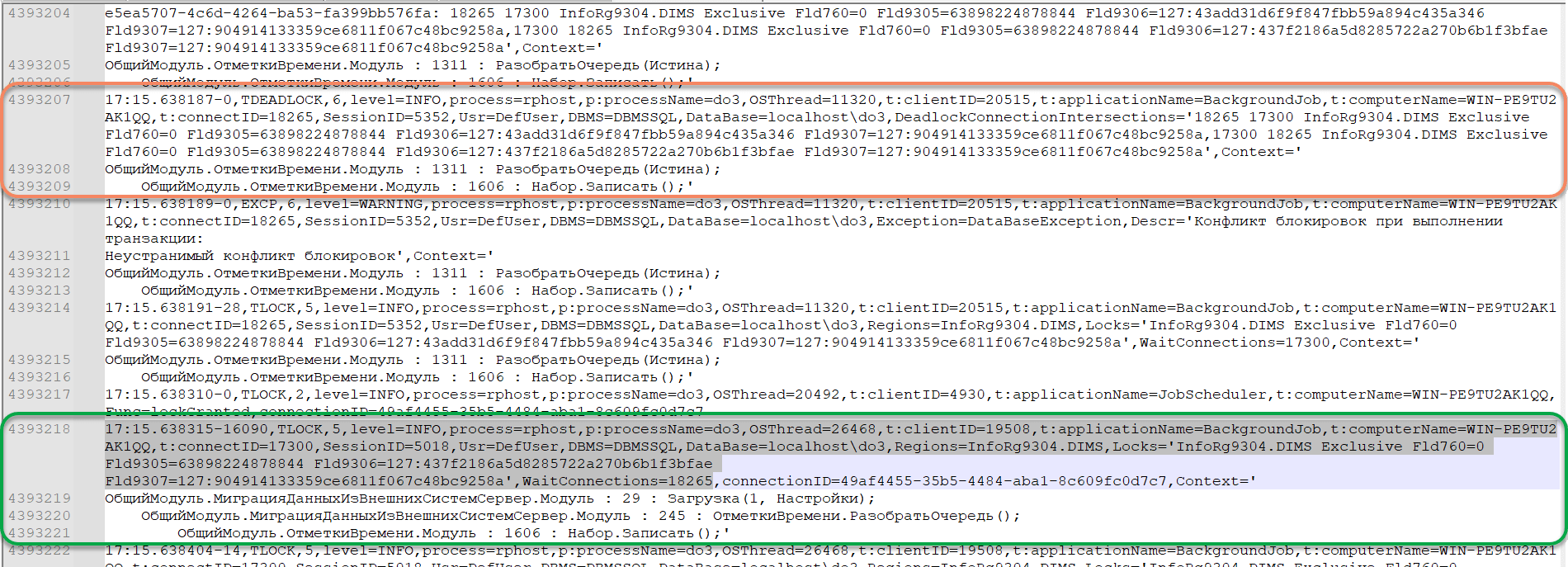
Шаг 4: Дальше найдем TLOCK жертвы по номеру соединения виновника, и пространству:
Находим запись пары:

Для удобства соберем найденные строки в один файл:

Примечание
Важно понимать, что, хотя Notepad++ является отличным инструментом, но его возможности по обработке регулярных выражений на больших файлах не безграничны.
При попытке применить сложное регулярное выражение (даже синтаксически корректное) к большому текстовому файлу в Notepad++, вы можете столкнуться с ошибкой:
«Поиск: Недопустимое регулярное выражение»
Это сообщение часто вводит в заблуждение! В отличие от прямого указания на синтаксическую ошибку в регулярном выражении, оно, как правило, является общим индикатором системных проблем. Движок регулярных выражений Notepad++ мог столкнуться с внутренней ошибкой, такой как переполнение стека, нехватка оперативной памяти или превышение лимита времени выполнения. Поскольку операция не была успешно завершена, система выдает эту общую ошибку, не уточняя истинную причину сбоя.
В нашей статье Notepad++ использовался исключительно как демонстрационный инструмент для иллюстрации принципов поиска по логам технологического журнала. Для практической работы с большими объемами данных гораздо эффективнее и надежнее применять специализированные решения, такие как утилиты командной строки (bash с grep/awk) или комплексные системы, например, «1С-Рарус: Мониторинг производительности».
Для полного понимания ситуации, далее мы разберем схему возникновения данной взаимоблокировки.
Анализ схемы взаимоблокировки
Выведем участников взаимоблокировки TLOCK в таблицу:
| Время | Участник | Соединение | Ресурс | Ожидание |
|---|---|---|---|---|
| 17:15.622132 | Виновник | 17300 | Fld9305=63898224878844 Fld9306=127:43add31d6f9f847fbb59a894c435a346 Fld9307=127:904914133359ce6811f067c48bc9258a | |
| 17:15.622142 | Жертва | 18265 | Fld9305=63898224878844 Fld9306=127:437f2186a5d8285722a270b6b1f3bfae Fld9307=127:904914133359ce6811f067c48bc9258a | |
| 17:15.638191 | Жертва | 18265 | Fld9305=63898224878844 Fld9306=127:43add31d6f9f847fbb59a894c435a346 Fld9307=127:904914133359ce6811f067c48bc9258a | 17300 |
| 17:15.638315 | Виновник | 17300 | Fld9305=63898224878844 Fld9306=127:437f2186a5d8285722a270b6b1f3bfae Fld9307=127:904914133359ce6811f067c48bc9258a | 18265 |
Анализ логов показывает: причиной конфликта блокировок стало нарушение порядка захвата ресурсов, что подтверждается различиями в значении поля Fld9306. Представим это наглядной схемой, включив найденных участников:

Итак, участники блокировок успешно идентифицированы. Прежде чем перейти к анализу контекстов, сопоставим наименования полей таблицы СУБД с их наименованиями, заданными в конфигурации ДО3. В нашем случае пространством блокировки было InfoRg9304.DIMS — измерения регистра сведений «ОтметкиВремениОчередь3»:
- Fld9305 — Отметка.
- Fld9306 — Ключ.
- Fld9307 — Объект.

Анализ контекстов выполнения кода
Приступим к разбору контекстов событий блокировок, вызвавших конфликт блокировок.
Контекст выполнения соединения 17300
Давайте проанализируем контекст выполнения, связанный с t:connectID=17300:
ОбщийМодуль.МиграцияДанныхИзВнешнихСистемСервер.Модуль : 245 : ОтметкиВремени.РазобратьОчередь();
ОбщийМодуль.ОтметкиВремени.Модуль : 1606: Набор.Записать();
Источником контекста является регламентное задание «Миграция с предыдущей версии. Загрузка»:


Данное регламентное задание выполняет загрузку данных из каталога миграции.
Контекст выполнения соединения 18265
Переходим к анализу контекста, ставшего жертвой текущего случая взаимоблокировки (могло бы быть и наоборот):
ОбщийМодуль.ОтметкиВремени.Модуль : 1606 : Набор.Записать();
Определяем источник, регламентное задание «Отметки времени. Обработка»:


Это регламентное задание выполняет распределение данных очереди в целевые регистры отметок времени, особенности отметок времени можно посмотреть в разделе подсистема «Отметки времени» первой части статьи.
Обработка очереди отметок времени
Можно заметить, что оба контекста проходят через процедуру ОтметкиВремени.РазобратьОчередь() и имеют общую точку завершения:
Код, который приводит к конфликту блокировок — это очистка обработанных записей из очереди:

Согласно коду, очистка наборов очереди отметок времени происходит порциями по 10 записей, каждая из которых обрабатывается в рамках одной транзакции, и так до полной очистки выбранной обработанной порции. Предполагаем, что пакетное выполнение в транзакции реализовано для оптимизации: подобная групповая запись действительно может быть быстрее за счет сокращения ряда сопроводительных операций передачи данных.
Если далее проанализировать код метода РазобратьОчередь() можно найти запрос, формирующий выборку записей очереди. И важный момент этого запроса заключается в том, что сортировка данных производится исключительно по полю «Отметка» (ТекущаяДатаВМиллисекундах):

Когда данные загружаются одновременно в 5 потоков, существует высокая вероятность того, что несколько записей об изменениях попадут в очередь в один и тот же момент времени (Отметка) . Проблема в том, что выборка из очереди происходит только по полю «Отметка». Из‑за этого, когда два регламента одновременно пытаются обработать эти записи, они могут захватывать ресурсы (Отметка, Ключ, Объект) в разном, непредсказуемом порядке. Именно это является источником потенциальных взаимоблокировок:

Формально для устранения этой проблемы можно было бы расширить упорядочивание, включив в него поле «Ключ» (ЛюбаяСсылка). Его достаточная уникальность обеспечит последовательный и предсказуемый порядок блокирования ресурсов, тем самым предотвращая конфликты.
Однако тут возникает закономерный вопрос, а как так получилось, что очередь отметок разбирают одновременно два регламента?
Попробуем разобраться с этим и заодно выяснить, является ли конфликт блокировки причиной, по которой загрузка данных работала в одном потоке вместо пяти, что привело к значительному замедлению.
Для наглядности схематично изобразим оба контекста, а также освежим в памяти алгоритм загрузки данных, представленный в первой части статьи:
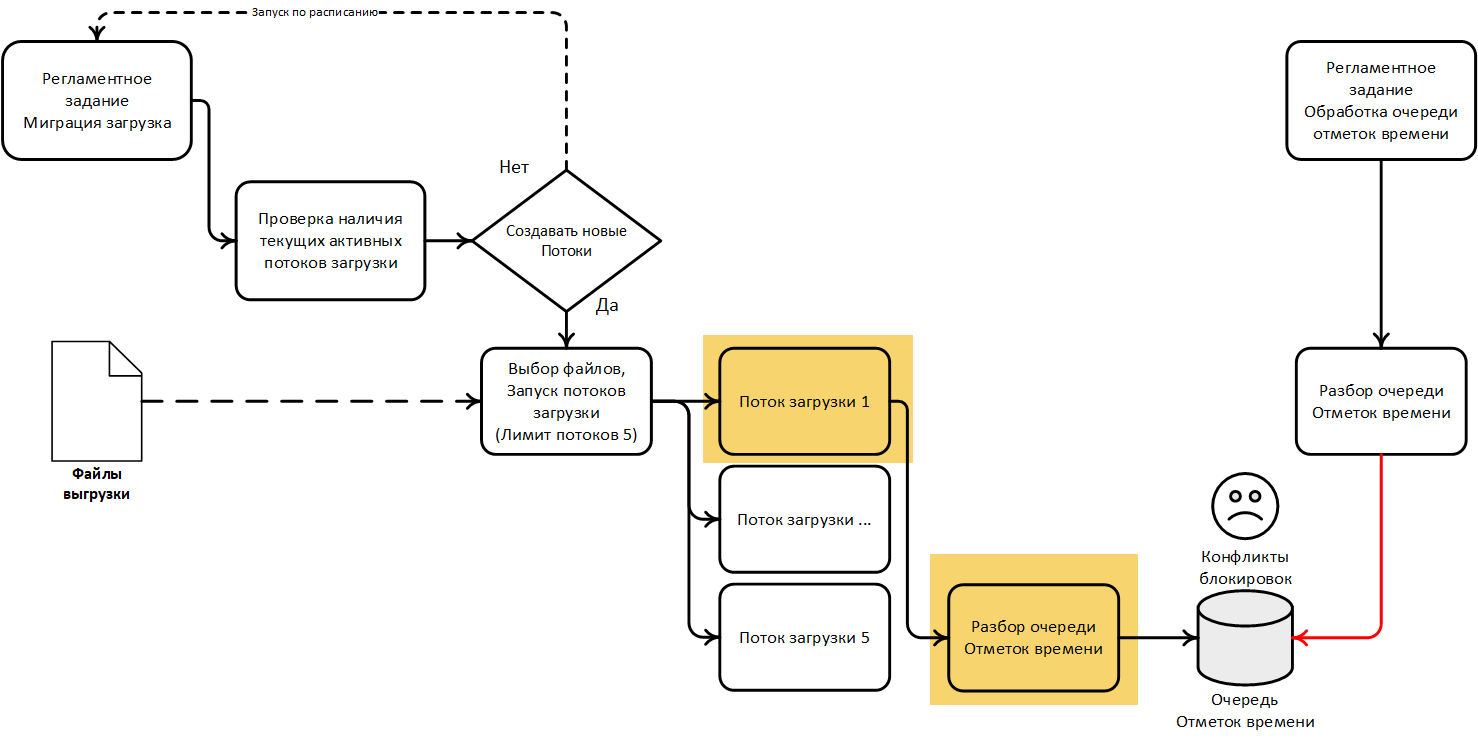
Взглянув на схему мы предположили, что вызов операции обработки очереди отметок времени в регламенте загрузки данных — избыточен. Для проверки этой гипотезы и всестороннего анализа давайте детально изучим алгоритм функционирования самого потока загрузки данных.
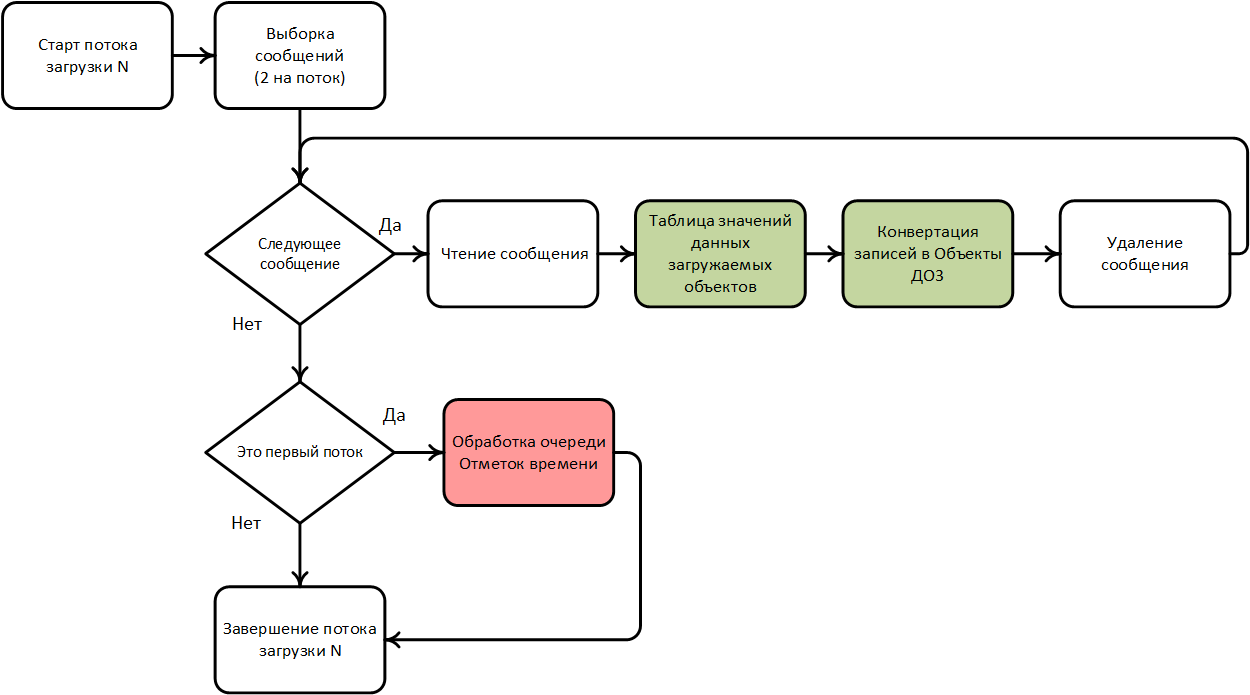
Алгоритм потока загрузки данных в 1С:Документооборот 3
Для наглядности алгоритм потока загрузки также представим в форме схемы:

- Старт потока: новый поток инициируется на верхнем уровне, учитывая количество активных потоков и последовательность загружаемых объектов, а также для него определяется признак «первый поток» (см. раздел «Про особенности работы регламента загрузки в ДО3» Части 1).
- Выборка сообщений: из каталога миграции выбираются 2 файла сообщений.
- Цикл обработки сообщений: пока имеется набор сообщений к загрузке производится цикл действий.
Чтение файла -> таблица значений с данными:

Конвертация данных в объекты ДО3 — данные, содержащиеся в таблице значений, именуемой в коде как «Порция», преобразуются в объекты ДО3 с помощью специализированных методов для конкретного типа данных объекта:

- Успешная загрузка порции -> удаление файла, переход к следующему.
- Обработка очереди отметок времени — запускается каждый раз после завершения цикла обработки сообщений, но только в «первом потоке».
- Завершение потока.
Причина замедления/остановки загрузки объектов
Анализ алгоритмов показал: первый поток «застревает» на обработке накопленной очереди отметок времени. И здесь важно учесть, что по внутренней логике регламента миграции запуск новых потоков блокируется контролем последовательности загрузки файлов. Далее конфликты блокировок мешают очистке очереди, поток жертвы взаимоблокировки аварийно завершается — всё перезапускается регламентом и цикл повторяется:
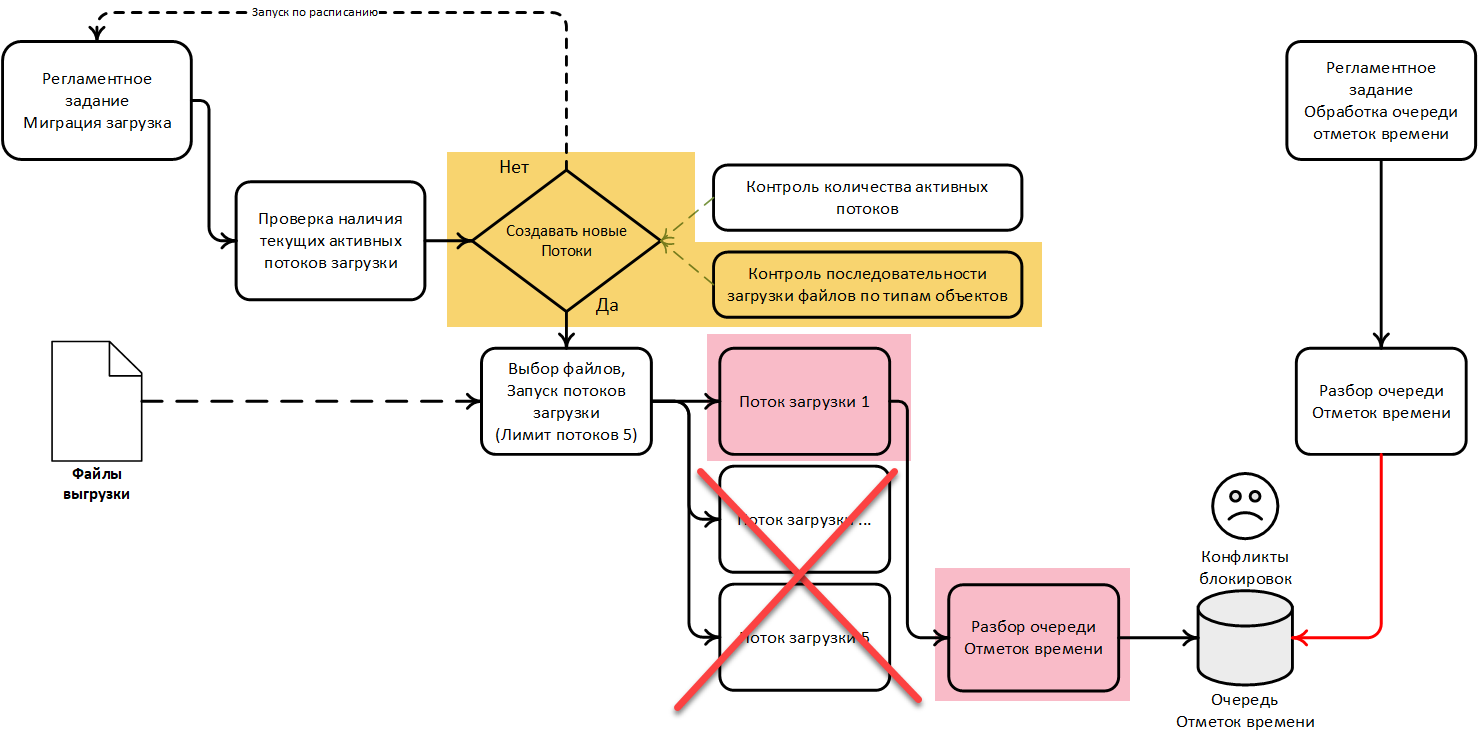
Эти выводы окончательно склонили нас к решению — полностью исключить вызов обработки очереди отметок времени из основного процесса загрузки. Эта функция будет целиком возложена на регламентное задание «Обработка очереди отметок времени».
Мы предполагаем, что текущая реализация разбора очереди предполагала целенаправленное регулирование темпа процесса загрузки для обеспечения своевременной обработки данной очереди. Это обусловлено тем, что чрезмерный объем очереди увеличивает время проверки изменений перед загрузкой объектов, что в конечном итоге так же замедляет процесс загрузки.
Отсюда же предвидим возможные негативные последствия нашего решения — возникает риск потенциального неконтролируемого роста очереди отметок времени.
Поэтому вместе с отключением обработки очереди в регламенте миграции также решено поработать над ускорением работы штатного регламента обработки очереди и добавить средства мониторинга размера очереди.
Медленная обработка таблицы данных
Безусловно проблема уменьшения скорости загрузки можно сказать являлась стоп-фактором всего процесса миграции. Однако напомним, что по замерам мы не укладывались в сроки и до выявленного замедления.
Поэтому вместе с анализом алгоритма потока загрузки для решения проблемы с разбором очереди, мы занялись исследованием производительности. И обнаружили, что одними из самых «нагруженных» являются этапы обработки таблицы значений данных загружаемых объектов и конвертации их в объекты базы:

А так как часто таблицу можно разбить на несколько порций, и при этом на нашей машине было достаточно много ядер (процессор Intel Xeon Gold 6248R 3.00 ГГц — 44 ядра), пришла идея о распараллеливании этих этапов.
Проведя «эскизный» тест мы убедились в перспективности подхода. Мы сравнили типовую и многопоточную (5 потоков) загрузку одних и тех же файлов регистра сведений «МоиДокументы» (порции по 10 000 записей). Замеры из журнала миграции показали почти двукратное сокращение времени загрузки:

Исправления и оптимизация
От завершения этапа анализа выявленных проблем переходим к их практическому решению. В этой главе будет изложен план оптимизации и представлены разработанные нами подходы, направленные на предотвращение конфликтов блокировки и обеспечение прироста скорости загрузки данных.
План оптимизации загрузки в ДО3
Опираясь на данные предыдущего анализа, составим план по повышению производительности и стабильности загрузки данных, а также по внедрению дополнительного мониторинга сопутствующих процессов:

- Работы по блоку обработки очереди отметок:
Отключение обработки очереди отметок времени из контекста загрузки.
В целях обеспечения бесперерывной загрузки данных, предлагается полностью исключить вызов обработки очереди отметок времени из основного процесса загрузки. Эта функция будет целиком возложена на регламентное задание «Обработка очереди отметок времени».
- Необходимые меры, связанные с отключением обработки очереди отметок времени из контекста загрузки:
Оптимизация алгоритмов обработки очереди отметок времени.
Рассматривается возможность внедрения многопоточной обработки очереди.
Разработать инструмент мониторинга динамики очереди.
Он должен обеспечивать регулярную фиксацию размеров очереди, что позволит увидеть динамику. И в случае необходимости, если увидим, что очередь продолжает расти, сможем своевременно корректировать настройки расписания регламентного задания или количество потоков загрузки.

- Дополнительная сортировка выборки очереди. Ну и конечно сортировка при отборе записей из очереди для предотвращения конфликтов блокировок, причины которых разобрали ранее.
- Внедрение дополнительной многопоточной обработки данных.
Решено ускорить этап обработки таблицы значений загружаемых данных путем деления входящей таблицы на порции и обработки в нескольких потоках. - В местах добавления многопоточности для сглаживания возможных проблем решено реализовать управление количеством потоков и порций, а также адаптивное их изменение в зависимости от показателей загрузки.
Сформулировав основные направления работ, мы переходим к их реализации.
Отключение обработки очереди отметок времени из контекста загрузки
Первое что мы хотели сделать — отключить вызов обработки очереди отметок из основного регламента загрузки данных.
Для этого в общем модуле МиграцияДанныхИзВнешнихСистемСервер в методе «Загрузка()» комментируем вызов процедуры РазобратьОчередь():

На этом в общем-то доработка завершена. Переходим к ускорению основного регламента разбора очереди отметок.
Оптимизация обработки очереди отметок времени
Для описания основных мест доработок, рассмотрим алгоритм обработки отметок времени до изменений:

- Выборка записей очереди. Из очереди извлекается порция, содержащая до 300 записей.
- Основной цикл обработки. Запускается цикл, который продолжается до тех пор, пока имеются записи для обработки.
- Транзакция распределения записей очереди. В рамках одной транзакции записи очереди распределяются по соответствующим целевым регистрам отметок времени, основываясь на их типе.
- Транзакция удаления записей очереди. Обработанные записи удаляются из очереди порциями по 10 штук в отдельных транзакциях, пока не удалится вся исходная выборка.
- Контроль времени выполнения. При передаче параметра РежимОжидания = Истина (в контексте регламентного задания «Обработка отметок времени») цикл имеет принудительный таймаут в 1 час, по истечении которого выполнение прерывается.
Оптимизированный алгоритм обработки очереди отметок времени
Мы предложили следующую схему оптимизированного алгоритма обработки очереди отметок времени:

Добавленные улучшения:
- Регулировка порций выборки. Реализована возможность настройки размера порций при выборке данных, что позволяет увеличить лимит сверх прежних 300 записей (по 100 записей из каждого регистра очередей).
- Дополнительная сортировка в запросе. В качестве меры для предотвращения конфликтов блокировок вследствие разного порядка захвата ресурсов, дополнительно добавлена сортировка данных по полю «Ключ» (было только по Отметке, стало Ключ, Отметка). Поскольку в рамках текущей оптимизации применяется многопоточная обработка очереди, количество параллельных транзакций будет увеличено многократно.
- Предварительная подготовка к распределению. Добавлен метод, осуществляющий предварительную свертку записей по максимальным значениям «Отметка» и «Граница» перед многопоточным распределением и также сортирующий по полям «Ключ», «Объект». Это необходимо для:
- Сохранения логики изменений. Гарантирует, что при многопоточной записи в регистры будут установлены только максимальные отметки, предотвращая запись устаревших данных, что могло бы нарушить механизм проверки изменений.
- Предотвращения взаимоблокировок. Аналогично п. 2.
- Отдельные регулировки количества потоков. Добавлена возможность раздельной настройки числа потоков для распределения записей очереди и для очистки очереди.
- Многопоточная обработка. Добавлена многопоточная обработка операций распределения записей очереди и очистки.
Фиксация размеров очереди. Добавлен регистр сведений для фиксации размеров очереди по состоянию на определенный момент времени. Размер очереди фиксируется с заданным интервалом, после каждой итерации обработки. Он поможет в деле мониторинга размера очереди и анализа истории изменения параметров обработки.

- Авторегулировка порций. Добавлена автоматическая регулировка размера порции при отборе очереди, по аналогии с уже существующей авторегулировкой количества потоков. В случае возникновения исключений, обработка задания прерывается и размер порции уменьшается на заданный шаг до минимума в 10 записей. При успешном завершении порция увеличивается на заданный шаг до установленного предела.
Теперь изложим подробнее примеры в коде.
Устранение причины конфликта блокировок
В методе ОтметкиВремени.РазобратьОчередь() добавлена дополнительная сортировка по полям Ключ, Объект:

Регулировка порции запроса
В той же процедуре РазобратьОчередь() добавили регулировку порций отбора из очередей:


Добавили метод переопределения порции:
// Переопределяет размер порций в запросе
//
Процедура ПорцииПереопределить(ТекстЗапроса)
ИдентификаторПорцияОтметкиВремени = "ПорцияОтметкиВремени";
Если НЕ из_Привязка.Существует(ИдентификаторПорцияОтметкиВремени) Тогда
Возврат;
КонецЕсли;
ТекстПоиска = "100 //ЗаменаПорций";
Порция = из_Привязка.Получить(ИдентификаторПорцияОтметкиВремени);
Если Число(Порция) > 0 Тогда
ТекстЗапроса = СтрЗаменить(ТекстЗапроса, ТекстПоиска, СтрЗаменить(Порция, Символы.НПП, ""));
КонецЕсли;
КонецПроцедуры // ПорцииПереопределитьПримечание
Здесь и далее в коде можно увидеть применение специального механизма «привязок». Его описание выходит за рамки статьи, но по сути это просто получение ранее сохраненных настроек. Можно воспринимать это как аналог получения из константы.
Пример:
Значение = из_Привязка.Получить(«ИмяНастройки»);
То же самое, что:
Значение = Константы[«ИмяНастройки»].Получить();
Раздельная регулировка количества потоков
Добавлены независимые настройки для управления числом потоков, используемых в операциях распределения записей очереди отметок времени и в операциях очистки очереди:
// Возвращает параметры многопоточности
//
// Возвращаемое значение:
// Структура
//
Функция МногопоточностьПараметрыПолучить()
ИДРаспределениеПотоки = "КоличествоПотоковРаспределенияОчередиОтметокВремени";
ИДОчисткаПотоки = "КоличествоПотоковОчисткиОчередиОтметокВремени";
Результат = Новый Структура;
Результат.Вставить("РаспределениеПотоки", 0);
Результат.Вставить("ОчисткаПотоки", 0);
Если из_Привязка.Существует(ИДРаспределениеПотоки) Тогда
Результат.РаспределениеПотоки = из_Привязка.Получить(ИДРаспределениеПотоки);
КонецЕсли;
Если из_Привязка.Существует(ИДОчисткаПотоки) Тогда
Результат.ОчисткаПотоки = из_Привязка.Получить(ИДОчисткаПотоки);
КонецЕсли;
Возврат Результат;
КонецФункции // МногопоточностьПараметрыПолучить()Многопоточное распределение записей очереди отметок времени
При распределении записей из очередей есть важные нюансы:
При записи набора условие по полю Отметка исключается, а фактический отбор выполняется по полям Ключ и Объект (для ссылочных записей — только по Ключу):

Поскольку в запросе сортировка сейчас начинается с «Отметка», необходимо перестроить порядок сортировки так, чтобы в приоритете стояли ключевые поля «Ключ», «Объект»; в противном случае при многопоточном распределении записей возможны конфликты блокировок из-за разного порядка захвата ресурсов. Ранее при двух потоках таких конфликтов при распределении не наблюдалось (проблемы возникали только при операции очистки очереди), но при увеличении числа потоков этот момент нужно учесть сразу — сортировку следует добавить в метод распределения перед обработкой, сохранив при этом существующую сортировку из запроса по полю «Удаление» по убыванию.
- Перед многопоточной обработкой необходимо сразу сгруппировать записи к распределению по Максимальной отметке и границе, так как судя по отборам набора (Ключ, Объект), максимальная Отметка и Граница записывалась последовательно, а у нас из-за разбивки на потоки в данном случае может записаться некорректная Отметка.
Разработали специальную функцию получения записей к распределению очереди сразу по максимальным отметкам и необходимой сортировкой:
// Возвращает таблицу данных очереди к распределению
//
// Параметры:
// Источник - ТаблицаЗначений - Очередь
//
// Возвращаемое значение:
// ТаблицаЗначений
//
Функция ДанныеКРаспределениюПолучить(Источник)
Запрос = Новый Запрос("ВЫБРАТЬ
| Т.Владелец КАК Владелец,
| Т.Граница КАК Граница,
| Т.ЗначенияКлюча КАК ЗначенияКлюча,
| Т.Источник КАК Источник,
| Т.Ключ КАК Ключ,
| Т.ОбновитьГраницу КАК ОбновитьГраницу,
| Т.Объект КАК Объект,
| Т.Отметка КАК Отметка,
| Т.ТипКлюча КАК ТипКлюча,
| Т.Удаление КАК Удаление
|ПОМЕСТИТЬ Данные
|ИЗ
| &Источник КАК Т
|;
|
|////////////////////////////////////////////////////////////////////////////////
|ВЫБРАТЬ
| Т.Владелец КАК Владелец,
| Т.Источник КАК Источник,
| Т.Ключ КАК Ключ,
| Т.ОбновитьГраницу КАК ОбновитьГраницу,
| Т.Объект КАК Объект,
| Т.ТипКлюча КАК ТипКлюча,
| Т.Удаление КАК Удаление,
// Добавлено получение Максимума {
| МАКСИМУМ(Т.Граница) КАК Граница,
| МАКСИМУМ(Т.Отметка) КАК Отметка
// Добавлено получение Максимума }
|ПОМЕСТИТЬ ОтметкиМакс
|ИЗ
| Данные КАК Т
|
|СГРУППИРОВАТЬ ПО
| Т.Владелец,
| Т.Источник,
| Т.Ключ,
| Т.ОбновитьГраницу,
| Т.Объект,
| Т.ТипКлюча,
| Т.Удаление
|;
|
|////////////////////////////////////////////////////////////////////////////////
|ВЫБРАТЬ
| Т.Владелец КАК Владелец,
| Т.Источник КАК Источник,
| Т.Ключ КАК Ключ,
| Т.ОбновитьГраницу КАК ОбновитьГраницу,
| Т.Объект КАК Объект,
| Т.ТипКлюча КАК ТипКлюча,
| Т.Удаление КАК Удаление,
| Т.Граница КАК Граница,
| Т.Отметка КАК Отметка,
| Данные.ЗначенияКлюча КАК ЗначенияКлюча
|ИЗ
| ОтметкиМакс КАК Т
| ВНУТРЕННЕЕ СОЕДИНЕНИЕ Данные КАК Данные
| ПО Т.Владелец = Данные.Владелец
| И Т.Источник = Данные.Источник
| И Т.Ключ = Данные.Ключ
| И Т.ОбновитьГраницу = Данные.ОбновитьГраницу
| И Т.Объект = Данные.Объект
| И Т.Отметка = Данные.Отметка
| И Т.ТипКлюча = Данные.ТипКлюча
| И Т.Удаление = Данные.Удаление
| И Т.Граница = Данные.Граница
|
|УПОРЯДОЧИТЬ ПО
// Сортировка {
| Ключ,
| Объект,
// Добавлено получение Максимума }
| Удаление УБЫВ");
Запрос.УстановитьПараметр("Источник", Источник);
Возврат Запрос.Выполнить().Выгрузить();
КонецФункции // ДанныеКРаспределениюПолучить()// Обрабатывает очередь, распределяет записи по целевым регистрам
//
// Параметры:
// Очередь - ТаблицаЗначений/ХранилищеЗначений - Очередь
//
Процедура опт_ОчередьПоРегистрамРаспределить(Очередь) Экспорт
Если ТипЗнч(Очередь) = Тип("ХранилищеЗначения") Тогда
Очередь = Очередь.Получить();
КонецЕсли;
ВремяПерерыва = Неопределено;
ОтметкиВремениСсылочныхОбъектов = Неопределено;
ОтметкиВремениРегистровНезависимых = Неопределено;
ОтметкиВремениРегистровПодчиненных = Неопределено;
ОкнаОчереди = Неопределено;
СостояниеОчереди = 2;
НачатьТранзакцию();
Попытка
Если Очередь.Количество() Тогда
Для Каждого Очередность Из Очередь Цикл
Если Очередность.ОбновитьГраницу = Ложь Тогда
Продолжить;
ИначеЕсли Очередность.ТипКлюча = 0 Тогда
Если ОтметкиВремениСсылочныхОбъектов = Неопределено Тогда
ОтметкиВремениСсылочныхОбъектов = РегистрыСведений.ОтметкиВремениСсылочныхОбъектов.СоздатьНаборЗаписей();
ОтметкиВремениСсылочныхОбъектов.Отбор.Ключ.Использование = Истина;
ОтметкиВремениСсылочныхОбъектов.Добавить();
ЗаполнитьРежимЗаписи(ОтметкиВремениСсылочныхОбъектов);
КонецЕсли;
ЗаполнитьЗначенияСвойств(ОтметкиВремениСсылочныхОбъектов[0], Очередность);
//Поддержка старого формата на переходный период.
ОтметкиВремениСсылочныхОбъектов[0].УдалитьОтметка =
Формат(Дата(1, 1, 1) + Цел(ОтметкиВремениСсылочныхОбъектов[0].Отметка / 1000), "ДФ=yyyyMMddHHmmss")
+ Формат(ОтметкиВремениСсылочныхОбъектов[0].Отметка % 1000, "ЧЦ=3; ЧН=000; ЧВН=; ЧГ=0");
ОтметкиВремениСсылочныхОбъектов.Отбор.Ключ.Значение = Очередность.Ключ;
ОтметкиВремениСсылочныхОбъектов.Записать();
ИначеЕсли Очередность.ТипКлюча <= 2 Тогда
Если ОтметкиВремениРегистровПодчиненных = Неопределено Тогда
ОтметкиВремениРегистровПодчиненных = РегистрыСведений.ОтметкиВремениРегистровПодчиненных.СоздатьНаборЗаписей();
ОтметкиВремениРегистровПодчиненных.Отбор.Ключ.Использование = Истина;
ОтметкиВремениРегистровПодчиненных.Отбор.Объект.Использование = Истина;
ОтметкиВремениРегистровПодчиненных.Добавить();
ЗаполнитьРежимЗаписи(ОтметкиВремениРегистровПодчиненных);
КонецЕсли;
ЗаполнитьЗначенияСвойств(ОтметкиВремениРегистровПодчиненных[0], Очередность);
ОтметкиВремениРегистровПодчиненных.Отбор.Ключ.Значение = Очередность.Ключ;
ОтметкиВремениРегистровПодчиненных.Отбор.Объект.Значение = Очередность.Объект;
ОтметкиВремениРегистровПодчиненных.Записать();
Иначе
Если ОтметкиВремениРегистровНезависимых = Неопределено Тогда
ОтметкиВремениРегистровНезависимых = РегистрыСведений.ОтметкиВремениРегистровНезависимых.СоздатьНаборЗаписей();
ОтметкиВремениРегистровНезависимых.Отбор.Ключ.Использование = Истина;
ОтметкиВремениРегистровНезависимых.Отбор.Объект.Использование = Истина;
ОтметкиВремениРегистровНезависимых.Добавить();
ЗаполнитьРежимЗаписи(ОтметкиВремениРегистровНезависимых);
КонецЕсли;
Запись = ОтметкиВремениРегистровНезависимых[0];
ЗаполнитьЗначенияСвойств(Запись, Очередность);
Запись.КлючСсылка = Очередность.Ключ;
Запись.Ключ = Очередность.Ключ.УникальныйИдентификатор();
ОтметкиВремениРегистровНезависимых.Отбор.Ключ.Значение = Запись.Ключ;
ОтметкиВремениРегистровНезависимых.Отбор.Объект.Значение = Запись.Объект;
ОтметкиВремениРегистровНезависимых.Записать();
КонецЕсли;
КонецЦикла;
СостояниеОчереди = 2;
КонецЕсли;
ЗафиксироватьТранзакцию();
Исключение
ОтменитьТранзакцию();
ВызватьИсключение;
КонецПопытки;
Набор = Неопределено;
ОтметкиВремениСсылочныхОбъектов = Неопределено;
ОтметкиВремениРегистровНезависимых = Неопределено;
ОтметкиВремениРегистровПодчиненных = Неопределено;
КонецПроцедуры // ОчередьПоРегистрамРаспределить()
Многопоточная очистка записей очереди отметок времени
В методе очистки получаем уже отсортированную таблицу из запроса:
// Очищает очередь
//
// Параметры:
// Очередь - ТаблицаЗначений/ХранилищеЗначений - Очередь
// ТолькоГраницу - Булево - ТолькоГраницу
//
Процедура опт_ОчередьОчистить(Очередь, ТолькоГраницу) Экспорт
Если ТипЗнч(Очередь) = Тип("ХранилищеЗначения") Тогда
Очередь = Очередь.Получить();
КонецЕсли;
ОкнаОчереди = Неопределено;
ВремяПерерыва = Неопределено;
Пока Не ТолькоГраницу И Очередь.Количество() Цикл
Если ОкнаОчереди = Неопределено Тогда
ОкнаОчереди = Новый Массив(4);
КонецЕсли;
НачатьТранзакцию();
Попытка
Для Н = 1 По Мин(10, Очередь.Количество()) Цикл
Очередность = Очередь[0];
Если Не ЗначениеЗаполнено(Очередность.Объект) Тогда
Очередь.Удалить(Очередность);
Продолжить;
КонецЕсли;
Набор = ОкнаОчереди[Очередность.Окно];
Если Набор = Неопределено Тогда
Набор = РегистрыСведений["ОтметкиВремениОчередь" + Очередность.Окно].СоздатьНаборЗаписей();
Для Каждого Поле Из Набор.Отбор Цикл
Поле.Использование = Истина;
КонецЦикла;
ЗаполнитьРежимЗаписи(Набор);
ОкнаОчереди[Очередность.Окно] = Набор;
КонецЕсли;
Отбор = Набор.Отбор;
Отбор.Отметка.Значение = Очередность.Отметка;
Отбор.Ключ.Значение = Очередность.Ключ;
Отбор.Объект.Значение = Очередность.Объект;
Набор.Записать();
Очередь.Удалить(Очередность);
КонецЦикла;
ЗафиксироватьТранзакцию();
Исключение
ОтменитьТранзакцию();
ЗаписьЖурналаРегистрации(
НСтр("ru = 'ОтметкиВремени.Обработка'"),
УровеньЖурналаРегистрации.Ошибка,,,
ПодробноеПредставлениеОшибки(ИнформацияОбОшибке()));
ВызватьИсключение;
КонецПопытки;
КонецЦикла;
Если ОкнаОчереди <> Неопределено Тогда
ОкнаОчереди.Очистить();
КонецЕсли;
КонецПроцедуры // ОчередьОчистить()Реализованы методы для подготовки и запуска фоновых заданий.
Метод подготовки и запуска многопоточного распределения записей очереди:
// Запускает многопоточную обработку распределения отметок времени
//
// Параметры:
// Задания - Массив - Массив идентфикаторов фоновых, заполняется по мере запуска
// КоличествоПотоков - Число - Количество потоков
// Параметры - Структура - Параметры фонового задания
// МетодаИмя - Строка - Имя метода
//
Процедура ОтметкиВремениРаспределениеЗапустить(Задания, КоличествоПотоков, Параметры, МетодаИмя) Экспорт
Очередь = Параметры.Очередь;
ДанныеКоличество = Очередь.Количество();
Размер = ДанныеКоличество / КоличествоПотоков;
ПорцияРазмер = ?(Размер = Цел(Размер), Размер, Цел(Размер) + 1);
ПредставлениеЗадания = "Распределение очереди отметок времени";
ПорцияЗадания = Очередь.СкопироватьКолонки();
Для Каждого Строка Из Очередь Цикл
НоваяСтрока = ПорцияЗадания.Добавить();
ЗаполнитьЗначенияСвойств(НоваяСтрока, Строка);
Если ПорцияЗадания.Количество() = ПорцияРазмер Тогда
ПараметрыМетода = Новый Массив;
ПараметрыМетода.Добавить(Новый Структура("Очередь", Новый ХранилищеЗначения(ПорцияЗадания)));
Задания.Добавить(ФоновоеЗапустить(МетодаИмя, ПараметрыМетода, , ПредставлениеЗадания));
ПорцияЗадания = Очередь.СкопироватьКолонки();
КонецЕсли;
КонецЦикла;
// Остатки
Если ПорцияЗадания.Количество() Тогда
ПараметрыМетода = Новый Массив;
ПараметрыМетода.Добавить(Новый Структура("Очередь", Новый ХранилищеЗначения(ПорцияЗадания)));
Задания.Добавить(ФоновоеЗапустить(МетодаИмя, ПараметрыМетода, , ПредставлениеЗадания));
КонецЕсли;
КонецПроцедуры //Метод подготовки и запуска многопоточной очистки:
// Запускает многопоточную обработку очистки очереди отметок времени
//
// Параметры:
// Задания - Массив - Массив идентфикаторов фоновых, заполняется по мере запуска
// КоличествоПотоков - Число - Количество потоков
// Параметры - Структура - Параметры фонового задания
// МетодаИмя - Строка - Имя метода
//
Процедура ОтметкиВремениОчисткаЗапустить(Задания, КоличествоПотоков, Параметры, МетодаИмя) Экспорт
Очередь = Параметры.Очередь;
ТолькоГраницу = Параметры.ТолькоГраницу;
ДанныеКоличество = Очередь.Количество();
Размер = ДанныеКоличество / КоличествоПотоков;
ПорцияРазмер = ?(Размер = Цел(Размер), Размер, Цел(Размер) + 1);
ПредставлениеЗадания = "Очистка очереди отметок времени";
ПорцияЗадания = Очередь.СкопироватьКолонки();
Для Каждого Строка Из Очередь Цикл
НоваяСтрока = ПорцияЗадания.Добавить();
ЗаполнитьЗначенияСвойств(НоваяСтрока, Строка);
Если ПорцияЗадания.Количество() = ПорцияРазмер Тогда
ПараметрыМетода = Новый Массив;
ПараметрыМетода.Добавить(Новый Структура("Очередь", Новый ХранилищеЗначения(ПорцияЗадания)));
ПараметрыМетода.Добавить(Новый Структура("ТолькоГраницу", ТолькоГраницу));
Задания.Добавить(ФоновоеЗапустить(МетодаИмя, ПараметрыМетода, , ПредставлениеЗадания));
ПорцияЗадания = Очередь.СкопироватьКолонки();
КонецЕсли;
КонецЦикла;
// Остатки
Если ПорцияЗадания.Количество() Тогда
ПараметрыМетода = Новый Массив;
ПараметрыМетода.Добавить(Новый Структура("Очередь", Новый ХранилищеЗначения(ПорцияЗадания)));
ПараметрыМетода.Добавить(Новый Структура("ТолькоГраницу", ТолькоГраницу));
Задания.Добавить(ФоновоеЗапустить(МетодаИмя, ПараметрыМетода, , ПредставлениеЗадания));
КонецЕсли;
КонецПроцедуры //Доработка типового метода РазобратьОчередь() — оставлена возможность однопоточной обработки опционально в зависимости от настроек:
&Вместо("РазобратьОчередь")
Процедура опт_РазобратьОчередь(РежимОжидания, ТолькоГраницу)
..............................
// Получаем параметры потоков в каждой итерации
ПараметрыПотоков = МногопоточностьПараметрыПолучить();
Если ПараметрыПотоков.РаспределениеПотоки > 0 Тогда
ИмяМетода = "ОтметкиВремени.опт_ОчередьПоРегистрамРаспределить";
ОчередьКРаспределению = ДанныеКРаспределениюПолучить(Очередь);
Параметры = Новый Структура;
Параметры.Вставить("Очередь", ОчередьКРаспределению );
МассивЗаданий = Новый Массив;
опт_МногопоточнаяОбработка.ОтметкиВремениРаспределениеЗапустить(МассивЗаданий
, ПараметрыПотоков.РаспределениеПотоки
, Параметры
, ИмяМетода);
ТекстОшибки = опт_МногопоточнаяОбработка.Ожидать(МассивЗаданий);
ПривязкиПорцииАвтоопределить(ТекстОшибки);
Если ЗначениеЗаполнено(ТекстОшибки) Тогда
ВызватьИсключение ТекстОшибки;
КонецЕсли;
Иначе
опт_ОчередьПоРегистрамРаспределить(Очередь);
КонецЕсли;
Если ТолькоГраницу Тогда
Прервать;
КонецЕсли;
Если ПараметрыПотоков.ОчисткаПотоки > 0 Тогда
ИмяМетода = "ОтметкиВремени.опт_ОчередьОчистить";
Параметры = Новый Структура;
Параметры.Вставить("Очередь", Очередь);
Параметры.Вставить("ТолькоГраницу", ТолькоГраницу);
МассивЗаданий = Новый Массив;
опт_МногопоточнаяОбработка.ОтметкиВремениОчисткаЗапустить(МассивЗаданий
, ПараметрыПотоков.ОчисткаПотоки
, Параметры
, ИмяМетода);
ТекстОшибки = опт_МногопоточнаяОбработка.Ожидать(МассивЗаданий);
ПривязкиПорцииАвтоопределить(ТекстОшибки);
Если ЗначениеЗаполнено(ТекстОшибки) Тогда
ВызватьИсключение ТекстОшибки;
КонецЕсли;
Иначе
опт_ОчередьОчистить(Очередь, ТолькоГраницу);
КонецЕсли;
..............................
КонецПроцедурыТак же по аналогии автоматического управления потоками добавлен метод автоустановки размера порции:
// Автоматически устанавливает размер порции
//
// Параметры:
// ТекстОшибки - Строка - Текст ошибки
//
Процедура ПривязкиПорцииАвтоопределить(ТекстОшибки)
ИДПорция = "ПорцияОтметкиВремени";
Порция = Число(из_Привязка.Получить(ИДПорция));
Шаг = 20;
ШагУменьшение = 200;
Порог = 900;
УвеличитьПотоки = Ложь;
Если ТекстОшибки = Неопределено Тогда
УвеличитьПотоки = Истина;
КонецЕсли;
Если УвеличитьПотоки Тогда
Порция = Порция + Шаг;
Если Порция >= Порог Тогда
Порция = Порог;
КонецЕсли;
Иначе
Порция = Порция - ШагУменьшение;
Если Порция <= 5 Тогда
Порция = 5;
КонецЕсли;
КонецЕсли;
из_Привязка.Установить(ИДПорция
, Строка(Порция));
КонецПроцедуры // ПривязкиПотоковАвтоопределить()Фиксация размеров очереди
Добавлен функционал фиксации размеров очереди.
Метод фиксации:
// Фиксирует размер очереди отметок времени
//
Процедура РазмерОчередиЗафиксировать() Экспорт
Запрос = Новый Запрос("ВЫБРАТЬ
| КОЛИЧЕСТВО(1) КАК Количество,
| ""ОтметкиВремениОчередь1"" КАК Поле
|ПОМЕСТИТЬ Очередь1
|ИЗ
| РегистрСведений.ОтметкиВремениОчередь1 КАК Т
|;
|
|////////////////////////////////////////////////////////////////////////////////
|ВЫБРАТЬ
| КОЛИЧЕСТВО(1) КАК Количество,
| ""ОтметкиВремениОчередь2"" КАК Поле
|ПОМЕСТИТЬ Очередь2
|ИЗ
| РегистрСведений.ОтметкиВремениОчередь2 КАК Т
|;
|
|////////////////////////////////////////////////////////////////////////////////
|ВЫБРАТЬ
| КОЛИЧЕСТВО(1) КАК Количество,
| ""ОтметкиВремениОчередь3"" КАК Поле
|ПОМЕСТИТЬ Очередь3
|ИЗ
| РегистрСведений.ОтметкиВремениОчередь3 КАК Т
|;
|
|////////////////////////////////////////////////////////////////////////////////
|ВЫБРАТЬ
| Очередь1.Количество + Очередь2.Количество + Очередь3.Количество КАК Размер
|ИЗ
| Очередь1 КАК Очередь1,
| Очередь2 КАК Очередь2,
| Очередь3 КАК Очередь3");
Выборка = Запрос.Выполнить().Выбрать();
Выборка.Следующий();
ИДРаспределениеПотоки = "КоличествоПотоковРаспределенияОчередиОтметокВремени";
ИДОчисткаПотоки = "КоличествоПотоковОчисткиОчередиОтметокВремени";
ИДРазмерПорции = "ПорцияОтметкиВремени";
НаборЗаписей = РегистрыСведений.опт_РазмерыОчередиОтметокВремени.СоздатьМенеджерЗаписи();
НаборЗаписей.Дата = ТекущаяДатаСеанса();
НаборЗаписей.Размер = Выборка.Размер;
НаборЗаписей.КоличествоПотоковРаспределения = из_Привязка.Получить(ИДРаспределениеПотоки);
НаборЗаписей.КоличествоПотоковОчистки = из_Привязка.Получить(ИДОчисткаПотоки);
НаборЗаписей.РазмерПорции = из_Привязка.Получить(ИДРазмерПорции);
НаборЗаписей.Записать();
КонецПроцедуры // РазмерОчередиЗафиксироватьФиксируем в конце каждой итерации с проверкой интервала, заданного в привязках:
&Вместо("РазобратьОчередь")
Процедура опт_РазобратьОчередь(РежимОжидания, ТолькоГраницу)
......................................
// [+][...] 2024-07-29 {
СчетчикФиксации = 0;
ИнтервалФиксации = ИнтервалИтерацииФиксации();
// } # [...] 2024-07-29 }
Пока СостояниеОчереди >= 1 Цикл
......................................
МассивЗаданий = Новый Массив;
опт_МногопоточнаяОбработка.ОтметкиВремениОчисткаЗапустить(МассивЗаданий
, ПараметрыПотоков.ОчисткаПотоки
, Параметры
, ИмяМетода);
ТекстОшибки = опт_МногопоточнаяОбработка.Ожидать(МассивЗаданий);
Если ЗначениеЗаполнено(ТекстОшибки) Тогда
ВызватьИсключение ТекстОшибки;
КонецЕсли;
Иначе
опт_ОчередьОчистить(Очередь, ТолькоГраницу);
КонецЕсли;
СчетчикФиксации = СчетчикФиксации + 1;
Если СчетчикФиксации = ИнтервалФиксации Тогда
опт_МониторнигОчередиОтметок.РазмерОчередиЗафиксировать();
СчетчикФиксации = 0;
КонецЕсли;
......................................
КонецЦикла;
Набор = Неопределено;
ОтметкиВремениСсылочныхОбъектов = Неопределено;
ОтметкиВремениРегистровНезависимых = Неопределено;
ОтметкиВремениРегистровПодчиненных = Неопределено;
Если Очередь <> Неопределено Тогда
Очередь.Очистить();
КонецЕсли;
Если ОкнаОчереди <> Неопределено Тогда
ОкнаОчереди.Очистить();
КонецЕсли;
КонецПроцедурыМетод получения интервала, по умолчанию фиксируется после каждой итерации:
// Возвращает интервал итерации для фиксации размеров очереди
//
// Возвращаемое значение:
// Число
//
Функция ИнтервалИтерацииФиксации()
ИДИнтервал = "ИнтервалИтерацииФиксацииОбработкиОчередиОтметокВремени";
Результат = 1;
Если из_Привязка.Существует(ИДИнтервал) Тогда
Результат = из_Привязка.Получить(ИДИнтервал);
КонецЕсли;
Возврат Результат;
КонецФункции // ИнтервалИтерацииФиксации()Полный код расширенного метода РазобратьОчередь():
&Вместо("РазобратьОчередь")
Процедура опт_РазобратьОчередь(РежимОжидания, ТолькоГраницу)
УстановитьПривилегированныйРежим(Истина);
Запрос = Новый Запрос(
"ВЫБРАТЬ
| Т.Граница КАК Граница
|ПОМЕСТИТЬ Границы
|ИЗ
| (ВЫБРАТЬ ПЕРВЫЕ 1
| Т.Граница КАК Граница
| ИЗ
| РегистрСведений.ОтметкиВремениСсылочныхОбъектов КАК Т
|
| УПОРЯДОЧИТЬ ПО
| Граница УБЫВ) КАК Т
|
|ОБЪЕДИНИТЬ ВСЕ
|
|ВЫБРАТЬ
| Т.Граница
|ИЗ
| (ВЫБРАТЬ ПЕРВЫЕ 1
| Т.Граница КАК Граница
| ИЗ
| РегистрСведений.ОтметкиВремениРегистровПодчиненных КАК Т
|
| УПОРЯДОЧИТЬ ПО
| Т.Граница УБЫВ) КАК Т
|
|ОБЪЕДИНИТЬ ВСЕ
|
|ВЫБРАТЬ
| Т.Граница
|ИЗ
| (ВЫБРАТЬ ПЕРВЫЕ 1
| Т.Граница КАК Граница
| ИЗ
| РегистрСведений.ОтметкиВремениРегистровНезависимых КАК Т
|
| УПОРЯДОЧИТЬ ПО
| Т.Граница УБЫВ) КАК Т
|;
|
|////////////////////////////////////////////////////////////////////////////////
|ВЫБРАТЬ
| ЕСТЬNULL(МАКСИМУМ(Т.Граница), -1) КАК Граница
|ПОМЕСТИТЬ ГраницыМакс
|ИЗ
| Границы КАК Т
|;
|
|////////////////////////////////////////////////////////////////////////////////
|УНИЧТОЖИТЬ Границы
|;
|
|////////////////////////////////////////////////////////////////////////////////
// [+] # [...] 2024-08-02 {
//|ВЫБРАТЬ ПЕРВЫЕ 100
|ВЫБРАТЬ ПЕРВЫЕ 100 //ЗаменаПорций
// } # [...] 2024-08-02 }
| 1 КАК Окно,
| Т.Отметка КАК Отметка,
| Т.Ключ КАК Ключ,
| Т.Объект КАК Объект,
| Т.Удаление КАК Удаление,
| Т.Источник КАК Источник,
| Т.Владелец КАК Владелец,
| Т.ТипКлюча КАК ТипКлюча,
| Т.ИдентификаторКлюча КАК ИдентификаторКлюча,
| Т.ЗначенияКлюча КАК ЗначенияКлюча,
| ВЫБОР КОГДА Т.ТипКлюча = 0 ТОГДА 0 КОГДА Т.ТипКлюча <= 2 ТОГДА 1 ИНАЧЕ 2 КОНЕЦ КАК ХранилищеКлюча
|ПОМЕСТИТЬ Очередь
|ИЗ
| РегистрСведений.ОтметкиВремениОчередь1 КАК Т
|
|ОБЪЕДИНИТЬ ВСЕ
|
// [+] # [...] 2024-08-02 {
//|ВЫБРАТЬ ПЕРВЫЕ 100
|ВЫБРАТЬ ПЕРВЫЕ 100 //ЗаменаПорций
// } # [...] 2024-08-02 }
| 2,
| Т.Отметка,
| Т.Ключ,
| Т.Объект,
| Т.Удаление,
| Т.Источник КАК Источник,
| Т.Владелец КАК Владелец,
| Т.ТипКлюча,
| Т.ИдентификаторКлюча,
| Т.ЗначенияКлюча,
| ВЫБОР КОГДА Т.ТипКлюча = 0 ТОГДА 0 КОГДА Т.ТипКлюча <= 2 ТОГДА 1 ИНАЧЕ 2 КОНЕЦ
|ИЗ
| РегистрСведений.ОтметкиВремениОчередь2 КАК Т
|
|ОБЪЕДИНИТЬ ВСЕ
|
// [+] # [...] 2024-08-02 {
//|ВЫБРАТЬ ПЕРВЫЕ 100
|ВЫБРАТЬ ПЕРВЫЕ 100 //ЗаменаПорций
// } # [...] 2024-08-02 }
| 3,
| Т.Отметка,
| Т.Ключ,
| Т.Объект,
| Т.Удаление,
| Т.Источник КАК Источник,
| Т.Владелец КАК Владелец,
| Т.ТипКлюча,
| Т.ИдентификаторКлюча,
| Т.ЗначенияКлюча,
| ВЫБОР КОГДА Т.ТипКлюча = 0 ТОГДА 0 КОГДА Т.ТипКлюча <= 2 ТОГДА 1 ИНАЧЕ 2 КОНЕЦ
|ИЗ
| РегистрСведений.ОтметкиВремениОчередь3 КАК Т
|;
|
|ВЫБРАТЬ
| Т.Окно КАК Окно,
| Т.Отметка КАК Отметка,
| ВЫБОР
| КОГДА Границы.Граница >= Т.Отметка
| ТОГДА Границы.Граница + 1
| ИНАЧЕ Т.Отметка
| КОНЕЦ КАК Граница,
| Т.Ключ КАК Ключ,
| Т.Объект КАК Объект,
| Т.Удаление КАК Удаление,
| Т.Источник КАК Источник,
| Т.Владелец КАК Владелец,
| Т.ТипКлюча КАК ТипКлюча,
| Т.ЗначенияКлюча КАК ЗначенияКлюча,
| СсылочныхОбъектов.Отметка ЕСТЬ NULL И РегистровПодчиненных.Отметка ЕСТЬ NULL И РегистровНезависимых.Отметка ЕСТЬ NULL КАК ОбновитьГраницу
|ИЗ
| Очередь КАК Т
| ЛЕВОЕ СОЕДИНЕНИЕ РегистрСведений.ОтметкиВремениСсылочныхОбъектов КАК СсылочныхОбъектов
| ПО Т.ХранилищеКлюча = 0
| И Т.Ключ = СсылочныхОбъектов.Ключ
| И Т.Отметка <= СсылочныхОбъектов.Отметка
| ЛЕВОЕ СОЕДИНЕНИЕ РегистрСведений.ОтметкиВремениРегистровПодчиненных КАК РегистровПодчиненных
| ПО Т.ХранилищеКлюча = 1
| И Т.Ключ = РегистровПодчиненных.Ключ
| И Т.Объект = РегистровПодчиненных.Объект
| И Т.Отметка <= РегистровПодчиненных.Отметка
| ЛЕВОЕ СОЕДИНЕНИЕ РегистрСведений.ОтметкиВремениРегистровНезависимых КАК РегистровНезависимых
| ПО Т.ХранилищеКлюча = 2
| И Т.ИдентификаторКлюча = РегистровНезависимых.Ключ
| И Т.Объект = РегистровНезависимых.Объект
| И Т.Отметка <= РегистровНезависимых.Отметка
| ЛЕВОЕ СОЕДИНЕНИЕ ГраницыМакс КАК Границы
| ПО (ИСТИНА)
|
|//ГДЕ СсылочныхОбъектов.Отметка ЕСТЬ NULL И РегистровПодчиненных.Отметка ЕСТЬ NULL И РегистровНезависимых.Отметка ЕСТЬ NULL
|
|УПОРЯДОЧИТЬ ПО
| Отметка,
// [+][...] 2024-08-01 {
// Для предотвращения конфликтов блокировок разного порядка
// захвата ресурсов
|Ключ,
// } # [...] 2024-08-01 }
|Удаление УБЫВ");
ВремяПерерыва = Неопределено;
ОтметкиВремениСсылочныхОбъектов = Неопределено;
ОтметкиВремениРегистровНезависимых = Неопределено;
ОтметкиВремениРегистровПодчиненных = Неопределено;
ОкнаОчереди = Неопределено;
СостояниеОчереди = 2;
Если ТолькоГраницу Тогда
Запрос.Текст = СтрЗаменить(Запрос.Текст, "//ГДЕ", "ГДЕ");
КонецЕсли;
// [+] # [...] 2024-08-02 {
// Переопределение порций
ПорцииПереопределить(Запрос.Текст);
// } # [...] 2024-08-02 }
// [+][...] 2024-07-29 {
СчетчикФиксации = 0;
ИнтервалФиксации = ИнтервалИтерацииФиксации();
// } # [...] 2024-07-29 }
Пока СостояниеОчереди >= 1 Цикл
// [+][...] 2024-08-01 {
// Многопоточность, фиксация очереди
Очередь = Запрос.Выполнить().Выгрузить();
Если НЕ Очередь.Количество() Тогда
СостояниеОчереди = 0;
КонецЕсли;
// Получаем параметры потоков в каждой итерации
ПараметрыПотоков = МногопоточностьПараметрыПолучить();
Если ПараметрыПотоков.РаспределениеПотоки > 0 Тогда
ИмяМетода = "ОтметкиВремени.опт_ОчередьПоРегистрамРаспределить";
Параметры = Новый Структура;
Параметры.Вставить("Очередь", Очередь);
МассивЗаданий = Новый Массив;
опт_МногопоточнаяОбработка.ОтметкиВремениРаспределениеЗапустить(МассивЗаданий
, ПараметрыПотоков.РаспределениеПотоки
, Параметры
, ИмяМетода);
ТекстОшибки = опт_МногопоточнаяОбработка.Ожидать(МассивЗаданий);
Если ЗначениеЗаполнено(ТекстОшибки) Тогда
ВызватьИсключение ТекстОшибки;
КонецЕсли;
Иначе
опт_ОчередьПоРегистрамРаспределить(Очередь);
КонецЕсли;
Если ТолькоГраницу Тогда
Прервать;
КонецЕсли;
Если ПараметрыПотоков.ОчисткаПотоки > 0 Тогда
ИмяМетода = "ОтметкиВремени.опт_ОчередьОчистить";
Параметры = Новый Структура;
Параметры.Вставить("Очередь", Очередь);
Параметры.Вставить("ТолькоГраницу", ТолькоГраницу);
МассивЗаданий = Новый Массив;
опт_МногопоточнаяОбработка.ОтметкиВремениОчисткаЗапустить(МассивЗаданий
, ПараметрыПотоков.ОчисткаПотоки
, Параметры
, ИмяМетода);
ТекстОшибки = опт_МногопоточнаяОбработка.Ожидать(МассивЗаданий);
Если ЗначениеЗаполнено(ТекстОшибки) Тогда
ВызватьИсключение ТекстОшибки;
КонецЕсли;
Иначе
опт_ОчередьОчистить(Очередь, ТолькоГраницу);
КонецЕсли;
СчетчикФиксации = СчетчикФиксации + 1;
Если СчетчикФиксации = ИнтервалФиксации Тогда
опт_МониторнигОчередиОтметок.РазмерОчередиЗафиксировать();
СчетчикФиксации = 0;
КонецЕсли;
Если РежимОжидания Тогда
Если ВремяПерерыва = Неопределено Тогда
ВремяПерерыва = ТекущаяУниверсальнаяДата() + 3600;
КонецЕсли;
Если ТекущаяУниверсальнаяДата() >= ВремяПерерыва Тогда
Прервать;
КонецЕсли;
КонецЕсли;
// } # [...] 2024-08-01 }
КонецЦикла;
Набор = Неопределено;
ОтметкиВремениСсылочныхОбъектов = Неопределено;
ОтметкиВремениРегистровНезависимых = Неопределено;
ОтметкиВремениРегистровПодчиненных = Неопределено;
Если Очередь <> Неопределено Тогда
Очередь.Очистить();
КонецЕсли;
Если ОкнаОчереди <> Неопределено Тогда
ОкнаОчереди.Очистить();
КонецЕсли;
КонецПроцедурыВнедрение адаптивной многопоточности загрузки данных
Теперь перейдем к описанию доработок блока загрузки данных направленных на ускорение процесса миграции.
Схема оптимизации
Посмотрим схему оптимизированного алгоритма потока загрузки:

Улучшения и дополнительные регулировки:
- Регулировка количества сообщений на основной поток. Заменили жёстко зашитое ограничение в 2 сообщения на основной поток на настраиваемый параметр.
- Деление входной таблицы значений на порции. Ввиду того, что объём Таблицы значений может быть значительным (зависит от типа объекта и настроек порции в регистре «Переход. Объекты выгрузки» на стороне ДО2), а на размер параметров фонового задания есть ограничение в 1 ГБ (its.1c.ru/db/v8325doc#bookmark:dev:TI000000793), внедряем предварительное разбиение на порции, с возможностью регулирования размера порции.
- Многопоточная обработка таблицы значений. Добавили многопоточность с регулировкой количества потоков и ожиданием их завершения.
- Адаптивное управление количеством потоков. Добавили функционал, который при возникновении ошибок будет уменьшать число потоков на заданный шаг вплоть до одного, а при успешной работе — увеличивать их на заданный шаг увеличения до установленного порога.
Типовой метод загрузки
Загрузка данных Таблицы значений (Порция) производится в методе МиграцияДанныхИзВнешнихСистемСервер.ЗагрузитьПорцию():

Логика загрузки зависит от типа загружаемого Метаданного (Ссылочный, Регистры, Константы). В центре нашего внимания оказались методы ЗагрузитьПорциюСсылочныйОбъект() и ЗагрузитьПорциюРегистры(). Метод ЗагрузитьПорциюКонстанты() реализовывать многопоточно не стали, так как константы обрабатываются быстро.
Расширение типового метода загрузки данных
Для выбранных методов разработали функционал многопоточной обработки Таблицы значений (Порция) — в расширение добавили переопределение метода ЗагрузитьПорцию():
// Загрузить порцию. Порция - по сути таблица значений в памяти.
//
// Параметры:
// Метаданное - ОбъектМетаданных - Метаданное
// Порция - ТаблицаЗначений
// Замены - ТаблицаЗначений - Замены:
// * СтароеТип
// * Старое
// * Новое
// * Реквизиты
// Настройки - Структура, Неопределено - Настройки:
// * Поток - Число -
// * ИОМ - Соответствие -
// * Переименования - Соответствие -
// * УзелИсточник - СправочникСсылка.ИдентификаторыОбъектовМетаданных, СправочникСсылка.ИдентификаторыОбъектовРасширений, Произвольный, Null -
// ИмяОбъекта - Строка, Произвольный - Имя объекта
// ИмяИсточника - Строка - Имя источника
&Вместо("ЗагрузитьПорцию")
Процедура опт_ЗагрузитьПорцию(Метаданное, Порция, Замены, Настройки, ИмяОбъекта, ИмяИсточника) Экспорт
ЕстьУдаление = Порция.Колонки.Найти("_Удаление") <> Неопределено;
ПараметрыСеанса.ЗагрузкаОбработанныхДанныхИзДругойСистемы = Истина;
УдаленныеОбъекты = МиграцияДанныхИзВнешнихСистемДО21.УдаленныеОбъекты();
Если УдаленныеОбъекты.Получить(ИмяИсточника) <> Неопределено Тогда
Возврат;
КонецЕсли;
Если ЭтоСсылочныйОбъект(Метаданное) Тогда
// [+][... ] 2024-06-21 {
// Обработаем многопоточно опционально
Если ОбработатьМногопоточноСсылочные(Метаданное) Тогда
СсылочныеТипыМногопоточноОбработать(Метаданное
, Порция
, Замены
, Настройки
, ИмяОбъекта
, ИмяИсточника
, ЕстьУдаление);
Иначе
ЗагрузитьПорциюСсылочныйОбъект(Метаданное, Порция, Замены, Настройки, ИмяОбъекта, ИмяИсточника, ЕстьУдаление);
КонецЕсли;
// } # [... ] 2024-06-21 }
ИначеЕсли Метаданные.Константы.Содержит(Метаданное) Тогда
ЗагрузитьПорциюКонстанты(Метаданное, Порция, Замены, Настройки, ИмяОбъекта, ИмяИсточника, ЕстьУдаление);
Иначе
//Регистры
Если ОбработатьМногопоточноРегистры(Метаданное) Тогда
РегистрыМногопоточноОбработать(Метаданное
, Порция
, Замены
, Настройки
, ИмяОбъекта
, ИмяИсточника
, ЕстьУдаление);
Иначе
ЗагрузитьПорциюРегистры(Метаданное, Порция, Замены, Настройки, ИмяОбъекта, ИмяИсточника, ЕстьУдаление);
КонецЕсли;
КонецЕсли; // тип метаданного
КонецПроцедурыМетоды проверки включенной опции многопоточной обработки
Для каждого метода загрузки:
- ЗагрузитьПорциюСсылочныйОбъект()
- ЗагрузитьПорциюРегистры()
реализована отдельная опция проверки включенной многопоточности. При отсутствии настроек или при значении количества потоков = 0 обработка остаётся в стандартном режиме:
// Истина, если обрабатывать многопоточно ссылочные типы
//
// Параметры:
// Метаданное - ОбъектМетаданных - Метаданное
//
// Возвращаемое значение:
// Булево
//
Функция ОбработатьМногопоточноСсылочные(Метаданное)
Результат = Ложь;
ИдентфикаторКолВоПотоков = "КоличествоПотоковЗаписиСсылочныхОбъектов";
Если из_Привязка.Существует(ИдентфикаторКолВоПотоков)
И из_Привязка.Получить(ИдентфикаторКолВоПотоков) > 0
И опт_МногопоточнаяОбработка.Разрешить(Метаданное) Тогда
Результат = Истина;
КонецЕсли;
Возврат Результат;
КонецФункции // ОбработатьМногопоточноСсылочные()
// Истина, если обрабатывать многопоточно регистры
//
// Параметры:
// Метаданное - ОбъектМетаданных - Метаданное
//
// Возвращаемое значение:
// Булево
//
Функция ОбработатьМногопоточноРегистры(Метаданное)
Результат = Ложь;
ИдентфикаторКолВоПотоков = "КоличествоПотоковЗаписиРегистров";
Если из_Привязка.Существует(ИдентфикаторКолВоПотоков)
И из_Привязка.Получить(ИдентфикаторКолВоПотоков) > 0
И опт_МногопоточнаяОбработка.Разрешить(Метаданное) Тогда
Результат = Истина;
КонецЕсли;
Возврат Результат;
КонецФункции // ОбработатьМногопоточноРегистры()Не для всех типов объектов многопоточная загрузка проходит гладко. В ряде случаев это приводит к конфликтам блокировок. Например, в нашем случае при загрузке Справочники.ПрофилейГруппДоступа возникали ошибки, из-за того что в параллельные потоки попадали частично пересекающиеся по данным объекты:

Поэтому дополнительно внесли возможность отключать параллельную обработку для таких проблемных объектов на уровне типов объекта метаданных с помощью привязки «ИдентификаторыОбъектовМетаданныхМногопоточностьИсключить». Проверка разрешения на использование многопоточности осуществляется через метод опт_МногопоточнаяОбработка.Разрешить():
// Истина, если обрабатывать многопоточно
//
// Параметры:
// Источник - Метаданные - Источник
//
// Возвращаемое значение:
// Булево
//
Функция Разрешить(Источник) Экспорт
Результат = Истина;
ИдентификаторПривязки = "ИдентификаторыОбъектовМетаданныхМногопоточностьИсключить";
Если НЕ из_Привязка.Существует(ИдентификаторПривязки) Тогда
Возврат Результат;
КонецЕсли;
КоллекцияИдентификаторов = из_Привязка.Получить(ИдентификаторПривязки);
КоллекцияСравнить = Новый Соответствие;
Если ТипЗнч(КоллекцияИдентификаторов) <> Тип("СписокЗначений") Тогда
КоллекцияСравнить.Вставить(КоллекцияИдентификаторов, Истина);
Иначе
Для каждого Элемент Из КоллекцияИдентификаторов Цикл
КоллекцияСравнить.Вставить(Элемент.Значение, Истина);
КонецЦикла;
КонецЕсли;
ИсточникТипИмя = Источник.ПолноеИмя();
Если КоллекцияСравнить.Получить(ИсточникТипИмя) = Истина Тогда
Результат = Ложь;
КонецЕсли;
Возврат Результат;
КонецФункции // РазрешитьПример заполненной коллекции исключения объектов из многопоточности:

На основе этой коллекции регулируем применение многопоточности для загружаемых объектов.
Метод деления на порции данных Таблицы значений
Делит таблицу значений на порции по настройке «Миграция_РазмерПорции»:
// Возвращает наборы порций
//
// Параметры:
// Источник - ТаблицаЗначений - Источник
//
// Возвращаемое значение:
// Массив - Набор порций таблицы значений
//
Функция ДанныеНаПорцииРазделить(Источник)
РазмерПорции = из_Привязка.Получить("Миграция_РазмерПорции");
НаборПорций = Новый Массив;
ПорцияТаблица = Источник.СкопироватьКолонки();
Для каждого СтрПорц Из Источник Цикл
НоваяСтрока = ПорцияТаблица.Добавить();
ЗаполнитьЗначенияСвойств(НоваяСтрока, СтрПорц);
Если ПорцияТаблица.Количество() = РазмерПорции Тогда
НаборПорций.Добавить(ПорцияТаблица);
ПорцияТаблица = Источник.СкопироватьКолонки();
КонецЕсли;
КонецЦикла;
// Остатки
Если ПорцияТаблица.Количество() Тогда
НаборПорций.Добавить(ПорцияТаблица);
КонецЕсли;
Возврат НаборПорций;
КонецФункции // ДанныеНаПорцииРазделить()Методы подготовки к запуску многопоточной обработки для ссылочных типов
Для корректной передачи в фоновые задания изменили несериализуемые параметры. В обычном методе использовался параметр Метаданное с типом ОбъектМетаданных, мы заменили его на строковое представление метаданных. По схожей причине параметр «Замены» помещаем в хранилище значения, так как в нём передается таблица значений, в столбцах которой могут быть несериализуемые значения.
Помимо этого добавили контроль за запущенными потоками и при обнаружении ошибок в любом из них вызываем исключение — это приводит к прерыванию основного потока загрузки. Если прерывание не выполнять, алгоритм завершит обработку и удалит файл — данные, которые не успели загрузиться в аварийных потоках, будут потеряны.
// Многопоточная обработка ссылочных типов
//
Процедура СсылочныеТипыМногопоточноОбработать(Метаданное, Порция, Замены, Настройки, ИмяОбъекта, ИмяИсточника, ЕстьУдаление)
НаборПорций = ДанныеНаПорцииРазделить(Порция);
ИдентфикаторКолВоПотоков = "КоличествоПотоковЗаписиСсылочныхОбъектов";
КоличествоПотоков = из_Привязка.Получить(ИдентфикаторКолВоПотоков);
// Запускаем разбитые наборы порций в обработку
Для Каждого Набор Из НаборПорций Цикл
ИмяМетода = "МиграцияДанныхИзВнешнихСистемСервер.опт_ЗагрузитьПорциюСсылочныйОбъект";
Параметры = Новый Структура;
Параметры.Вставить("МетаданноеИмя", Метаданное.ПолноеИмя());
Параметры.Вставить("Набор" , Набор);
Параметры.Вставить("Замены " , Новый ХранилищеЗначения(Замены));
Параметры.Вставить("Настройки" , Настройки);
Параметры.Вставить("ИмяОбъекта" , ИмяОбъекта);
Параметры.Вставить("ИмяИсточника" , ИмяИсточника);
Параметры.Вставить("ЕстьУдаление" , ЕстьУдаление);
МассивЗаданий = Новый Массив;
опт_МногопоточнаяОбработка.Запустить(МассивЗаданий, КоличествоПотоков, Параметры
, ИмяМетода);
ТекстОшибки = опт_МногопоточнаяОбработка.Ожидать(МассивЗаданий);
ПривязкиПотоковАвтоопределить(ТекстОшибки);
Если ЗначениеЗаполнено(ТекстОшибки) Тогда
ВызватьИсключение ТекстОшибки;
КонецЕсли;
КонецЦикла;
КонецПроцедуры // СсылочныеТипыМногопоточноОбработать()И соответственно саму обработку набора запускаем в параллельных потоках, предварительно конвертируя параметр Порция в ХранилищеЗначения, как это было выше с параметром «Замены»:
// Запускает многопоточную обработку
//
// Параметры:
// Задания - Массив - Массив идентфикаторов фоновых, заполняется по мере запуска
// КоличествоПотоков - Число - Количество потоков
// Параметры - Структура - Параметры фонового задания
// МетодаИмя - Строка - Имя метода
//
Процедура Запустить(Задания, КоличествоПотоков, Параметры, МетодаИмя) Экспорт
МетаданноеИмя = Параметры.МетаданноеИмя;
Набор = Параметры.Набор;
Замены = Параметры.Замены;
Настройки = Параметры.Настройки;
ИмяОбъекта = Параметры.ИмяОбъекта;
ИмяИсточника = Параметры.ИмяИсточника;
ЕстьУдаление = Параметры.ЕстьУдаление;
ДанныеКоличество = Набор.Количество();
Размер = ДанныеКоличество / КоличествоПотоков;
ПорцияРазмер = ?(Размер = Цел(Размер), Размер, Цел(Размер) + 1);
ПредставлениеЗадания = СтрШаблон("Загрузка объектов по метаданному: %1 (Миграция)"
, МетаданноеИмя);
ПорцияЗадания = Набор.СкопироватьКолонки();
Для Каждого Строка Из Набор Цикл
НоваяСтрока = ПорцияЗадания.Добавить();
ЗаполнитьЗначенияСвойств(НоваяСтрока, Строка);
Если ПорцияЗадания.Количество() = ПорцияРазмер Тогда
ПараметрыМетода = Новый Массив;
ПараметрыМетода.Добавить(Новый Структура("МетаданноеИмя", МетаданноеИмя));
ПараметрыМетода.Добавить(Новый Структура("Порция" , Новый ХранилищеЗначения(ПорцияЗадания)));
ПараметрыМетода.Добавить(Новый Структура("Замены" , Замены));
ПараметрыМетода.Добавить(Новый Структура("Настройки" , Настройки));
ПараметрыМетода.Добавить(Новый Структура("ИмяОбъекта" , ИмяОбъекта));
ПараметрыМетода.Добавить(Новый Структура("ИмяИсточника" , ИмяИсточника));
ПараметрыМетода.Добавить(Новый Структура("ЕстьУдаление" , ЕстьУдаление));
Задания.Добавить(ФоновоеЗапустить(МетодаИмя, ПараметрыМетода, , ПредставлениеЗадания));
ПорцияЗадания = Набор.СкопироватьКолонки();
КонецЕсли;
КонецЦикла;
// Остатки
Если ПорцияЗадания.Количество() Тогда
ПараметрыМетода = Новый Массив;
ПараметрыМетода.Добавить(Новый Структура("МетаданноеИмя", МетаданноеИмя));
ПараметрыМетода.Добавить(Новый Структура("Порция" , Новый ХранилищеЗначения(ПорцияЗадания)));
ПараметрыМетода.Добавить(Новый Структура("Замены" , Замены));
ПараметрыМетода.Добавить(Новый Структура("Настройки" , Настройки));
ПараметрыМетода.Добавить(Новый Структура("ИмяОбъекта" , ИмяОбъекта));
ПараметрыМетода.Добавить(Новый Структура("ИмяИсточника" , ИмяИсточника));
ПараметрыМетода.Добавить(Новый Структура("ЕстьУдаление" , ЕстьУдаление));
Задания.Добавить(ФоновоеЗапустить(МетодаИмя, ПараметрыМетода, , ПредставлениеЗадания));
КонецЕсли;
КонецПроцедуры //Основной метод загрузки данных выполняемый в фоновом задании
Модифицировали метод ЗагрузитьПорциюСсылочныйОбъект(): сделали экспортным для обеспечения возможности запуска его в фоновом задании. В начале выполнения метода установили специализированный параметр сеанса «ЗагрузкаОбработанныхДанныхИзДругойСистемы», необходимый для корректной работы всего механизма.
Далее выполнили обратное преобразование параметров — получается объект метаданных и содержимое, переданное в ХранилищеЗначения, восстанавливается в рабочий формат ТаблицыЗначений:
// Загрузить порцию ссылочного типа. Порция - по сути таблица значений в памяти.
//
// Параметры:
// МетаданноеИмя - Строка - Метаданное Имя
// Порция - ХранилищеЗначений
// Замены - ХранилищеЗначений
// * СтароеТип
// * Старое
// * Новое
// * Реквизиты
// Настройки - Структура, Неопределено - Настройки:
// * Поток - Число -
// * ИОМ - Соответствие -
// * Переименования - Соответствие -
// * УзелИсточник - СправочникСсылка.ИдентификаторыОбъектовМетаданных, СправочникСсылка.ИдентификаторыОбъектовРасширений, Произвольный, Null -
// ИмяОбъекта - Строка, Произвольный - Имя объекта
// ИмяИсточника - Строка - Имя источника
// ЕстьУдаление - Булево - есть ли удаление
//
Процедура опт_ЗагрузитьПорциюСсылочныйОбъект(МетаданноеИмя, Порция, Замены, Настройки, ИмяОбъекта, ИмяИсточника, ЕстьУдаление) Экспорт
// [+][...] 2024-06-21 {
// Установим параметр сеанса как в методе ЗагрузитьПорцию()
// иначе проверки не пропустят запись объектов
ПараметрыСеанса.ЗагрузкаОбработанныхДанныхИзДругойСистемы = Истина;
// Преобразуем обратно параметры
// Получим обратно таблицу значений
Порция = Порция.Получить();
Замены = Замены.Получить();
// Получим метаданное по имени
Метаданное = Метаданные.НайтиПоПолномуИмени(МетаданноеИмя);
// } # [...] 2024-06-21 }
ПараметрыМетаданного = ЗаполнитьКешМетаданных(Метаданное, Порция, Настройки, ИмяОбъекта);
Изменения = Новый ТаблицаЗначений;
// сперва пробуем все сразу получить изменения
НачатьТранзакцию();
Попытка
Изменения = ОтметкиВремени.ПроверитьИзменения(Порция, Метаданное, Настройки.УзелИсточник);
ЗафиксироватьТранзакцию();
Исключение
ОтменитьТранзакцию();
Причина = ПодробноеПредставлениеОшибки(ИнформацияОбОшибке());
Изменения = Новый ТаблицаЗначений;
КонецПопытки;
Для Каждого Источник Из Порция Цикл
.......
КонецЦикла;
КонецПроцедурыМетод ожидания завершения потоков
Ожидает выполнения запущенных заданий и, при обнаружении аварийно завершённых или прерванных заданий, прекращает ожидание и возвращает описание ошибки фонового задания:
// Ожидает завершения потоков
//
// Параметры:
// МассивЗаданий - Массив - Массив идентфикаторов фоновых, заполняется по мере запуска
//
Функция Ожидать(МассивЗаданий) Экспорт
Если МассивЗаданий.Количество() = 0 Тогда
Возврат Неопределено;
КонецЕсли;
ОшибкаЭто = Ложь;
ОжидатьФЗ = Истина;
ТекстОшибки = Неопределено;
Пока ОжидатьФЗ Цикл
Попытка
ФоновыеТекущие = ФоновыеЗадания.ОжидатьЗавершенияВыполнения(МассивЗаданий);
КоллекцияАктивно = Новый Соответствие;
Для каждого ТекФоновое Из ФоновыеТекущие Цикл
КоллекцияАктивно.Вставить(ТекФоновое.Состояние = СостояниеФоновогоЗадания.Активно, 1);
Если ТекФоновое.Состояние = СостояниеФоновогоЗадания.ЗавершеноАварийно
ИЛИ ТекФоновое.Состояние = СостояниеФоновогоЗадания.Отменено Тогда
ОжидатьФЗ = Ложь;
ТекстОсновной = "Задание завершено аварийно или отменено" + Символы.ПС;
ТекстОшибки = ТекстОсновной + ПодробноеПредставлениеОшибки(ТекФоновое.ИнформацияОбОшибке);
ОшибкаЭто = Истина;
КонецЕсли;
КонецЦикла;
Если КоллекцияАктивно.Количество() = 1 Тогда
ОжидатьФЗ = КоллекцияАктивно.Получить(Истина) = 1;
КонецЕсли;
Исключение
ОшибкаЭто = Истина;
ТекстОшибки = Строка(ПодробноеПредставлениеОшибки(ИнформацияОбОшибке()));
ЗаписьЖурналаРегистрации("Миграция.МногопоточнаяЗагрузка"
, УровеньЖурналаРегистрации.Ошибка
,
,
, СтрШаблон("Во время загрузки данных произошла ошибка: %1", ТекстОшибки));
ОжидатьФЗ = Ложь;
КонецПопытки;
КонецЦикла;
Возврат ТекстОшибки;
КонецФункции // ОжидатьМетод адаптивной регулировки потоков
Метод увеличивает или уменьшает число потоков на шаги, заданные в настройках привязок, при этом не выходя за установленные пределы:
// Автоматически устанавливает количество потоков
//
// Параметры:
// ТекстОшибки - Строка - Текст ошибки
// РегистрыЭто - Булево - Признак регистров
//
Процедура ПривязкиПотоковАвтоопределить(ТекстОшибки, РегистрыЭто = Ложь)
ПорогПотоков = из_Привязка.Получить("ПорогПотоков");
ШагПотоков = из_Привязка.Получить("ШагПотоков");
ШагПотоковУменьшение = из_Привязка.Получить("ШагПотоковУменьшение");
КоличествоПотоковМиграции = из_Привязка.Получить("КоличествоПотоковМиграции");
ПорогОсновныхПотоков = из_Привязка.Получить("ПорогОсновныхПотоков");
Если ПорогПотоков = 0 Тогда
Возврат;
КонецЕсли;
УвеличитьПотоки = Ложь;
Если ТекстОшибки = Неопределено Тогда
УвеличитьПотоки = Истина;
КонецЕсли;
ИдентификаторКоличествоДочернихПотоков = Неопределено;
Если РегистрыЭто Тогда
ИдентификаторКоличествоДочернихПотоков = "КоличествоПотоковЗаписиРегистров";
Иначе
ИдентификаторКоличествоДочернихПотоков = "КоличествоПотоковЗаписиСсылочныхОбъектов";
КонецЕсли;
КоличествоДочернихПотоков = из_Привязка.Получить(ИдентификаторКоличествоДочернихПотоков);
Если УвеличитьПотоки Тогда
КоличествоДочернихПотоков = КоличествоДочернихПотоков + ШагПотоков;
Если КоличествоДочернихПотоков >= ПорогПотоков Тогда
КоличествоДочернихПотоков = ПорогПотоков;
КонецЕсли;
КоличествоПотоковМиграции = КоличествоПотоковМиграции + 1;
Если КоличествоПотоковМиграции >= ПорогОсновныхПотоков Тогда
КоличествоПотоковМиграции = ПорогОсновныхПотоков;
КонецЕсли;
ЗаписьЖурналаРегистрации("АдаптивностьПотоков.Увеличение", УровеньЖурналаРегистрации.Предупреждение
,,, СтрШаблон("Основные потоки: %1, дочерние потоки: %2, для регистров: %3"
, КоличествоПотоковМиграции
, КоличествоДочернихПотоков
, РегистрыЭто));
Иначе
КоличествоДочернихПотоков = КоличествоДочернихПотоков - ШагПотоковУменьшение;
Если КоличествоДочернихПотоков <= 1 Тогда
КоличествоДочернихПотоков = 1;
КонецЕсли;
КоличествоПотоковМиграции = КоличествоПотоковМиграции - 1;
Если КоличествоПотоковМиграции <= 1 Тогда
КоличествоПотоковМиграции = 1;
КонецЕсли;
ЗаписьЖурналаРегистрации("АдаптивностьПотоков.Уменьшение", УровеньЖурналаРегистрации.Предупреждение
,,, СтрШаблон("Основные потоки: %1, дочерние потоки: %2, для регистров: %3"
, КоличествоПотоковМиграции
, КоличествоДочернихПотоков
, РегистрыЭто));
КонецЕсли;
из_Привязка.Установить(ИдентификаторКоличествоДочернихПотоков
, КоличествоДочернихПотоков);
из_Привязка.Установить("КоличествоПотоковМиграции", КоличествоПотоковМиграции);
КонецПроцедуры // ПривязкиПотоковАвтоопределить()Доработка метода основного потока загрузки
Добавили регулировку количества основных потоков и сообщений на поток:
&Вместо("Загрузка")
Процедура опт_Загрузка(Поток = 0, Настройки = Неопределено) Экспорт
УстановитьПривилегированныйРежим(Истина);
Если Настройки = Неопределено Тогда
Настройки = КэшНастроек();
КонецЕсли;
Настройки.Поток = Поток;
ТекДата = ТекущаяУниверсальнаяДата();
ВремяОбновления = ТекДата + 60;
ВремяПерерыва = ТекДата + 3600;
ИДБлокировки = Новый УникальныйИдентификатор();
КлючБлокировки = Новый Структура("Сеанс");
Если Поток = 0 Тогда
//Все в текущем сеансе.
ЛимитЗаданий = 1;
Порция = 100;
ИначеЕсли ОбщегоНазначения.ИнформационнаяБазаФайловая() Тогда
ЛимитЗаданий = 1;
Порция = 100;
Иначе
ЛимитЗаданий = 5;
СообщенийНаЗадание = 2;
МетодЗадания = "МиграцияДанныхИзВнешнихСистемСервер.Загрузка";
// [+] #* [...] 2024-06-21 {
// Для пользователей строго в одном потоке.
НастройкиПотоковПереопределить(ЛимитЗаданий, СообщенийНаЗадание);
// } #* [...] 2024-06-21 }
Порция = ЛимитЗаданий * СообщенийНаЗадание;
КонецЕсли;
...........................
КонецПроцедурыМетод переопределения настроек потока:
// Переопределяет типовые настройки запуска потоков
//
// Параметры:
// ЛимитЗаданий - Число - Лимит потоков
// СообщенийНаЗадание - Число - Сообщение на задание
//
Процедура НастройкиПотоковПереопределить(ЛимитЗаданий, СообщенийНаЗадание)
ИДКоличествоПотоковМиграции = "КоличествоПотоковМиграции";
ИДСообщенийНаЗаданиеМиграция = "СообщенийНаЗаданиеМиграция";
Если из_Привязка.Существует(ИДКоличествоПотоковМиграции) Тогда
КолПотоки = из_Привязка.Получить(ИДКоличествоПотоковМиграции);
Если КолПотоки > 0 Тогда
ЛимитЗаданий = КолПотоки;
КонецЕсли;
КонецЕсли;
Если из_Привязка.Существует(ИДСообщенийНаЗаданиеМиграция) Тогда
КолСообщ = из_Привязка.Получить(ИДСообщенийНаЗаданиеМиграция);
Если КолСообщ > 0 Тогда
СообщенийНаЗадание = КолСообщ;
КонецЕсли;
КонецЕсли;
КонецПроцедуры // НастройкиПотоковПереопределитьОптимизация загрузки связей
В ходе тестирования вышеуказанных работ также выявлено одно узкое место — это запись объекта РегистрСведений.СвязиОбъектов. По замерам она оказалась крайне медленная (до 50 минут на 10 000 записей), а также периодически возникали взаимоблокировки, один из примеров:
ОптимизацияМиграции ОбщийМодуль.МиграцияДанныхИзВнешнихСистемСервер.Модуль : 662 : МиграцияДанныхИзВнешнихСистемДО21.ЗагрузкаДанных_ДО8_2_1(
ОбщийМодуль.МиграцияДанныхИзВнешнихСистемДО21.Модуль : 345 : КонвертацияСвязейОбъектов(
ОбщийМодуль.МиграцияДанныхИзВнешнихСистемДО21.Модуль : 3009 : СвязиОбъектов.ОбновитьСведенияОСвязяхВДанныхДокументов(Источник.Объект);
ОбщийМодуль.СвязиОбъектов.Модуль : 1278 : Блокировка.Заблокировать();'
Взаимоблокировка возникла на блокировках по измерениям регистра:
- Fld10435 — Объект.
- Fld10436 — ТипСвязи.
- Fld10437 — СвязанныйОбъект.
Подробно на расследовании мы останавливаться не будем. Проведенный анализ этих взаимоблокировок, основанный на ранее рассмотренных методиках, однозначно показал, что причина заключается в разном порядке захвата ресурсов параллельными потоками. Поскольку исходные данные поступают в виде ТаблицыЗначений, порядок элементов в которой после сериализации является произвольным, это создает условия для возникновения взаимоблокировок при одновременной попытке доступа и модификации записей.
Сначала мы решили, что для устранения этих взаимоблокировок достаточно предварительно отсортировать ТаблицуЗначений по ключевым полям Объект, ТипСвязи, СвязанныйОбъект перед передачей ее в многопоточную обработку.
Для этого в ранее разработанный метод РегистрыМногопоточноОбработать() добавили вызов новой процедуры сортировки:
// Сортировка для объектов Связи документов, для избежания конфликта блокировок
//
// Параметры:
// Метаданное - ОбъектМетаданных - Метаданное
// Порция - ТаблицаЗначений
//
Процедура ПорцияОбъектСвязиДокументовСортировать(Метаданное, Порция)
Если Метаданное.ПолноеИмя() <> "РегистрСведений.СвязиОбъектов" Тогда
Возврат;
КонецЕсли;
Если Порция.Колонки.Найти("Документ") = Неопределено
И Порция.Колонки.Найти("СвязанныйДокумент") = Неопределено Тогда
Возврат;
КонецЕсли;
Порция.Сортировать("Документ, ТипСвязи, СвязанныйДокумент");
КонецПроцедуры // ПорцияОбъектСвязиДокументовСортировать()Однако, хоть после этой доработки конфликтов блокировок мы больше не обнаружили, но скорость загрузки порций осталась прежней.
По замерам приличное время занимал метод СвязиОбъектов.ОбновитьСведенияОСвязяхВДанныхДокументов(); поэтому мы решили его исследовать. Рассмотрим код метода:
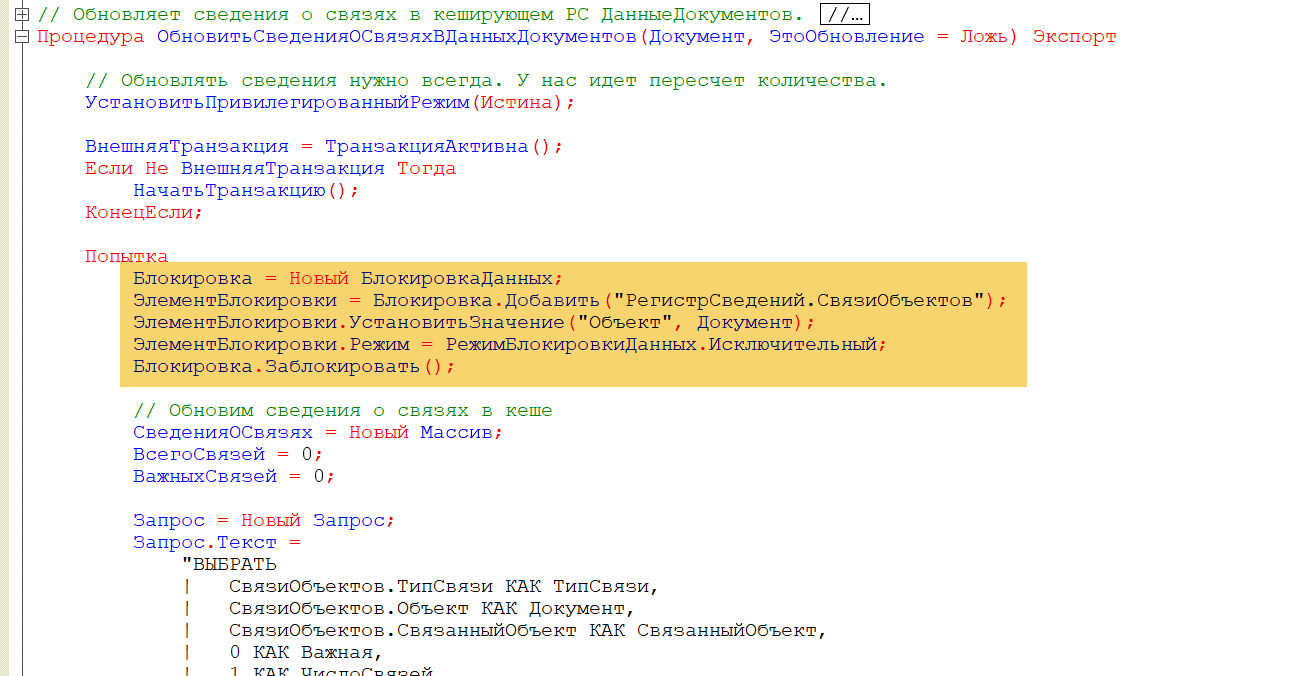
Сразу бросается в глаза, что записи РегистрСведений.СвязиОбъектов блокируются по полю «Объект», которое, по сути, является ключевым родительским идентификатором. Поскольку у одного «родителя» часто много «потомков», многопоточная загрузка приводит к тому, что остальные потоки неизбежно простаивают, ожидая захвата ресурса по этому «Объекту». Таким образом, многопоточность не дает ускорения для данного регистра.
Возникает вопрос: стоит ли просто отключить многопоточность для этого объекта? Нет, это было бы слишком простым, но не оптимальным решением. Кроме того, этот метод используется и при загрузке документов и также занимает приличное время.
Из описания назначение данного метода: «Обновление сведений о связях в кэширующем регистре ДанныеДокументов». И если чуть вникнуть в логику метода, видно что там происходит актуализация реквизитов КоличествоВажныхСвязей и КраткиеСведенияОСвязях в регистре сведений ДанныеДокументовПредприятия, с отбором по документу.
Мы решили, что это не обязательно делать синхронно с загрузкой объектов, поэтому в качестве оптимизации предложили вынести этот метод для отложенного выполнения, которое будет запускаться регламентным заданием по расписанию.
При этом при загрузке самих связей объектов мы будем блокировать выполнение данного рег. задания. Тем самым мы минимизируем или даже сведём к нулю пересекающиеся блокировки и значительно ускорим весь процесс.
Что для этого нужно:
Добавим регистр сведений очереди:

- УникальныйИдентификатор — для избежания длительных блокировок при параллельной записи в очередь.
- Родитель — Объект родитель загружаемой связи из контекста загрузки.
Переопределим в расширении метод ОбновитьСведенияОСвязяхВДанныхДокументов():
&Вместо("ОбновитьСведенияОСвязяхВДанныхДокументов")
КонецПроцедуры
Процедура опт_ОбновитьСведенияОСвязяхВДанныхДокументов(Документ, ЭтоОбновление)
// На момент миграции переносим в отложенное обновление
// во избежание длительных ожиданий при блокировке Родителя
УидЗаписи = Новый УникальныйИдентификатор();
НаборЗаписей = РегистрыСведений.опт_ОчередьОбновленияСведенийСвязей.СоздатьНаборЗаписей();
НаборЗаписей.Отбор.УникальныйИдентификатор.Установить(УидЗаписи);
НаборЗаписей.Отбор.Родитель.Установить(Документ);
Запись = НаборЗаписей.Добавить();
Запись.УникальныйИдентификатор = УидЗаписи;
Запись.Родитель = Документ;
НаборЗаписей.Записать();
В контексте загрузки будем просто наполнять очередь.
Добавим регламентное задание «Отложенное обновление сведений связей» и его обработчик, который будет обрабатывать записи порционно:
// Обновляет сведения связей отложенно
КонецПроцедуры // СвязиСведенияОбновить()
//
Процедура СвязиСведенияОбновить() Экспорт
ИмяЗадания = "Загрузка объектов по метаданному: РегистрСведений.СвязиОбъектов (Миграция)";
ПараметрыОтбора = Новый Структура("Наименование, Состояние"
, ИмяЗадания, СостояниеФоновогоЗадания.Активно);
Если ФоновыеЗадания.ПолучитьФоновыеЗадания(ПараметрыОтбора).Количество() Тогда
// Во избежание избыточных ожиданий прерываем обработку
Возврат;
КонецЕсли;
Запрос = Новый Запрос("ВЫБРАТЬ ПЕРВЫЕ 1000
| Т.УникальныйИдентификатор КАК УникальныйИдентификатор,
| Т.Родитель КАК Родитель
|ИЗ
| РегистрСведений.опт_ОчередьОбновленияСведенийСвязей КАК Т
|ГДЕ
| Т.КоличествоПопыток < 5");
Выборка = Запрос.Выполнить().Выбрать();
Пока Выборка.Следующий() Цикл
Попытка
СвязиОбъектов.опт_ОбновитьСведенияОСвязяхВДанныхДокументовОтложенно(Выборка.Родитель);
РегистрыСведений.опт_ОчередьОбновленияСведенийСвязей
.РезультатЗаписать(Выборка.УникальныйИдентификатор
, Выборка.Родитель);
Исключение
ТекстОшибок = ПодробноеПредставлениеОшибки(ИнформацияОбОшибке());
РегистрыСведений.опт_ОчередьОбновленияСведенийСвязей
.РезультатЗаписать(Выборка.УникальныйИдентификатор
, Выборка.Родитель
, Новый Структура("ТекстОшибок", ТекстОшибок));
КонецПопытки;
КонецЦикла;
На этом описание доработок оптимизации завершаем и переходим к результатам.
Результаты оптимизации
По итогу всех проведенных работ нам удалось преодолеть «кризис» замедления процесса миграции, избавиться от взаимоблокировок и получить приличный прирост производительности!
Если говорить про реальный проект с 27 млн. записей загружаемых данных, это позволило нам «уложиться» в отведенный срок в две недели, тогда как до доработок пробная миграция за 30 дней достигла только 80% прогресса.
Однако вопросы касающиеся миграции на продуктивном контуре мы постараемся изложить в следующей части статьи. А сейчас для того, чтобы наглядно показать разницу, мы повторили этот опыт до и после оптимизаций на специальном тестовом стенде на демо базе с 4 млн записей.
Результаты оптимизации на тестовой исследуемой базе
Сравнительный анализ показал, что благодаря оптимизации время миграции сократилось с 83 до 35 часов, то есть в ~2.4 раза.
Графики размеров очереди и количества загруженных данных:
-
До оптимизации (общее время 83 часа):
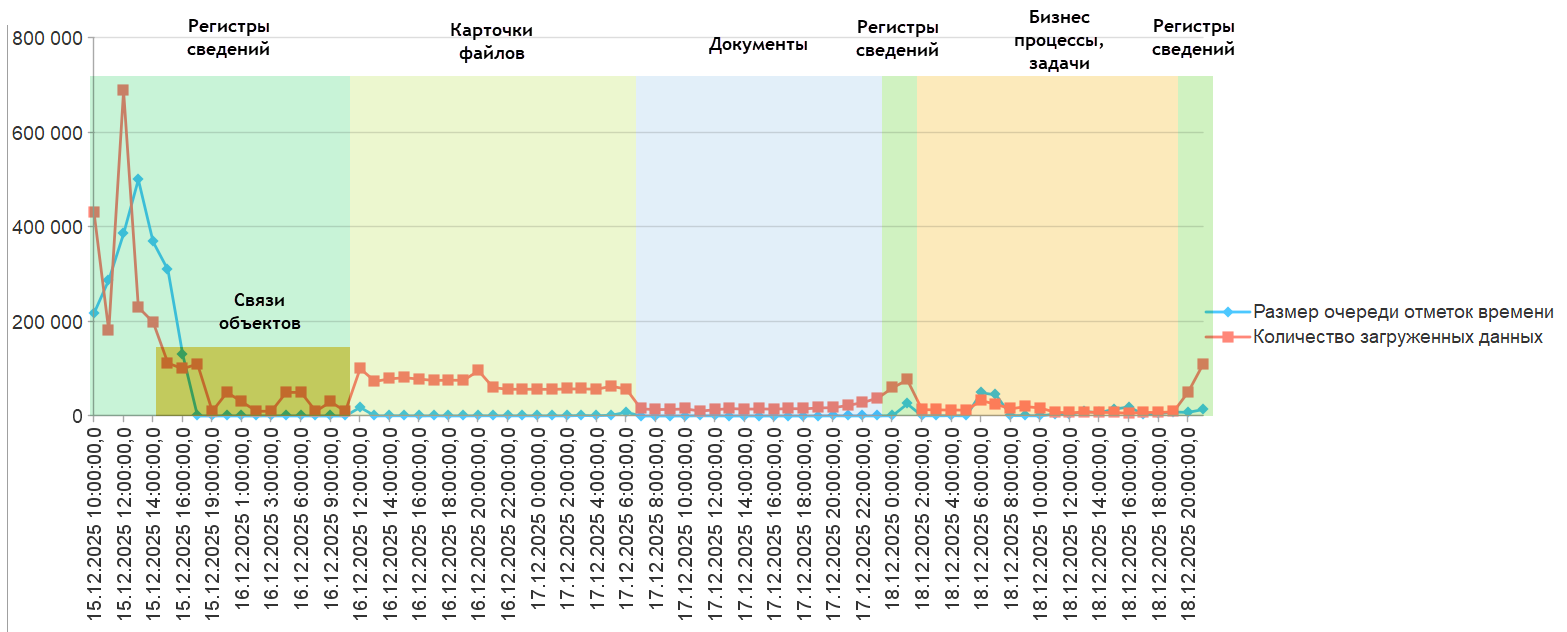
-
После оптимизации (Общее время 35 часов):

Здесь хотим обратить ваше внимание на следующие моменты:
- Изменения длительности этапов. Например:
- карточки файлов до изменений грузились 18 часов, после — 8 часов;
- документы до изменений — 15 часов, после — 7 часов.
- и т. д.
- Пик размера очереди отметок (синий график) в начале миграции — до изменений он доходил до 500 тыс., после оптимизации — 250 тыс. Это неочевидный и важный момент, по нашим данным этот этап нелинейно зависит от количества данных и на крупной базе очередь может достигнуть неподъемных размеров. О динамике разбора очереди поговорим чуть ниже.
Ключевые улучшения
-
Дополнительная многопоточность.
Внедрение дополнительных механизмов параллельной обработки значительно ускорило выполнение загрузки.
Пример динамики загрузки объекта Справочник.ВерсииФайлов.
Без доработок оптимизации было в среднем 700-1900 объектов в минуту:

С доработками оптимизации стало 1000-5000 объектов в минуту:

Пример динамики загрузки объекта Справочник.ВнутренниеДокументы.
-
Без доработок оптимизации было в среднем 100-400 объектов в минуту:

-
С доработками оптимизации стало 500-1000 объектов в минуту:

На представленных выше графиках можно наблюдать некую «зигзагообразность», полагаем минимальные значения динамики определяют периоды считывания файлов сообщений, непосредственно предшествующие запуску конвертации объектов. Эти снижения возникают в момент завершения обработки очередной порции файлов сообщений, перед тем как система переходит к следующему отбору сообщений.
Расшивание обработки отметок при загрузке и устранение конфликтов блокировок.
Исключены взаимоблокировки на этапе загрузки данных связей объектов и при обработке очереди отметок времени, что стабилизировало процесс. Исключение из контекста загрузки обработку очереди отметок времени (Особенности первого потока) обеспечило непрерывную загрузку.
Посмотрим подробнее на график размера очереди.
До изменений:

Во-первых, здесь можно заметить тенденцию к росту, как полагаем, это означает, что система как будто не справляется с потоком очереди отметок. По нашим данным до оптимизации очередь доходила максимум до 500 тыс. записей. Но это на тестовой демо-базе, на реальном проекте с большим количеством данных очередь может доходить до миллионов.
Также на графике нельзя не заметить характерные «провалы». И если повнимательней присмотреться к отсечкам времени в одном из них видно, что он длился около часа, получается именно столько «простаивал» первый поток при загрузке очереди отметок.

После оптимизации график стал не просто более плавный, а в принципе не содержит подобных разрывов длиной в час. При этом максимальный размер очереди не превысил 300 тыс. записей:

Адаптивное управление потоками.
Реализована адаптивная регулировка количества потоков и размера порций для обработки отметок времени, обеспечивающая непрерывность и высокую эффективность загрузки данных, особенно в ночное время. Не обязательно всё время контролировать процесс, система сама уменьшит количество потоков в случае ошибок и увеличит обратно в случае стабильной загрузки.
Оптимизация РегистрСведений.СвязиОбъектов.
Доработка механизма отложенного обновления сведений о связях объектов значительно увеличила скорость загрузки РегистрСведений.СвязиОбъектов, который ранее был одним из «узких мест» процесса миграции.
Замеры среднего времени загрузки без доработок оптимизации:

Замеры среднего времени загрузки с доработками оптимизации:
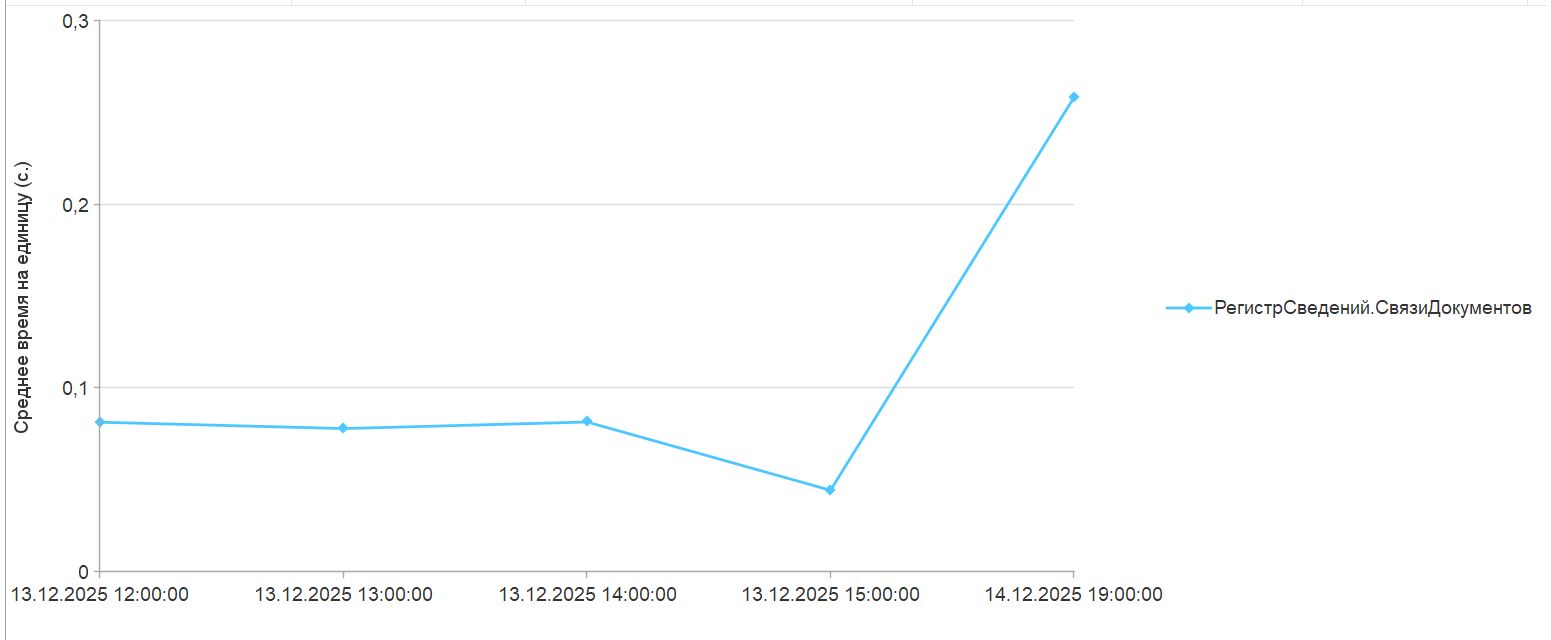
Миграция ~520 тыс. записей без оптимизаций длилась 14 часов. После внедрения оптимизаций это время сократилось до 5 часов, демонстрируя значительный прирост эффективности.
Проблема продолжения в ДО3 запущенных процессов в ДО2
Друзья, теперь от оптимизационных задач перейдем к сугубо практической.
Ранее в первой части статьи в пункте «Завершение неактуальных процессов» мы рассказывали о проблематике продолжения бизнес-процессов. Напомним, она заключается в том, что если бизнес-процесс начался в ДО2 и не закончился, то после миграции в ДО3 его нельзя будет продолжить.
На ИТС про этот нюанс указано в в разделе «Новое в версии 2.1.32 — Миграция процессов» (its.1c.ru/db/updinfo#content:1361:hdoc:issogl2_15):

Говоря иначе, такие бизнес-процессы предлагается завершить на стороне ДО2 до окончания миграции. Как следствие, пока это не будет сделано, возникает необходимость параллельной работы в обеих системах.
В рамках нашей продуктивной миграции ряд бизнес-процессов имел сложно прогнозируемый срок завершения и такая параллельная работа была неприемлема для заказчика. Исходя из этого была поставлена задача исследовать вопрос, и в глобальной перспективе может быть сделать так, чтобы появилась возможность продолжения бизнес-процесса на стороне ДО3.
Предупреждение
Забегая немного вперед, сразу предупредим, что после миграции объектов бизнес-процессов необходимо проверить все настройки обработок на стороне ДО3 на предмет корректности, и при необходимости восстановить их до рабочего состояния. Кроме прочего, нужно также учесть, что в них могут быть скрипты завязанные на структуру метаданных ДО2, и конечно при переезде они могут сломаться, такие скрипты следует переписать на новую структуру ДО3. Эти действия по проверке/исправлению необходимо сделать независимо от решения — завершать ли процессы в ДО2, прерывать ли их или организовать их продолжение на стороне ДО3.
Глоссарий
Обработка объекта — верхний срез аналитики запущенных процессов документов. Хранит информацию о том, кто, когда и с каким результатом выполнены действия в рамках цикла обработки. В настройках обработки определяется через какие действия должен пройти объект (Согласование, подписание, регистрация и т. п.);
Действия — определяет вид работы, которую нужно выполнить (согласовать, подписать, зарегистрировать и т. п.). Каждое действие имеет свою логику и прописывается какие участники должны его выполнить.
Если «Обработка объекта» — это весь маршрут целиком, то «Действие» — это конкретная остановка на этом маршруте с четкой инструкцией: что именно нужно сделать, в какой срок и кому.
Перед завершением миграции
Первое о чем стоит упомянуть в связи с нами выбранным путём продолжения бизнес-процессов, то, что стандартная процедура завершения миграции, кнопка «Завершить» в обработке «Миграция данных из предыдущей версии» — предусматривает остановку всех мигрировавших активных бизнес-процессов:

В этом можно убедиться, если заглянуть в её обработчик:

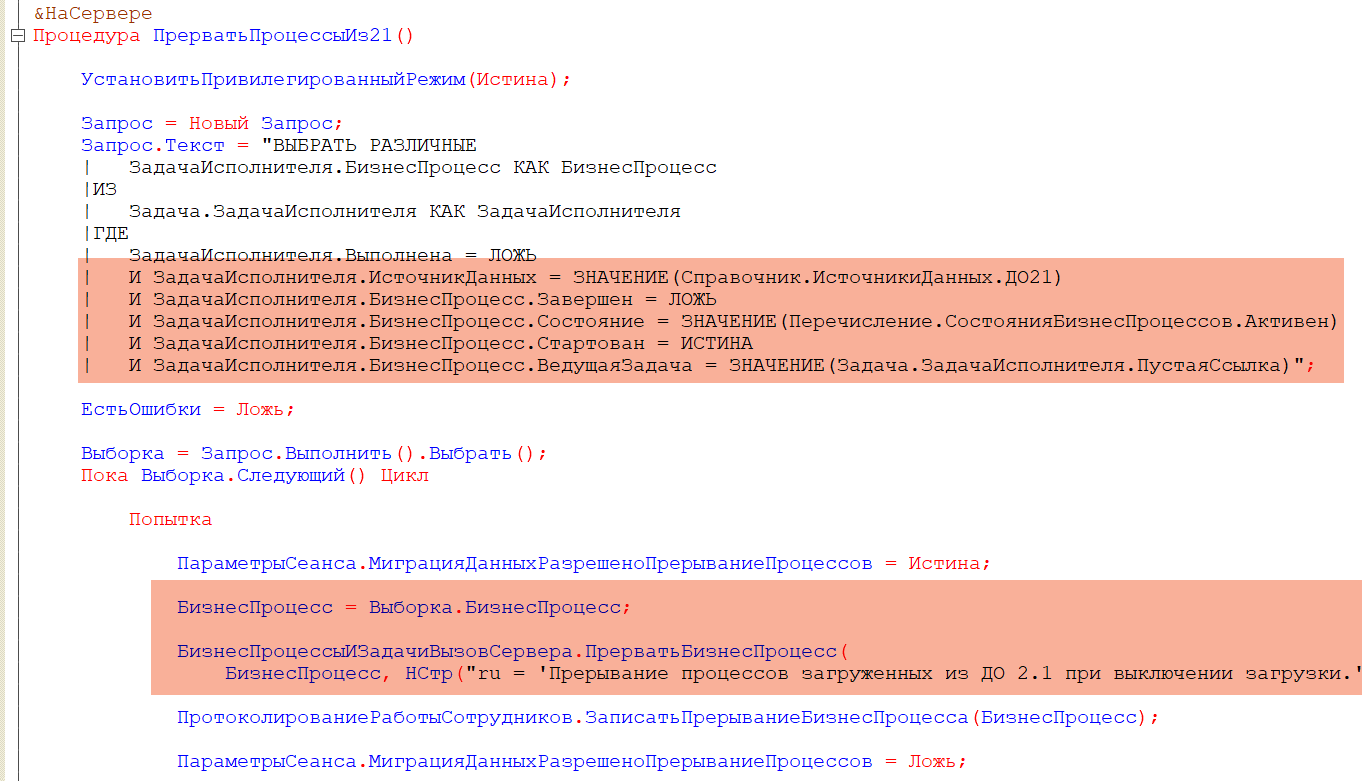
И для нашей цели это создаст сложности: мы потеряем возможность легко идентифицировать процессы, требующие дальнейшего выполнения. Чтобы избежать этого, мы программно отключаем данную процедуру в расширении. После применения этих модификаций мы смело можем нажать кнопку завершения миграции.
Визуальное представление проблемы
Рассмотрим пример на наших тестовых базах ДО2 и ДО3: в базе ДО2 имеется документ «Договор аренды» с незавершенным процессом согласования, где часть задач уже выполнена, а остальные ждут исполнения:
Результат согласования:
Перейдем на сторону ДО3. На вкладке «Обработка» документа «Договор аренды» отображается успешно мигрированный процесс. Одна задача уже выполнена (Смирнов В. Д.):
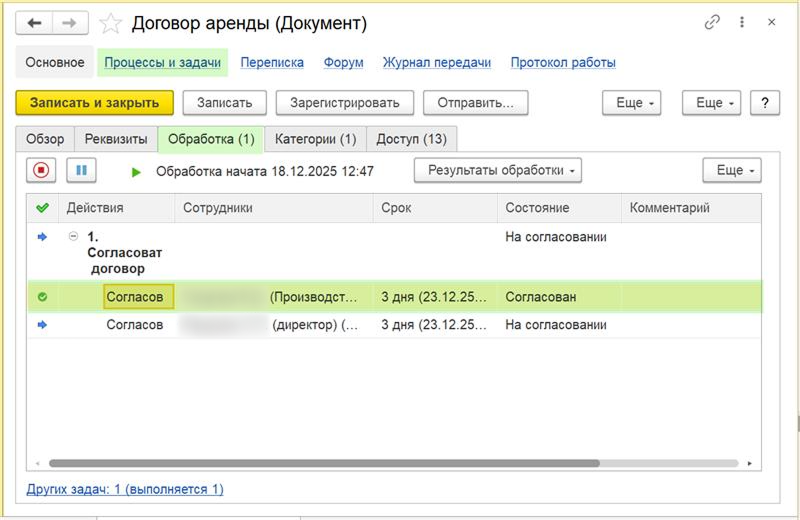
Но несмотря на возможность фактического выполнения задач и фиксации их статуса, система не инициирует дальнейшие шаги маршрутизации процесса.
Попробуем разобраться, почему так происходит.
Проверка настроек обработки документов
Начнем с оценки результатов миграции и текущего состояния настроек. Наша цель — подтвердить готовность системы ДО3 к полноценному старту новых бизнес-процессов.
Для этого необходимо проанализировать текущие настройки обработки документов и убедиться, что система корректно принимает новые документы в работу и запускает по ним требуемые действия.
На примере тестового «Договора аренды» мы проанализируем перенос этих настроек и определим шаги для успешного старта новых процессов.
Итак, начнем: в главном меню перейдем в раздел «НСИ», затем выберем «Виды документов», найдем нужный вид («Договор аренды») и перейдем на вкладку «Обработка»:


Теперь давайте перейдем к проверке правил обработки. Открыв окно правил по ссылке «Правила обработки», выберем строку для нашей организации ООО «Меркурий Проект». Как видим в правой части окна, для действия «Согласовать» проставлены участники (есть дочерний элемент), а для действия «Согласовать договор» нет:
Аналогичные настройки в ДО2 выглядят так — для действия «Согласовать» указан участник:

И для действия «Согласовать договор» также есть участники:
Это означает, что при текущих настройках процесс обработки будет некорректно запущен: действия «Согласовать договор» просто не появятся.
Чтобы исправить ситуацию мы восстанавливаем настройки участников вручную, как это было в ДО2. Для этого в настройке в ДО3 в правой части окна, дважды кликнув по строке действия «Согласовать договор» перейдем к настройке и добавим нужных участников:

На этом считаем, что восстановили настройку.Теперь переходим к проверке бизнес-процесса.
Создаем новый тестовый документ Договор аренды, далее на форме документа перейдем на вкладку «Обработка» и выполним команду «Еще» — «Заполнить»:

При этом должно заполниться дерево действий. Далее для старта обработки нажимаем кнопку «Начать обработку»:

Тут следует отметить, что в ДО3 задачи появляются у исполнителей не сразу, а только после того, как система обработает очередь заданий и произошедшие бизнес-события. Этот процесс выполняют регламентные задания «Диспетчер очереди заданий» и «Обработка произошедших бизнес-событий». Именно они отвечают за создание задач и дальнейшее движение (маршрутизацию) процесса:


После того, как задачи создались, их нужно выполнить. Это можно сделать прямо с вкладки «Обработка» — для этого необходимо дважды кликнуть по синей стрелке в строке, откроется форма задачи, где можно проставить результат выполнения/отказа:

После выполнения всех пунктов, на вкладке «Обработка» должна появиться отметка «Обработка завершена», значит всё прошло успешно:

Мы исправили настройки и убедились в их корректности. Это позволяет нам дальше разбирать проблему продолжения мигрированных активных процессов из ДО2.
Ещё раз напоминаем, что после миграции крайне важно проверять настройки для всех объектов обработок.
Анализ созданных объектов обработки документа
Теперь, когда у нас есть запущенные обработки документов — мигрированная и новая, давайте сравним, какие связанные объекты они сформировали. Для этого воспользуемся обработкой поиска по ссылке, и искать эти объекты будем по сквозной аналитике элемента справочника обработки объектов.
Сверху — поиск по новой обработке, созданной уже в ДО3 по исправленной настройке.
Снизу — поиск по обработке, которая загрузилась в ДО3 в рамках миграции из ДО2.

Анализ отчетов на примере связанных объектов обработки документа показал, что мигрированный пример отличается неполнотой: в нем отсутствуют записи в справочнике «Очередь заданий документооборота» и регистре сведений «Процессы обработки объектов». И мы предположили, что именно эта нехватка системных объектов является причиной, по которой функционал маршрутизации не может корректно продолжить процессы.
Как же нам продолжить бизнес-процессы?
Первый вариант, который мы рассмотрели, можно сказать решение «в лоб» — это восстановление всех «утраченных» объектов. Однако такой подход виделся достаточно трудоемким, мог потребовать глубокого анализа стека кода и знаний нюансов прикладного решения для разработки правильной логики. Поэтому мы пошли другим путём.
Что первое советуют айтишники, когда что-то не работает? Верно: «Попробуйте выключить и включить».
Вот этому принципу мы и последовали — решили «выключить» существующие мигрированные обработки документов и создать новые. И далее нам остается только довести бизнес-процесс до нужного этапа с помощью типовых методов. А система пусть сама создает все объекты как считает нужным.
Идея решения проблемы продолжения процессов
Давайте представим идею, позволяющая системе самостоятельно сформировать необходимые объекты, в виде следующей последовательности:
- Остановка процесса:
- Сохраняем все промежуточные результаты данного процесса (исполнитель, результат согласования, дата согласования и т. п.). Это гарантирует, что прогресс не будет утерян.
- Прерываем активный мигрированный процесс.
- Запуск новой обработки документа:
- После сохранения промежуточных результатов создаем новую обработку, на основе настроек.
- Автоматическое создание объектов:
- Система, в рамках новой обработки, самостоятельно создаст все требуемые объекты в рамках типовой логики с помощью регламентных заданий обработки процессов.
- Заполнение объектов сохраненными данными:
- Используя сохраненные на первом шаге промежуточные результаты, заполним результаты вновь созданных объектов. Это обеспечивает передачу актуальной информации и состояния мигрированного процесса.
- Продолжение выполнения задач исполнителями:
- После того как объекты сформированы и заполнены, исполнители получают возможность продолжить работу над оставшимися задачами. Новые объекты содержат всю необходимую информацию для корректного выполнения дальнейших этапов процесса:

Преимущества данного подхода:
- Снижение трудоемкости. Избегается сложная ручная разработка логики для добавления объектов.
- Корректность. Система самостоятельно формирует объекты, минимизируя риск ошибок.
- Сохранение прогресса. Промежуточные результаты не теряются, обеспечивая плавный переход.
- Возобновление работы. Исполнители могут продолжить выполнение задач без задержек.
Реализация перезапуска процессов
Обработку процессов решено выполнять порциями с помощью очереди в виде специализированного регистра сведений. Перезапускаемых процессов достаточно много, очередь позволит сделать обработку более плавной, не мешать другим пользователям и их бизнес-процессам. Кроме этого выделенный регистр также позволит фиксировать прогресс и хранить промежуточные результаты на всех стадиях обработки.
Представляем финальную техническую реализацию нашей стратегии перезапуска процессов:

1. Очередь перезапуска. Создан специализированный регистр сведений, который служит очередью перезапуска для выборочного добавления документов к перезапуску процессов.

2. Специализированные регламентные задания для перезапуска. Перезапуск процессов решили сделать отдельными этапами с помощью регламентных заданий.
Разделение функционала на независимые регламентные задания обусловлено необходимостью выполнения типовых регламентных заданий системы между каждым из наших этапов. Это критически важно для корректного создания, выполнения и маршрутизации объектов обработки документа типовым функционалом.
Вначале мы пытались реализовать весь цикл одной обработкой, вызывая типовые методы регламентных заданий между этапами. Однако этот подход оказался неэффективным: в ряде случаев объекты не успевали создаваться между этапами, что требовало ручного вмешательства и повторного запуска.
Регламентные задания обеспечения перезапуска процессов:
Перезапуск процессов — задание выбирает порцию записей из очереди с условиями:
Перезапущен = ЛОЖЬ
КоличествоПопыток <= Заданной в константеДля каждого документа порции сохраняются промежуточные результаты выполнения текущей обработки в специализированный регистр:

- Документ: Справочник.ДокументыПредприятия — источник бизнес процесса.
Данные: ХранилищеЗначений — структура значений с промежуточными результатами действий помещенные в таблицу значений).
Затем активная обработка документов прерывается, запускается новая с использованием типовых механизмов системы.
Заполнение результатов — задание выбирает порцию записей из очереди с условиями:
Перезапущен = ИСТИНА
ПроцессыПерезаполнены = ЛОЖЬ
КоличествоПопыток <= Заданной в константеПосле этого для соответствующих документов определяются вновь созданные объекты обработки, которые затем заполняются промежуточными результатами на основе ранее сохраненных исторических данных.
Заполнение дат — задание выбирает порцию записей с условиями:
Перезапущен = ИСТИНА
ПроцессыПерезаполнены = ИСТИНА
ДатыВыполненияЗаполнены = ЛОЖЬ
КоличествоПопыток <= ЗаданнойКонстантеВыполняется заполнение дат выполнения задач историческими значениями, полученными из ранее сохраненных данных. Это необходимо, так как типовые механизмы устанавливают текущую дату при выполнении процессов, что нарушает целостность истории процесса. Для этого заполнение производится в режиме ОбменДанными.Загрузка = Истина.
3. Типовые регламентные задания, обеспечивающие маршрутизацию. Для корректного функционирования нашей системы перезапуска процессов мы используем типовые регламентные задания ДО3, отвечающие за создание и маршрутизацию задач:
- Диспетчер очереди заданий.
- Обработка произошедших бизнес-событий.
Именно они формируют необходимые нам промежуточные объекты, которые затем обрабатываются нашими доработанными регламентными заданиями.
Пример перезапуска процессов
Рассмотрим, как работает реализованный механизм перезапуска процессов.
1. Формирование очереди перезапуска.
В очередь добавляются документы, отвечающие следующим критериям отбора:
- Источник данных бизнес-процесса: «Документооборот 2.1».
- Созданы в указанном периоде.
- Соответствуют определённому виду документа.
- Имеют активные бизнес-процессы.

2. Регламентное задание «Перезапуск процессов».
Предназначено для перезапуска процессов. Его основной целью является создание нового процесса взамен существующего активного, сохраняя при этом все промежуточные результаты, порядок действий задания:
- Получает порцию записей к перезапуску из очереди, с сортировкой по убыванию даты создания документов, в приоритете к перезапуску новые документы.
Сохраняет промежуточные результаты в регистр «rp_КэшДанныхПроцессовДокумента»:
Запускает новый процесс обработки:

Устанавливает флаг в очереди «Перезапущен»:
3. Регламентное задание «Заполнение результатов».
Когда процессы перезапущены, типовые регламентные задания создают полный набор необходимых объектов обработки. Наше задание, основываясь на ранее сохраненных промежуточных данных, заполняет результаты и выполняет задачи. Здесь возникает тонкий момент: регламентное задание при фиксации выполнения задач автоматически проставляет текущую дату:

Возникает потребность установки исторической даты выполнения.
Далее устанавливается флаг «Процессы перезаполнены» в очереди:
Устранение этой неточности в датах является задачей следующего регламентного задания — «Заполнение дат перезапущенных процессов».
4. Регламентное задание «Заполнение дат перезапущенных процессов».
Данное задание получает готовые результаты перезапущенных, заполненных результатами задачи и восстанавливает фактические даты выполнения и записывает их в режиме ОбменДанными.Загрузка = Истина.

Устанавливает флаг «Даты выполнения заполнены»:
Результаты
В итоге данный подход позволил нам перезапустить бизнес-процессы, восстановив их промежуточные этапы. То есть у пользователей появилась возможность продолжить выполнение бизнес-процессов в системе ДО3 для тех документов, которые были запущены, но не завершены в ДО2.
В рамках нашего реального проекта в результате продуктивной миграции, сначала вручную были восстановлены до работоспособного состояния порядка 20 настроек обработок объектов, далее с помощью выработанного алгоритма обработали ~2 тысячи бизнес-процессов, и пользователи благополучно продолжили с ними работу.
Заключение
Что ж, порой сложно уместить все детали в рамки одной статьи, и мы в очередной раз благополучно с этим не справились. :)
На этом мы не прощаемся, о том как мы преодолевали нюансы интеграции Документооборота и ERP, как избирали свой путь для миграции прав доступа, а также подробности о результатах миграции уже в продуктивной среде — расскажем в следующей части статьи.
Всем удачи и увидимся на страницах экспертных статей!
От экспертов «1С-Рарус»











Читайте первыми статьи от экспертов «1С‑Рарус»
Вы можете получать оповещения по электронной почте
Или получайте уведомления в телеграм-боте







