


Оглавление
- Механизмы «Копии баз данных» и «Дата акселератор» для базы финансового учёта
- Лицензирование механизмов Копии баз данных и Дата акселератора
- Требования к инфраструктуре
- Настройка механизмов Копии баз данных и Дата акселератора
- Управление выбором копии или основной базы данных и проверка выполнения в копии
- Заполнение копии базы данных
- Сложности запуска Копии баз данных и Дата акселератора
- Вынос сервиса на отдельный сервер
- Результаты и замеры производительности
- К чему обращается система
- Заключение
Механизмы «Копии баз данных» и «Дата акселератор» для базы финансового учёта
В статье мы делимся своим опытом применения механизма «Копий баз данных» с режимом «Дата акселератор» (Data accelerator) в базе финансового учета с достаточно «тяжелыми» регистрами накопления и бухгалтерии.
База активно используется для построения различных аналитических отчетов, по множеству индивидуальных структур. Некоторые отчеты несут в себе сложную математику агрегации ресурсов с построением по кастомизируемым формулам с применением функций.
Пример выражения агрегации:

С недавнего времени у нас стал набирать популярность «блок диаграмм» (об этом блоке подробнее мы поговорим в других статьях), который основан на множественном выполнении отчетов. В связи с этим возникла необходимость поработать над их ускорением.
Путей ускорения отчетов множество — это оптимизация запросов, упрощение RLS, переработка архитектуры метаданных или, например, улучшение ситуации с индексами. По всем этим направлениям так или иначе у нас работа ведется.
Но есть и другие возможности. В 2020 году фирма «1С» в платформе версии 8.3.17 реализовала BI-систему «1С:Аналитика». Многие, вероятно, слышали, что в связке с ней, также поставляется так называемый механизм «Копий баз данных» с сервисом «Дата акселератор». Но, возможно, не все в курсе, что этот сервис был выпущен ещё раньше, в платформе версии 8.3.14, и его можно использовать как самостоятельное решение.
Механизм «Копий базы данных» позволяет вынести часть данных из рабочей базы в другую базу-копию, например, одну из таблиц. В случае, если доступ к этой таблице является узким местом в системе, можно направить часть запросов на чтение, например, при формировании отчетов, в эту копию и таким образом распараллелить процесс.
Классический вариант предполагает для копии наличие физической базы данных, например, PostgreSQL или MS SQL. Альтернативный вариант копии БД — режим «Дата акселератора». В этом случае копия устроена по принципу in-memory database — базы данных, размещенной в оперативной памяти. Помимо этого такая БД использует колоночную модель хранения данных и включает ряд оптимизаций, что должно приводить к ускорению выполнения некоторых запросов до 3–5 раз, а в отдельных случаях в десятки раз (habr.com/ru/company/1c/blog/645365/).
Мы не могли пройти мимо такой технологии и решили попробовать ускорить отчеты в нашей базе с помощью Дата акселератора.
Лицензирование механизмов Копии баз данных и Дата акселератора
Поначалу, до погружения в тему, нам казалось что Дата акселератор является неотъемлемой частью 1С:Аналитики. Но если разобраться в вопросе, становится ясно — механизмы 1С:Аналитики, Копий баз данных и Дата акселератора хоть и отлично дополняют друг друга, но вполне могут и не использоваться совместно.
В отличии от 1С:Аналитики, механизм Копий баз данных/Дата акселератора специальной установки не требует — он уже встроен в дистрибутив платформы начиная с версии 8.3.14. Однако, для его использования необходима лицензия, на выбор:
- серверная лицензия уровня КОРП;
- лицензии по выделенной функциональности 1С:Аналитики.
В нашем случае это был второй вариант — мы приобрели лицензию выделенной функциональности.
Требования к инфраструктуре
Для версии платформы 8.3.21 на портале ИТС указаны следующие требования (its.1c.ru/db/v8321doc#bookmark:cs:TI000000254):
- Процессор с архитектурой Intel Nehalem или AMD Piledriver, а также архитектуры процессоров Intel или AMD, разработанные после указанных архитектур. Процессор должен иметь не менее двух ядер. Под термином «ядро» понимается физическое ядро процессора компьютера (в том числе полученное в результате включения технологии hyper-threading) или любое ядро виртуальной машины, на которой работает Дата акселератор.
- 64-разрядная операционная система:
- Семейство Microsoft Windows: версии 7, 8, 8.1, 10, 11 (со всеми установленными обновлениями).
- Семейство Microsoft Windows Server: 2012, 2012 R2, 2016, 2019, 2022.
- Семейство ОС Linux: CentOS 6 и выше, Red Hat Enterprise Linux 7 и выше, Fedora 20 и выше, Debian GNU/Linux 8 и выше, Ubuntu 14.04 и выше.
- Оперативная память:
- Минимальные требования — 64 ГБ.
- Рекомендуется — 512 ГБ.
Параметры нашей системы
База данных:
- Платформа «1С:Предприятие 8»: 8.3.21.1622 64х.
- База данных: PostgreSQL 11.8.
- Программный продукт: Конфигурация на основе БСП.
Основной сервер:
- Операционная система: Ubuntu 18.04.6.
- Процессор: Intel Xeon CPU E5-2637 v2@ 3.5GHz.
- Оперативная память: 376 ГБ.
- SSD: 5 ТБ.
Изначально мы попытались поработать с Дата акселератором на том же сервере, но столкнулись с аномальным поведением (об этом расскажем подробнее в разделе ниже «Сложности запуска Копии баз данных и Дата акселератора»). В связи с этим пришли к варианту вынести сервис Дата акселератора на виртуальный сервер под управлением Windows.
Виртуальная машина:
- Операционная система: Windows server 2019 standard.
- Процессор: Intel Xeon CPU E5-2637 v2@ 3.5GHz (доступ ко всем ядрам основной машины без ограничений).
- Оперативная память: 150 ГБ (Выделенные от основной машины).
- SSD: 500 ГБ (выделенные от основной машины).
Настройка механизмов Копии баз данных и Дата акселератора
Чтобы копия базы данных заработала, нужно указать системе какие таблицы мы хотим туда перенести.
Состав копии
Согласно инструкции на ИТС (its.1c.ru/db/metod8dev/content/5951/hdoc) мы прошли в стандартную обработку «Управление копиями базы данных» через пункт основного меню «Функции технического специалиста...»:
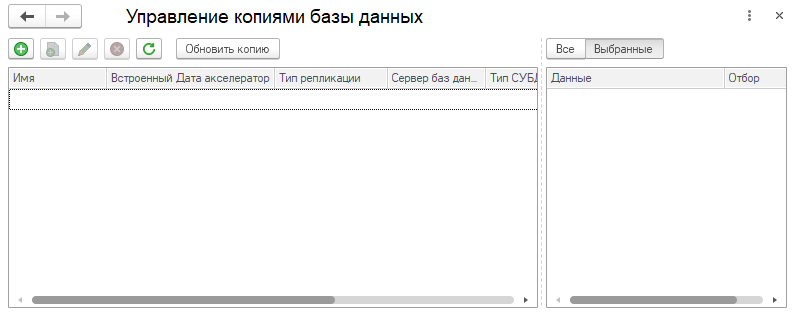
Добавили новую копию базы данных и установили флаг «Встроенный Дата акселератор»:
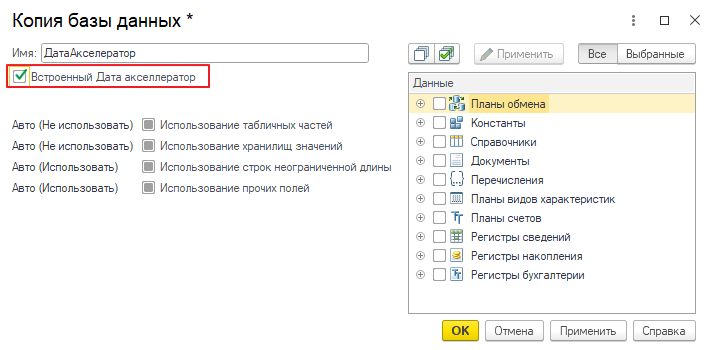
Далее нужно выбрать метаданные, которые будут скопированы в копию. Это можно сделать:
- Вручную — через интерфейс формы «Управление копиями базы данных», установив нужные флажки.
- Программно — используя свойство глобального контекста КопииБазыДанных.
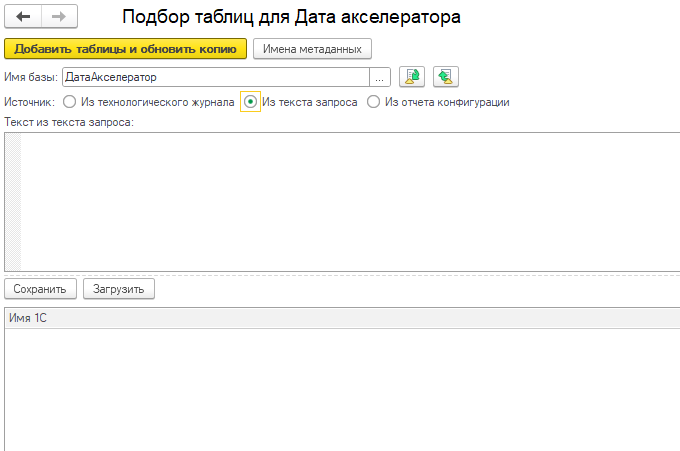
- Используя обработку — «Подбор таблиц для Дата акселератора», которая размещена в инструкции на ИТС.
В обработке «Подбор таблиц для Дата акселератора» есть варианты подбора метаданных по:
- тексту запроса на языке 1С;
- выбранному отчету из конфигурации;
- тексту запроса в терминах СУБД из лога технологического журнала.
Выбирая вариант, следует учесть, что одним из условий отправки запроса в копию является то, что все таблицы-источники запроса должны быть включены в состав копируемых метаданных, в том числе — таблицы, используемые при неявном левом соединении (при разыменовывании через точку), и таблицы, использующиеся в платформенной «добавке» RLS.
В нашей базе используется RLS и во многих отчетах присутствует программная обработка текста запроса. Поэтому для нас единственно логичным вариантом было пойти по пути подбора метаданных через лог ТЖ, который будет содержать уже конечный вариант запроса, со всеми включениями.
Для этого мы настроили лог по сбору событий DBPOSTGRS:
<?xml version="1.0" encoding="UTF-8"?> <config xmlns="http://v8.1c.ru/v8/tech-log"> <log history="1" location="/techlogs/base_name/dataaccelerator"> <event> <eq value="DBPOSTGRS" property="Name"/> <eq value="base_name" property="p:processName"/> </event> <property name="all"/> </log> </config>
За основу эксперимента были взяты одни из ключевых отчетов нашей системы:
- Отчет о прибылях и убытках.
- Сравнительный анализ ключевых показателей.
Далее мы выдали тестовому пользователю ограниченные права по аналогии с одним из существующих пользователей, запустили под ним выполнение отчета «Отчет о прибылях и убытках».
В запросе отчета в СКД есть удобный тег «ДОХОДЫ», по которому мы легко нашли нужный запрос в логе ТЖ:
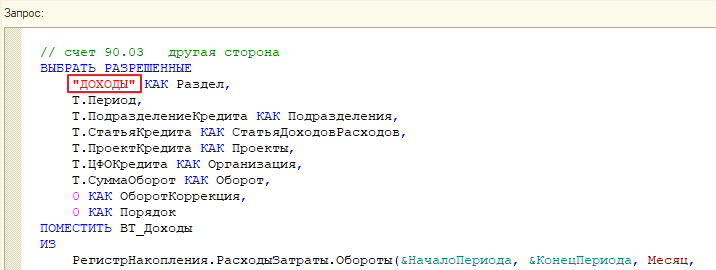
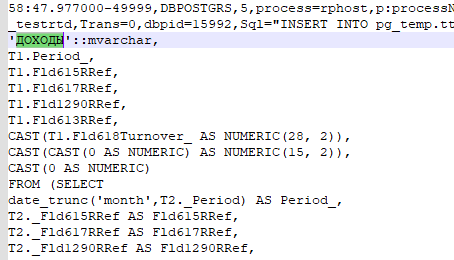
Далее загрузили текст найденного события в обработку «Подбор таблиц для Дата акселератора» и нажали кнопку «Добавить таблицы и обновить копию»:
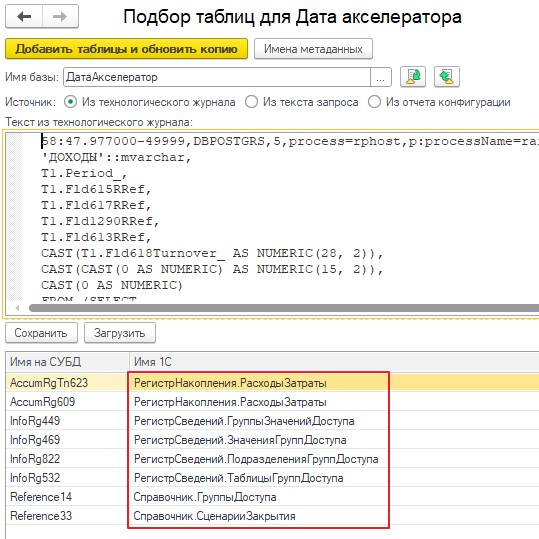
В результате в копию были добавлены таблицы:

- Регистр накопления: «Расходы затраты» — основной источник данных этого отчета.
- Справочник «Сценарии закрытия» — условие по реквизитам этого справочника добавляется программно, в исходном текста запроса СКД их нет.
- И ряд таблиц блока RLS, которых также в исходном тексте запроса нет:
- Регистр сведений «Группы значений доступа».
- Регистр сведений «Значения групп доступа».
- Регистр сведений «Подразделения групп доступа».
- Регистр сведений «Таблицы групп доступа».
- Справочник «Группы доступа».
После обновления копии попытались запустить отчет под нашим тестовым пользователем с настройкой выполнения «Только в копии» и получили ошибку:

Похоже выбранных таблиц оказалось недостаточно. Мы предположили, что метаданных участвующих в одном событии может быть недостаточно, поэтому попробовали загрузить в обработку подбора весь лог событий DBPOSTGRS. Были подобраны новые метаданные:
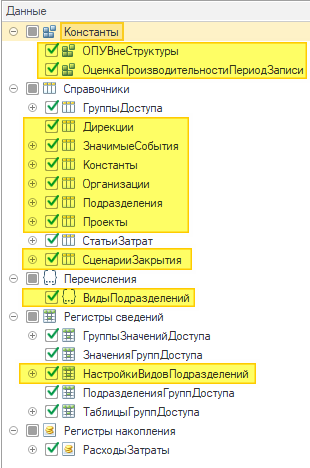
Все они так или иначе участвуют в построении отчета, но не в запросе СКД. Эти объекты не занимают много места, поэтому мы посчитали разумным их оставить.
Увы, и после этих действий данных в копии было недостаточно. Снова ошибка — нет подходящих копий.
Мы проанализировали функционал настроек копии и в качестве эксперимента решили включить флаг «Использование табличных частей»:

Это помогло — отчет стал читать данные из копии. В табличный документ результата отчета была выведена информация, откуда прочитаны данные:

Для отчета «Сравнительный анализ ключевых показателей» метаданные были добавлены аналогичным способом. Поэтому подробно процесс излагать не будем.
Уточнение настроек
Чуть позже мы включили в копию вообще все константы и перечисления, так как посчитали, что многие из них могут использоваться, при этом места они занимают мало.
Нужно понимать, что если для констант и перечислений цена ошибки скорее всего невелика, то добавление всех табличных частей может быть чревато большим расходом памяти и, скорее всего, требует дополнительных экспериментов и уточнения.
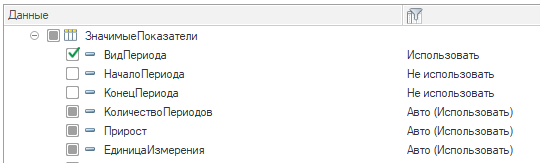
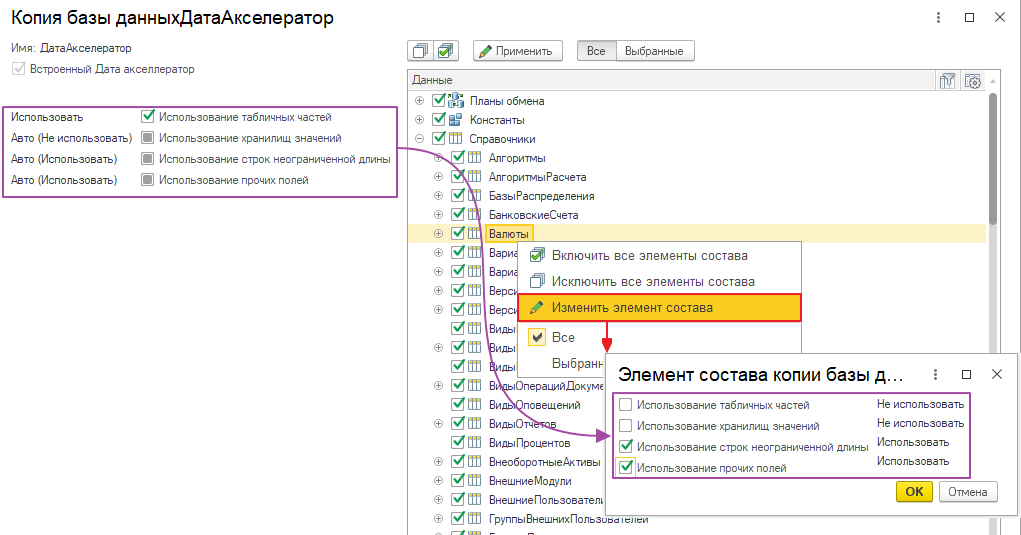
Для этого в форме редактирования состава метаданных копии есть дополнительные возможности по индивидуальной настройке элементов:
- В дереве метаданных копии при раскрытии узла элемента можно выбирать, какие конкретно поля таблиц будут использоваться в копии:
- Также есть возможность переопределить глобальные флаги использования табличных частей, хранилищ значений и т.д. Для этого нужно выбрать команду «Изменить элемент состава» в контекстном меню:
Выбранные нами отчеты не являются типовыми и достаточно непросты, посему, возможно, вы с такими проблемами при подборе состава копии не столкнетесь.
Но как можно заметить, задача определения необходимых метаданных для копии не так уж прозаична. Надеемся, в будущем этот процесс будет упрощен и станет более интуитивно понятным.
Управление выбором копии или основной базы данных и проверка выполнения в копии
Тут стоит сказать о том, какие вообще есть рычаги влияния на выбор системы — отправлять запрос в копию или нет и как убедиться, что копия используется.
Для управления поведением системы в отношении копий существует ряд свойств объекта Запрос и одноименных параметров вывода СКД.
Задание требуемой актуальности данных управляется с помощью свойств ТребуемаяАктуальностьДанных и ТребуемоеВремяАктуальностиДанных объекта Запрос (и одноименного свойства параметра вывода компоновки данных). Работа данных свойств зависит от значения свойства ИспользованиеКопийБазыДанных. Рассмотрим эту связку:
- Свойство ИспользованиеКопийБазыДанных установлено в значение ПреимущественноКопии. Свойство ТребуемаяАктуальностьДанных работает следующим образом:
- Актуальные — в этом случае данные будут получаться только из основной базы данных.
- Любые — в этом случае будут использоваться данные из копии, которая содержит все таблицы, необходимые для выполнения запроса и эти таблицы содержат данные с требуемой актуальностью (свойство ТребуемоеВремяАктуальностиДанных). Если нужной копии базы данных нет, то запрос будет исполнен в основной базе данных.
- Свойство ИспользованиеКопийБазыДанных установлено в значение ИспользоватьТолькоКопии. Свойство ТребуемаяАктуальностьДанных работает следующим образом:
- Актуальные — в этом случае данные из копии буду считаться пригодными для использования в том случае, если данные в копии актуальны. Данные будут считаться актуальными в том случае, если для данной копии в основной базе нет изменений, которые еще не перенесены в копию.
- Любые — в этом случае будут использоваться данные из копии, которая содержит данные с требуемой актуальностью (свойство ТребуемоеВремяАктуальностиДанных). Если нужной копии базы данных нет — будет сформировано исключение.
Если свойство ТребуемаяАктуальностьДанных установлено в значение Авто (при любом значении свойства ИспользованиеКопийБазыДанных ), то решение о выборе требуемой актуальности данных в копии автоматически принимается платформой. Для объекта Запрос в этом случае будет использоваться значение Актуальные, а для системы компоновки данных — значение Любые.
Рассмотрим, как работает механизм определения актуальности данных.
Фактически, значение свойства ТребуемоеВремяАктуальностиДанных можно описать следующим образом: изменения данных за какой интервал времени мы готовы проигнорировать ради того, чтобы запрос всегда выполнялся на копии?
Так, если у нас значение свойства ТребуемоеВремяАктуальностиДанных равно 30, то это означает, что если все таблицы копии, участвующие в запросе актуальны, а изменение не актуальных таблиц было не ранее, чем время выполнения запроса, уменьшенное на 30 секунд, то запрос будет выполняться на копии. Если время изменения не актуальной таблицы произошло более чем за 30 секунд от момента формирования запроса — такая копия считается не подходящей. Указывать период актуальности можно тремя различными способами:
- Целым числом. Это значение описывает интервал времени в секундах. Если таблицы копии изменялись внутри этого интервала (относительно момента начала выполнения запроса), то эти таблицы считаются актуальными. Такой способ указания требуемого времени актуальности данных будет зависеть только от времени начала выполнения запроса.
- Датой и временем. Указывается конкретный момент времени. Все изменения, которые были выполнены после этой даты — не окажут влияния на признак актуальности в данном запросе. Такой способ указания требуемого времени актуальности данных будет зависеть только от указанного значения.
- Стандартная дата начала. Позволяет указать начало «интервала актуальности» таким образом, что он будет автоматически изменяться без участия прикладного разработчика. Такой способ указания требуемого времени актуальности данных будет зависеть только от текущей даты.
После получения данных (а для системы компоновки данных — во время компоновки данных), платформа предоставляет возможность получить информацию о том, откуда получались данные и насколько они актуальны:
- Объект РезультатЗапроса предоставляет свойства:
- ДанныеАктуальны — позволяет определить, актуальны или нет данные, полученные запросом.
- ВремяАктуальности — содержит дату и время последнего фактического обновления данных в копии. Для актуальных данных содержит время начала выполнения запроса.
- КопияБазыДанных — содержит имя копии базы данных, которая использована для получения данных.
- Язык выражений системы компоновки данных содержит функции ДанныеАктуальны(), ВремяАктуальностиДанных() и КопияБазыДанных(). Назначение этих функций полностью соответствует одноименным свойствам результата запроса.
При использовании системы компоновки данных предоставляется возможность управлять выводом в отчет информации о том, откуда получена информация и какова актуальность полученных данных. Для этого предназначены параметры вывода ВыводитьАктуальностьДанных и ВыводитьКопиюБазыДанных. При этом следует помнить, что если в схеме компоновки данных используются вложенные схемы, то каждая схема компоновки данных может быть выполнена как на основной базе данных, так и на любой из копии, которая удовлетворяет требованиям исполняющегося запроса.
Если в информационной базе настроены несколько копий и каждая из этих копий соответствует требованиям исполняющегося запроса, то в этом случае система выберет произвольную копию из списка подходящих. В системе отсутствует механизм управления выбором копии в таком случае.
Источник: its.1c.ru/db/v8321doc#bookmark:dev:TI000002113
Ручное управление выбором копии или основной базы данных
Для технических целей, чтобы «заставить» систему выполнить запрос/отчет в копии, мы использовали такие значения:
- ИспользованиеКопийБазыДанных = ИспользоватьТолькоКопии.
- ТребуемаяАктуальностьДанных = Любые.
- ТребуемоеВремяАктуальностиДанных = достаточно большое число для теста, например час (3600).
Со значением ИспользоватьТолькоКопии нужно быть осторожными, т. к. при отсутствии копий с нужным набором метаданных будет вызвано исключение, после которого в некоторых случаях необходимо будет перезапустить «1С:Предприятие».
Аналогично, чтобы запрос выполнился именно в СУБД, а не в копии — мы устанавливали свойство ИспользованиеКопийБазыДанных в значение НеИспользоватьКопии.
Полагаем, что в обычной эксплуатации более правильно будет использовать значения ИспользоватьПреимущественноКопии или Авто.
Важно!
Дополнительно обращаем внимание, что стандартное значение параметра ТребуемаяАктуальностьДанных — Авто по-разному работает для запросов и СКД:
- В запросе будет использовано значение Актуальные.
- В СКД — Любые.
Управление несколькими копиями
Свойство ИспользуемыеКопииБазыДанных может быть полезным, если нужно управлять выполнением запросов/отчетов в нескольких копиях. В наших тестах такое не требовалось, поэтому мы его не применяли.
Проверка выполнения — копия базы данных или СУБД
Запрос
Для запроса мы проверяли выполнение в копии программно через свойство результата запроса — КопияБазыДанных.
Если запрос выполнен в копии — в этом свойстве будет указано наименование копии БД, если запрос выполнен в СУБД — будет пустым.
Для информации также выводили свойства ДанныеАктуальны, ВремяАктуальностиДанных. В текущих экспериментах они нам не пригодились, но для настройки бизнес-логики могут быть полезны.
Примеры:
1. Запрос с актуальностью = 1 час, который система попытается выполнить в копии, либо выдаст исключение:
Запрос = Новый Запрос; Запрос.Текст = "Ваш текст запроса"; Запрос.ИспользованиеКопийБазыДанных = ИспользованиеКопийБазыДанных.ИспользоватьТолькоКопии; //Запрос.ИспользуемыеКопииБазыДанных.Добавить("ИмяКопии"); Запрос.ТребуемаяАктуальностьДанных = ТребуемаяАктуальностьДанных.Любые; Запрос.ТребуемоеВремяАктуальностиДанных = 3600; РезультатЗапроса = Запрос.Выполнить(); Если ЗначениеЗаполнено(РезультатЗапроса.КопияБазыДанных) Тогда Сообщить(СтрШаблон("Запрос выполнился в копии: %1", РезультатЗапроса.КопияБазыДанных)); Иначе Сообщить("Запрос выполнился в СУБД"); КонецЕсли; Сообщить(СтрШаблон("Данные актуальны: %1", РезультатЗапроса.ДанныеАктуальны)); Сообщить(СтрШаблон("Время актуальности данных: %1", РезультатЗапроса.ВремяАктуальностиДанных));
2. При таких настройках система сама выберет, где выполнять запрос. Условие актуальности копии — до суток:
Запрос.ИспользованиеКопийБазыДанных = ИспользованиеКопийБазыДанных.ИспользоватьПреимущественноКопии; Запрос.ТребуемаяАктуальностьДанных = ТребуемаяАктуальностьДанных.Любые; Запрос.ТребуемоеВремяАктуальностиДанных = 86400;
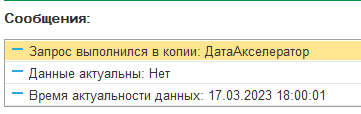
Если копия не обновлена, но укладывается в период актуальности, флаг «Данные актуальны» будет равен «Нет»:
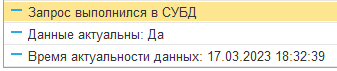
В случае, если все копии окажутся с превышенным периодом актуальности, запрос будет выполнен в СУБД:
Отчет на СКД
Чтобы понять, где выполнился отчет на СКД, мы устанавливали параметры вывода ВыводитьАктуальностьДанных и ВыводитьКопиюБазыДанных в значение “Выводить”.
В этом случае в табличном документе результата отчета ниже заголовка будет выведена дополнительная секция:

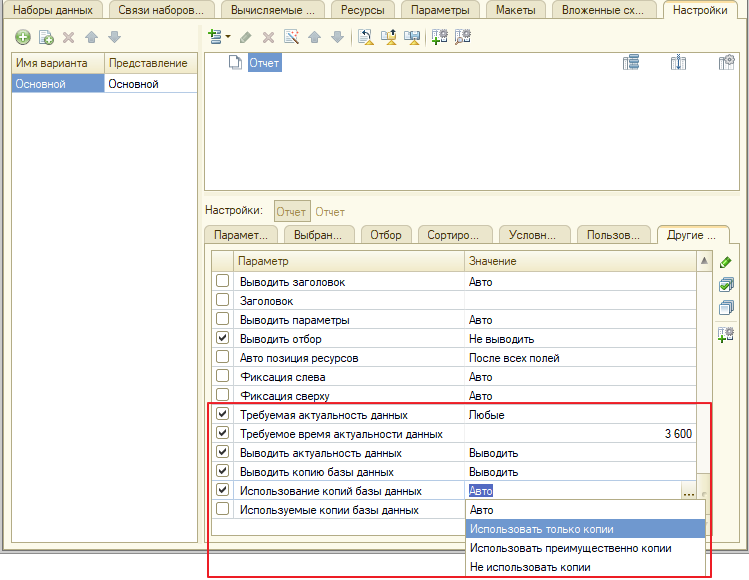
Варианты установки параметров вывода:
1. Вручную в схеме компоновки данных — на вкладке «Настройки» → «Другие настройки»:
2. Эти же параметры можно установить программно:
Настройки = КомпоновщикНастроек.Настройки; ЗначениеПараметра = Настройки.ПараметрыВывода.НайтиЗначениеПараметра(Новый ПараметрКомпоновкиДанных(“ВыводитьАктуальностьДанных”)); Если ЗначениеПараметра <> Неопределено Тогда ЗначениеПараметра.Использование = Истина; ЗначениеПараметра.Значение = ТипВыводаАктуальностиДанныхКомпоновкиДанных.Выводить; КонецЕсли;
Заполнение копии базы данных
Для первоначального заполнения таблиц, при изменении состава копии может быть запущено несколько фоновых заданий (по умолчанию 4):

Тест времени обновления
Мы провели тест времени выполнения. Добавили в состав копии только один элемент метаданных — регистр накопления «Расходы затраты», который по данным СУБД занимает:
- Основная таблица ~ 8 ГБ, в сумме с индексами 36 ГБ.
- Итоги ~ 2 ГБ, в сумме с индексами 10 ГБ.

На нашей системе первичное заполнение такой копии заняло около 5 минут.
При этом процесс dbda по занимаемой памяти доходил до ~15 ГБ. Также по наблюдениям после завершения загрузки процесс некоторое время продолжал использовать процессор и занимаемая память постепенно убывала — в конечном итоге дойдя до 4 ГБ.
Тут правда не совсем понятно, какие именно данные используются — загружаются ли итоги и индексы? То есть, в этом примере объем данных в теории может варьироваться от 8 до 46 ГБ.
В одном из наших тестов, после запуска пересчета итогов регистр «Расходы затраты» копия БД оказалась не актуальна, что наводит на мысли об использовании таблицы итогов при обновлении.
С индексами же вопрос открытый, т. к. Дата акселератор описывается как колоночная БД, в которой хранение устроено совсем иным образом нежели в реляционной и традиционные индексы в ней не применимы. Про колоночные БД мы рассказывали в статье «Как и зачем интегрировать Yandex ClickHouse с 1С?».
Тест занимаемого объема памяти
Также мы провели ещё один эксперимент по оценке занимаемого объема данных в памяти. Для этого выбрали в составе копии БД с Дата акселератором ВСЕ метаданные. По данным СУБД на тот момент база занимала 223 ГБ:
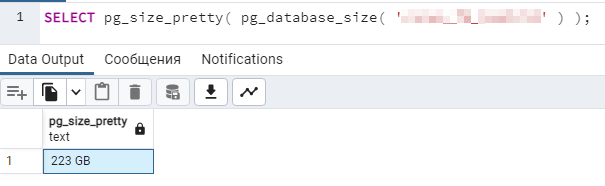
После полной загрузки копии и «устаканивания» процесса dbda, по данным htop он занял ~ 44 ГБ физической памяти:
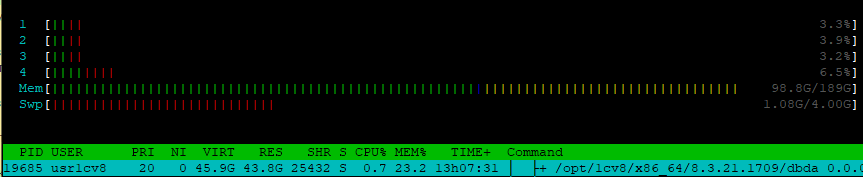
Работает некий процесс по упаковке данных. Однако, здесь следует учесть, что такой объем процесса получился спустя некоторое время, а в момент загрузки копии занимаемая память может быть больше.
Обновление копии базы данных
После первичного заполнения копии для поддержки актуальности её необходимо периодически обновлять. Система автоматически отслеживает изменения в выбранных таблицах, но запуск обновления отдан на откуп разработчику.
Обновить копию можно:
- Вручную — в стандартной обработке по кнопке «Обновить копию»:
- Программно — используя метод КопииБазыДанных.Обновить(...).
В нашем случае мы создали регламентное задание, которое выполняется раз в 10 мин и запускает следующий код:
Процедура ОбновитьКопииБазДанных() Экспорт Для Каждого Копия Из КопииБазыДанных Цикл КопииБазыДанных.Обновить(Копия); КонецЦикла; КонецПроцедуры
Сложности запуска Копии баз данных и Дата акселератора
Во время пилотного подключения механизма мы столкнулись с несколькими проблемами. Часть из них потребовали настоящего экспертного расследования.
Падение процесса dbda на Linux
По-умолчанию сервис Дата акселератора работает на основном рабочем сервере. Изначально мы пробовали именно такой вариант, но столкнулись с не ясными проблемами — на нашей ОС Ubuntu 18.04.6, на платформе 1С версии 8.3.17 процесс dbda, который отвечает за хранение базы в оперативной памяти деградировал, что приводило к его падению при очередном обращении к акселератору:
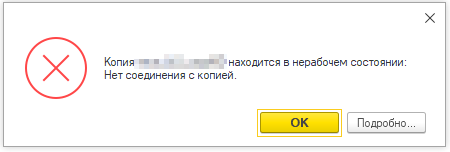
По данным journalctl с ошибкой типа segfault:

Увы, расследование причин в данном кейсе зашло в тупик.
При этом в экспериментах на Windows таких проблем не наблюдалось, поэтому мы пошли по пути выделения сервиса на отдельный рабочий сервер, запущенный под ОС Windows.
Позже мы протестировали работу на linux с версией платформы 8.3.21.1709 и подобных проблем не наблюдалось.
«Зависания» у пользователей с некорректным RLS
Спустя некоторое время эксплуатации на рабочей базе начали поступать жалобы от пользователей по поводу «зависания» системы при выполнении некоторых отчетов.
В консоли кластера это выглядело как соединение с СУБД (запрос) с очень большой длительностью.
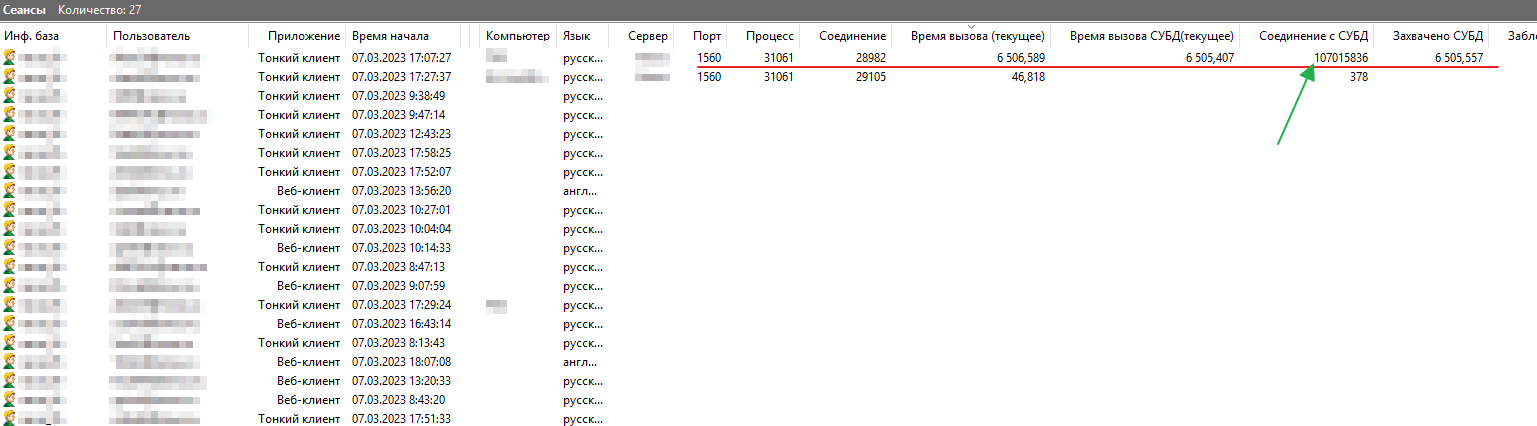
Что здесь примечательно — как правило, по наблюдениям, номер соединения с СУБД имеет до 5-ти разрядов, в этом случае он был 10-тизначный. При наших экспериментах мы уже заметили такую закономерность — такие «длинные» номера соединений мы считаем маркером вызова в копии БД.
Причем, обычно в момент обращения в копию по данным диспетчера задач (в Windows) или htop (в Linux) у процесса dbda наблюдается нагрузка процессора. А при текущем «зависшем» вызове никакой нагрузки практически не было.
Проблему удалось локализовать — она была не плавающая и возникала у одних и тех же пользователей. Эмпирическим путем удалось выявить, что зависания возникают при наличии определенной роли у пользователя:
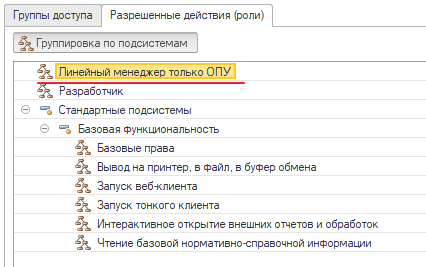
При расследовании было несколько гипотез — предположения по различному формированию текста запроса, пересечению прав и другие. При анализе ограничения доступа в роли был выявлен блок, который, по сути, являлся дублирующим, т. к. внутри шаблона доступа присутствуют аналогичные условия. Данный атавизм остался в ролях после рефакторинга системы доступа:
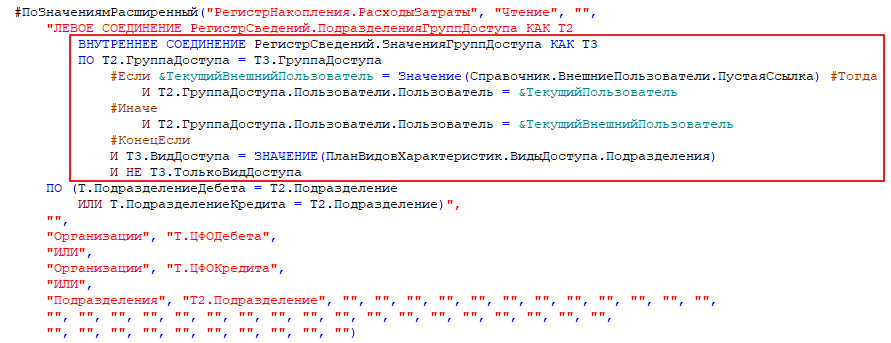
Мы проанализировали роли с подобными ограничениями и заменили условие на корректное:

После этого зависания прекратились.
«Отсекание» части пакетов в объединениях с условием «В»
Ещё один кейс, который был выявлен при исправлении предыдущего. При сравнении результатов отчета «Отчет о прибылях и убытках» выполненного в СУБД и в копии БД, были обнаружены расхождения в суммах. При локализации отбора в отчете стало ясно, что при выполнении отчета в копии «пропадает» сумма по счету 90.03.
В запросе СКД выборка выполнена в виде объединения запросов по различным счетам. И наблюдалась явная картина, что суммы из 1-го пакета (с отбором по счету 90.01.1) в отчет попадали, а суммы 5-го пакета (с счетом 90.03) нет:

Далее мы получили преобразованный текст запроса СКД и в ходе ряда экспериментов выявили, что на «пропадание» пакета влияет условие по сценарию типа «В» с массивом насчитывающим ~ 400 элементов:

Как выяснилось далее — это оказалась недавняя доработка, поэтому было несложно откатиться к прежнему условию по реквизитам справочника без условия типа «В», после чего расхождение в суммах ушло:

Стоит отметить, что Дата акселератор довольно чувствителен к видам запросов, в частности, к запросам со сложными условиями RLS и некоторым видам условий таблиц. Поэтому перед подключением механизма в продуктивной базе рекомендуем обкатать его на тестовом контуре.
Вынос сервиса на отдельный сервер
Как было описано ранее, при падении процесса dbda на рабочем сервере на Linux мы решили вынести сервис на машину с Windows.
Мы развернули виртуальную машину на Windows Server 2019 на том же сервере, выделили ей 150ГБ ОЗУ и запустили на ней кластер 1С.
Далее согласно инструкции с портала ИТС (its.1c.ru/db/metod8dev/content/5951/hdoc) мы добавили в консоли кластера дополнительный рабочий сервер и настроили требования назначения функциональности (ТНФ):
- На основном рабочем сервере — запретили использование Дата акселератора:

- На дополнительном рабочем сервере, назначили сервис акселератора с первым приоритетом, а второй настройкой запретили остальные сервисы:

- Применили требования для кластера:
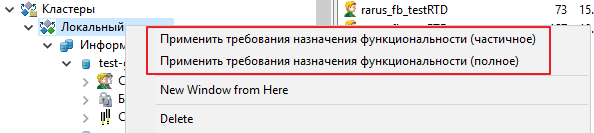
После этого на виртуальной машине автоматически запустился дополнительный процесс dbda.exe:

На этом процесс настройки в общем-то окончен, копию уже можно использовать.
Результаты и замеры производительности
Мы провели серию замеров времени выполнения на паре отчетов. Так как база Дата акселератора устроена иначе, чем реляционные, мы решили охватить некий спектр условий, чтобы понять в каких вариантах можно получить ускорение. Для этого взяли двух пользователей — полноправного и с ограниченными правами, пару видов отборов и разные вариации периодов отчетов.
Отчет «Отчет о прибылях и убытках»
Отборы:
- «Без отборов» — подразумевает только отбор по периоду, без иных отборов.
- «Узкий отбор» — включает в себя отбор по одному элементу в полях «ЦФО», «подразделение» и «статья затрат».
Результаты замеров:
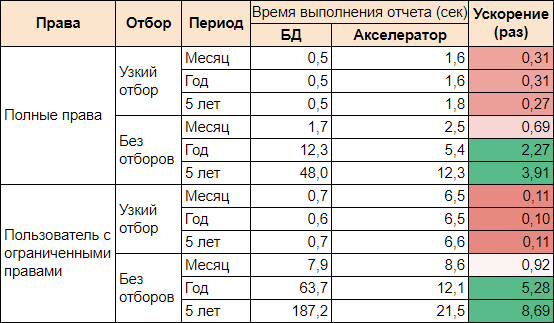
Как можно заметить при достаточно узких отборах время выполнения отчета в Дата акселераторе оказалось больше, чем в СУБД, в то время как на широких выборках данных получили существенное ускорение. Выгодность акселератора видна на больших объемах данных, при этом с увеличением выборки время выполнения вырастает незначительно.
Отчет «Сравнительный анализ ключевых показателей»
Отборы:
- «Без отборов» — по условиям бизнес-логики отчет не может быть выполнен без отборов по полю «Ключевой показатель», так что этот вариант включает в себя отбор по списку из 16-ти часто используемых показателей.
- «Узкий отбор» — включает в себя тот же отбор по показателям + отбор по одному элементу в полях «ЦФО» и «подразделение».
Данный отчет необычный — процесс его формирования состоит из нескольких этапов:
- Сначала выполняется СКД, которая получает данные показателей из регистра сведений «Значимые показатели».
- Далее программно готовится специальная разряженная таблица этих данных.
- И после передается в виде внешнего набора данных в другую СКД, в которой происходит агрегация, вычисление по ряду формул.
Поэтому для наглядности мы замерили два параметра:
- время получения данных показателей;
- общее время формирования отчета.
Результаты замеров:
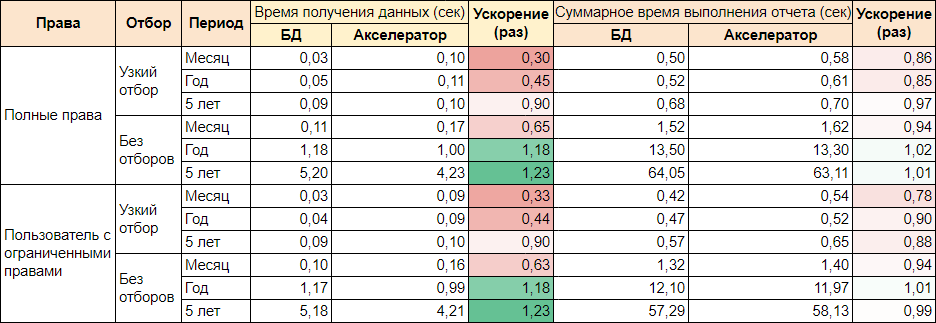
Здесь можно отметить, что как и в предыдущем замере — мы видим ускорение выборки с широким отбором. Но в текущем отчете львиную долю времени выполнения составляет не выборка данных, а их программная обработка и формирование СКД через внешний набор данных — таблицу значений. На эти этапы Дата акселератор конечно никак не мог существенно повлиять, поэтому суммарное время выполнения почти не изменилось, а в случае малых выборок даже увеличилось.
К чему обращается система
Пару слов о том, чем можно отследить работу с Дата акселератором — в логе технологического журнала появились новые события.
Событие DBDA
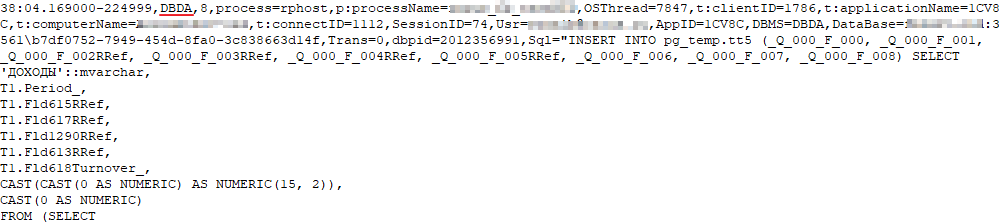
Данное событие является аналогом событий DBMSSQL и DBPOSTGRS, оно отражает исполнение операторов в базе данных Дата акселератора.
В наши тестах, когда мы выполняли запрос в Дата акселераторе, в логе ТЖ вместо события DBPOSTGRS:
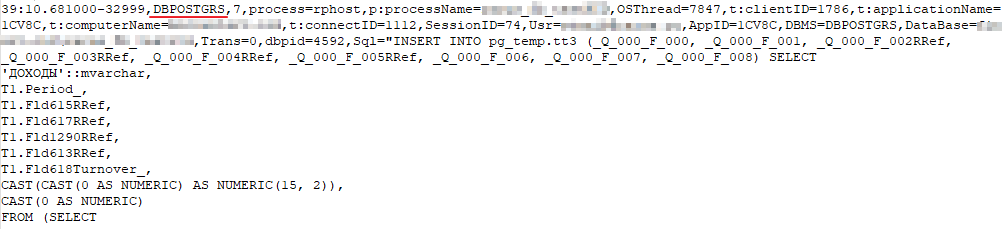
Появлялось событие DBDA:
Событие DBCOPIES
Описание с ИТС: «Работа с копиями базы данных».
По нашим наблюдениям, это событие возникает при обслуживании копии БД. Например, при обновлении, как в этом событии:

Или при изменении состава копии:

Другое
Также литерал DBDA стал возможным значением некоторых свойств событий. Подробнее можно ознакомиться в руководстве администратора на ИТС (its.1c.ru/db/v8321doc#bookmark:adm:TI000000841).
Заключение
- Дата акселератор — нормальный рабочий инструмент, позволяющий существенно ускорять именно выборку больших объемов данных.
- Однако, чтобы добиться ускорения надо применять с умом и в нужных местах.
- Мы продолжим с ним работать и адаптировать его для ускорения системы и делиться результатами исследований с вами.
От экспертов «1С-Рарус»

















