

Оглавление
- Архитектура MS SQL Server, структура TempDB
- Значение временных таблиц для 1С
- Потенциальные проблемы производительности из-за TempDB
- Рекомендации по настройке TempDB
- Практические кейсы
- Работа с временными таблицами в PostgreSQL
- Заключение
Архитектура MS SQL Server, структура TempDB
Когда речь заходит про взаимодействие платформы «1С:Предприятие 8» с системой управления базами данных (СУБД), то обычно подразумевается непосредственное взаимодействие с самой пользовательской базой. Однако это совсем не так. Ведь платформа явно и неявно выполняет взаимодействие и со служебными базами данных. Например, если один из пакетов запроса помещается во временную таблицу, то в момент его выполнения СУБД потребуется его где-то разместить. В Microsoft SQL Server данная временная таблица разместится в служебной базе данных TempDB.

Данная база предназначена для хранения различных временных сущностей, которые создаются как явно, так и не явно. К создаваемым явно можно отнести временные таблицы и их индексы. А операции создаваемые и выполняемыми ядром системы происходят не явно.
Из наиболее известных — это промежуточные результаты сортировок и объединений, вызванных операциями «Упорядочить», «Сгруппировать» и «Объединить», также версии строк данных для поддержки уровней изоляции транзакций, результаты операций хэш-соединений и т. п. Кроме этого в TempDB размещаются и множество сущностей, которые не используются в 1С и могут быть неизвестны 1С разработчикам. Например, временные хранимые процедуры, табличные переменные и курсоры.
При этом из-за того, что TempDB доступен всем базам данным и соединениям, то влияние на него оказывают не только базы на платформе «1С:Предприятие 8», а все размещенные в экземпляре сервера. К чему мы вернемся в следующих разделах, а пока давайте поговорим о том, как и что из себя представляет TempDB физически.
С точки зрения хранения TempDB практически не отличается от других баз данных. Она точно также представляет из себя файлы данных и файл журнала транзакции.

Файлы данных — это файлы, в которых хранятся создаваемые данные и делятся на два вида:
- Первичные имеют расширение .mdf (master data file). Кроме временных данных, также содержат сведения, необходимые для запуска базы данных. На одну базу может быть только один первичный файл данных.
- Вторичные имеют расширение .ndf (not master data file) и не являются обязательными. Основное их назначение — повышение производительности за счет распределения нагрузки операций чтения и записи по разным ядрам процессора. Количество вторичных файлов можно изменять, а изначальное значение устанавливается при установке экземпляра сервера.

Файл журнала транзакций — это файл с расширением .ldf (log data file), в который записывается вся информация о выполненных действиях, используемая для обеспечения целостности и восстановления данных в базе. Однако в отличии от прочих баз данных в журнал транзакций TempDB фиксируется в минимальном объеме.
Прежде всего это связано с тем, что TempDB не поддерживает возможность создания резервных копий для восстановления и при каждом запуске SQL Server создается заново. Ведь на то сущности и временные, что не должны использоваться в следующих сеансах. Многие любители хранения вещей тут бы могли поспорить, но SQL Server так не думает, а повлиять мы на него сможем.
А если создается заново, то с какими параметрами она создается? В этом плане TempDB не отличается от других баз, созданных в SQL Server. Т. е. создается на основании служебной базы данных Model, которая является шаблоном для всех новых баз и хранит настройки по умолчанию.
К чему была оговорка «созданных в SQL Server»? Когда мы говорим про создание новых баз из технологической платформы, то после штатного поведения SQL Server технологическая платформа выполняет ряд манипуляций, необходимых для ее корректной работы. Из наиболее известных действий: установка свойства уровня изоляции транзакций по умолчанию, а также при использовании режима совместимости 8.3 параметр «Is Read Committed Snapshot On» включается в истину. Подробно про данные действия мы говорили на 1C-RarusTechDay 2022 и в статье «Блокировки в 1С при работе с внешними источниками данных и блокировки на схемах в MS SQL».
Таким образом, временные данные в SQL Server хранятся в служебной базе данных TempDB, которая представляет из себя набор файлов с данными и журналом транзакций. Однако, перед тем как записать новый набор записей системе необходимо понять, в какой из файлов данных нужно произвести запись. Что же ей для этого нужно сделать?
Логически все файлы данных разделены на страницы, в которых и размещаются временные данные. Одна страница содержит всего 8 КБ информации, а все операции ввода-вывода SQL Server производятся страницами целиком. Соответственно, когда в плане запросов можно увидеть показатель количества логических чтений, то речь идет о количестве считанных страниц данных.
Сами страницы состоят из трех частей:
- Заголовок, содержащий системные данные о странице.Такие как номер страницы и объем свободного места.
- Строки с данными, которые заполняются последовательно.
- Таблица смещения строк, которая фиксирует позицию строк данных от начала страницы. Данная таблица помогает SQL Server быстро находить строки на странице.

Набор из восьми физически непрерывных страниц называется экстентом. Данные наборы позволяют SQL Server эффективно управлять страницами. При этом они могут быть однородными — принадлежащими одной сущности, и смешанными — когда страницы принадлежат нескольким сущностям:

Когда выполняются запросы на создание новых или удаление текущих записей, система с помощью служебных страниц быстро определяет нужные экстенты и страницы в них. За состояние занятости экстентов отвечают служебные страницы: «Глобальная карта распределения» (GAM) и «Общая глобальная карта распределения» (SGAM). Данные карты отличаются лишь тем, что в GAM хранится информация об однородных экстентах, а в SGAM — смешанных.
А вот за определение свободных мест на страницах отвечают страницы — «Свободное место на страницах» (PFS).
Более подробно про страницы и управление экстентами можно ознакомиться в официальной документации learn.microsoft.com/ru-ru/sql/relational-databases/pages-and-extents-architecture-guide?view=sql-server-ver15.
Значение временных таблиц для 1С
Для технологической платформы немаловажную роль занимает использование временных таблиц и TempDB соответственно.
Если раньше их применение было скорее исключением. Сейчас практически любой сложный запрос состоит из нескольких временных таблиц, а иногда и не нескольких.
В одном из наших продуктов есть запрос состоящий из 107 пакетов и порядка 80 временных таблиц. Данный запрос предназначен для консолидации информации о продажах и возвратах и подготовки к заполнения учетных документов. Переход на использование запроса позволило значительно повысить скорость выполнения данной математики и рассказ о математике заслуживает отдельную статью.

Почему же разработчики стали активнее использовать временные таблицы?
Во-первых, данный подход позволяет оптимизатору запросов СУБД подбирать более точные и оптимальные планы запросов, тем самым увеличив скорость, а также стабильность их выполнения.
Во-вторых, данная рекомендация передается в сообществе 1С со значительной скоростью.
И в-третьих, данная рекомендация зафиксирована в отдельном разделе стандартов разработки 1С its.1c.ru/db/v8std/content/777/hdoc.
Причем зафиксировав данную рекомендацию в стандартах разработки, разработчики фирмы 1С проговорили также ситуации, когда не стоит использовать временные таблицы. Ведь их неосторожное применение может спровоцировать целый ряд проблем с производительностью.
Наиболее критичные ситуации, когда не стоит использовать временные таблицы:
- Не следует создавать временные таблицы с очень большим количеством строк (более сотни тысяч). Т. к. большой объем может спровоцировать потребление памяти и увеличение объема файлов данных TempDB.
ВЫБРАТЬ * ПОМЕСТИТЬ ПродажиЗаВсеГодыРаботы ИЗ РегистрНакопления.Продажи КАК Продажи
- Не следует помещать во временные таблицы поля, которые не будут использоваться в следующих запросах. Ведь лишние поля занимают объем, а также их инициализация приводит дополнительным временным затратам.
ВЫБРАТЬ Номенклатура.Наименование КАК Наименование, Номенклатура.Изготовитель КАК ПолеАВдругПригодится ПОМЕСТИТЬ ВТ_НоменклатураСЛишнимиПолями ИЗ Справочник.Номенклатура КАК Номенклатура ; //////////////////////////////////////////////////////////////////////////////// ВЫБРАТЬ Номенклатура.Наименование КАК Наименование ИЗ ВТ_НоменклатураСЛишнимиПолями КАК Номенклатура
- Не стоит создавать временную таблицу только для того, чтобы ее переименовать.
ВЫБРАТЬ * ПОМЕСТИТЬ ВТ_НоменклатураСНовымНазванием ИЗ ВТ_НоменклатураСоСтарымНазванием КАК ВТ_Номенклатура
Немаловажную роль в данном стандарте занимает и ответ про индексирование временных таблиц. «Народная» рекомендация, особенно при сертификации на 1С:Специалиста, гласит: «Всегда индексируйте все поля, по которым будут соединения». На самом деле вопрос не так прост, как кажется. Ведь индексирование само по себе требует времени и места в памяти.
Потому разработчики фирмы 1С в стандарте явно говорят, что не следует индексировать таблицы с количеством строк меньше 1 000. Потому что оптимизатор запросов может не использовать индексирование, посчитав выгоду от его использования, а вот затраты на построение будут.

Потенциальные проблемы производительности из-за TempDB
Если использование TempDB так важно при работе с платформой «1С:Предприятие», то к чему может привести неправильная настройка СУБД и конфигурирование мощностей?
База данных TempDB является общим ресурсом и доступна всем базам данных экземпляра SQL Server. Особенно базы на платформе «1С:Предприятие 8» активнейшим образом эксплуатируют TempDB. Физически это операции записи в базу TempDB и чтение из нее. Следовательно если данные операции производятся на медленных дисках, то появятся задержки в выполнении операций, а чем активнее будут использоваться временные таблицы, тем больше задержек будет проявляться.
При этом данные задержки могут привести к дополнительным неприятным последствиям. Ранее мы выяснили, что при выполнении операций с TempDB SQL Server работает с рядом служебных страниц: «Глобальная карта распределения» (GAM) и «Общая глобальная карта распределения» (SGAM). Данные страницы отвечают на вопрос, где выполняется работа в файлах данных TempDB. При выполнении операций чтения и записи системе нужно ответить на данный вопрос. Однако их ожидание может сформировать очередь, что приведет к различным конфликтам СУБД.
Следующей неприятностью является запуск расширения файлов данных TempDB из-за неправильной настройки, что приводит к нагрузке на процессор и диски. Основной причиной данного поведения является указания небольшого размера файлов данных. Ведь тогда после каждого перезапуска экземпляра SQL Server потребуется доводить данное значение до рабочей нагрузки. А сделать это весьма легко, т. к. по умолчанию оно состоит всего 8 МБ на файл данных, чего точно может не хватать.
Особенно малое значение размера файлов данных неприятно в паре с малым значением размера приращения роста файлов данных. Потому что при необходимости выделения дополнительной памяти потребуется выполнить данную операцию множество раз, а это также приведет к нагрузке процессора и диски.
Для демонстрации нагрузки на мощности при указании малых показателей размера файлов данных и прироста давайте проведем следующий эксперимент.
Нам потребуется:
- СУБД: Microsoft SQL Server;
- размер файла данных TempDB: 8 МБ;
- размер автоприращения роста файлов TempDB: 64 МБ.

Далее выполним следующий запрос с созданием временной таблицы и помещением в нее результатов:
CREATE TABLE #ВременнаяТаблицаДляПримера ( Идентификатор varchar(256) NOT NULL ); INSERT INTO #ВременнаяТаблицаДляПримера (Идентификатор) VALUES ('38a4cfd1-6842-44af-a7fd-d0561d2f58df'), ('b3556487-86d1-4ada-ad8f-79eaf9cb1a5d'), ('c2c1fa37-f800-4454-a95a-970ad6ed9b2e'), ('fe3f83d7-39ee-41f3-b8fb-04408a8d62a3'), ('2f18049f-caee-4484-afbd-46f400270031'), ('aef12cf4-7027-4e0d-b424-05d81381813f'), ('061ca93e-143b-4e9a-9750-e8aa98904f09'), ('94f85232-8ef2-463c-ae34-7dbb3506b8fe'), ('0c3dbd0f-63bc-46b9-89ae-ca71d88a0c82'), ('a3cebdb3-04fd-4be2-95fa-9132e933e4aa') ; INSERT INTO #ВременнаяТаблицаДляПримера SELECT ВТ_ДляПримера1.Идентификатор FROM #ВременнаяТаблицаДляПримера AS ВТ_ДляПримера1, #ВременнаяТаблицаДляПримера AS ВТ_ДляПримера2, #ВременнаяТаблицаДляПримера AS ВТ_ДляПримера3, #ВременнаяТаблицаДляПримера AS ВТ_ДляПримера4, #ВременнаяТаблицаДляПримера AS ВТ_ДляПримера5, #ВременнаяТаблицаДляПримера AS ВТ_ДляПримера6, #ВременнаяТаблицаДляПримера AS ВТ_ДляПримера7, #ВременнаяТаблицаДляПримера AS ВТ_ДляПримера8, #ВременнаяТаблицаДляПримера AS ВТ_ДляПримера9, #ВременнаяТаблицаДляПримера AS ВТ_ДляПримера10 ;
В результате его выполнения можно увидеть рост потребления оперативной памяти, а также скачкообразное влияние на диски.


Таким образом, неправильная настройка параметров TempDB может приводить к различным проблемам производительности от задержек при выполнении операции до загрузки дисков под 100%.
Рекомендации по настройке TempDB
К чему может привести неправильная настройка мы уже выяснили. Самое время рассмотреть, что нужно сделать, чтобы уменьшить вероятность проблем с TempDB.
Количество файлов данных и их размер, размер автоприращения
Для начала необходимо выполнить настройку основных параметров:
- количество файлов данных;
- размер файла данных;
- размер автоприращения роста файла данных.
Изначально они указываются при установке Microsoft SQL Server в момент настройки ядра СУБД:

Однако, если указанное значение не подходит или вы хотите проверить их, то можно воспользоваться Management Studio. Далее вызывать контекстное меню базы TempDB, перейти в Свойства (Property) и открыть вкладку Files:


Для того, чтобы определить, какое количество файлов необходимо системе стоит оттолкнуться от количества ядер процессора:
- Если ядер процессора больше 8, то рекомендуется использовать 8 файлов данных.
- Если меньше или равно, то по количеству ядер: 1–1, 2–2, 4–4, 8–8.
В случае, если будут появляться ожидания с типом «PAGELATCH_UP», которые будут проявляться как задержки при выполнении операций и будут фиксироваться выполнением следующего запроса:
SELECT session_id as НомерСессии, wait_type as ТипОжидания, resource_description as ОписаниеРесурса FROM sys.dm_os_waiting_tasks WHERE wait_type = 'PAGELATCH_UP'
То необходимо постепенно увеличивать количество файлов данных на 4, пока ожидания не пропадут.
Стоит отметить, что при несоблюдение данной рекомендации никто не гарантирует, что при росте системы вы неожиданно не столкнетесь с кратковременными страничными блокировками в TempDB.
Для ручного создания дополнительных файлов данных можно воспользоваться кнопкой «Добавить» на форме свойств TempDB:

Или же воспользоваться следующим скриптом:
USE [master] GO ALTER DATABASE [tempdb] ADD FILE ( NAME = N'tempdev1', FILENAME = N'ПутьКФайламTempDB\tempdb1.ndf' , SIZE = РазмерФайлаДанныхKB , FILEGROWTH = РазмерАвтоприращенияKB ) GO ALTER DATABASE [tempdb] ADD FILE ( NAME = N'tempdev2', FILENAME = N'ПутьКФайламTempDB\tempdb2.ndf' , SIZE = РазмерФайлаДанныхKB , FILEGROWTH = РазмерАвтоприращенияKB ) GO ALTER DATABASE [tempdb] ADD FILE ( NAME = N'tempdev3', FILENAME = N'ПутьКФайламTempDB\tempdb3.ndf' , SIZE = РазмерФайлаДанныхKB , FILEGROWTH = РазмерАвтоприращенияKB ) GO ALTER DATABASE [tempdb] ADD FILE ( NAME = N'tempdev4', FILENAME = N'ПутьКФайламTempDB\tempdb4.ndf' , SIZE = РазмерФайлаДанныхKB , FILEGROWTH = РазмерАвтоприращенияKB ) GO ALTER DATABASE [tempdb] ADD FILE ( NAME = N'tempdev5', FILENAME = N'ПутьКФайламTempDB\tempdb5.ndf' , SIZE = РазмерФайлаДанныхKB , FILEGROWTH = РазмерАвтоприращенияKB ) GO ALTER DATABASE [tempdb] ADD FILE ( NAME = N'tempdev6', FILENAME = N'ПутьКФайламTempDB\tempdb6.ndf' , SIZE = РазмерФайлаДанныхKB , FILEGROWTH = РазмерАвтоприращенияKB ) GO ALTER DATABASE [tempdb] ADD FILE ( NAME = N'tempdev7', FILENAME = N'ПутьКФайламTempDB\tempdb7.ndf' , SIZE = РазмерФайлаДанныхKB , FILEGROWTH = РазмерАвтоприращенияKB ) GO
Где:
ПутьКФайламTempDB — это путь к файлам данных TempDB.
РазмерФайлаДанных — размер файла данных в килобайтах.
РазмерАвтоприращения — размер автоприращения в килобайтах.
Размер файлов данных должен быть достаточен для обеспечения штатной нагрузки. Если вам неизвестен данный показатель, то можно оттолкнуться от значения по умолчанию, а после понаблюдать до какого значения система будет увеличивать его при рабочей нагрузке.
Для выяснения текущих значений можно воспользоваться следующим скриптом:
SELECT СистемнаяИнформация.name AS ИмяФайла, СистемнаяИнформация.size*1.0/128 AS РазмерФайлаВ_МБ, CASE СистемнаяИнформация.max_size WHEN 0 THEN 'Увеличение размера запрещено' WHEN -1 THEN 'Увеличение размера до полного заполнения диска' ELSE 'Увеличение размера до 2 ТБ' END AS МаксимальныйРазмер, CASE WHEN СистемнаяИнформация.growth = 0 THEN СистемнаяИнформация.growth WHEN СистемнаяИнформация.growth > 0 AND СистемнаяИнформация.is_percent_growth = 0 THEN СистемнаяИнформация.growth*1.0/128.0 WHEN СистемнаяИнформация.growth > 0 AND СистемнаяИнформация.is_percent_growth = 1 THEN СистемнаяИнформация.growth END AS РазмерПриращения, CASE WHEN СистемнаяИнформация.growth = 0 THEN 'Фиксированный и не будет увеличиваться' WHEN СистемнаяИнформация.growth > 0 AND СистемнаяИнформация.is_percent_growth = 0 THEN 'МБ' WHEN СистемнаяИнформация.growth > 0 AND СистемнаяИнформация.is_percent_growth = 1 THEN '%' END AS ЕдиницаИзмеренияПриращения FROM tempdb.sys.database_files AS СистемнаяИнформация; GO

При этом желательно применять одинаковый размер файлов для всех файлов данных в каждой файловой группе. Данная рекомендация обеспечивает эффективное использование TempDB с высокой степенью параллелизма. Прежде всего это связано с используемым SQL Server алгоритмом пропорционального заполнения, который повышает вероятность выделения памяти в файлах с большим объемом свободного пространства.
Размер автоприращения роста файлов также должен быть одинаковый и не должен быть слишком малым по сравнению с объемом записываемых данных в TempDB. Иначе системе потребуется выполнять многократное повторение расширения, что скажется на производительности. Рекомендуем значение от 512 МБ до 5 ГБ.
Для установки значений необходимо вызвать форму указания параметров из строки файла по колонке «Автоприращение /Максимальный размер» на вкладке Files:

При использовании Microsoft SQL Server до версии 2016 и указании нескольких файлов данных разработчики Microsoft рекомендует включать следующие флаги трассировки:
- 1117, который позволяет одновременно увеличивать размер всех файлов одной файловой группы. Данная операция позволит избежать разбалансирования размеров файлов при постоянном приросте TempDB, что в свою очередь позволит наиболее оптимально применять ранее упомянутый алгоритм пропорционального заполнения.
- 1118, который отключает использование смешанных экстентов, что уменьшает вероятность конфликтов на страницах SGAM. Т. е. система изначально будет размещать временные объекты в однородных экстентах и при их увеличении размера не будет выполнять перенос.
Включить данные флаги трассировки можно с помощью запросов:
DBCC TRACEON (1117, -1); DBCC TRACEON (1118, -1);
При использовании версии 2016 и выше установка данных флагов не требуется по причине их преобразования в соответствующие настройки баз данных и включения по умолчанию.
Вынесение файлов TempDB на отдельные накопители
Давайте двигаться дальше. Следующей рекомендацией является размещение файлов TempDB на отдельных физических дисках, нежели файлы данных и журналы информационных баз данных. Это позволит повысить производительность за счет параллельной работы дисков.
Для перемещения файлов TempDB можно воспользоваться скриптом:
USE master; GO ALTER DATABASE tempdb MODIFY FILE (NAME = tempdev, FILENAME = 'ПутьКНовомуРазмещению\tempdb.mdf'); GO ALTER DATABASE tempdb MODIFY FILE (NAME = templog, FILENAME = 'ПутьКНовомуРазмещению\templog.ldf'); GO
Где, соответственно, ПутьКНовомуРазмещению — это путь к новому каталогу.
После выполнения скрипта потребуется выполнить перезапуск службы экземпляра сервера.
Также важно размещение файлов данных TempDB на быстрых дисках. Это могут быть как SSD, так и RAMDisk. При этом скорость выполнения операций чтения и записи должна быть равной в степени велика, как и лимит данных операций.
Стоит отметить, что некоторые тесты проводимые сообществом демонстрируют схожие показатели производительности при использовании NVMe SSD в сравнении с RAM. Потому приобретение более дорогих RAMDisk может не дать соответствующего эффекта.
Что же касается рекомендации о разделении файлов данных и журнала транзакций на разные физические диски, которую обычно дают для обычных баз данных, то в отличии от них у TempDB используется сокращенный журнал транзакций. Потому нагрузка на него значительно ниже и необходимость в разделении, при использовании рекомендованных быстрых дисков, практически отсутствует. Однако, если же вы используете медленные жесткие диски и столкнулись с конфликтами операций чтения и записи, то разделив их на разные диски действительно можно снизить нагрузку.
Практические кейсы
Ознакомившись с базовыми понятиями и архитектурой TempDB давайте поговорим о расследованиях связанных с нею, с которыми мы столкнулись на практике.
Увеличение размеров файлов данных TempDB при групповом перепроведении документов
Первая ситуация произошла с крупным кейтеринговым предприятием, которое использует типовую конфигурацию «1С:УНФ 8. Управление предприятием общепита» для автоматизации своей деятельности.
После выхода очередного релиза они столкнулись с проблемой, когда в момент выполнения группового перепроведения документов файлы данных TempDB вырастали до 80 ГБ. Хотя под штатной нагрузкой значения не достигали 20 Гб и столь стремительный рост размера файлов казался не совсем здоровым.
Инфраструктура исследуемой системы
- Программный продукт: 1С:УНФ 8. Управление предприятием общепита.
- База данных: Microsoft SQL Server 2012.
- Платформа 1С:Предприятие 8: 8.3.20.1710 64х.
- Операционная система: Windows Server 2012 R2.
- Процессор: Intel Xeon Silver 4210 CPU @ 2.2GHz.
- Оперативная память: 256 GB.
- SSD: 3 TB.
В этот же период проходило расследование связанное с длительным групповым перепроведением, про которое мы подробно рассказывали в статье рубрики от экспертов «1С-Рарус» https://rarus.ru/publications/20221228-ot-ekspertov-1c-index-management-mssql-postgresql-568557/.
При расследовании была сформулирована гипотеза, что виновником является какой-то запрос, который выбирает 430 млн записей:

Чтение и обработка большого количества строк при выполнении операции сортировки и хэширования, да еще и временных таблиц — действительно может приводить к увеличению файлов данных TempDB. Однако является ли именно данный запрос виновником — требуется доказать.
Чтобы это сделать нам потребовалось:
- Выяснить временной диапазон, в котором произошел рост TempDB.
- По собранным логам расширенных событий SQL Server узнать тексты и планы запросов, выполняемых в этот момент на стороне СУБД, а также сопоставить их с логами технологического журнала 1С.
Настройка счётчиков производительности, сбор данных по событиям и логам технологического журнала
Для этого в первую очередь мы подготовили сбор информации о производительности с помощью системного монитора (Performance monitor) Windows. Интересуют нас следующие счетчики:
- SQLServer:Databases(tempdb)\Data File(s) Size (KB);
- Memory\Available Mbytes;
- Memory\Pages/sec;
- PhysicalDisk(_Total)\Avg. Disk Queue Length;
- PhysicalDisk(_Total)\Avg. Disk sec/Transfer.

Далее для выяснения текста и плана выполняемых запросов настроили сбор Extended Events по событиям sql_batch_completed, rpc_completed и query_post_execution_showplan. Для этого в Management Studio можно выполнить следующий запрос:
CREATE EVENT SESSION [rarus_analize] ON SERVER ADD EVENT sqlserver.query_post_execution_showplan( ACTION(sqlserver.sql_text) WHERE ([sqlserver].[equal_i_sql_unicode_string]([sqlserver].[database_name],N'base_name'))), ADD EVENT sqlserver.rpc_completed( WHERE ([sqlserver].[equal_i_sql_unicode_string]([sqlserver].[database_name],N'base_name'))), ADD EVENT sqlserver.sql_batch_completed( ACTION(sqlserver.sql_text) WHERE ([sqlserver].[equal_i_sql_unicode_string]([sqlserver].[database_name],N'base_name'))) ADD TARGET package0.event_file(SET filename=N'rarus_analize') WITH (MAX_MEMORY=4096 KB,EVENT_RETENTION_MODE=ALLOW_SINGLE_EVENT_LOSS,MAX_DISPATCH_LATENCY=30 SECONDS,MAX_EVENT_SIZE=0 KB,MEMORY_PARTITION_MODE=NONE,TRACK_CAUSALITY=OFF,STARTUP_STATE=OFF) GO
Или же создать его вручную с помощью конструктора. Для этого в ветке Management — Extended Events — Session необходимо вызвать контекстное меню и выбрать New Session. После чего на вкладке Events выбрать ранее указанные события:


После создания новой сессии потребуется запустить сбор событий:

Остается настроить сбор логов технологического журнала по событиям CALL, SDBL, DBMSSQL, чтобы связать выполняемые запросы в СУБД с соответствующими в 1С.
Полный текст файла logcfg.xml:
<?xml version="1.0" encoding="UTF-8"?> <config xmlns="http://v8.1c.ru/v8/tech-log"> <log history="24" location="d:\logs"> <property name="all"/> <event> <eq property="name" value="CALL"/> <eq property="p:processName" value="base_name"/> </event> <event> <eq property="name" value="SDBL"/> <eq property="p:processName" value="base_name"/> </event> <event> <eq property="name" value="DBMSSQL"/> <eq property="p:processName" value="base_name"/> </event> </log> <dump location="d:\dumps\" create="1" type="0" externaldump="1"/> </config>
Завершив подготовку, запустим сбор всех материалов и выполним операцию группового перепроведения документов:

В результате проведенного эксперимента получаем следующую картину со счетчиками производительности:

Обратим внимание на счетчик «SQLServer:Databases(tempdb)\Data File(s) Size (KB)» на котором виден рост размера базы данных TempDB:

События технологического журнала и расширенные события фиксируются только по факту выполнения операций. Потому нас будут интересовать события, которые выполнялись от начала роста и до стабилизации. Стоит отметить, что они могут быть зафиксированы и когда рост TempDB завершился.
Основываясь на данных ограничениях посмотрим на выполняемые в этот момент запросы в SQL Server:

Можно увидеть, что в период с 13:58 по 14:23 события отсутствовали, но по продолжительности события в 14:23 получаем, что все это время выполнялся данный запрос:
INSERT INTO #tt12 WITH(TABLOCK) (_Q_001_F_000, _Q_001_F_001_TYPE, _Q_001_F_001_RTRef, _Q_001_F_001_RRRef, _Q_001_F_002RRef, _Q_001_F_003RRef, _Q_001_F_004, _Q_001_F_005, _Q_001_F_006, _Q_001_F_007, _Q_001_F_008, _Q_001_F_009, _Q_001_F_010, _Q_001_F_011, _Q_001_F_012) SELECT T1._Q_001_F_000, T1._Q_001_F_003_TYPE, T1._Q_001_F_003_RTRef, T1._Q_001_F_003_RRRef, T1._Q_001_F_006RRef, T1._Q_001_F_009RRef, T1._Q_001_F_007, CASE WHEN (T1._Q_001_F_003_TYPE = 0x08 AND T1._Q_001_F_003_RTRef = 0x00000289) THEN 0x01 WHEN NOT (T1._Q_001_F_003_TYPE = 0x08 AND T1._Q_001_F_003_RTRef = 0x00000289) THEN 0x00 END, MIN(T2._Q_001_F_007), T1._Q_001_F_001, T1._Q_001_F_002, T1._Q_001_F_004, T1._Q_001_F_005, T1._Q_001_F_008, ISNULL(T3._Q_001_F_001,0.0) FROM #tt10 T1 WITH(NOLOCK) LEFT OUTER JOIN #tt10 T2 WITH(NOLOCK) ON (T1._Q_001_F_006RRef = T2._Q_001_F_006RRef) AND (T1._Q_001_F_000 <= T2._Q_001_F_000) AND (T1._Q_001_F_007 < T2._Q_001_F_007) LEFT OUTER JOIN #tt11 T3 WITH(NOLOCK) ON (T1._Q_001_F_003_TYPE = T3._Q_001_F_000_TYPE AND T1._Q_001_F_003_RTRef = T3._Q_001_F_000_RTRef AND T1._Q_001_F_003_RRRef = T3._Q_001_F_000_RRRef) GROUP BY T1._Q_001_F_000, T1._Q_001_F_003_TYPE, T1._Q_001_F_003_RTRef, T1._Q_001_F_003_RRRef, T1._Q_001_F_006RRef, T1._Q_001_F_009RRef, T1._Q_001_F_008, T1._Q_001_F_007, T1._Q_001_F_001, T1._Q_001_F_002, T1._Q_001_F_004, T1._Q_001_F_005, ISNULL(T3._Q_001_F_001,0.0)
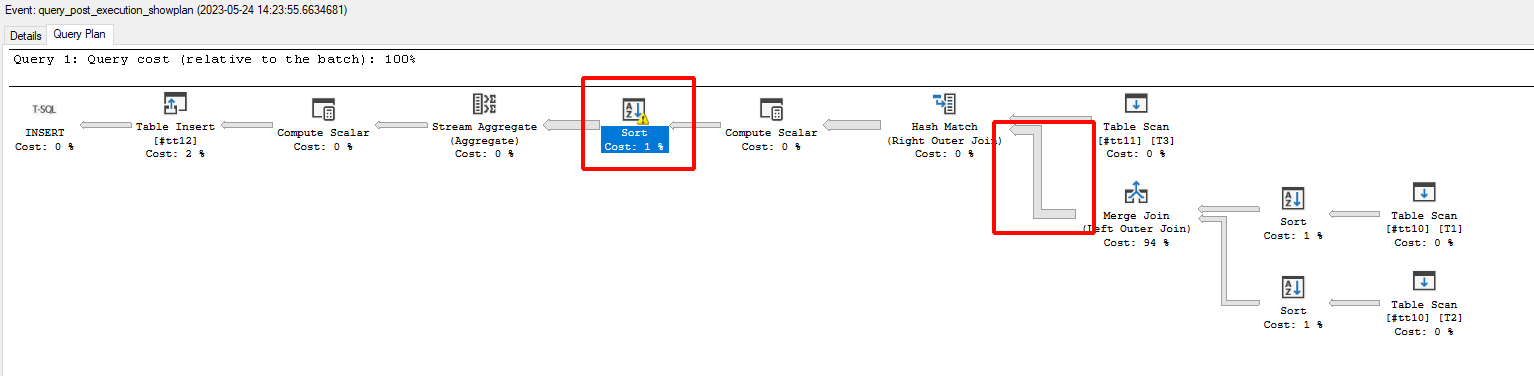
Если присмотреться к плану запросов, то можно увидеть знак предупреждения у операции Sort. В его описании сообщается об использовании TempDB, а также большое количество строк полученное в результате объединение двух временных таблиц:
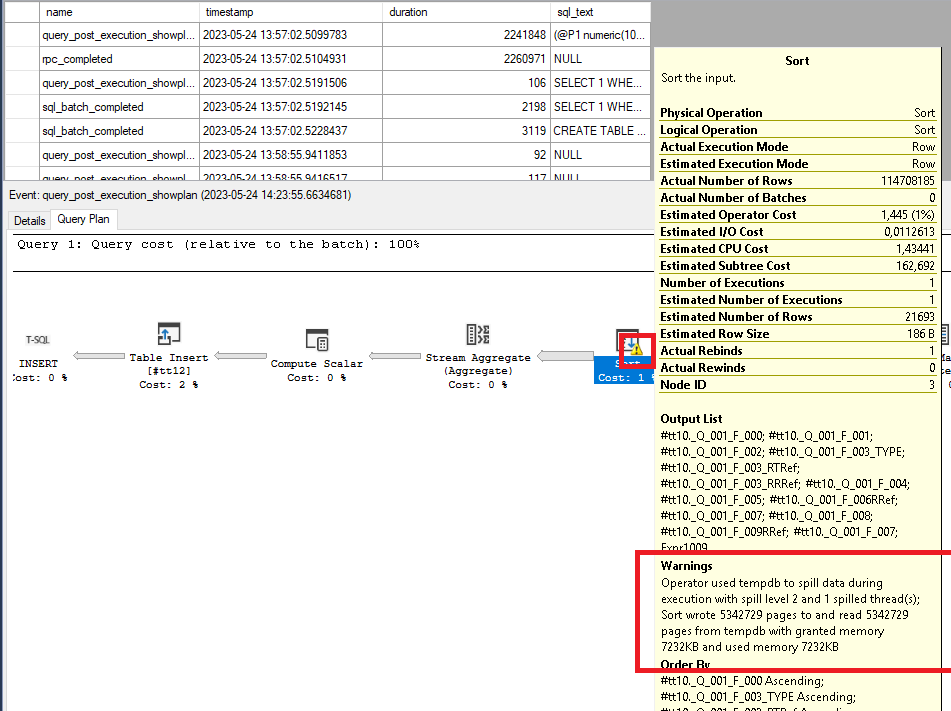
Данное предупреждение фиксируется из-за неточной оценки необходимой памяти для выполнения запроса. Т. е. при подготовке предварительного плана оптимизатор запросов посчитал, что хватит одного объема памяти, а в момент выполнения система замечает, что выделенного объема не хватит и начинает выгружать данные TempDB из буферной памяти, что отрицательно сказывается на производительности запросов.
Для отслеживания ситуаций когда операции сортировки или хэш-соединений начинают выгружать данные в TempDB в SQL Server предусмотрены отдельные расширенные события hash_warning и sort_warning:



Сопоставим обнаруженный проблемный запрос с сохраненным в технологическом журнале, который произошел в этот же промежуток времени:

Оптимизация запроса
Обнаруженный запрос совпадает с предложенным ранее, но теперь нам стало известно, что привело к длительному выполнению и большому потреблению памяти.
Данный запрос выполняет задачу связывание документов на оси времени. Т.е. отвечает на вопрос какой документ будет обрабатываться следующим после данной строки. Для этого происходит их упорядочивание по времени, а чтобы не формировать дополнительный пакет разработчик решил выполнить дополнительное соединение, что привело к не оптимальному плану запросов, обработке большого количества строк и помещению их в TempDB. Если представить упрощенный вариант, то получится такой запрос:
ВЫБРАТЬ ПоследовательностьДокументовИсточник.Дата КАК Дата, ПоследовательностьДокументовИсточник.КлючДокумента КАК КлючДокументаИсточник, МИНИМУМ(ПоследовательностьДокументовПриемник.КлючДокумента) КАК КлючДокументаПриемник, ЕСТЬNULL(ВТ_ОценочнаяСтоимостьДокументов.КоличествоЗаписей, 0) КАК КоличествоЗапасов ПОМЕСТИТЬ ВТ_МатрицаСвязей ИЗ ПоследовательностьДокументов КАК ПоследовательностьДокументовИсточник ЛЕВОЕ СОЕДИНЕНИЕ ПоследовательностьДокументов КАК ПоследовательностьДокументовПриемник ПО ПоследовательностьДокументовИсточник.Организация = ПоследовательностьДокументовПриемник.Организация И ПоследовательностьДокументовИсточник.Дата <= ПоследовательностьДокументовПриемник.Дата И ПоследовательностьДокументовИсточник.КлючДокумента < ПоследовательностьДокументовПриемник.КлючДокумента ЛЕВОЕ СОЕДИНЕНИЕ ВТ_ОценочнаяСтоимостьДокументов КАК ВТ_ОценочнаяСтоимостьДокументов ПО ПоследовательностьДокументовИсточник.Ссылка = ВТ_ОценочнаяСтоимостьДокументов.Регистратор СГРУППИРОВАТЬ ПО ПоследовательностьДокументовИсточник.Дата, ПоследовательностьДокументовИсточник.КлючДокумента КАК КлючДокументаИсточник, ЕСТЬNULL(ВТ_ОценочнаяСтоимостьДокументов.КоличествоЗаписей, 0)
Для того, чтобы оптимизатор запросов мог сформировать более оптимальный план запроса нами было принято решение разбить данный пакет на два: в первом пакете идет дополнение данными, а во втором непосредственное связывание документов:
ВЫБРАТЬ ПоследовательностьДокументовИсточник.Дата КАК Дата, ПоследовательностьДокументовИсточник.Организация КАК Организация, ПоследовательностьДокументовИсточник.КлючДокумента КАК КлючДокументаИсточник, МИНИМУМ(ПоследовательностьДокументовПриемник.КлючДокумента) КАК КлючДокументаПриемник, ЕСТЬNULL(ВТ_ОценочнаяСтоимостьДокументов.КоличествоЗаписей, 0) КАК КоличествоЗапасов ПОМЕСТИТЬ ПоследовательностьДокументов ИЗ ПоследовательностьДокументовБезОценок КАК ПоследовательностьДокументов ЛЕВОЕ СОЕДИНЕНИЕ ВТ_ОценочнаяСтоимостьДокументов КАК ВТ_ОценочнаяСтоимостьДокументов ПО ПоследовательностьДокументов.Ссылка = ВТ_ОценочнаяСтоимостьДокументов.Регистратор ИНДЕКСИРОВАТЬ ПО Организация, Дата, КлючДокумента ; //////////////////////////////////////////////////////////////////////////////// ВЫБРАТЬ ПоследовательностьДокументовИсточник.Дата КАК Дата, ПоследовательностьДокументовИсточник.КлючДокумента КАК КлючДокументаИсточник, МИНИМУМ(ПоследовательностьДокументовПриемник.КлючДокумента) КАК КлючДокументаПриемник, ПоследовательностьДокументовИсточник.КоличествоЗапасов КАК КоличествоЗапасов ПОМЕСТИТЬ ВТ_МатрицаСвязей ИЗ ПоследовательностьДокументов КАК ПоследовательностьДокументовИсточник ЛЕВОЕ СОЕДИНЕНИЕ ПоследовательностьДокументов КАК ПоследовательностьДокументовПриемник ПО ПоследовательностьДокументовИсточник.Дата <= ПоследовательностьДокументовПриемник.Дата И ПоследовательностьДокументовИсточник.КлючДокумента < ПоследовательностьДокументовПриемник.КлючДокумента И ПоследовательностьДокументовИсточник.Организация = ПоследовательностьДокументовПриемник.Организация СГРУППИРОВАТЬ ПО ПоследовательностьДокументовИсточник.Дата, ПоследовательностьДокументовИсточник.КлючДокумента, ПоследовательностьДокументовИсточник.КоличествоЗапасов ;
Повторив эксперимент мы получили более быстрое выполнение без увеличения потребления памяти:


Таким образом, при выполнении запроса система начинала активное потребление памяти и TempDB для выполнения операции соединения. Обнаружив и модернизировав данный запрос получилось избавиться от данного потребления.
Увеличение размера файлов данных TempDB при закрытии месяца
Следующая ситуация произошла с предприятием общественного питания, которое также ведет свою деятельность в «1С:УНФ 8. Управление предприятием общепита».
В момент выполнения операции закрытии месяца происходит резкое потребление памяти на дисках до 200 ГБ. При этом даже спустя 3 часа после операции закрытия ситуация не улучшается.
Попытки принудительного завершения процессов, перезапуск службы экземпляра SQL Server, закрытия месяца по другим организациям не приводят к успеху. Общее настроение клиента можно описать его следующим сообщением: «Коллеги, это ад».
Для тех кто не знаком с механизмом закрытия месяца, то это непростой механизм в ходе которого система анализирует различные показатели за месяц и выполняет корректировки по различным регистрам. Они могут быть самого различного характера: расчет себестоимости выпущенной продукции, распределение амортизации и затрат, расчет финансовых показателей и т. п.:

Данный механизм существует во многих типовых решениях: 1С:ERP, «1С:Бухгалтерия», «1С:Управление нашей фирмой» и других. Ранее мы рассказывали про ускорение и анализ выполняемых операций в 1С:ERP в статьях рубрики от экспертов «1С‑Рарус», а также на конференции 1С-RarusTechDay и конечно рекомендуем к ознакомлению с ними.
Хотя реализация закрытия месяца в разных типовых решений отличается, их идея остается весьма схожей — выполнение ряда операций, для которых требуется обработать данные за месяц и правильно их преобразовать. В этой обработке и кроется проблема — иногда могут потребоваться запросы в цикле, а иногда простой запрос, но получающий большой объем данных.
В связи с этим нагрузка на TempDB может расти как постепенно, так и скачками, а анализировать все временные диапазоны трудозатратно. Так мы и пришли к необходимости более точного мониторинга за происходящим в TempDB.
Если перед вами стоит задача посмотреть, что сейчас происходит в СУБД, то для этого можно воспользоваться готовыми инструментами или же формировать запросы к системным таблицам самостоятельно.
Одним из наиболее известных инструментов является Activity Monitor. Запустить его можно из контекстного меню экземпляра сервера:


К сожалению, в чрезвычайной ситуации, когда все «горит», данный инструмент имеет привычку отваливаться и зависать. Потому сильно на него надеяться не стоит, но при этом если он жив, то проанализировать текущие выполняемые процессы и запросы точно поможет.
Альтернативным решением является анализ системных таблиц с помощью запросов напрямую. Данный подход чуть менее удобный, зато более универсальный и позволяет решить множество задач. Пример запроса для анализа текущих выполняемых запросов в TempDB:
SELECT tst.session_id AS ИдентификаторСессии, tdt.database_transaction_begin_time AS ДатаНачала, tdt.database_transaction_log_record_count AS КоличествоЗаписанныхДанных, tdt.database_transaction_log_bytes_used AS БайтЗанятоТранзакцией, tdt.database_transaction_log_bytes_reserved AS БайтЗарезервированоТранзакцией, SUBSTRING(st.text, (r.statement_start_offset/2)+1, ((CASE r.statement_end_offset WHEN -1 THEN DATALENGTH(st.text) ELSE r.statement_end_offset END - r.statement_start_offset)/2) + 1) AS ТекстВыполняемогоЗапроса, st.text AS ТекстПоследнегоЗапроса, qp.query_plan AS ПланПоследнегоЗапроса FROM sys.dm_tran_database_transactions tdt JOIN sys.dm_tran_session_transactions tst ON tst.transaction_id = tdt.transaction_id JOIN sys.dm_exec_sessions s ON s.session_id = tst.session_id JOIN sys.dm_exec_connections c ON c.session_id = tst.session_id LEFT OUTER JOIN sys.dm_exec_requests r ON r.session_id = tst.session_id CROSS APPLY sys.dm_exec_sql_text (c.most_recent_sql_handle) AS st OUTER APPLY sys.dm_exec_query_plan (r.plan_handle) AS qp WHERE DB_NAME (tdt.database_id) = 'tempdb' ORDER BY БайтЗанятоТранзакцией DESC GO

При этом в SQL Server существует динамические представления для анализа TempDB, которые позволяют проанализировать размеры файлов данных, оценить количество страниц, занимаемых временными таблицами и прочие паказатели.
Речь идет про:
- sys.dm_db_file_space_usage — хранит информацию о файлах данных TempDB
- sys.dm_db_session_space_usage — позволяет анализировать влияние выполненных запросов на TempDB.
- sys.dm_db_task_space_usage — позволяет анализировать влияние выполняемых запросов на TempDB.
Давайте рассмотрим каждый из них на примере.
sys.dm_db_file_space_usage
Данное представление позволяет анализировать пространство каждого файла данных TempDB, т. е.отвечать на вопрос сколько страниц заняли временные таблицы или сколько занимают результаты сортировок и хэш-соединений и т. д.
Перейдем к примеру и выполним запрос на получение всех колонок данного представления:
SELECT * FROM sys.dm_db_file_space_usage AS TempDBTable

Основываясь на результат выполнения можно увидеть, что в экземпляре сервера используется 8 файлов данных, что соответствует настройкам базы данных TempDB:

В колонке total_page_count видно текущее количество страниц до которого расширились файлы. В allocated_extent_page_count и unallocated_extent_page_count — количество занятых и свободных страниц соответственно.
Для нас наиболее интересными являются колонки user_object_reserved_page_count и internal_object_reserved_page_count, т. к в них указан размер и чем именно заняты данные файлы. Например, internal_object_reserved_page_count хранит информацию о размере результатов необходимых для выполнения сортировок, хэш-соединений и прочих внутренних объектов ядра. А user_object_reserved_page_count считает размер занятых пользовательских объектов, например, временными таблицами.
Если выполнить тяжелый запрос с помещением во временные таблицы и выполнением операций сортировки, требующих размещения в TempDB, то можно увидеть как показатели вырастут.

sys.dm_db_session_space_usage и sys.dm_db_task_space_usage
Предлагаем двигаться дальше и рассмотреть представления sys.dm_db_session_space_usage и sys.dm_db_task_space_usage, которые интересны отражением информации о виновниках потребления, т. е. какое соединение с СУБД вызвало запрос на создание и заполнение TempDB. Эта информация будет весьма полезна для сопоставления с логами технологического журнала 1С.
Можно попробовать возразить и сказать, что за помещение во временную таблицу отвечает команда «Поместить» и нечего придумывать. Однако, ранее мы уже говорили, что разработчики 1С очень любят данную команду. Потому как иначе ответить на вопрос, какой из сотен «Поместить» является виновником или какая операция сортировки или группировки повлекла к заполнению TempDB? На все эти вопросы можно ответить анализируя результаты данных представлений.
В частности колонки:
- session_id — Идентификатор сеанса.
- user_objects_alloc_page_count — Количество страниц занятых пользовательских объектов. Например, создание и помещение временных таблиц.
- internal_objects_alloc_page_count — Количество страниц занятых внутренними объектами ядра СУБД. Например, результаты сортировок и хэш-соединений.
- user_objects_dealloc_page_count — Количество страниц освобожденных пользовательских объектов. Например, удаление временных таблиц.
- internal_objects_dealloc_page_count — Количество страниц, освобожденных внутренними объектами ядра СУБД. Например, удаление результатов сортировок и хэш-соединений.
Если попробовать описать процесс их заполнения, то изначально sys.dm_db_task_space_usage сообщает информацию о количестве страниц занятых и освободившихся в данный момент. Если запрос использует параллелизм, то в результате будут отображаться несколько строк выполнения запроса. После завершения выполнения каждого запроса его результаты сворачиваются в sys.dm_db_session_space_usage. Соответственно, в sys.dm_db_session_space_usage хранится информация только о полностью выполненных запросах.
Чтобы в этом убедиться запустим запрос на заполнение временных таблиц, который мы рассматривали в разделе проблем производительности.
Параллельно будем выполнять запрос на получение информации о занятом объеме каждой сессией по представлениям:
SELECT CURRENT_TIMESTAMP, session_id, user_objects_alloc_page_count, internal_objects_alloc_page_count FROM sys.dm_db_session_space_usage AS TempDBTable WHERE database_id=DB_ID('tempdb') and (user_objects_alloc_page_count > 0 or internal_objects_alloc_page_count > 0) ; SELECT CURRENT_TIMESTAMP, session_id, user_objects_alloc_page_count, internal_objects_alloc_page_count FROM sys.dm_db_task_space_usage AS TempDBTable WHERE database_id=DB_ID('tempdb') and (user_objects_alloc_page_count > 0 or internal_objects_alloc_page_count > 0) ;
При выполнении можно заметить, что пока запрос выполняется он виден лишь в sys.dm_db_task_space_usage:

Однако, как только запрос будет считаться выполненным, то он станет видным в sys.dm_db_session_space_usage и пропадет из sys.dm_db_task_space_usage:

Таким образом, анализируя результаты данных представлений можно ответить на множество вопросов связанных с TempDB.
Выявляем проблемный запрос, вызывающий рост размеров файлов TempDB
В ходе расследования проблемы данного клиента мы использовали мониторинг представления sys.dm_db_session_space_usage, которое и позволило обнаружить моменты явного потребления памяти. Мы воспользовались следующим подходом:
- Необходимо подготовить служебную базу данных с таблицей, в которой будем хранить результаты мониторинга.
- Создаем задание с периодичностью 10 секунд, которое будет фиксировать занятые и освободившиеся объемы памяти.
- Подготавливаем сбор лога технологического журнала по событию DBMSSQL.
- Запускаем математику приводящую к потреблению памяти. В данном случае закрытие месяца.
- После того как SQL Server приступит к активному потреблению памяти TempDB начинаем смотреть какое соединение и запрос привел к этому. Для этого смотрим в сохраненную служебную таблицу и сопоставляем с логами технологического журнала.
Теперь рассмотрим подробнее.
Для создания служебной базы данных нам потребуется открыть Management Studio. Далее воспользоваться запросом на создание новой базы и таблицы в ней или воспользоваться помощником SQL Server.
Для создания базы с помощью запроса потребуется открыть окно создания нового запроса из контекстного меню экземпляра сервера:
После чего выполнить следующий запрос:
USE [master] GO CREATE DATABASE [ИмяСлужебнойБазы] CONTAINMENT = NONE ON PRIMARY ( NAME = N'ИмяСлужебнойБазы', FILENAME = N'ПутьКФайлам\ИмяСлужебнойБазы.mdf' , SIZE = 8192KB , MAXSIZE = UNLIMITED, FILEGROWTH = 65536KB ) LOG ON ( NAME = N'ИмяСлужебнойБазы_log', FILENAME = N'ПутьКФайлам\ИмяСлужебнойБазы.ldf' , SIZE = 73728KB , MAXSIZE = 2048GB , FILEGROWTH = 65536KB ) WITH CATALOG_COLLATION = DATABASE_DEFAULT GO USE [ИмяСлужебнойБазы] GO CREATE TABLE [dbo].[sp_use]( [date] [datetime] NULL, [session_id] [smallint] NULL, [user_objects_alloc_page_count] [bigint] NULL, [internal_objects_alloc_page_count] [bigint] NULL ) ON [PRIMARY] GO
Где ИмяСлужебнойБазы — Имя служебной базы. Например, AnalysisTempDB.
ПутьКФайлам — Путь к размещению файлов данных и журнала транзакций.

Для создания служебной базы с помощью помощника потребуется выполнить ряд действий.
- Открыть окно создания новой базы данных:

- На вкладке General указать название служебной базы и путь к файлам данных и журнала транзакций:

- После чего нажать ОК. Найти базу в дереве баз данных и вызвать окно создания новой таблицы:

- Затем подготовить колонки представленные на скриншоте:

После создания базы и таблицы для хранения можно перейти к созданию нового задания. Для этого требуется перейти в ветку SQL Server Agent — Jobs и создать новое задание:

Далее на вкладке General потребуется указать наименование нового задания:

На вкладке Steps добавить новый шаг, в котором заполнить основные параметры и текст запроса на копирование информации в служебную таблицу:
INSERT INTO sp_use_closeMonth(date, session_id, user_objects_alloc_page_count, internal_objects_alloc_page_count) SELECT CURRENT_TIMESTAMP, session_id, user_objects_alloc_page_count - user_objects_dealloc_page_count AS user_objects_alloc_page_count, internal_objects_alloc_page_count - internal_objects_dealloc_page_count AS internal_objects_alloc_page_count FROM sys.dm_db_session_space_usage AS TempDBTable WHERE database_id=DB_ID('tempdb') AND (user_objects_alloc_page_count > 0 OR internal_objects_alloc_page_count > 0)

Затем перейти на вкладку Schedulers и создать расписание с периодичностью выполнения каждые 10 секунд:

Для расследования проблемы остается настроить сбор логов технологического журнала по событию DBMSSQL, чтобы связать выполняемые запросы в СУБД с соответствующими в 1С.
Полный текст файла logcfg.xml:
<?xml version="1.0" encoding="UTF-8"?> <config xmlns="http://v8.1c.ru/v8/tech-log"> <log history="24" location="d:\logs"> <property name="all"/> <event> <eq property="name" value="DBMSSQL"/> <eq property="p:processName" value="base_name"/> </event> </log> <dump location="d:\dumps\" create="1" type="0" externaldump="1"/> </config>
Подготовка к расследованию завершена и можно приступать к запуску эксперимента:

Спустя время смотрим вырос ли размер TempDB. Для этого можно выполнить запрос к представлению sys.dm_db_file_space_usage:
USE tempdb; GO SELECT file_id AS ФайлДанных, total_page_count AS ОбщееКоличествоСтраниц, user_object_reserved_page_count AS ЗанятоПользовательскимиОбъектами, internal_object_reserved_page_count AS ЗанятоВнутреннимиОбъектами FROM sys.dm_db_file_space_usage AS TempDBTable

В случае если файлы выросли, то можно останавливать выполнение задания и сбора логов технологического журнала, приступать к анализу.
Для анализа нам понадобился простой запрос на выборку данных из служебной таблицы куда выполнялась фиксация слепков.
Можно обратить внимание, что в 13:53 система зафиксировала рост TempDB, который далее не продолжился. Соответственно, в этот промежуток и было выполнение запроса и помещение крупной таблицы в TempDB:

Если перейти в логи технологического журнала, то в этот же промежуток времени по 74 номеру соединению можно обнаружить соответствующий запрос:

Найдем его в конфигурации по указанным строкам:

Как можно заметить в нем присутствует множественные соединения как временных и физических, так и виртуальных таблиц. В частности, выполняется соединение с виртуальными таблицами остатков. Еще и без применения отборов. В связи с этим, видимо, оптимизатор запросов формировал неудачный план запроса, что приводило к проблеме потребления памяти.
Благодаря выносу получения таблицы остатков в соответствующие временные таблицы получилось избавиться от проблемы потребления памяти.

Работа с временными таблицами в PostgreSQL
В отличии от MSSQL в PostgreSQL работа с временными таблицами устроена иначе — в ней нет общего пространства подобного TempDB. При создании временной таблицы — в СУБД автоматически создается специальная служебная схема с именем pg_temp_N, где N — номер сессии в базе данных. Данная схема недоступна для других сессий. При этом, область размещения временной таблицы — ОЗУ или диск в зависимости от параметра temp_buffers.
temp_buffers (integer)
Задаёт максимальный объём памяти, выделяемой для временных буферов в каждом сеансе. Эти существующие только в рамках сеанса буферы используются исключительно для работы с временными таблицами. Если это значение задаётся без единиц измерения, оно считается заданным в блоках (размер которых равен BLCKSZ байт, обычно это 8 КБ). Значение по умолчанию — 8 мегабайт (8MB). (Если BLCKSZ отличен от 8 КБ, значение по умолчанию корректируется пропорционально.) Этот параметр можно изменить в отдельном сеансе, но только до первого обращения к временным таблицам; после этого изменения его значения не будут влиять на текущий сеанс.
Сеанс выделяет временные буферы по мере необходимости до достижения предела, заданного параметром temp_buffers. Если сеанс не задействует временные буферы, то для него хранятся только дескрипторы буферов, которые занимают около 64 байт (в количестве temp_buffers). Однако если буфер действительно используется, он будет дополнительно занимать 8192 байта (или BLCKSZ байт, в общем случае).
Источник: postgrespro.ru/docs/postgrespro/11/runtime-config-resource#GUC-TEMP-BUFFERS
Убедимся в работе механизма.
Для этого выполним любой запрос с помещением данных во временную таблицу. Далее обратимся к системному каталогу СУБД — pg_namespace:
SELECT n.nspname AS "Name", pg_catalog.pg_get_userbyid(n.nspowner) AS "Owner" FROM pg_catalog.pg_namespace n WHERE n.nspname <> 'information_schema' ORDER BY n.nspname LIMIT 100
Видим, что в списке схем появились схемы с суффиксом temp:

Примечания:
- Несмотря на то, что схема имеет уникальное имя с номером соединения к СУБД в конце pg_temp_18, в запросах можно обращаться к схеме pg_temp без индекса:
SELECT * FROM pg_temp.myTempTable;
Поиск таблицы будет произведен в первую очередь в схеме текущего подключения.
- Таблицы с суффиксом toast предназначены для хранения очень больших значений полей, это не предмет текущей статьи, про этот механизм подробнее можно почитать в документации (postgrespro.ru/docs/postgrespro/11/storage-toast).
Получается, так как в PostgreSQL нет общего пространства для хранения временных таблиц, значит не возникает сопутствующих проблем — никаких блокировок или конкуренции за пространство.
То есть «проблема tempDB» в PostgreSQL — отсутствует как класс.
Однако, есть свои нюансы и они кроются в настройках postgresql.conf.
Важные для текущей темы параметры:
- shared_buffers — буферный кэш БД, о нём мы упоминали в одной из прошлых статей.
- temp_buffers — выделенный кэш для временных таблиц, описано выше.
- work_mem — объём памяти, выделяемый для внутренних операций сортировки и хеш-таблиц. При превышении порога будут задействованы временные файлы на диске.
- maintenance_work_mem — задаёт максимальный объём памяти для операций обслуживания БД, в частности VACUUM, CREATE INDEX и ALTER TABLE ADD FOREIGN KEY.
Подробнее про них также можно почитать в документации: postgrespro.ru/docs/postgrespro/11/runtime-config-resource.
Рекомендации по значениям этих параметров от фирмы «1С» приведены на портале ИТС: its.1c.ru/db/metod8dev#content:5866:hdoc.
Со своей стороны хотим поделиться важным критерием, который мы учитываем при расчете значений. Эти параметры должны укладываться в уравнение:
Оперативная память на сервере >=
shared_buffers + temp_buffers × max_connections + work_mem × max_connections + work_mem
Где max_connections — предполагаемое максимальное количество соединений с БД.
Если это условие соблюдается, вероятность проблем производительности, связанных с памятью, значительно снижается.
Расследование проблем с временными файлами в PostgreSQL
При подозрениях на избыточное использование временных файлов на дисках, нужна возможность проанализировать какие файлы и в каком объеме используются, при исполнении каких запросов. В PostgreSQL для решения этой задачи необходимо настроить механизм логирования. Как и в других случаях, для этого нужно настроить параметры в файле postgresql.conf.
Ключевые пункты находятся в разделе Reporting and Logging, рекомендуем с ними со всеми ознакомиться в документации: postgrespro.ru/docs/postgresql/11/runtime-config-logging.
Мы же обратим внимание на:
- log_directory — путь к каталогу в который будут сохраняться файлы лога.
- log_temp_files — настройка в виде числа, которая определяет возможность логирования временных файлов.
- Значение по умолчанию = −1 — запись отключена.
- Значение = 0 — запись включена для всех временных файлов без ограничений.
- Положительное значение — означает предел размера в килобайтах, по достижении которого информация о файле будет записана в логе.
При желании можно посмотреть текущие настройки например в PgAdmin с помощью запроса:
SELECT category, --Группа параметра name, --Имя параметра конфигурации vartype, --Тип параметра setting || CASE WHEN unit IS NULL THEN '' ELSE ' (' || unit || ')' END AS setting, CASE WHEN enumvals IS NULL THEN min_val|| ' - ' ||max_val ELSE concat(enumvals) END AS vals, --Возможные значения boot_val, --Значение параметра, устанавливаемое при запуске сервера, если параметр не устанавливается другим образом reset_val, --Значение, к которому будет сбрасывать параметр команда RESET в текущем сеансе short_desc || CASE WHEN extra_desc IS NULL THEN '' ELSE '; ' || extra_desc END AS DESC --Описание FROM pg_settings WHERE category LIKE'Reporting and Logging%' ORDER BY category, name
После включения настроек события с использованием временных файлов можно «отловить» в логах. Появятся строки с текстом «temporary file», в которых будет указан путь к файлу, размер и запрос:

Заключение
Давайте сделаем несколько важных выводов:
- 1С — особая система в части работы с временными файлами. И на то две причины:
- Стандарты написания запросов требуют вместо соединения с вложенными подзапросами писать пакетные запросы с помещением результатов во временные таблицы.
- Запросов на чтение делается в процессе функционирования системы гигантское количество.
- В этой связи необходимо аккуратно относится к рекомендациям по размещению и настройке базы для временных файлов.
- Требуется постоянный мониторинг использования базы временных таблиц, особенно для СУБД MS SQL.
- Концептуальное устройство работы с временными файлами в СУБД PostgreSQL и MS SQL совершенно разное и со своими особенностями.
От экспертов «1С-Рарус»

















