


Оглавление
- Вступление
- Описание проблематики
- Описание ситуации глазами пользователя
- Описание ситуации глазами системных администраторов
- Оценка ситуации глазами экспертов
- Чек-листы проверки сервера СУБД и сервера 1С:Предприятия
- Что мы увидели на сервере СУБД
- Что мы увидели на сервере 1С
- Место на локальном жестком диске для сбора логов ТЖ
- Изменение «Требований назначения функциональности» сервера 1С:Предприятия и включение неиспользуемых серверов в кластер
- Замечание по доступу к серверам кластера 1С:Предприятия, а также серверу СУБД
- Решение задач производительности по блокировкам СУБД. Случай 1
- Решение задач производительности по блокировкам СУБД. Случай 2
- Как мы осуществляем разбор логов технологического журнала
- Анализ управляемых блокировок. Случай с блокировками №3
- Итоги и выводы
Вступление
В последнее время всё чаще специалисты 1С сталкиваются с двумя тенденциями:
- Большим числом пользователей в базе.
- Использованием «тяжелых» конфигураций, необходимых корпоративному сегменту: 1С:Управление холдингом, 1С:ERP 2.5, 1С:ERP.Управление холдингом 3.0, Документооборот КОРП 3.0.

Хотим поделиться одним экспертным случаем. Сам случай интересен тем, что при достаточно небольшом объеме базы (всего 49 ГБ) и сравнительно небольших доработках в конфигурации, наблюдается падение производительности системы.
Описание проблематики
Входящие данные:
- 1С:ERP версии 2.5.7, несколько доработанная, особенно в части добавления обменов и массовых обработок документов:
- Работают 500+ пользователей.
- Объем базы сравнительно небольшой — 49 ГБ.
- Функционируют различные обмены, такие как:
- Контур EDI (электронный документооборот для ритейла).
- Diadoc (электронный документооборот).
- WMS (управление складом).
- Обмен с другими базами 1С.
- На тех же мощностях работают типовые решения:
- 1С:Управление автотранспортом (50 пользователей).
- 1С:Документооборот (15 пользователей).
- Однако в силу того, что нагрузка на них сравнительно небольшая, их можно «оставить за скобками».
- Платформа 8.3.21.1393, серверная лиценизия уровня КОРП.
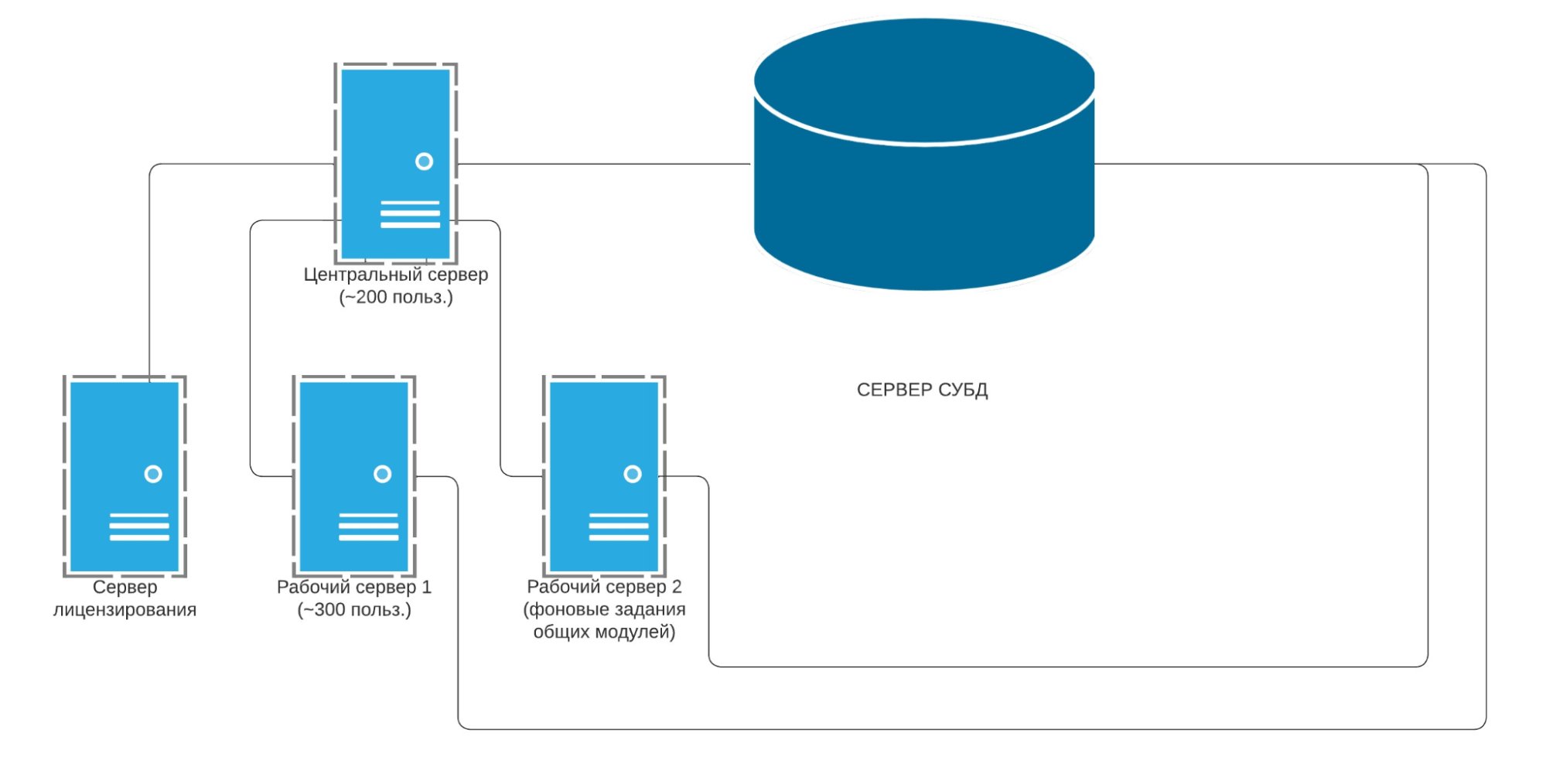
- Структура кластера 1С:
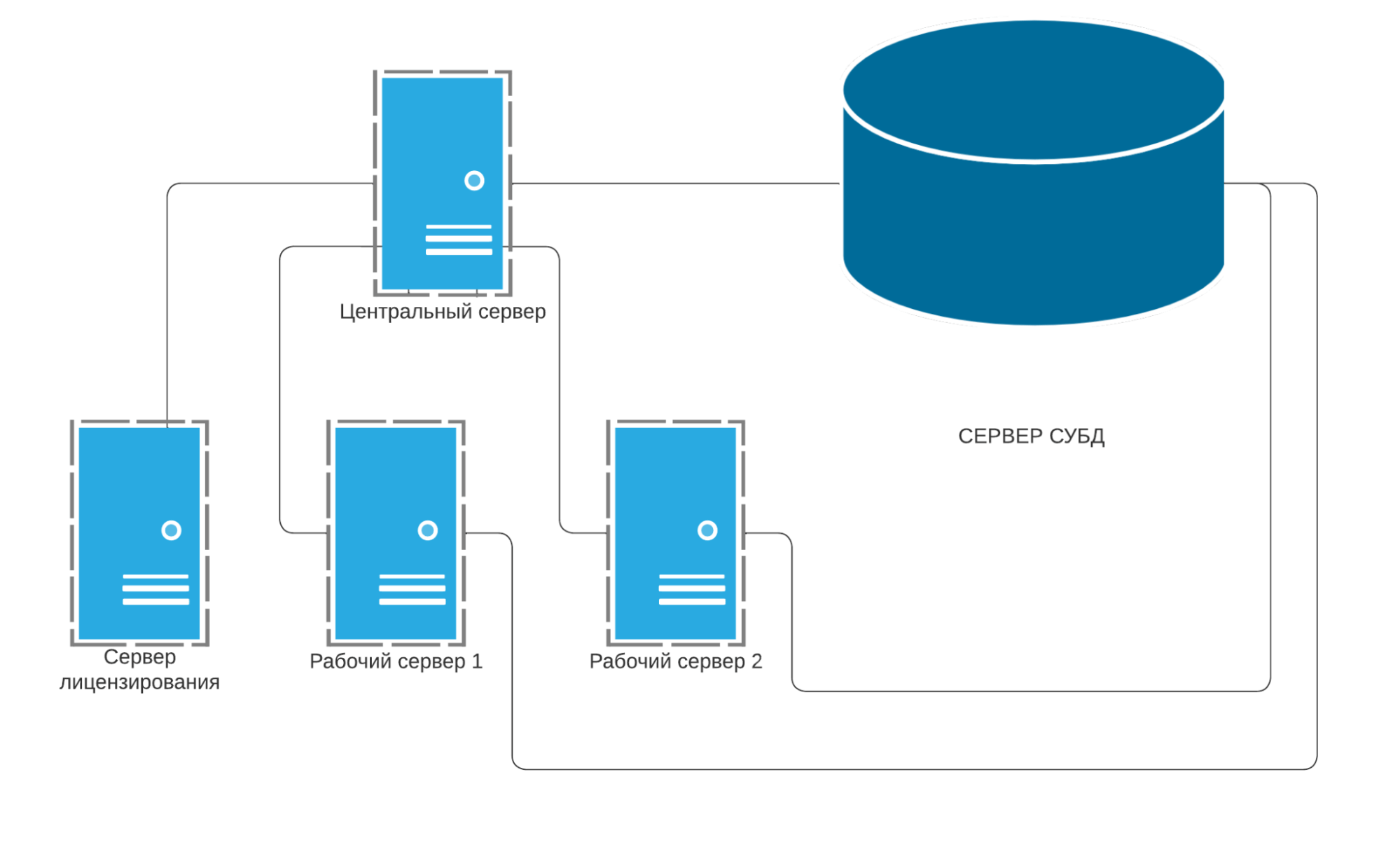
- 3 рабочих сервера, один из которых выполняет функцию сервера лицензирования.
- Один центральный в одном кластере 1С.
- Каждый рабочий сервер имеет следующие параметры:
- Intel Xeon E5-2643 v4 3.4 ГГц (12 ядер).
- 256 ГБ ОЗУ.
- СУБД:
- Intel Xeon E5-2690 v4 2.6 ГГц (6 ядер).
- 96 ГБ ОЗУ.
- Always On failover cluster instances (SQL Server) (пояснение ниже).
- План обслуживания есть и работает по расписанию (подробнее ниже).
- Это характеристика виртуальных серверов. Характеристики реального железа клиент не раскрывает. Используется виртуализация VMWare 6.7.1.3.
- Для мониторинга используется Zabbix.
- На серверах СУБД и 1С используется ОС Windows.
Always On Failover Cluster Instances (SQL Server)
В рамках SQL Server AlwaysOn экземпляры отказоустойчивой кластеризации AlwaysOn используют функциональные возможности отказоустойчивой кластеризации Windows Server (WSFC) для обеспечения высокого уровня доступности локальных ресурсов за счет избыточности на уровне экземпляра сервера — экземпляра отказоустойчивого кластера (FCI). Экземпляр отказоустойчивого кластера (FCI) является единственным экземпляром SQL Server , установленным на всех узлах отказоустойчивой кластеризации Windows Server (WSFC) и, возможно, в нескольких подсетях. Экземпляр отказоустойчивого кластера выглядит в сети как экземпляр SQL Server , запущенный на одном компьютере, но экземпляр отказоустойчивого кластера обеспечивает отработку отказа с переходом одного узла WSFC на другой узел, если текущий узел становится недоступным.
Экземпляр отказоустойчивого кластера (FCI) может эффективно использовать группы доступности для удаленного аварийного восстановления на уровне базы данных.
Источник:
learn.microsoft.com/ru-ru/sql/sql-server/failover-clusters/windows/always-on-failover-cluster-instances-sql-server?view=sql-server-ver16
Проще говоря, использование Always On failover cluster instances означает, что используется отказоустойчивый кластер СУБД, что обеспечивает бесперебойную работу СУБД.
Подробнее о плане обслуживания
План обслуживания включает в себя ежедневное обновление статистики с помощью вызова хранимой процедуры dbo.IndexOptimize, взятой отсюда: ola.hallengren.com/sql-server-index-and-statistics-maintenance.html, а также еженедельной реиндексации таблиц, которая запускается при помощи той же процедуры.
Вывод
На первый взгляд всё вроде бы неплохо: мощные серверы, за ними следят, имеются планы обслуживания. Однако, когда мы погрузились в детали, стало многое видится под другим углом.
Описание ситуации глазами пользователя
Кратко проблема со слов заказчика звучит так — запустили ERP своими силами; по началу всё было неплохо, но при включении второго торгового контура, появились проблемы с производительностью:
- При работе 150–200 пользователей система работала хорошо.
- при приближении к 300 удовлетворительно;
- Когда пользователей стало 400–500 и более — работа с системой стала невыносимой.
Как это выглядит:
- Есть «общее замедление работы» — медленное проведение, медленное открытие форм списков и форм документов.
- Пользователи получают сообщения о блокировках: как СУБД, так и от 1С:Предприятия.
- Нехватка данных, которые должны приехать по обмену. Регл. задания обмена то и дело падают или отстают (работают медленно).
Описание ситуации глазами системных администраторов
При приближении числа пользователей к 400 начались проблемы производительности. На момент расследования имеет место регулярное:
- падение рабочих процессов;
- падение регламентных заданий;
- в том числе, операций обменов, которые являются критически важными для бизнеса.
По доработкам конфигураций:
- ИТ служба клиента не считает, что проблема связана с доработками базы.
- По их словам, выполненные доработки конфигурации касались только двух вещей:
- исправления ошибок обменов, например в блоке Контур.EDI;
- создания обработок массового проведения документов.
Время удовлетворительной производительности 1С:ERP меняется от времени суток:
- В 9–10 утра система работает удовлетворительно:
- Открытие заказа клиентов — 2–3 сек.
- Проведение заказа клиента — 3–10 сек.
- К 12–13 часам дня начинается существенное снижение быстродействия. В этот момент в системе 500–550 пользователей:
- Открытие заказа клиентов — 5–7 сек.
- Проведение заказа клиента — до 50 сек.
- Вечером ситуация становится еще хуже.
- С 12:00 и в течение всего дня падают рабочие процессы сервера «1С:Предприятие».
Положение дел на момент обследования выглядит грустно:
- Обновление динамического списка Заказов клиентов — 5–10 сек.; целевое время — 1 сек.
- Открытие заказа клиентов — 5–7 сек; целевое время — 1 сек.
- Проведение заказа клиента — 50 сек; целевое время — 3 сек.
- Проведение других документов в зависимости от вида в диапазоне от 10 до 50 сек.
- Также работают с существенными задержками регламентные и фоновые задания, причем как типовые, так и разработанные силами заказчика.
- В неустановленные моменты времени пользователи начинают получать информацию о таймаутах:
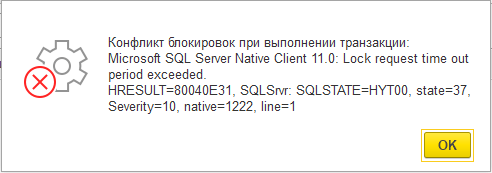
При этом замечена странность:
- На сервере СУБД загрузка процессора не 100%, а база «еле шевелится».
- В кластер 1С добавили еще 1 сервер, но скорость работы с базой всё равно не увеличилась.
Временное решение, которое вынужден применять клиент:
- При необходимости выполнить критически важный обмен, временно выгонять всех пользователей и выполнять конкретный обмен, например с Контур.EDI.
Заказчик пытался самостоятельно решить проблему:
- Добавлением памяти серверу СУБД.
- Включением дополнительного сервера «1С:Предприятие» в кластер серверов 1С.
Однако это не решило проблему.
Решили обратиться за помощью к экспертам «1С‑Рарус».
Оценка ситуации глазами экспертов
Обычно мы подходим к решению подобных задач следующим образом:
- Проводим проверку оборудования и настроек серверов по чек-листам, основанным на рекомендациях 1С:ИТС и kb.1c.ru, а также собственному опыту.
- Далее разбираем наиболее острые проблемы, полученные от клиента.
На ресурсе kb.1c.ru имеется достаточно подробный чек-лист проверки сервера СУБД MS SQL (kb.1c.ru/articleView.jsp?id=100). Наш основан на нем, но несколько расширен.
Чек-листы проверки сервера СУБД и сервера 1С:Предприятия
Приведем пример части чек-листа проверки сервера СУБД:
| № п/п |
Наименование | Отметка о выполнении | Примечание |
|---|---|---|---|
| 1. | Проверка установки последних обновлений СУБД. Запрос для проверки: Select @@VERSION |
Цели:
|
|
| 2. | Проверка отсутствия роли «Контроллер домена» у серверной ОС с установленной службой MSSQLServer. | Процитируем документацию вендора: Исходя из соображений безопасности, не рекомендуется устанавливать SQL Server на контроллере домена. SQL Server не заблокирует установку на компьютере, который является контроллером домена, однако при этом будут применен ряд ограничений. См. подробнее на learn.microsoft.com/ru-ru/sql/sql-server/install/security-considerations-for-a-sql-server-installation?view=sql-server-ver16#Install_DC. Кроме того, на машине с ролью «Контроллер домена» зачастую отключено кэширование записи на диск, что может негативно сказываться на скорости работы СУБД. См. подробнее на learn.microsoft.com/en-us/previous-versions/windows/it-pro/windows-server-2008-R2-and-2008/dd941847(v=ws.10)?redirectedfrom=MSDN. |
|
| 3. | Проверка установки схемы электропитания в значение «Высокая производительность». | Пункт из чек-листа 1С (kb.1c.ru/articleView.jsp?id=100). Если этого не сделать, то сервер может работать не на полную мощность, а также в случае простоя отключать некоторые устройства. |
|
| 4. | Проверка включения параметра «Database instant file initialization» (Мгновенная инициализация файлов) Стартовой учетной записи службы SQLServerSQL Server должно быть предоставлено разрешение SE_MANAGE_VOLUME_NAME политика «Perform volume maintenance tasks» (Выполнение задач по обслуживанию томов). | Процитируем с сайта вендора СУБД (learn.microsoft.com/ru-ru/sql/database-engine/configure-windows/server-memory-server-configuration-options?view=sql-server-ver16#lock-pages-in-memory-lpim): По умолчанию файлы данных и журналов инициализируются, чтобы перезаписать все существующие данные на диске, оставшиеся после удаленных файлов. Файлы данных и журналов сначала инициализируются путем обнуления (заполнения нулями) при выполнении следующих операций: Создается база данных. Добавление файлов данных и журналов к существующей базе данных. Увеличение размера существующего файла (включая операции автоувеличения). Восстановление базы данных или файловой группы. В SQL Server мгновенное инициализация файлов (IFI) позволяет ускорить выполнение ранее упомянутых операций с файлами, так как оно освобождает используемое дисковое пространство без заполнения этого пространства нулями. Вместо этого содержимое диска перезаписывается, поскольку в файлы записываются новые данные. |
|
| 5. | Проверка включения параметра «Lock pages in memory» (Блокировка страниц в памяти). Стартовая учетная запись службы SQL ServerSQL Server должна быть включена политика «Lock pages in memory» (Блокировка страниц в памяти) в разделе Computer Configuration → Windows Settings → Security Settings → Local Policies → User Rights Assignment. |
Процитируем с сайта вендора СУБД (learn.microsoft.com/ru-ru/sql/database-engine/configure-windows/server-memory-server-configuration-options?view=sql-server-ver16#lock-pages-in-memory-lpim): Для сохранения данных в физической памяти, чтобы система не отправляла страницы данных в виртуальную память на диске. Память, выделенная с помощью AWE(API Address Windowing Extensions), блокируется до тех пор, пока приложение не освободит ее или не завершит работу. См. подробнее на learn.microsoft.com/ru-ru/sql/database-engine/configure-windows/enable-the-lock-pages-in-memory-option-windows?view=sql-server-ver16&viewFallbackFrom=sql-server-2014&redirectedfrom=MSDN. |
|
| 6. | Проверка отключения системного сжатия и шифрования файлов данных и файлов журналов для тестируемой базы данных и базы tempdb. | Системное сжатие, может существенно снижать быстродействие сервера СУБД, поскольку приводят к выполнению алгоритмов сжатия и распаковки. | |
|
7. |
Проверка наличия в списке исключений антивирусного ПО файлов данных и журналов для тестируемой базы данных и базы tempdb. | Антивирус, запуская проверку, может существенно снижать быстродействие сервера СУБД. | |
|
8. |
Проверка включения флагов трассировки в SQL Server Configuration Manager в свойствах SQL Server services -T4199 — для Microsoft SQL Server 2014 необходимо включить исправление ошибок оптимизатора. -T1118 — неиспользовать смешанные экстенты (когда страницы разных объектов располагаются в одном экстенте). Для Microsoft SQL Server 2016 и выше данная настройка включена по умолчанию. -T1224 для отключения укрупнения блокировок на основе количества блокировок. |
Подробнее можно ознакомиться на сайте производителя (learn.microsoft.com/ru-ru/sql/t-sql/database-console-commands/dbcc-traceon-trace-flags-transact-sql?view=sql-server-ver16). Например, для -T1224: Отключает укрупнение блокировок на основе количества блокировок. Однако слишком активное использование памяти может включить укрупнение блокировок. Компонент Компонент Database Engine укрупняет блокировки строк или страниц до блокировок таблиц (или секций), если объем памяти, используемый блокированными объектами, превышает одно из следующих условий. |
Чек-лист настройки серверов 1С:Предприятия основан на чек-листе с ИТС (its.1c.ru/db/metod8dev/content/5899/hdoc), но несколько дополнен.
Пример части чек-листа проверки серверов 1С:Предприятия:
| № п/п |
Наименование | Отметка о выполнении | Примечание |
|---|---|---|---|
| 5. | Проверка формата журнала регистрации тестируемой информационной базы — журнал должен быть переведен в последовательный («старый» — lgf/lgp/elf/log) формат. | Формат журнала регистрации SQLite имеет ряд проблем при работе с 1С:Предприятием. Описания проблем пользователей, эксплуатирующих lgd-формат можно найти на Партнерском форуме 1С (partners.v8.1c.ru/forum/t/1801803/m/1806537). Компания 1С даже запустила опрос о необходимости поддержки данного механизма (wonderland.v8.1c.ru/blog/opros-zhurnal-registratsii-vozmozhnoe-prekrashchenie-podderzhki-formata-sqlite/). |
|
| 6. | Проверка установки настроек перезапуска процессов по памяти. Ограничения по безопасному расходу памяти либо «По умолчанию», либо имеют такие значения, при которых они действительно могут сработать на конкретном оборудовании. Не должно быть установлено таких значений, которые «отключают» работу механизмов контроля потребления памяти на вызов. | Процитируем ИТС: «Допустимый объем памяти» стоит устанавливать из расчета, того, что в случае срабатывания условия превышения показателя будет запущен ещё один процесс rphost того же объема, как при нормальной работе кластера серверов в этой информационной системе. «Интервал превышения допустимого объема памяти» и «Выключенные процессы останавливать через» следует стараться указывать как можно меньше исходя из характера нагрузки на информационную систему, например, по 60 секунд, если мы рассчитываем, что все операции (или большая их часть) должны выполниться быстрее 60 секунд. См. подробнее на ИТС (its.1c.ru/db/metod8dev/content/5815/hdoc). |
|
| 7. | При наличии нескольких серверов в кластере: проверка наличия требований назначения функциональности для всех продукционных кластеров с двумя и более рабочими серверами:
|
См. подробнее на ИТС, п. 18. (its.1c.ru/db/metod8dev/content/5899/hdoc). Если проигнорировать данный пункт, может случиться ровно так, как описано ниже. |
|
| 8. | При наличии нескольких серверов в кластере: ragent должен быть запущен с параметрами
Если кластер содержит несколько рабочих серверов, и целесообразно изменить значения периода и таймаута по умолчанию, то рекомендуется:
|
Стоит увеличивать данные параметры при использовании более, чем одного сервера в кластере 1С в одном из следующих случаев:
|
Что мы увидели на сервере СУБД
Неполное использование ядер процессора
Увидели, что загрузка сервера СУБД — только на четырех процессорах, а на 2 других простаивает.
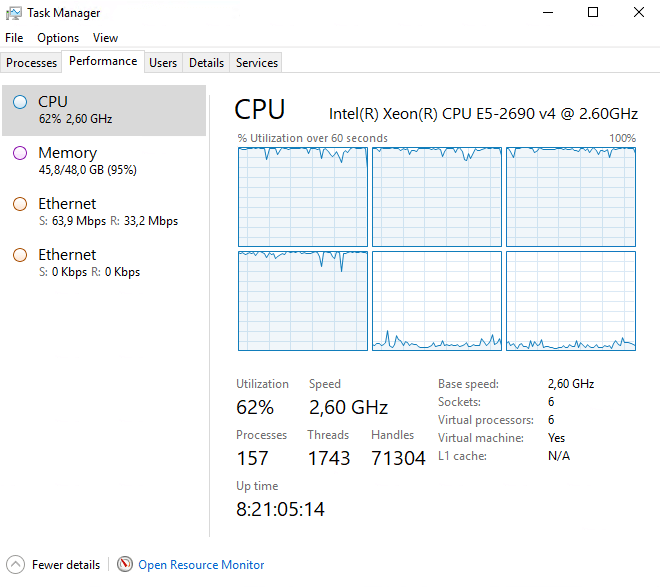
Проверили версию MSSQL, выполнив запрос:

Получили ответ сервера:
Почему произошла недозагрузка последних двух процессоров?
Конфигурация виртуальной машины сервера СУБД вида «6 процессоров по 1 ядру» приводит к ограничению Standard Edition версии MS SQL. В результате работают даже не 6, а лишь 4 ядра.
Подробнее об этом можно почитать на официальном ресурсе Microsoft (learn.microsoft.com/ru-RU/sql/sql-server/editions-and-components-of-sql-server-2016?view=sql-server-2016#Cross-BoxScaleLimits). Приведем информацию кратко:
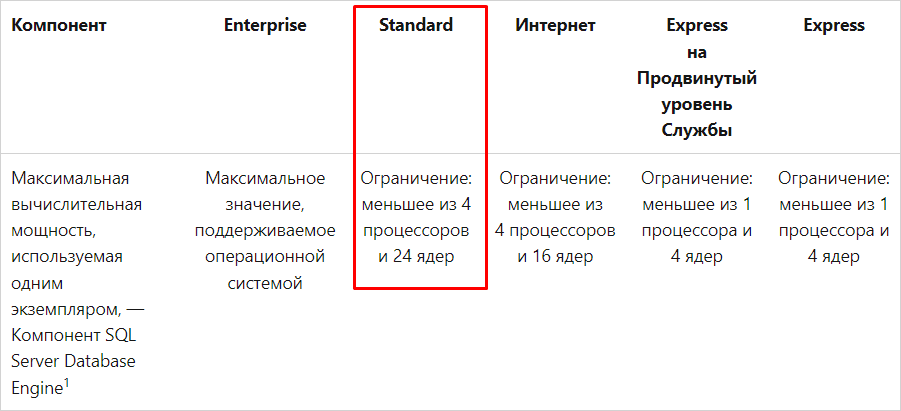
Рекомендация:
- Перейти на версию MS SQL без данных ограничений, например, на Enterprise-версию.
- Или переконфигурировать виртуальную машину так, чтобы она была «2 процессора по 3 ядра», или «1 процессор с 6 ядрами».
Итог:
- Клиент переконфигурировал виртуальную машину, выбрав конфигурацию «2 процессора по 3 ядра», общая нагрузка на процессоры снизилась, но незначительно.
Нехватка ядер, даже при использовании всех доступных ядер
После того, как клиент переконфигурировал виртуальную машину, на которой работает СУБД, средняя нагрузка на процессор, а также нагрузка на 1 ядро снизилась, но этого всё равно оказалось недостаточно. Поэтому принято решение увеличить количество ядер процессора.
Можно попробовать увеличить количество ядер хотя бы до 12 и посмотреть реальный отклик системы; мы это можем сделать, поскольку сервер виртуальный и мы имеем некоторую свободу конфигурирования железа.
В итоге клиент принял решение выдать виртуальной машине 24 ядра и остановился на конфигурации «2 процессора по 12 ядер».
Неверное значение параметра Max Degree of Parallelism
Ситуация с нехваткой процессорных мощностей на СУБД также еще ухудшается из-за значения параметра Max Degree of Parallelism (в народе — MaxDOP), которое равно 6:
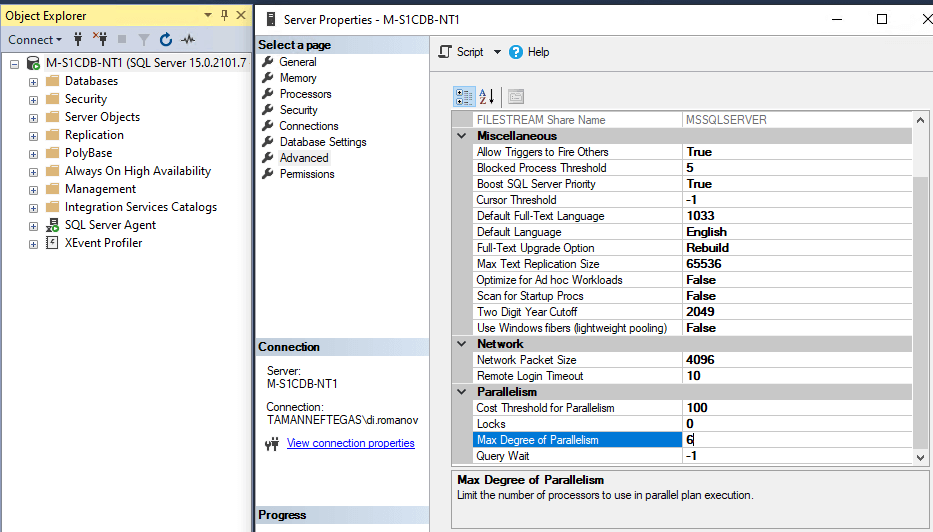
Параметр определяет, на какое количество процессоров может распараллелиться запрос, если оптимизатор сочтет его слишком тяжелым для одного ядра.
При наличии 6 ядер значение выставленное в 6, может привести к тому, что 1 запрос займет все ядра, а все остальные запросы будут стоять в очереди.
Рекомендация с kb.1c.ru (kb.1c.ru/kipArticleView.jsp?id=4A907509-5A94-4294-9257-3505CE0274C5):
- Параметры параллелизма необходимо выбирать исходя из характера нагрузки на базу данных. Если в базе много небольших и быстрых запросов, то степень параллелизма необходимо снизить. Если типичная нагрузка это большие и долгие запросы, то параллелизм улучшит производительность.
- Если характер нагрузки заранее не известен, то рекомендуется установить параметр max degree of parallelism (technet.microsoft.com/ru-ru/library/ms181007(v=sql.105).aspx) = 1. В последствии данный параметр можно увеличивать, комбинируя его с параметром cost threshold for parallelism (technet.microsoft.com/ru-ru/library/ms188603(v=sql.105).aspx), для достижения максимальной производительности.

Замечание:
- Есть ситуации, при которых необходимо на время некоторой «тяжелой» регламентной операции, когда с базой почти никто не работает, кроме пользователя, запустившего эту операцию, выделить побольше процессорных мощностей; в таком случае параметр MaxDOP можно выставить = числу ядер сервера СУБД или даже = 0 (автоматическое выделение любого количества ядер одному процессу — на усмотрение СУБД MSSQL).
- Например, это может быть операция закрытия месяца 1С:ERP, при работе которой с базой работает только 1 пользователь — главный бухгалтер; это может существенно ускорить время работы данной операции.
- По окончании данной операции необходимо вернуть значение MaxDOP в прежнее значение.
Отсутствие параметра FULLSCAN при обновлении статистики
При проверке регламентов обслуживания СУБД обратили внимание, что скрипт обновления статистики выполняется без параметра SAMPLE 100 PERCENT, или, что то же самое, без параметра FULLSCAN. Подробнее о данных параметрах learn.microsoft.com/Ru-Ru/sql/t-sql/statements/update-statistics-transact-sql?view=aps-pdw-2016.
В результате, обновление статистики производится путем анализа не всей таблицы, а случайного набора строк из нее.
По нашим наблюдениям, при работе с базами 1С бывает критически важно делать обновление статистики путем просмотра всех строк в таблице. По крайней мере, в таблицах, которые активно изменяются.
Замечание:
- При включении параметра FULLSCAN время обновления статистики возрастет. В нашей ситуации это не было столь критично и всё равно данная операция производилась за приемлемые ночные 2 часа. Однако при росте размера базы возможна ситуация, когда обновление статистики занимает 8 и более часов. В таком случае выбирают наиболее часто изменяющиеся таблицы и статистику обновляют по ним ежедневно, а по остальным — реже, например 1 раз в неделю.
Поскольку регламент обновления статистики выполняется не стандартным SELECT’ом, а через вызов хранимой процедуры dbo.IndexOptimize, то необходимо добавить данный параметр в терминах этой хранимой процедуры, как это описано kost.su/indexoptimize-хранимая-процедура-оптимизации-ст/:
EXECUTE dbo.IndexOptimize @DATABASES = 'USER_DATABASES', @FragmentationLow = NULL, @FragmentationMedium = NULL, @FragmentationHigh = NULL, @UpdateStatistics = 'ALL', @LogToTable = 'Y', @StatisticsSample=100
Пока это всё, что удалось увидеть при анализе сервера СУБД, согласно чек-листам.
Идем к проверке серверов кластера 1С.
Что мы увидели на сервере 1С
Первое, что мы сделали, когда зашли на сервер 1С:Предприятия — посмотрели нагрузку на процессоры через диспетчер задач. Она оказалась высокой, причем равномерно высокой по всем ядрам:
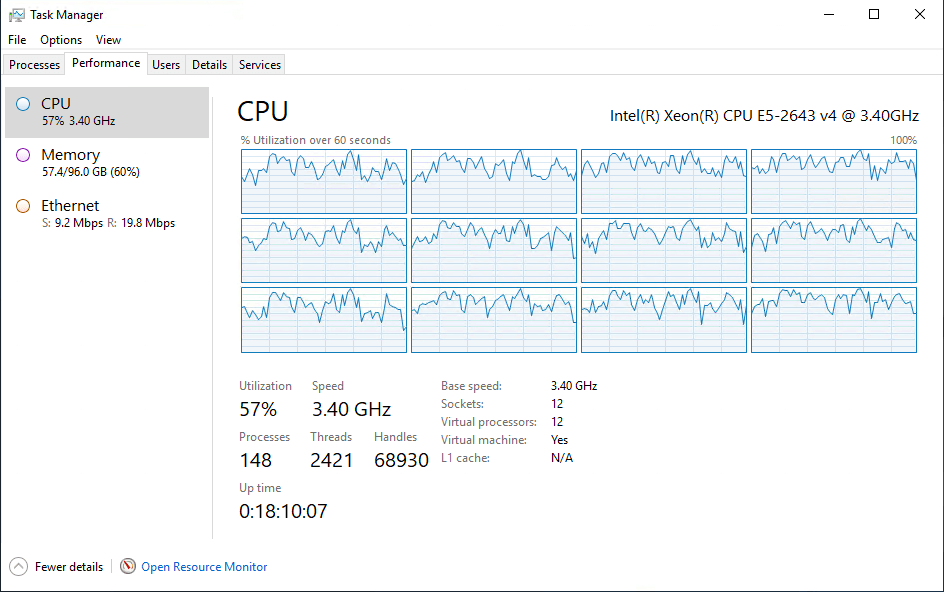
Видно, что на сервере 1С:Предприятия имеется 12 ядер и все они работают с нагрузкой 70–90%.
Обследование показало, что на момент подключения специалистов «1С‑Рарус», в кластере задействовано 4 сервера, однако все соединения — только на основном сервере. Причина — неверная настройка требований назначений функциональности.
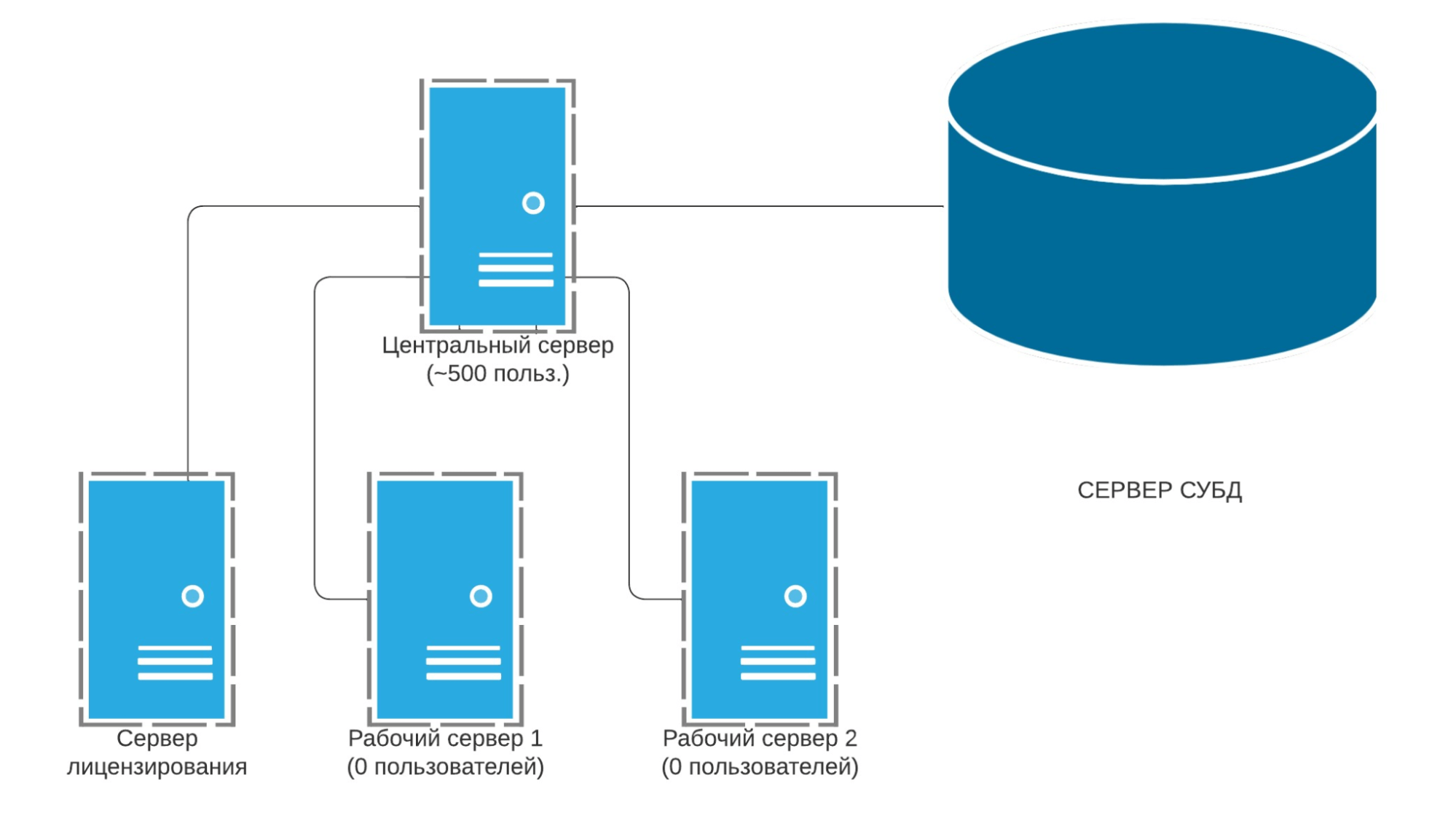
В результате вся нагрузка со стороны rphost’ов приходится на процессоры основного сервера, что приводит к их нагрузке свыше 70%.
По нашему опыту длительная загрузка процессора > 70% свидетельствует о его перегрузке. В таком случае сервер, в целом, может работать нестабильно, что мы и наблюдаем.
Косвенные признаки нехватки мощностей сервера 1С
Косвенно о регулярной ситуации нехватки процессорных мощностей на серверах кластера 1С свидетельствует наличие файлов дампов рабочих процессов с нулевыми адресами:

Наличие нулей говорит о том, что ошибок кода нет, а процесс был или принудительно завершен менеджером кластера, или завершился по внешним причинам — нехватка места, ОЗУ и т. п. (упоминается также на ИТС its.1c.ru/db/metod8dev/content/5809/hdoc — искать по ключевому слову «имя процесса, версия и смещение»).
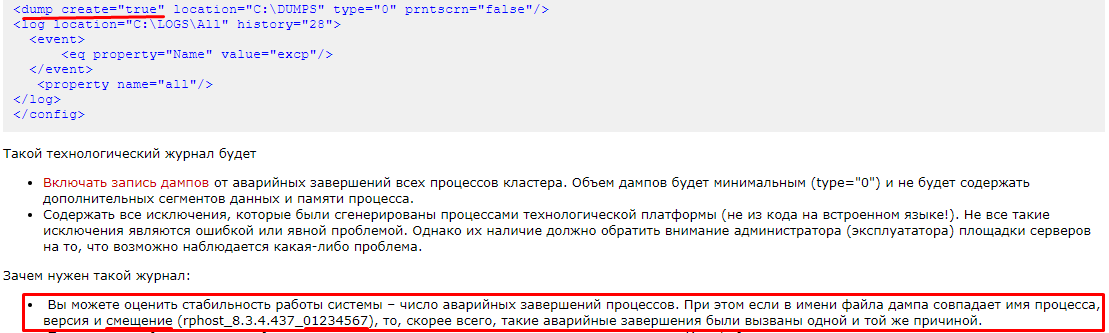
ЦП тут не исключение — если менеджер кластера rmngr длительное время не отвечал рабочему процессу rphost, т. к. была высокая загрузка ЦП, и rmngr был «занят чем-нибудь другим», например, ожидал отклика ОС в свою очередь, то рабочий процесс признает себя «потерянным» и завершится. Часто это сопровождается дампом.
Вывод:
- На сервере 1С:Предприятия с большой долей вероятности недостаточно ядер процессора.
Рекомендация:
- Либо увеличить количество ядер процессора (это возможно, поскольку серверы виртуальные).
- Либо настроить требования назначений функциональности так, чтобы другие серверы кластера также принимали на себя рабочие процессы и таким образом снизить нагрузку на главный сервер.
Параметры /pingPeriod и /pingTimeout не увеличены
Заметим, что падение рабочих процессов с дампами может также происходить вследствие недостаточного ожидания компонентов кластера ответов друг от друга.
Можно увеличить период проверки системы отслеживания разрыва соединений, а также таймаут проверки системы отслеживания разрыва соединений следующими параметрами, описанными на ИТС (its.1c.ru/db/v8320doc#bookmark:cs:TI000000119):

По нашим наблюдениям для преодоления ситуации долгого неответа между компонентами кластера сервера 1С стоит увеличить параметры работы служб сервера с значений по умолчанию на такие:
- pingPeriod не менее 1000, лучше 5000;
- pingTimeout не менее 15000 лучше 30000.
Источник с ИТС (its.1c.ru/db/v8320doc#bookmark:cs:TI000000119):

Если параметры недостаточно большие для вашей системы, то вы можете увидеть в логах ТЖ похожие сообщения:
- Вариант1:
- PROC...Cluster lock absent
- PROC...Cluster lock absent 5 seconds
- Вариант2 (смена времени):
- CONN...Txt=Incomming connection closed: client disconnected after silence
- EXCP...Exception=NetDataExchangeException,Descr=Ping time out expired on connection
- CONN...Txt=’Connection removed from ping direction:
- CONN...Txt=Incomming connection closed: long still
Источники информации по практике изменения параметров pingPeriod и pingTimeout
К сожалению, на официальных ресурсах 1С (на ИТС, а также на ресурсе «Технологические вопросы крупных внедрений») не слишком много информации по данным параметрам и методике их настройки.
Мы проанализировали вопросы на Партнерском форуме 1С по данной теме и пришли к выводу, что увеличивать данные значения имеет смысл в одном из следующих случаев:
- Сервер перегружен, компоненты сервера не успевают своевременно отвечать друг-другу, поэтому считаются потерянными и завершаются.
- Также это возможно из-за нестабильной работы сети; следствие то же.
- Происходит «замирание» виртуальной машины сервера на несколько секунд, например, в случае миграции на другой физический хост по причине балансировки нагрузки на кластере виртуальных машин; следствие то же, что в предыдущих пунктах.
Проблема заключается в работе компонента vCenter под названием DRS (Distributed Resource Scheduler), задача которого заключается в балансировке нагрузки виртуальных машин на физические серверы.
При появлении больших нагрузок по процессорным мощностям или по загрузке ОЗУ, DRS мигрирует виртуальную машину на другой физический хост, наименее загруженный в данный момент; в кульминации данного процесса возникают кратковременные проблемы с доступом к ресурсам этой VM.
Время миграции с хоста на хост совпадает с паузами в работе.
Понизили уровень необходимости миграции, стало намного лучше.
Место на локальном жестком диске для сбора логов ТЖ
Т. к. заказчику точно неизвестна природа неустойчивой работы сервера, согласно входящих условий проекта, мы должны собрать логи технологического журнала, в том числе, и по весьма объемным событиям DBMSSQL и SDBL.
По нашей статистике объем файлов лога ТЖ для базы 1С:ERP, в которой работают 500 пользователей составляет:
- для события DBMSSQL по всем полям — 10–45 ГБ/час;
- для события SDBL по всем полям — столько же.
Под файлы ТЖ необходимо иметь достаточный резерв на дисковом пространстве и тут есть некоторые ограничения:
- Желательно, чтобы запись логов производилась на локальный для сервера диск, а не сетевой.
- Не должно закончиться место на этом диске, т. к. в противном случае это может привести к падению запущенных экземпляров клиентов 1С.
Мы будем собирать логи ТЖ в течение рабочего дня как по событию DBMSSQL, так и SDBL (сбор осуществляется и по другим событиям, но т. к. они не содержат поля sql, их объемом можно пренебречь), поэтому на 8 часов сбора потребуется от 160 ГБ (10×2×8) — до 720 ГБ (45×2×8) дискового пространства.
В ходе анализа увидели, что специального места под логи ТЖ нет, поэтому запросили его.

Решение:
- На каждом сервере из состава кластера 1С:Предприятия был добавлен диск емкостью 200 ГБ для сбора логов технологического журнала.
- Формула для оценки объема логов ТЖ составлена исходя из нашего субъективного опыта и при более интенсивной работе пользователей или фоновых заданий логи ТЖ могут потребовать больше места, поэтому в течение дня мы несколько раз контролировали скорость роста.
Подробнее о сборе логов технологического журнала можно почитать на ИТС its.1c.ru/db/v8doc#content:26:1:issogl1_3.14.logcfg.xml.
После окончания рабочего дня мы останавливали сбор, ставили собранные логи на упаковку архиватором и просили заказчика передать нам их через файлообменник.
Изменение «Требований назначения функциональности» сервера 1С:Предприятия и включение неиспользуемых серверов в кластер
Как мы увидели ранее, на процессорах сервера 1С:Предприятия постоянная загрузка свыше 70%.
Т. к. заказчик располагает дополнительными серверами, которые можно использовать в качестве сервера 1С, а также имеются лицензии на сервер, то принято решение включить 2 дополнительных сервера в кластер. Добавим требования назначения функциональности (далее — ТНФ) на центральный сервер — на «Клиентское соединение с ИБ», «Сервис журналов регистрации», «Сервис нумерации»:
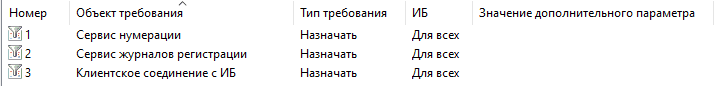
На дополнительный сервер назначим только «Клиентское соединение с ИБ».

Кроме того, при наличии корп.лицензий 1С (а они у заказчика есть), мы можем настроить требования назначения функциональности таким образом, чтобы все фоновые задания, порождаемые вызовами из общих модулей, стартовали строго на выделенном сервере, а на двух других — рабочем и дополнительном — не стартовали. Это приведет к перераспределению нагрузки и позволит гарантировать более предсказуемую работу, как регламентных заданий обменов, так и клиентских сессий. Для этого необходимо на целевом сервере настроить ТНФ так:
- Объект требования: Клиентское соединение с ИБ.
- Тип требования: Назначать.
- Имя ИБ: не указывается.
- Значение дополнительного параметра: BackgroundJob.CommonModule:

На остальных серверах кластера необходимо указать такую же настройку, но с «Тип требования» = «Не назначать» под номером требования 1.
На центральном сервере:

На рабочем сервере:

Подробнее об этом its.1c.ru/db/v8323doc#bookmark:cs:TI000000052.
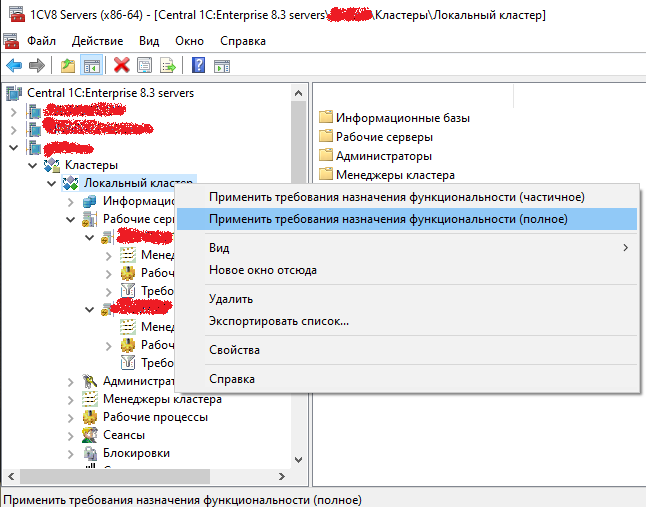
После настройки требований назначения функциональности на рабочих серверах 1С, чтобы они вступили в силу, необходимо их применить с помощью пунктов контекстного меню свойств кластера. Подробнее о частичном/полном применении см.на ИТС its.1c.ru/db/v8323doc#bookmark:cs:TI000000155:

Внимание!
- При полном применении ТНФ сеансы пользователей могут завершиться, поэтому желательно делать это во время технологического окна.
- Перезапуск службы агента сервера не включает настройки ТНФ, чтобы они заработали нужно вручную вызвать операцию применения:
Результат:
- В результате применения ТНФ, загрузка ядер процессоров как центрального сервера, так и дополнительных рабочих серверов кластера снизилась и теперь средняя нагрузка на ядра процессора не превышает 70%.
- Фоновые задания, создаваемые из общих модулей изолированы на отдельном рабочем сервере.
- Работа кластера стала более устойчива — пользователи перестали сообщать о «зависании» при работе, системные администраторы отметили, что прекратилось падение рабочих процессов, в том числе, по чувствительным для бизнеса регламентным заданиям обмена.
Замечание по доступу к серверам кластера 1С:Предприятия, а также серверу СУБД
Для беспрепятственного аудита системы важно иметь доступ уровня Администратор на каждом из исследуемых серверов по следующим причинам:
- На серверах кластера 1С:Предприятия необходимо иметь возможность стартовать и останавливать сбор логов технологического журнала, своевременно архивировать файлы логов ТЖ, а также контролировать свободное место для них.
- На сервере СУБД необходимо иметь возможность настраивать и стартовать трассировку через механизм Extended events MS SQL. Кроме того, желательно в течение рабочего периода выполнять запросы к служебным представлениям MS SQL, предоставляющим различную статистику работы СУБД: sys.dm_exec_query_stats (статистика выполнения запросов), sys.dm_io_virtual_file_stats (статистика ввода-вывода), sys.dm_os_wait_stats (статистика ожиданий);
- На обоих типах серверов — с целью настройки сбора счетчиков Perfmon ОС Windows.
Доступ необходим для сбора выбранных пользователем счетчиков производительности ОС Windows.
Вместе с тем, заказчик может выдвигать различные контраргументы против выдачи таких прав, как например:
- «Зачем вам счетчики Perfmon? У нас настроена выгрузка счетчиков в Zabbix».
Отвечаем:
- Обычно выгрузка в Zabbix происходит с дискретизацией в 1 минуту, тогда как сбор счетчиков ОС мы производим с частотой обновления 3 секунды, что позволяет отслеживать даже кратковременные, но иногда большие, всплески снижения доступности ресурсов.
- В Zabbix, как правило, не настроены счетчики отдельно по каждому процессу. Дело в том, что зачастую для расследования, например, утечек памяти конкретного процесса, необходимо иметь возможность видеть выделенный объем памяти конкретному рабочему процессу (Private Bytes по конкретному rphost).
Заметим, что при нежелании заказчика идти на предоставление доступа, мы можем обойтись и без него, но тогда:
- Проверки системы по чек-листам должны быть произведены силами заказчика.
- Заказчик должен будет самостоятельно настроить сбор логов ТЖ и присматривать за ними; мы готовы передать файл logcfg.xml.
- Заказчик должен будет самостоятельно настроить сбор трассы MSSQL.
- Заказчик должен будет самостоятельно стартовать сбор счетчиков ОС (если ОС Windows, то счетчики Perfmon). Необходимо настроить и передать заказчику скрипт для создания нужного нам набора счетчиков, например так:
logman create counter 1C_counter -f bincirc -c "\Memory(_Total)\Available Mbytes" "\Memory(_Total)\Pages/sec" "\Processor(_Total)\% User Time" "\Processor(_Total)\% Privileged Time" "\Processor(_Total)\% Processor Time" "\System(_Total)\Processor Queue Length" "\Network Interface(*)\Bytes Total/sec" "\PhysicalDisk(здесь перечислить все диски вместо *)\Avg. Disk Read Queue Length" "\PhysicalDisk(здесь перечислить все диски вместо *)\Avg. Disk Write Queue Length" "\PhysicalDisk(здесь перечислить все диски вместо *)\Avg. Disk sec/Read" "\PhysicalDisk(здесь перечислить все диски вместо *)\Avg. Disk sec/Write" "\LogicalDisk(здесь перечислить все диски вместо *)\Free Megabytes" -si 3 -v mmddhhmm
Дополнительные счетчики для сервера приложений 1C
"\Process("1cv8*")\% Processor Time" "\Process("1cv8*")\Private Bytes" "\Process("1cv8*")\Virtual Bytes" "\Process("ragent*")\% Processor Time" "\Process("ragent*")\Private Bytes" "\Process("ragent*")\Virtual Bytes" "\Process("rphost*")\% Processor Time" "\Process("rphost*")\Private Bytes" "\Process("rphost*")\Virtual Bytes" "\Process("rmngr*")\% Processor Time" "\Process("rmngr*")\Private Bytes" "\Process("rmngr*")\Virtual Bytes"
Для сервера СУБД
"\SQLServer:Buffer Manager\Buffer cache hit ratio" "\SQLServer:Buffer Manager\Lazy writes/sec" "\SQLServer:Buffer Manager\Page life expectancy" "\SQLServer:Wait Statistics(*)\Log buffer waits" "\SQLServer:Wait Statistics(*)\Log write waits" "\SQLServer:Wait Statistics(*)\Lock waits" "\SQLServer:Memory Manager\Total Server Memory (KB)"
Названия счетчиков могут отличаться в зависимости от настроек локализации ОС Windows, однако отметим, что англоязычные названия устойчиво работают вне зависимости от локализации ОС как в команде logman, так и при загрузке из xml-шаблона.
Решение задач производительности по блокировкам СУБД. Случай 1
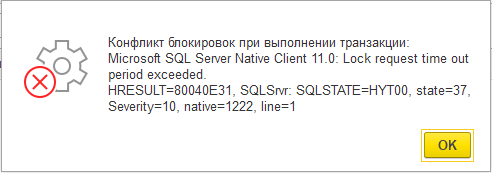
Одной из озвученных при обращении проблем заказчика являлись сообщения о блокировках с дальнейшим падением клиентских сессий 1С.
Пользователи при работе в базе начинали получать подобные сообщения и далее система на рабочем месте клиента завершала работу:
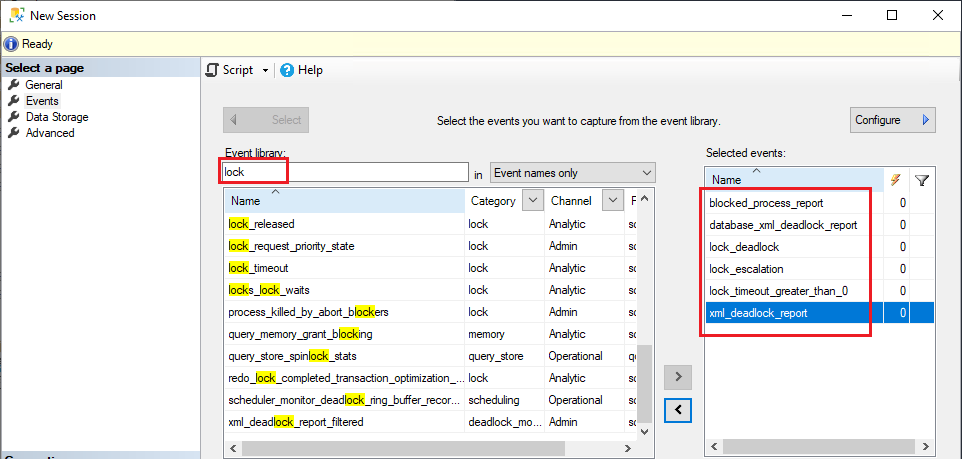
Для расследования блокировок СУБД был настроен сбор трассировки MS SQL через механизм Extended events:
Также был выставлен максимальный размер события и памяти = 128 МБ:
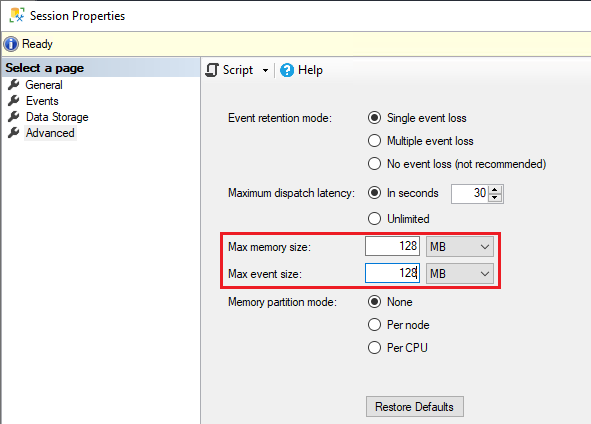
Это сделано для того, чтобы избежать ситуации, когда «тяжелые» события не включаются в трассировку (тогда вместо события в трассировке видим Trace Skipped Records).
Подробнее об установке Max memory size: learn.microsoft.com/ru-ru/sql/t-sql/statements/create-event-session-transact-sql?view=sql-server-ver16#max_memory-size--kb--mb-
По установке Max event size: learn.microsoft.com/ru-ru/sql/t-sql/statements/create-event-session-transact-sql?view=sql-server-ver16#max_event_size-size--kb--mb-
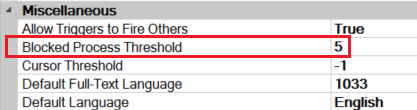
Подробнее о настройке Blocked Process Threshold
Чтобы было возможным собрать blocked_process_report, был установлен параметр экземпляра сервера Blocked Process Threshold = 5:
В документации (learn.microsoft.com/ru-ru/sql/database-engine/configure-windows/blocked-process-threshold-server-configuration-option?view=sql-server-ver16) сказано:
Параметр blocked process threshold определяет пороговое значение (в секундах), в течение которого блокированный процесс порождает сообщения. Пороговое значение может быть задано в диапазоне от 5 до 86400. Монитор блокировки переходит в активное состояние каждые 5 секунд для обнаружения условий блокировки, а также других условий, таких как взаимоблокировка. Соответственно, если параметр blocked process threshold имеет значение 1, процессы, заблокированные в течение 1 секунды, обнаруживаться не будут. Минимальная продолжительность блокировки процесса, которую можно будет обнаружить, составляет 5 секунд.
Анализ трассировки Extended events
Рассматриваем ее по времени возникшего у пользователя сообщения и чуть позднее, видим блокировку по причине асинхронного обновления статистики:
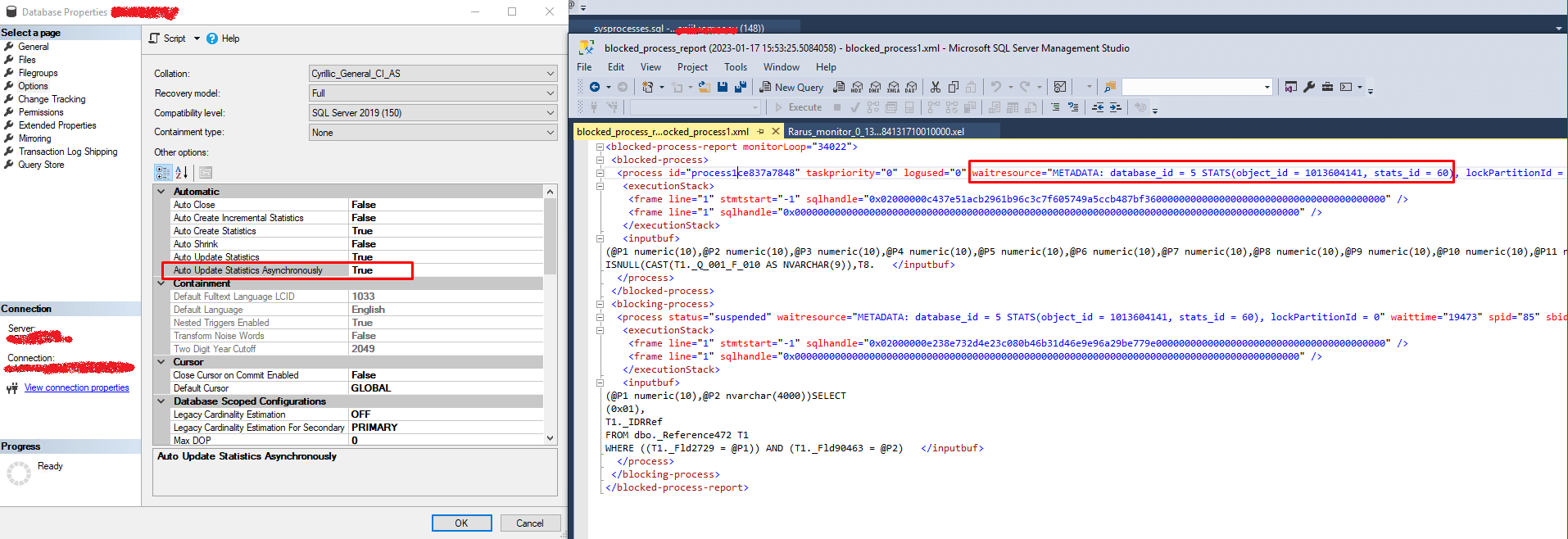
Включение данной настройки означает, что система будет пытаться обновлять статистику одновременно с выполнением запроса.
Видимо, в этот момент повысилась нагрузка и сработал предел автообновления статистики, а т. к. она асинхронная, то возникла блокировка данного типа. Также увидели, что данный режим включен для исследуемой базы.
Дальнейший анализ трассировки Extended events SQL показал следующее.
1. Самой частой причиной блокировок является как раз автоматическое обновление статистики.
В отчете видно, что заблокирован системный процесс пересчета статистики, а причина — пользовательский процесс:
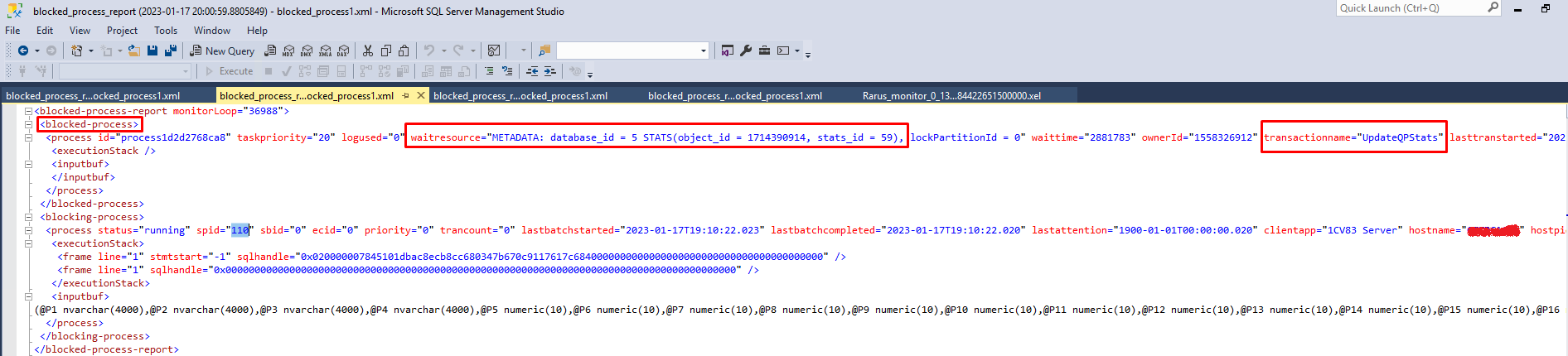

Pid процесса < 50 говорит, что это системный процесс.
Есть ситуации обратные, когда системный процесс автообновления статистики блокирует работу пользовательского процесса:

Такие события длились примерно с 11:11 до 20:01 17.01.2023 с незначительными перерывами:

2. Сразу после отключения асинхронного обновления статистики, блокировки всё равно имели место.
Причина:
- Если данная настройка была отключена сразу после наших рекомендаций, то вероятно, уже запущенные на тот момент процессы обновления статистики завершили свою работу в штатном режиме, но не завершились мгновенно, поэтому блокировки данного типа продолжались еще некоторое время в течение суток.
- Есть и другая причина блокировок, связанная с активным изменением таблицы изменений объектов плана обмена (см. скриншот):


В процессе анализа трассировки SQL обратили внимание, что довольно частая причина блокировки — работа регламентного процесса обновления статистики: у всех waitresource=METADATA...

Результат:
- После отключения асинхронного обновления статистики подобные блокировки стали возникать заметно реже.
Подробнее о блокировках при асинхронном обновлении статистик написано в статье «От экспертов „1С‑Рарус“: Блокировки в 1С при работе с внешними источниками данных и блокировки на схемах в MS SQL».
Решение задач производительности по блокировкам СУБД. Случай 2
Разберем еще один случай возникновения блокировок:

Видно, что причиной является относительно долгая транзакция, которая впоследствии приводит к превышению таймаута ожидания:
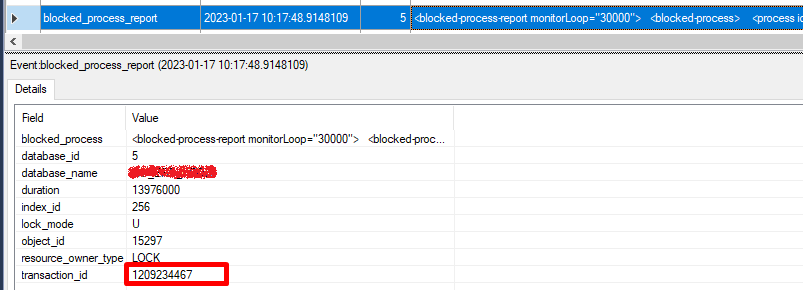
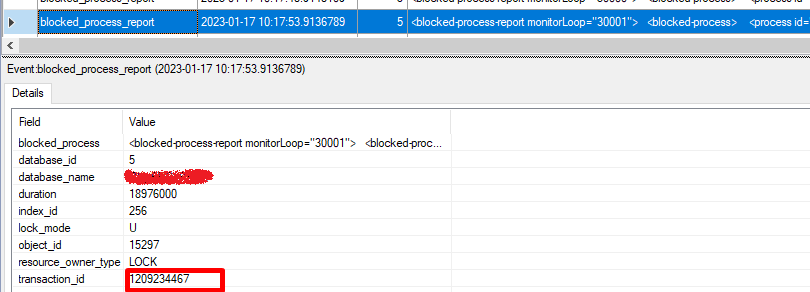
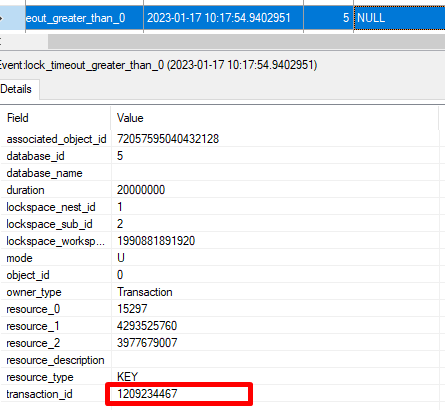
В рамках данной транзакции система пыталась заблокировать различные ресурсы, однако другая транзакция-виновник не дает этого сделать:
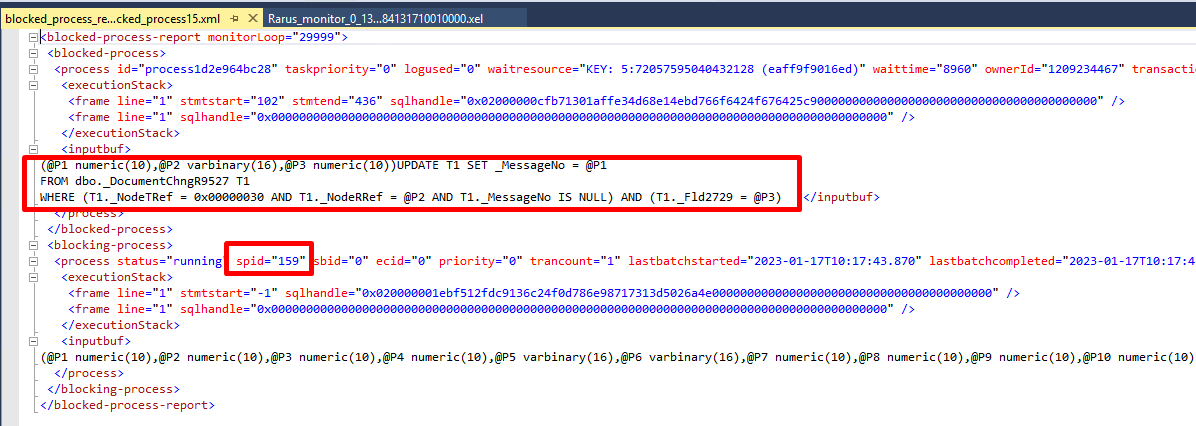
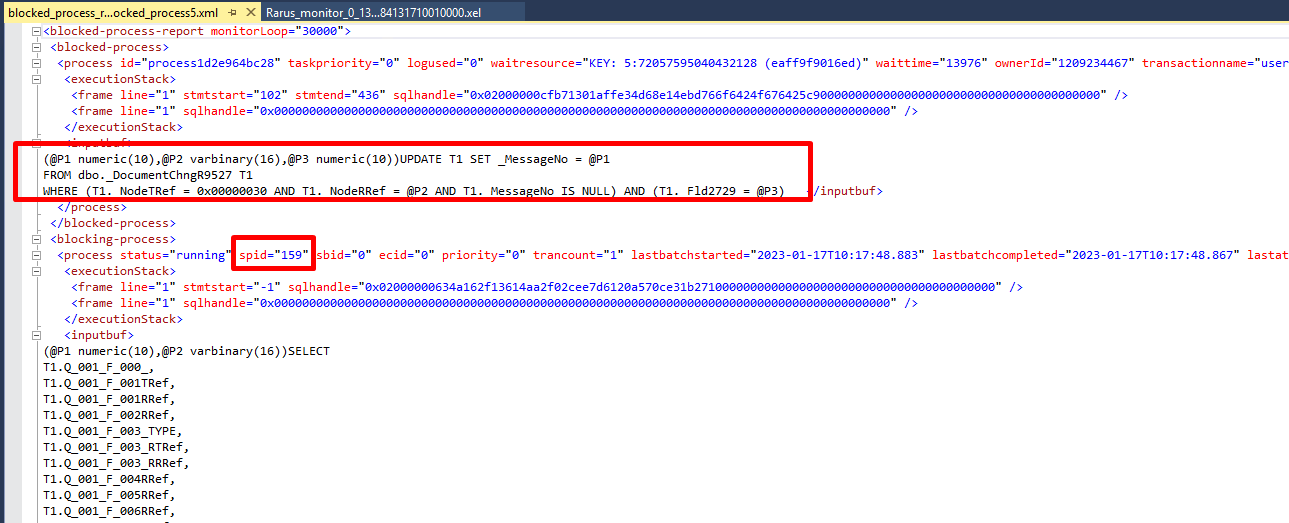
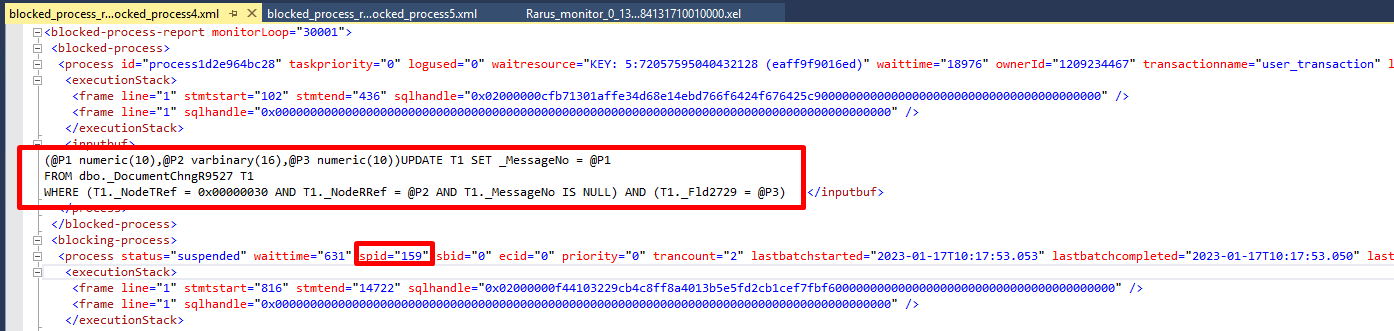
Далее мы отбираем по данному времени и spid=159 лог технологического журнала (подробнее о методах анализа технологического журнала см. на ИТС (its.1c.ru/db/metod8dev#content:5927:hdoc), а также пояснение ниже):


И поиском по контектсу по содержимому inputbuf DocumentChngR9527, обнаруживаем некоторую цикличность операций:
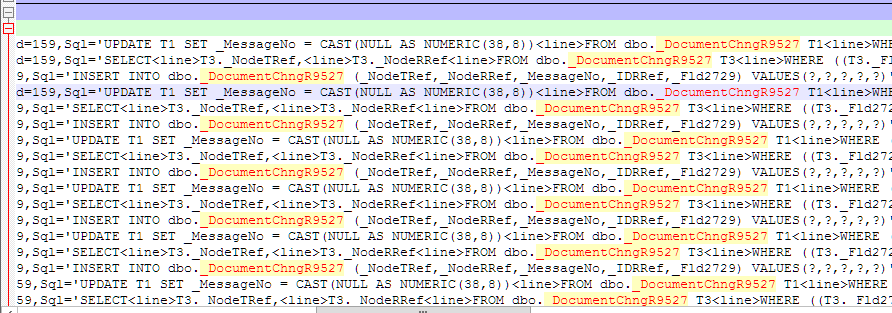
Рассмотрев один из INSERT’ов детальнее, видим контекст:
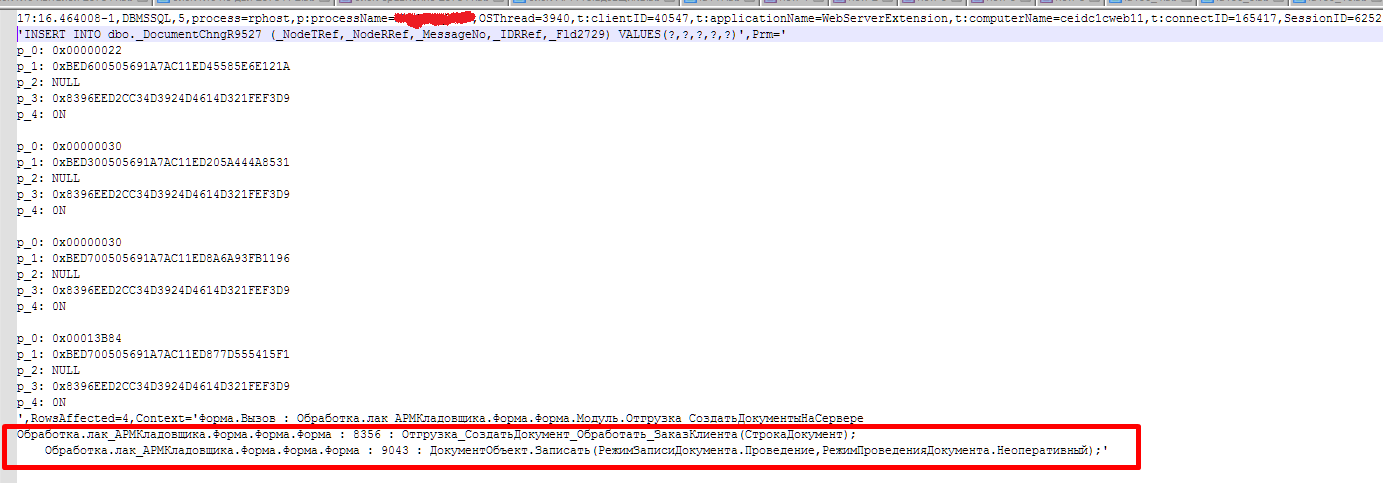
По контексту вышли на процедуру, внутри которой обнаружили открытие транзакции, внутри которой — цикл с массовым изменением данных:
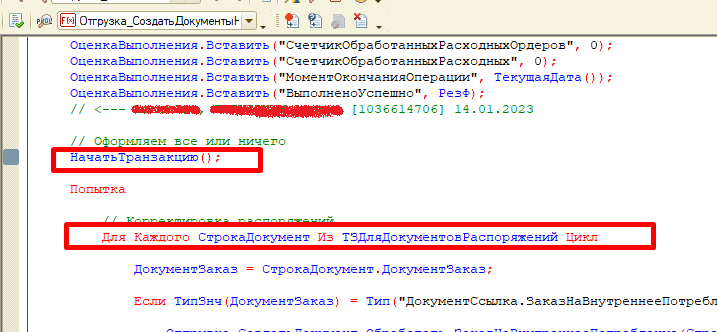
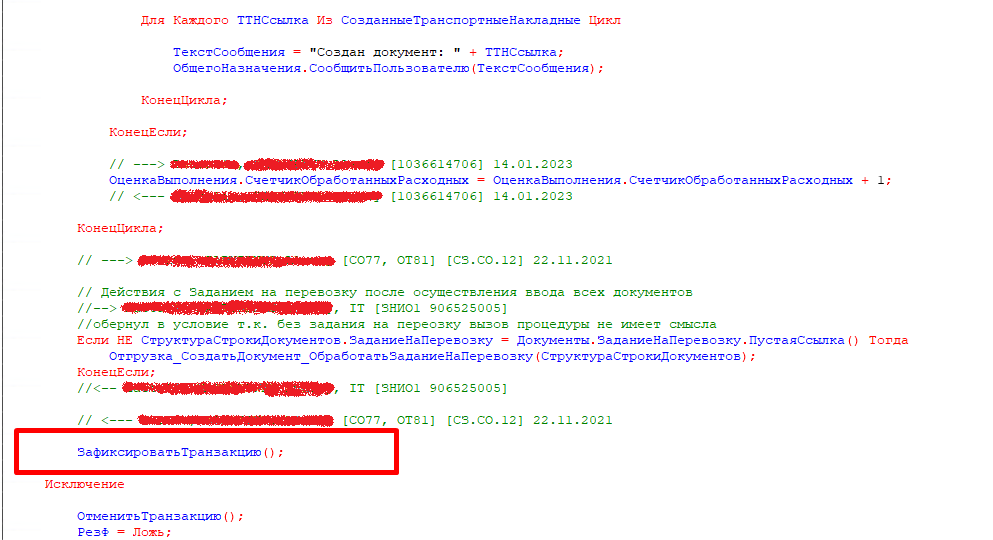
По данным логов ТЖ в данном примере транзакция длилась более 2 минут: с 10:17.12 до 10:19.39.
Начало:
...
...(в конце строки):
Окончание транзакции:

...
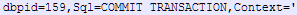
...(в конце строки):
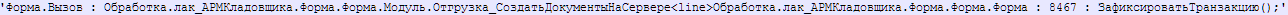
Таким образом всё, что модифицируется внутри данной транзакции, блокируется до её окончания.
Заблокированные процессы — в основном это сеансы обмена, удаляющие всю регистрацию узла, в том числе, и заблокированные записи.
Рекомендации:
- нужно либо избавиться от длительной транзакции;
- либо удалять изменения из плана обмена точечно;
- либо сделать и то, и другое.
Эпилог к длительному циклу изменения данных внутри транзакции
Причина появления неоптимальных блокировок понятна и с технической точки зрения объяснима, но вот вопрос: что делать, если функциональные требования нам говорят, что необходимо обязательно обработать весь массив документов, который обходится в цикле? А также гарантировать, что каждая цепочка документов оформлена до конца.
Например, все документы по заказам определенного склада, подлежащие отгрузке в ближайшие 2 дня должны быть обработаны; и обработаны до конца, т. е. не должно быть «оборванных цепочек», когда создана только часть документов по заказу.
Пример:
- Заказ 1 (сменить статус на Отгружено):
- Перемещение (создано под заказ и проведено).
- Реализация товаров (создана и проведена).
- Счет-фактура (создана и проведена).
- Отправить весь комплект на печать.
- Заказ 2 (сменить статус на Отгружено):
- Перемещение (создано под заказ и проведено).
- Реализация товаров (создана и проведена).
- Счет-фактура (создана и проведена).
- Отправить весь комплект на печать.
- ... и так далее.
Можно и другими способами решить эту задачу.
Можно при обходе такого массива документов поместить список заказов в служебный регистр сведений (например, создать регистр «ДокументыКОформлению»), а в теле цикла, вместо обработки (проведения и печати) документов — сначала сложить их в данный регистр. Уже потом регламентным заданием, которое будет стартовать многократно в течение дня, обходить документы из регистра и обрабатывать их. После успешной обработки всех документов по очередному заказу — удалять запись по этому заказу из регистра сведений.
Делать такую обработку без открытия транзакции: в данном случае гарантией обработки документов будет являться наличие записи с определенным заказом в регистре и периодическая обработка содержимого регистра регламентным заданием.
Плюсы и минусы:
- Плюсом подхода является отсутствие необходимости вовсе открывать на прикладном уровне какую-либо транзакцию и накладывать блокировку. Возникают только короткие блокировки при записи и проведении на уровне платформы 1С:Предприятия и модулей наборов записей регистров.
- Минусом подхода является необходимость заложить в логику создания очередного документа по заказу возможность предусмотреть, что мы можем иметь дело с «оборванной цепочкой» и проверять имеется ли уже проведенный документ «Перемещение товаров» по заказу перед тем, как его создавать.
- Ещё одним минусом является необходимость создания дополнительных объектов в системе (регистра сведений и регламентного задания), и, как следствие, решения таких задач:
- Включение возможности изменения в конфигурации по причине добавления новых объектов, небольшие сложности при обновлении.
- Присмотр за регламентным заданием.
- Очистка очень старых записей в регистре.
Еще одним вариантом является открытие транзакции на каждой итерации цикла: в начале цикла «НачатьТранзацкию» и в конце цикла «ЗафиксироватьТранзакцию». В таком случае решается задача создания всего комплекта документов по заказу без обрыва «на середине цепочки». Если документы по одному из 10 заказов провестись не смогут, например, проведётся соответствующее перемещение товаров, но не проведется реализация, то это приведет к тому, что:
- Перемещение откатится (отменится).
- Будет серия небольших транзакций, внутри каждой из которых будет накладываться блокировка на меньшее число ресурсов и по времени — только на одну итерацию цикла.
Плюсы и минусы:
- Плюсом данного подхода является отсутствие «оборванных цепочек» и отсутствие необходимости добавления новых объектов в конфигурацию.
- Минусом является появление более длительных блокировок в системе, что может стать проблемой при увеличении нагрузки на информационную систему.
Как мы осуществляем разбор логов технологического журнала
Для целей разбора можно использовать эмулятор bash в ОС Windows, например, Cygwin или GitBash или, как это cделали мы, анализировать на выделенном линукс-сервере.
Анализ, как правило, состоит из этапов:
1. Объединяем все файлы различных серверов кластера в один общий, а также заменяем перенос строки на <line> и одновременно разделяем по часам:
Здесь 23011310 — ГГММДДЧЧ.
2. Выделяем интересующее событие в отдельный файл:
3. Далее проводим дополнительный анализ в завимости от ситуации.
Подробнее о методах анализа технологического журнала см. its.1c.ru/db/metod8dev#content:5927:hdoc.
Анализ управляемых блокировок. Случай с блокировками № 3
Анализируя логи технологического журнала за период с 16:00 по 16:55 13.01.2023, разберем причины блокировок, ожидание на которых занимает наибольшее время:
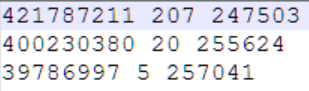
Как читать данный результат:
- 421 сек ждали 207 соединений, 400 сек ждали 20 соединений, 39 сек ждали 5 соединений. Последнее число в каждой строке — номер соединения.
Для этого применяем анализ событий TLOCK по методу, описанному выше. Далее, отбираем события TLOCK:
Затем для анализа TOP событий по длительности ожидания:
Контекст блокировок различен, но причины сводятся к блокировке на одном и том же регистре - РегистрНакопления.РасчетыСКлиентами.
По номеру соединения=247503.
Жертва:

Виновник:
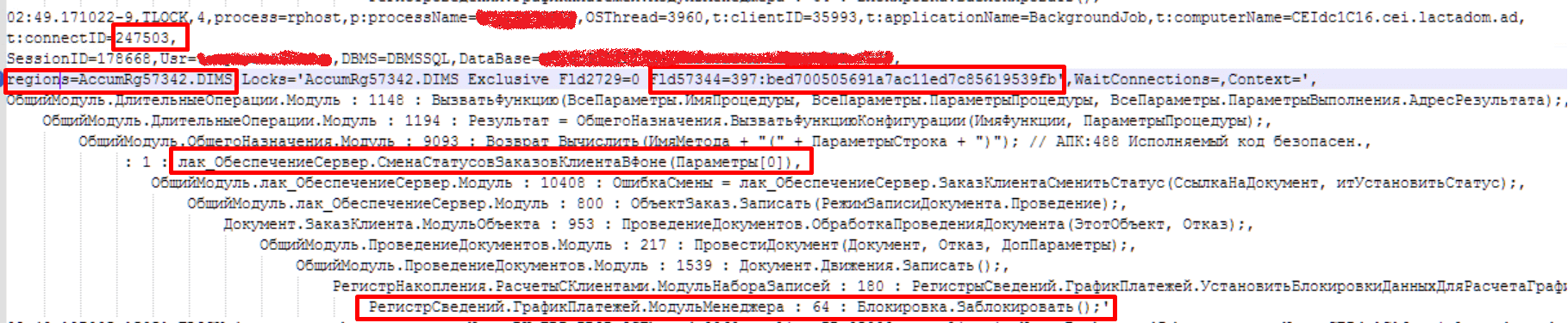
Выполняем анализ ТЖ.
Рассматриваем виновника:
Находим жертву:
По номеру соединения=255624 (метод анализа аналогичен):
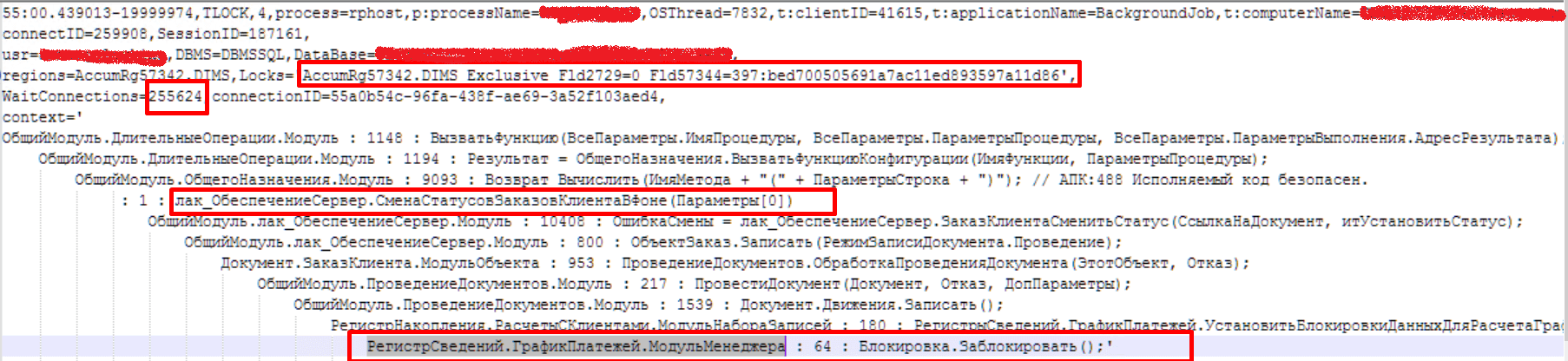

По номеру соединения=257041:
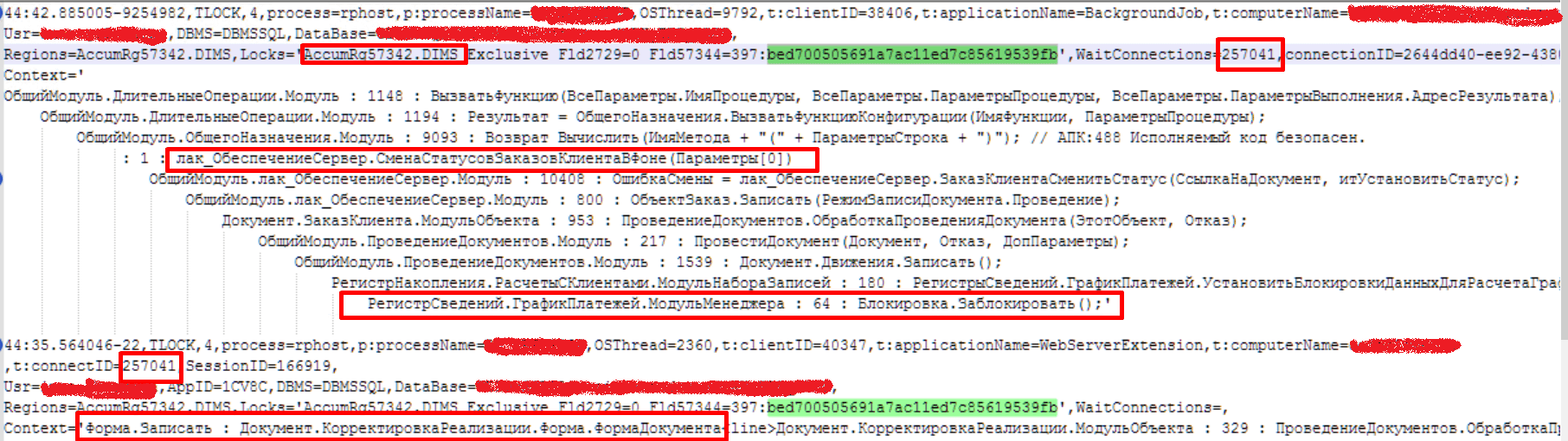
Анализируем объект ожидания и видим, что для нашего регистра РасчетыСКлиентами пересечение происходит на поле Fld57344 — а это «Объект расчетов»:

Примечание: для поиска соответствия имени БД и имени прикладного объекта в терминах 1С удобно использовать обработку «Структура хранения метаданных» (v8.1c.ru/obuchenie-programmistov/primery-razrabotki/sistemnye_protsedury_i_funktsii/kak_prosmotret_strukturu_tablits_informatsionnoy_bazy.htm).
«Объект расчетов» в прикладном решении может соответствовать договору, заказу и другим объектам системы.
Рассматриваем его ближе.
Тип объекта в логах ТЖ «Fld57344=397...» соответствует типу _Reference397:
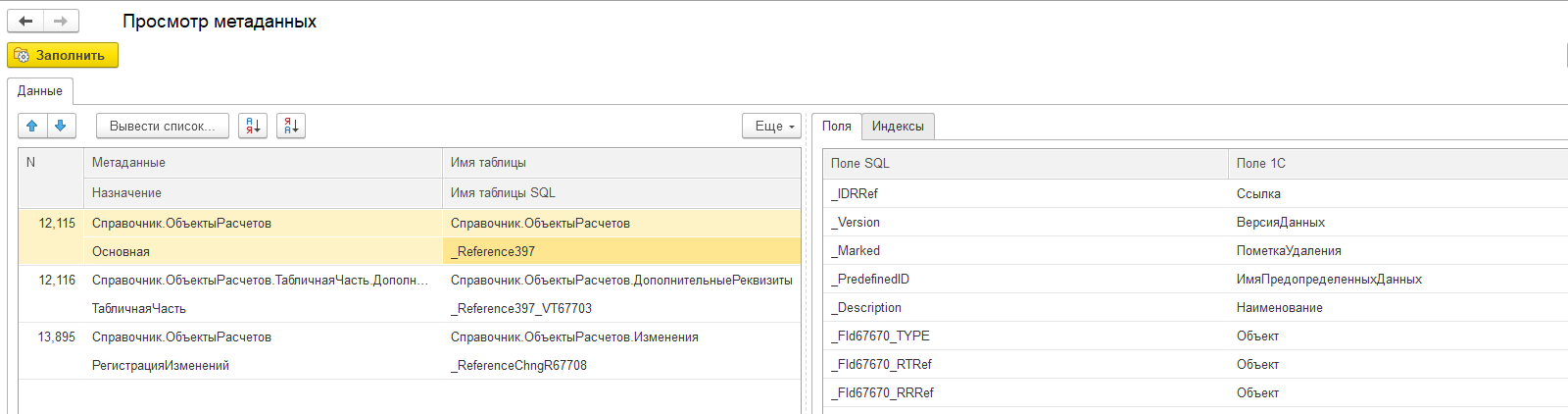
Выполняем прямой запрос к СУБД к справочнику _Reference397 с отбором по значению из объекта блокировки: bed700505691a7ac11ed7c85619539fb:
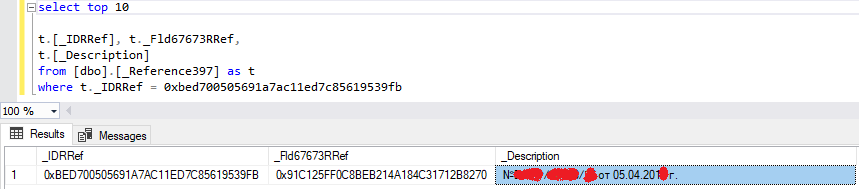
Выполняем запрос со стороны 1С к справочнику «Объекты расчетов» с отбором по полученному в _Description наименованию:

Видим, что найденная сущность это объект расчетов-договор.
Подобные блокировки также видели в ходе работы АРМ Кладовщика:

Можем рекомендовать один из следующих вариантов:
- Разделить работу пользователей по договорам так, чтобы исключить обработку документа по одному и тому же договору в один момент времени.
- Или для данных договоров перейти на взаиморасчеты другого типа: по объекту расчетов «Заказ» или «По платежным документам».
- Или сделать формирование регистра, на котором возникает блокировка отложенным во времени с помощью обработки регистра из очереди договор за договором.
Также подробная статья о методах расследования управляемых блокировок kb.1c.ru/articleView.jsp?id=124.
Итоги и выводы
В результате анализа инфраструктуры и блокировок СУБД и сервера 1С:Предприятия удалось качественно улучшить производительность базы 1С:ERP у клиента.
Не все проблемы были проанализированы, но по самым критическим из них, даны рекомендации.
Проблема блокировок и «общего замедления работы» ушла.
В статье дан анализ и рекомендации по устранению:
- Перегрузки сервера СУБД MSSQL и серверов кластера 1С:Предприятия.
- Блокировок на СУБД.
- Управляемых блокировок.
Помните, что работа эксперта — работа творческая, основанная на большом техническом опыте. Изложенные здесь примеры не являются серебряной пулей, т. е. не могут покрыть всех вариантов замедления производительности, но мы предполагаем, что какие-то из них могут случиться и у вас.
Что же касается расследования экспертных задач оптимизации работы многопользовательской системы, то мы можем порекомендовать 3 вещи:
- Не бояться расследовать экспертные случаи самостоятельно.
- Если взялись, то всё равно довести расследование до конца (даже, если привлечены внешние специалисты, всё равно финализировать собственное расследование).
- Исследовать и изучать опыт коллег и материалы.
Рекомендуем так же прослушать доклад «от первого лица» — Романова Даниила — с 1C-RarusTechDay 2023:
От экспертов «1С-Рарус»

















