




Оглавление
Введение
Почти каждый практикующий 1С-разработчик сталкивался с задачей создания HTTP-сервисов. Как правило, особых затруднений такие задачи не вызывают и выглядят они довольно просто: по функциональным требованиям определиться с методами сервиса, описать их в формате Open API, добавить соответствующие объекты конфигурации и реализовать описанные методы в модуле, протестировать их и отдать в эксплуатацию. Обычно такие задачи не считаются задачами повышенной сложности, и от исполнителя часто ожидают лишь аккуратной реализации описанных методов. Иногда в сети и между разработчиками в команде даже встречается такое шутливое название этого процесса, как «перекладывание данных в формате JSON из одного места в другое».
Однако, при постановке подобных задач, их реализации и приемке, могут забыть о таких ключевых характеристиках и требованиях к методам HTTP-сервисов, как безопасность и идемпотентность. И, прежде чем мы продолжим, давайте сразу поподробнее остановимся на терминологии, чтобы понимать, о чем в дальнейшем пойдет речь.
Термины
Методы HTTP‑запросов
URI — унифицированный (единообразный) идентификатор ресурса. Иными словами, URI — последовательность символов, идентифицирующая абстрактный или физический ресурс.
Предлагаем кратко вспомнить все методы HTTP-сервисов:
GET — клиент запрашивает у сервера содержимое ресурса. Запросы с использованием этого метода могут извлекать данные в режиме «только чтение». Параметры запроса, как правило, передаются в URI. При этом стандарт явно не запрещает клиенту передавать данные и в теле сообщения.
С другой стороны в стандартах и не описана такая возможность. Поэтому сервер, в общем случае, не обязан данные в теле GET‑запроса обрабатывать, и может их игнорировать. В ИТ‑сообществе также не приветствуется использование тела запроса в данном методе.
- HEAD — метод для получения заголовков ресурса. Запрашивает ресурс так же, как и метод GET, но без возврата тела ответа.
- POST — создает новый ресурс по данным, которые указаны в теле запроса. Также этот метод можно использовать для загрузки файлов на сервер.
- PUT — создает новый ресурс или полностью заменяет существующий ресурс данными, которые указаны в теле запроса.
- PATCH — работает таким же образом, как и PUT, но по отношению только к части ресурса. Используется для частичного изменения ресурса.
- DELETE — удаляет указанный ресурс.
- OPTIONS — позволяет запросить список методов, которые поддерживает сервер.
- TRACE — позволяет проверить, изменяют ли промежуточные узлы в сети запрос клиента. Возвращает полученный запрос так, что клиент может увидеть, какую информацию промежуточные серверы добавляют или изменяют в запросе.
- CONNECT — преобразует соединение запроса в прозрачный TCP/IP-туннель, обычно чтобы содействовать установлению защищенного SSL-соединения через нешифрованный прокси.
На практике чаще всего используются методы GET, POST, PUT, PATCH, DELETE. Остальные из перечисленных выше методов являются несколько специфичными и применяются в ситуациях и задачах, которые в рамках данной статьи мы не будем рассматривать.
На текущий момент доступно три версии сетевого протокола HTTP, используемого для доступа к всемирной паутине сети Интернет. Далее перечень в формате «Версия протокола: Спецификация»:
- HTTP/1.1: RFC 2616 (tools.ietf.org/html/rfc2616);
- HTTP/2: RFC 7540 (datatracker.ietf.org/doc/html/rfc7540);
- HTTP/3: RFC 9114 (ietf.org/rfc/rfc9114.html).
Все перечисленные выше методы подробно описаны в этих спецификациях. При желании с ними можно ознакомиться по приведенным ссылкам.
Безопасность и идемпотентность методов HTTP‑запросов
В разделе №9 спецификации HTTP/1.1: RFC 2616 дается подробное определение таким характеристикам HTTP-методов, как безопасность и идемпотентность. Ниже мы приводим не дословный перевод этого раздела, а его свободную интерпретацию, чтобы изложить его более простым и понятным языком.
Сводная таблица методов HTTP‑запросов и их характеристик
| Метод | Безопасность | Идемпотентность | Комментарий |
|---|---|---|---|
| GET | ✅ |
✅ |
Не меняют состояние системы. Только чтение данных на сервере |
| HEAD | ✅ |
✅ |
|
| POST | ❌ |
❌ |
Меняют состояние системы |
| PUT | ❌ |
✅ |
|
| PATCH | ❌ |
❌ |
|
| Спецификация RFC 5789 | |||
| DELETE | ❌ |
✅ |
Меняет состояние системы |
| OPTIONS | ✅ |
✅ |
Технические запросы, не меняют состояние системы |
| TRACE | ✅ |
✅ |
|
| CONNECT | ✅ |
✅ |
Как мы видим из таблицы, корректно реализованные методы GET, HEAD, OPTIONS, PUT и DELETE идемпотентны, методы POST или PATCH — нет. Все безопасные методы являются идемпотентными (Глоссарий MDN Web Docs: Идемпотентный метод, developer.mozilla.org/ru/docs/Glossary/Idempotent).
Важно отметить, что требование идемпотентности связано с тем, что запрос может повторяться автоматически несколько раз, если до того, как клиент сможет прочитать ответ сервера, произойдет сбой связи. Или если веб-сервер вернет какую-либо ошибку, при которой есть смысл попробовать отправить запрос еще раз. Например, если веб-сервер вернет клиенту ошибку 504 Gateway Timeout из-за чрезмерно длительной обработки запроса.
Метод HTTP является идемпотентным, если повторный, идентичный первому запрос, отправленный один или несколько раз подряд, имеет один и тот же эффект, не изменяющий состояние системы. Другими словами, идемпотентный метод при повторном выполнении не должен иметь никаких побочных эффектов (side-effects), кроме сбора статистики.
Что мы здесь понимаем под операцией сбора статистики? Это когда повторный запрос не вызывает повторное изменение системы, а возвращает в ответе какую-то полезную информацию, например о том: когда был выполнен самый первый запрос по текущей операции, и с каким результатом текущая операция была выполнена.
Далее, при детальном рассмотрении паттерна идемпотентности, которому и посвящена данная статья, мы рассмотрим с вами пример отправки такой статистики в ответе на повторный запрос по уже завершенной операции. Подробнее алгоритм проверки и обеспечения идемпотентности запросов описан в разделе Паттерн The Idempotency-Key HTTP Header Field.
Консистентность данных
Консистентность данных означает, что все узлы в системе должны иметь одинаковое представление о текущем состоянии данных в системе. При этом любое изменение данных должно быть видимо для всех узлов системы.
Устойчивость к разделению означает, что система должна продолжать работу при разделении сети на несколько частей, при этом данные должны оставаться консистентными.
Гонка запросов
В качестве иллюстрации к данному определению рассмотрим следующую ситуацию. Представим, что в нашем приложении имеется общий ресурс, какое-то хранилище данных, из которого мы можем инициализировать начальное значение нашей переменной. Два потока одновременно пытаются выполнить операцию инкремента над этой переменной, увеличивая её значение на единицу.
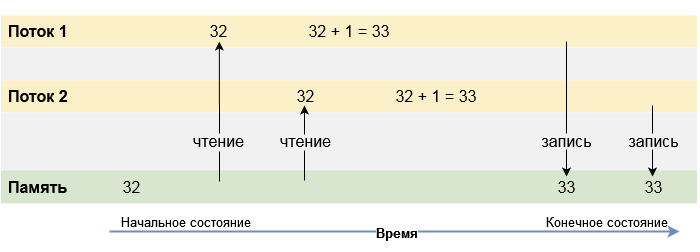
Что может произойти при этом, разберем в хронологическом порядке:
- Первый поток читает текущее значение переменной count (32).
- Второй поток также читает текущее значение переменной count (32).
- Первый поток увеличивает значение переменной count на единицу (33).
- Второй поток также увеличивает значение переменной count на единицу (33).
В результате выполнения данного приложения, записываемое в память значение переменной count будет равно 33 вместо 34. Это произошло из-за того, что оба потока одновременно считали начальное значение переменной и оперировали им. Для правильной работы приложения, второй поток должен был использовать результат вычисления первого потока.
Стоит отметить, что многопоточности лучше поддаются такие операции, которые можно выполнять независимо друг от друга.
Например, если нужно из большого файла в 100 тысяч строк загрузить данные в систему, можно разбить его содержимое на 10 частей по 10 тысяч строк и загружать их десятью потоками одновременно. При таком применении нескольких потоков конечный результат работы приложения не зависит от очередности их выполнения.
Термин состояние гонки относится к инженерному жаргону и появился вследствие неаккуратного дословного перевода английского эквивалента. В более строгой академической среде принято использовать термин неопределенность параллелизма.
Состояние гонки — «плавающая» ошибка (гейзенбаг), проявляющаяся в случайные моменты времени и «пропадающая» при попытке её локализовать.
Состязание сигналов в цифровых устройствах
В электрической цепи переходный процесс характеризуется плавным инерционным изменением тока и напряжения в цепи в ответ на приложенное внешнее воздействие (Переходный процесс, ru.wikipedia.org/wiki/Переходный_процесс).
Так как в любых линиях связи сигналы распространяются с некоторой задержкой, вносимой элементами линии связи, то на выходе любого устройства сигнал Uвых меняется с некоторой задержкой относительно входного сигнала Uвх. Такой разброс параметров реальных элементов, влияющих на задержку сигнала, и различные длины линий связи в устройствах могут стать причиной неодновременного изменения состояний входов некоторых элементов схем.
Хоть мы в большинстве своем и не являемся «аппаратчиками», все же давайте попробуем разобраться, о чем идет речь.
Представим, что у нас есть вход в некий элемент управления, представляющий собой часть цифрового устройства. В нашем примере в качестве такого элемента управления выступает простейший RS-триггер.
RS-триггер получил название по названию своих входов. Вход S (Set — установить англ.) позволяет устанавливать выход триггера Q (Quit — выход англ.) в единичное состояние (записывать единицу). Вход R (Reset — сбросить англ.) позволяет сбрасывать выход триггера Q в нулевое состояние (записывать ноль).
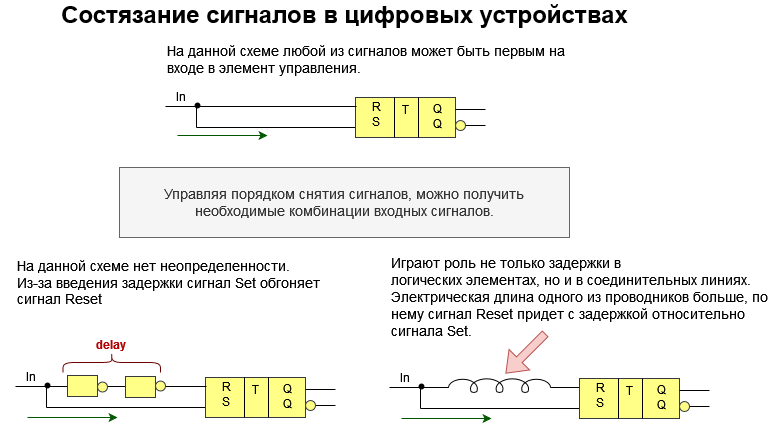
На иллюстрации выше изображено только два способа из многих, которыми пользуются разработчики цифровых устройств, чтобы управлять порядком снятия сигналов. На первой схеме (слева, внизу) в линию сигнала Reset добавлены два элемента, выполняющих роль сопротивления. Эти элементы приводят к такой задержке сигнала Reset, которая гарантирует, что он придет в триггер вторым. На второй схеме (справа, внизу) используется тот же принцип, но уже за счет увеличения длины линии сигнала Reset. Длина линии подбирается таким образом, чтобы гарантировать снятие триггером сигнала Set в первую очередь.
R |
S |
Q(t) |
Q(t+1) |
Пояснения |
|---|---|---|---|---|
0 |
0 |
0 |
0 |
Режим хранения информации R=S=0 |
0 |
0 |
1 |
1 |
|
0 |
1 |
0 |
1 |
Режим установки единицы S=1 |
0 |
1 |
1 |
1 |
|
1 |
0 |
0 |
0 |
Режим записи нуля R=1 |
1 |
0 |
1 |
0 |
|
1 |
1 |
0 |
* |
R=S=1 запрещенная комбинация |
1 |
1 |
1 |
* |
Если на логический элемент «И» подать последовательно комбинации сигналов 01, 10, то на выходе получим нуль. Но если один из сигналов, под воздействием переходных процессов, изменится несколько раньше второго, то на входах может кратковременно возникнуть иная комбинация. В случае опережения первым сигналом второго, получим запрещенную комбинацию 11, а на выходе в этот момент времени возникнет единичный импульс (ru.wikipedia.org/wiki/Единичный_импульс).
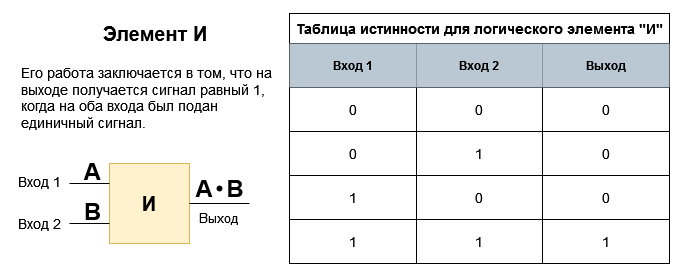
Если же второй сигнал опередит первый, то сигнал на выходе не изменится. Иногда сочетание задержек создает на входе комбинации, при которых выходные сигналы принимают значения, не соответствующие алгоритму работы схемы — так получается состязание между сигналами.
Какие есть еще способы борьбы с гонкой сигналов в цифровых устройствах? Разберемся на примере «продвинутой» версии устройства, так называемого синхронного RS-триггера.
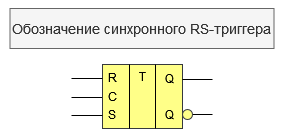
Символ «C» в данной схеме обозначает линию, по которому в элемент поступает тактовый, синхронизирующий сигнал.
Схема простейшего RS-триггера позволяет запоминать состояние логической схемы, но так как в начальный момент времени может возникать переходный процесс (вызывает «состояние гонки»), то запоминать состояния логической схемы нужно только в определенные моменты времени, когда все переходные процессы закончены (Цифровые устройства. RS-триггер, digteh.ru/digital/RS_trigg.php?ysclid=luzpba7lyk477727485).
Синхронными называются триггеры, запоминающие входные сигналы только в момент времени, определяемый сигналом синхронизации. Все переходные процессы в комбинационной логической схеме должны закончиться за время периода синхросигнала, подаваемого на входы триггеров.
На этом с гонкой сигналов в цифровых устройствах, пожалуй закончим. Не будем погружаться в нее глубже, несмотря на то, что тема очень интересная.
Почему вообще стоило так подробно рассказывать об этом? Во-первых, для понимания откуда у гонки запросов в HTTP‑сервисах, как говорится, «ноги растут». Во-вторых, это способствует более глубокому пониманию процессов, возникающих на прикладном уровне, с которыми мы — инженеры-программисты, чаще всего имеем дело при решении повседневных задач.
Гонка запросов в HTTP-сервисах
В терминах HTTP-сервисов, состояние гонки может произойти в результате получения двух одинаковых запросов с минимальной задержкой между ними или без неё. Система получатель может получить и обрабатывать запросы в порядке их отправления, в обратном порядке или даже одновременно (при многопоточной обработке).
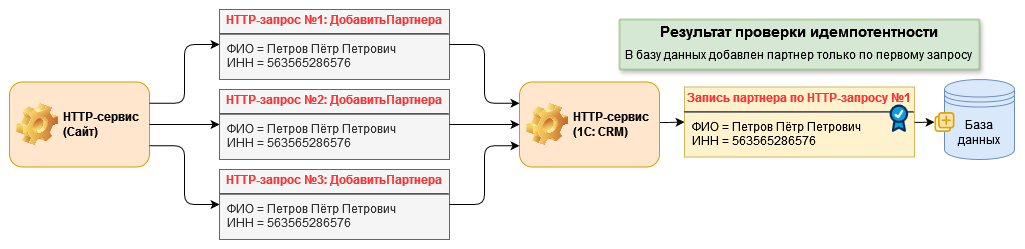
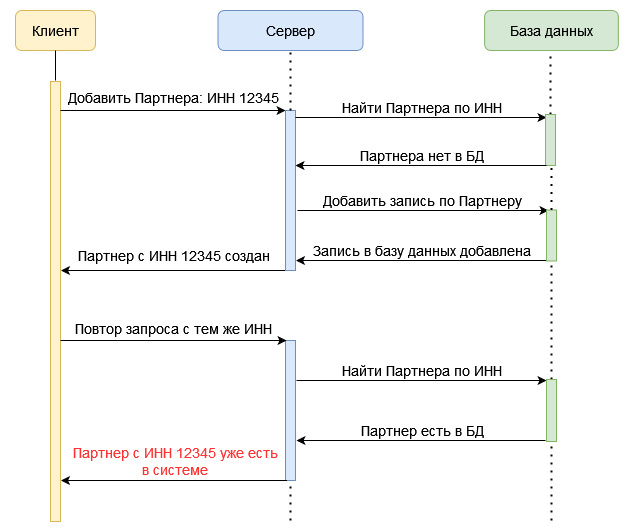
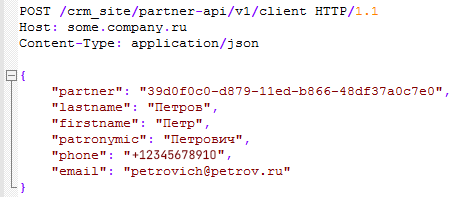
Любой из этих запросов может быть обработан первым, но если второй запрос выполнится сразу, не дожидаясь результатов обработки первого запроса и не проверяя их — возникает риск выполнения одной и той же операции дважды. На иллюстрации ниже приведен пример такой ситуации, приведшей к созданию дублирующихся элементов справочника «Партнеры».
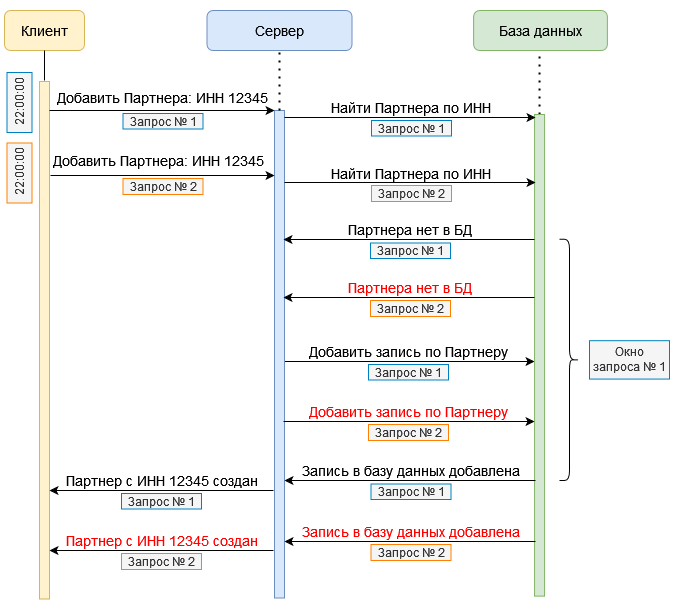
На этом рисунке отчетливо видно, как в окне исполнения запроса №1, когда он принимает решение о возможности добавления нового партнера, точно такое же решение принимает и запрос №2, так как в этот момент партнера в базе данных действительно еще нет.
Похожие ситуации также возможны, когда первый запрос попал в длительную обработку, превышающую по длительности отсечку по таймауту. В таких случаях события могут развиваться по следующему сценарию: веб-сервер отдает отправителю ошибку с кодом 504 Gateway Timeout, продолжая на самом деле обрабатывать запрос, отправитель шлет повторный запрос, который система пытается также выполнить, не проверяя состояние выполнения первого запроса. В результате исполнения такого сценария могут наступить нежелательные последствия. Например такие, как двукратное списание денежных средств с расчетного счета за одну покупку.
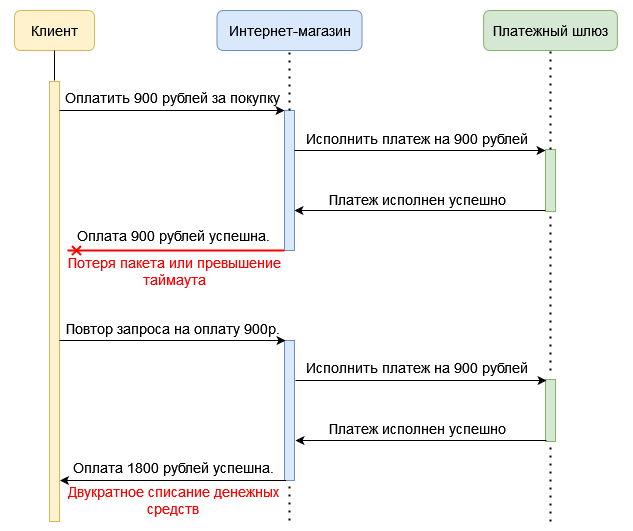
Помним также, что повторный запрос может быть отправлен и из-за ошибки клиентского приложения.
Если в простых HTTP-сервисах пренебрежение требованиями по обеспечению безопасности и идемпотентности методов может никак не сказаться, или наступившие последствия могут оставаться долгое время незамеченными, то в относительно сложных реализациях это может приводить к возникновению побочных эффектов, нарушению консистентности данных между клиентом и сервером.
Под простыми сервисами подразумеваются HTTP-сервисы, методы которых либо отдают информацию на входящий запрос в режиме «только чтение», либо их логика изначально предусматривает проверку на существование в системе создаваемого ресурса с целью исключения дублей.
Например, по входящему запросу к нашему http-сервису требуется создать партнера, заполнить его ИНН. Перед созданием партнера, необходимо выполнить его поиск по полю ИНН. Если партнер с указанным ИНН уже существует, выдать в ответе на входящий запрос ошибку с указанием причины, что такой партнер уже есть в системе.
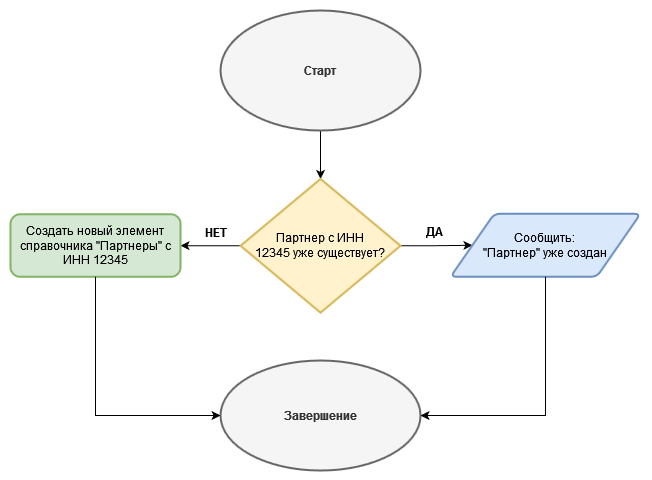
При этом, даже в данном примере, сервис можно считать «простым» только в идеальных условиях, когда сетевая инфраструктура от отправителя до получателя и обратно работает без сбоев, когда время обработки такого запроса не превышает времени таймаута веб-сервера, когда серверные приложения отправителя и получателя работают без ошибок и так далее.
На практике, в реальной эксплуатации, в распределенных средах и гетерогенных сетевых окружениях, когда между клиентом и сервером может находиться несколько промежуточных аппаратно-программных посредников, работающих по разным протоколам и в различных операционных системах, когда сетевые пакеты могут теряться, а разработчики могут допускать ошибки при проектировании и реализации многопоточных клиентских и серверных приложений, таких идеальных условий добиться практически невозможно.
Поэтому в рамках данной статьи принимаем, что любой HTTP-сервис, имеющий небезопасные методы, работающий в реальных условиях и оказывающий прямое или косвенное влияние на экономические и финансовые показатели предприятия — является сложным и требующим обеспечения устойчивости к разделению и консистентности данных между клиентом и сервером.
Паттерн The Idempotency-Key HTTP Header Field и пример его реализации в 1С, опыт применения в реальной эксплуатации
Пример выше со схемой добавления нового партнера в базу данных уже содержит базовую проверку на наличие партнера с указанным ИНН. В большинстве случаев такая проверка позволяет избежать дублирования партнера при получении повторных запросов. Однако, как мы обсудили выше, в реальной эксплуатации этого может быть недостаточно по причинам, подробно описанным в предыдущих разделах.
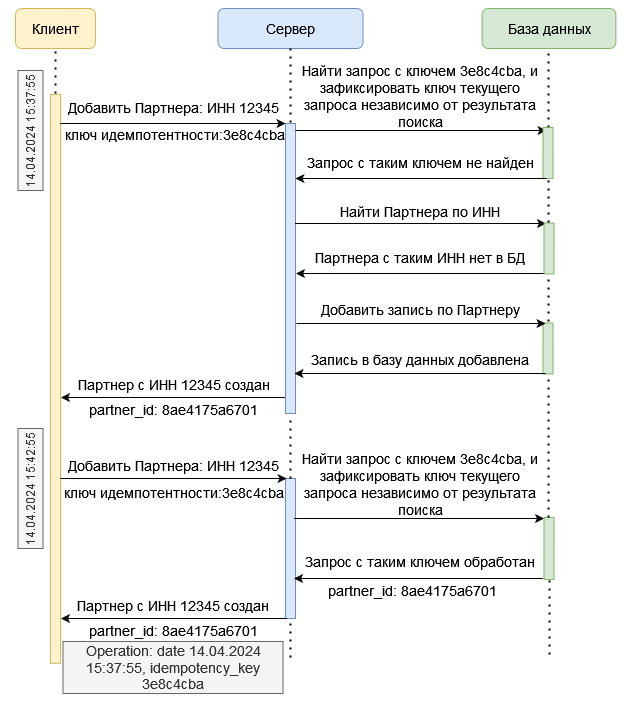
Как может выглядеть для нашего примера упрощенная схема алгоритма проверки идемпотентности запроса?
В HTTP-запросе, кроме данных тела запроса передается уникальный ключ, которым мы маркируем все запросы на добавление Партнера с ИНН 12345 и прежде, чем проверить наличие партнера по его ИНН, проверяем наличие уже обработанного или все еще находящегося в обработке такого же запроса с тем же уникальным ключем. В случае обнаружения успешно обработанного запроса, в ответе возвращаем готовый результат его обработки вместе со статистической информацие в блоке Operation.
HTTP-сервис в 1С:CRM
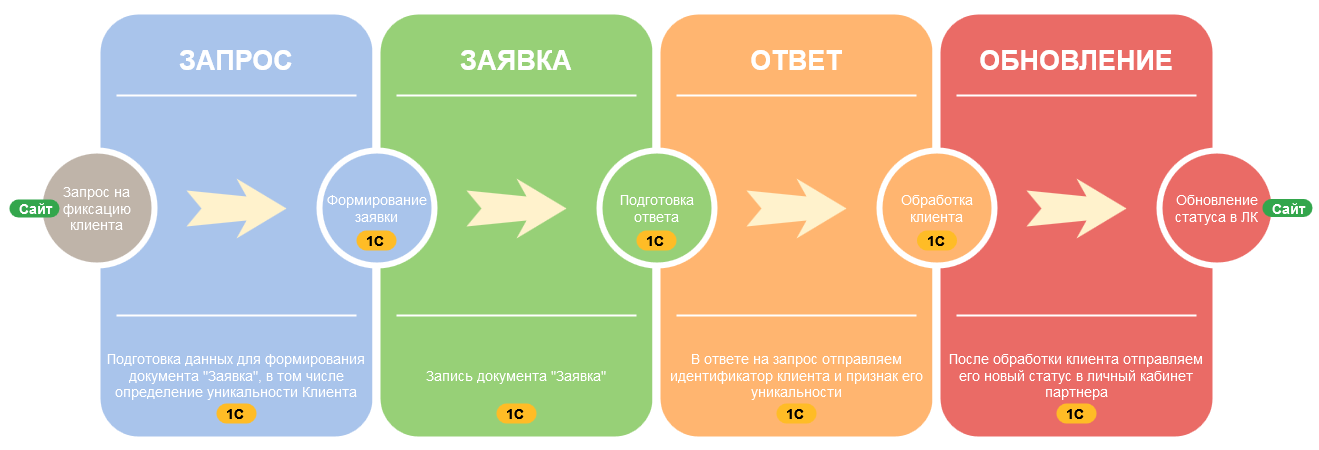
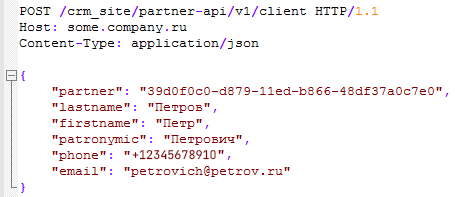
Поводом для написания данной статьи стал один из разрабатываемых HTTP‑сервисов в конфигурации 1С:CRM. Среди методов сервиса присутствует небезопасный POST-метод формирования заявок на фиксацию клиентов, который предусматривает возможность создания объектов системы по входящим запросам.
Заказчик запустил на своем сайте партнерскую программу по привлечению клиентов. Если участник партнерской программы приводит уникального клиента, которого еще нет в клиентской базе, то приведенный клиент закрепляется за приведшим его агентом, которому выплачивается повышенный процент агентского вознаграждения. За неуникального клиента, который на момент получения заявки от участника партнерской программы уже есть в клиентской базе, участник партнерской программы получает меньший размер агентского вознаграждения. Закрепление клиента за партнером происходит с помощью объекта Заявка с признаком уникальности. «Уникальный» признак рассчитывается на стороне 1С:CRM.
В 1С запросы поступают со стороны сайта. В ответах на запросы создания заявок на фиксацию партнера, сайту отправляется идентификатор созданной заявки и признак уникальности или коды ошибок при их возникновении.
Созданные заявки попадают в работу к пользователям 1С, и впоследствии у этих заявок могут быть изменены статусы, они могут «обрастать» дополнительными связями и наполняться различным содержимым. Информация об этих статусах и связях по определенным триггерам отправляется уже исходящими из 1С запросами обратно на сайт, в личный кабинет участника партнерской программы.
Метод на добавление заявки изначально был разработан без соблюдения требований к обеспечению безопасности и идемпотентности, но на этапе внутреннего тестирования в идеальных условиях никаких коллизий и побочных эффектов выявлено не было. Сервис прошел этап приемки и благополучно был передан в опытно-промышленную эксплуатацию. И уже во время опытно-промышленной эксплуатации мы столкнулись с несколькими интересными ситуациями. Ниже рассмотрим эти кейсы, как мы их решали, и какой механизм отказоустойчивости в итоге у нас получился.
Ошибка 504 Gateway Timeout
Первым звоночком об имеющихся проблемах в работе небезопасного POST-метода стали сообщения со стороны команды сайта о том, что на некоторые запросы мы отправляем им ответ с ошибкой 504 Gateway Timeout. Это говорит о том, что веб-сервер не дождался ответа от сервиса в отведенное время и принудительно разорвал соединение.

После тщательного изучения логов нашего сервиса, сопоставления с логами сайта и журнала регистрации мы пришли к выводу, что на самом деле эти запросы на нашей стороне были успешно обработаны, сформированы и записаны в базу данных заявки на фиксацию уникальных клиентов. По ним подготовлены ответы для передачи на сайт, но длительность обработки запросов превысила таймаут веб-сервера, который вместо подготовленных ответов отправлял сайту сообщения об ошибках 504 Gateway Timeout.

Ниже приведу чуть более подробный разбор данной ситуации, чтобы было понятно как мы пришли к таким выводам. Примем, что на веб-сервере установлено время ожидания ответа от HTTP-сервиса 1C:CRM равное 50 секундам. Если по истечении этого времени веб-сервер не получает ответ от сервиса, тогда он сам отдает клиенту ответ с кодом ошибки 504 Gateway Timeout.
Запись логов нашего журнала входящих запросов
| Период | Запрос | Код ответа | Длительность |
|---|---|---|---|
| 08.04.2024 17:45:30 |
|
200 ОК |
90 сек. |
По этим логам мы видим, что запрос обрабатывался больше 50 секунд, но обработка запроса на стороне 1С не была прервана и завершилась успешно, в журнале входящих вызовов зафиксирован соответствующий код ответа 200 ОК.
В журнале регистрации 1С, примерно на дату поступления запроса, мы видим фиксацию транзакции на запись документа «Заявка». В базе 1С:CRM мы также видим созданную заявку на фиксацию клиента с данными из запроса. Так мы убедились в том, что поступивший запрос действительно успешно обработан.
Как тот же самый запрос видели коллеги по логам на стороне сайта?
| Период | Запрос | Код ответа |
|---|---|---|
| 08.04.2024 17:45:30 |
|
504 Gateway Timeout |
Такая ситуация приводила к тому, что некоторая часть заявок от партнеров на фиксацию уникальных клиентов до нас доходила и успешно обрабатывалась, но сайту информация об этом не доходила, соответственно и партнеры в личном кабинете на сайте, по отправленной ими заявке, видели статус с ошибкой обработки заявки, по которой никаких дальнейших действий не предпринималось. По логам сайта получается, что по этому запросу зафиксировать уникального клиента за собой не получилось.
Если же партнер пробовал на сайте повторно вручную отправить еще один подобный запрос, который в этот раз на стороне 1С:CRM обрабатывался без таймаута, то в ответ ему приходил статус о том, что клиент за ним зафиксирован уже не уникальный. Хотя, на самом деле, именно этот партнер привел уникального клиента.
Нетрудно представить, что вероятность возникновения таких коллизий в долгосрочной перспективе может привести к заниженному вознаграждению участников партнерской программы, сказаться на имидже заказчика и доверии к нему и, как следствие, на его финансовых показателях.
Для быстрого решения этой проблемы можно было бы просто увеличить время до таймаута на веб-сервере, чтобы дать сервису больше времени на обработку запроса. Но так как это отразилось бы на всех сервисах системы и больше похоже на маскировку проблемы, чем на её решение, от такого варианта сразу отказались и решили сфокусироваться на тщательном разборе и исправлении ситуации.
Примерно в это же время от пользователей CRM приходят сообщения о том, что в систему стало поступать слишком много заявок, что их количество не соответствует действительности. В какой-то момент пришлось проводить работы по удалению лишних заявок из системы. При обсуждении этой проблемы с командой сайта выяснили, что они приняли решение отправлять в сторону 1С:CRM повторные запросы, если по первому запросу ответ не пришел совсем, или пришел с сообщением об ошибке.
Такой подход, без применения проверки идемпотентности запросов, привел к тому, что в системе начали накапливаться неуникальные заявки, создаваемые повторными запросами. При этом, по-прежнему остается вероятность того, что партнеры могут иногда получать недостоверную информацию по уникальности зафиксированных за ними клиентов.

Третьим пазлом в картину проблем с сервисом стала информация о том, что по некоторым заявкам на фиксацию уникальных клиентов мы не можем выгрузить обновление статусов исходящими запросами из CRM на сайт, по причине отсутствия этих заявок в базе данных сайта. То есть мы пытаемся отправить исходящие запросы со стороны 1С:CRM на сайт, а сайт возвращает нам ошибку с указанием такой причины. Как мы помним, на сайте этих заявок нет, потому что ранее мы отдавали по ним ошибку 504 Gateway Timeout, в то время как на самом деле у нас они создавались и пользователи 1С:CRM имели возможность производить их дальнейшую обработку. По результатам обработки менеджерами таких заявок в 1С:CRM, статусы и другая информация о заявке меняется и возникает необходимость отправить обновление этой информации на сайт.

На иллюстрации выше изображена как раз подобная ситуация, когда из трех запросов на обновление заявки на сайте, удалось обновить только одну — по запросу №2. По остальным вернулся ответ с сообщением об ошибке.
При анализе всех описанных выше ситуаций в совокупности стало очевидно, что все они очень тесно связаны между собой, и по сути, каждая следующая является закономерным продолжением предыдущей. Устранив первую проблему с таймаутами и некорректной обработкой повторных запросов, мы устраним всю цепочку ошибок.
Применяем The Idempotency-Key HTTP Header Field
Нужно было пересмотреть стратегию обработки запросов на создание заявки. Мы пришли к тому, что нужно рассматривать как отдельную операцию не каждый запрос, а считать отдельной операцией конечный результат от момента отправления первого запроса на формирование заявки до ее успешной записи в базе 1С:CRM независимо от того, сколько на это потребуется повторных запросов со стороны сайта.
Для этого необходима сквозная идентификация каждой заявки, чтобы мы могли отличать не только запросы по разным заявкам друг от друга, но и понимать — в данный момент мы обрабатываем первый запрос по конкретной заявке или повторный? Так, при поступлении повторных запросов, мы сможем проверить не была ли заявка успешно создана еще по первому запросу и отклонить обработку повторного запроса, если заявка с таким идентификатором уже создана или формируется в настоящий момент.
Сначала мы предполагали, что идентификатор заявки из запроса будет храниться в соответствующем реквизите объекта «Заявка». Такой подход действительно мог бы решить нашу задачу, но мы понимали, что выявленный кейс относится не только к конкретному POST-методу этого конкретного сервиса. Это было больше похоже на общую проблему, которую нужно решать более масштабно и универсально.
В процессе поиска подходящего решения мы вышли на спецификацию The Idempotency-Key HTTP Header Field (Спецификация, ietf.org/archive/id/draft-ietf-httpapi-idempotency-key-header-01.html), в которой нашли не только подтверждение тому, что описанная ситуация является общей проблемой сервисов, но и описание методов, позволяющих взять подобные ситуации под контроль.
Спецификация посвящена методам обеспечения идемпотентности запросов, и предлагает сквозную идентификацию операции на всем протяжении ее жизненного цикла, с момента формирования первого запроса по операции на стороне отправителя, до успешного её выполнения на стороне получателя.
Причем речь идет не об идентификации объекта, порождаемого операцией, а об идентификации только самой операции и ее запросов (первого и повторных). Идентификатор операции не хранится в объекте, ею порожденном.
Спецификация предлагает достаточно простой способ идентификации: в заголовки первичного и повторных запросов по операции, необходимо добавить пару ключ-значение, где ключ — имя заголовка «Idempotency-Key», а значение — уникальный идентификатор операции в формате UUIDv4. Например: Idempotency-Key: «8e03978e-40d5-43e8-bc93-6894a57f9324». В повторных запросах по операции должен быть тот же ключ идемпотентности, что и в первом запросе по этой же операции.
При поступлении запросов с таким идентификатором становится возможным проверять не была ли операция выполнена ранее, не выполняется ли она по другому запросу прямо сейчас, не подменили ли содержимое повторного запроса по сравнению с первым запросом.
Гонка запросов в реальной эксплуатации
На проверке, не выполняется ли прямо сейчас та самая операция, по который поступил еще один запрос, хотелось бы остановиться чуть подробнее и пояснить, почему такая проверка тоже важна — она имеет отношение к гонке запросов, которая также возможна в условиях реальной эксплуатации, как и остальные ошибки.
С гонкой запросов мы столкнулись только во время опытно-промышленной эксплуатации. Выявить её и локализовать удалось только после внедрения механизма проверки идемпотентности — во время наблюдения по логам за его работой. До внедрения механизма мы и не подозревали о наличии таких ситуаций.
Как это происходило? В какой-то момент из-за ошибки на стороне сайта к нам начали поступать повторные запросы, которые отправлялись еще до получения ответа по первому запросу. Это может приводить к дублированию объектов в системе и другим побочным эффектам, в том числе, к неоправданной повышенной нагрузке на сервер.
То есть, в то время, когда обрабатывается заявка по первому запросу, поступает повторный запрос по той же заявке, и так как по первому запросу заявка еще не создана, повторному запросу ничто не мешает начать создавать такую же заявку параллельно. Такая же ситуация может возникнуть независимо от возникновения превышения таймаута на веб-сервере по первичному запросу.
Описываемый механизм предлагает методы обнаружения и блокирования подобных повторных запросов, о которых более подробно расскажем чуть ниже.
Где следует контролировать идемпотентность?
Важный вопрос, на который также стоит обратить внимание при проектировании и разработке механизма — какое наиболее оптимальное место для размещения точки входа в него?
Ответ звучит примерно так: чтобы максимально изолировать механизм проверки от бизнес-логики, нужно разместить его между точкой получения запросов от клиента и точкой начала выполнения бизнес-логики по обработке этих запросов. Назовем этот слой «Контроллером идемпотентности».
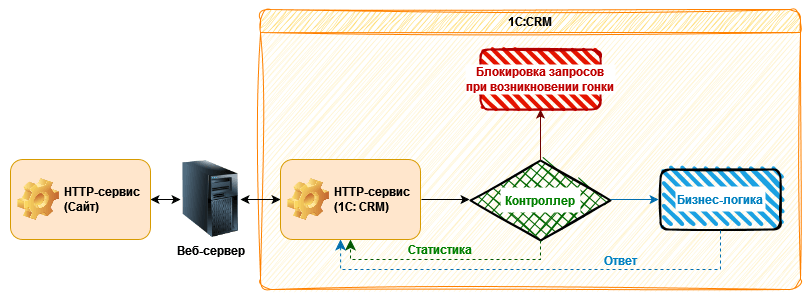
Почему расположение контроллера в указанном месте будет наиболее оптимальным? С одной стороны он максимально близко к инфраструктурной составляющей сервиса, то есть работает с сырыми данными запроса на входе. С другой стороны — он не зависит от бизнес-функциональности и ничего не знает о ней. Он лишь принимает решение пустить запрос в работу на уровень бизнес-логики или обработать его внутри своего контура.
Такой подход позволяет сделать механизм гибким, универсальным и использовать его одинаково для всех сервисов в системе при условии определенной унификации их реализации на инфраструктурном уровне. О какой унификации идет речь: запросы всех сервисов должны использовать единые методы общих модулей для разбора входящих запросов, их параметров, формирования и отправки ответов на запросы. Опять же, стоит еще раз упомянуть о том, что эти методы также должны быть отделены от бизнес-логики.
Реализация механизма проверки идемпотентности в 1С
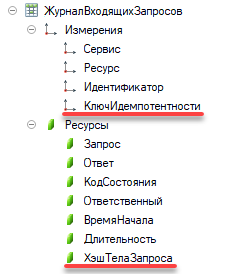
Переходим к описанию технической реализации этого механизма в конфигурации 1С в соответствии с приведенной спецификацией. На проекте используется доработанная конфигурация 1С:CRM 3.0 от «1С‑Рарус». На момент принятия решения о внедрении механизма в конфигурации для логирования входящих запросов уже используется нетиповой регистр сведений — назовем его условно «Журнал входящих запросов».
Его структура позволяет хранить и анализировать информацию о дате поступления запроса, о сервисе на который поступил запрос, о запрашиваемом ресурсе, о заголовках, параметрах и теле запроса. Также в нем фиксируется статус обработки запроса, длительность его обработки и параметры ответа клиенту: заголовки и тело ответа.
С командой сайта мы договорились о том, чтобы они добавили в исходящие запросы с POST-методом заголовок «Idempotency-Key».
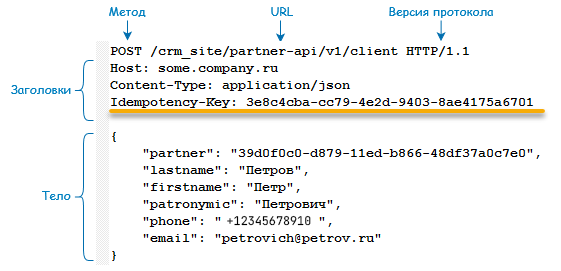
Для учета этого уникального идентификатора добавлено новое измерение «КлючИдемпотентности» в регистр «Журнал входящих запросов». С его помощью будет возможность запросом 1С получить информацию по всем запросам интересующей нас операции при разборе каких-то спорных ситуаций или для аналитики.
Также необходимо рассчитывать хэш тела каждого входящего запроса и хранить его в этом же регистре. Добавили новый ресурс с названием «ХэшТелаЗапроса», значение для которого рассчитываем на лету с помощью типового метода БСП ОбщегоНазначения.КонтрольнаяСуммаСтрокой(ТелоЗапроса).
Хэш используется как дополнительный «отпечаток» тела запроса, по которому сверяем тело повторных запросов с телом первичного запроса, чтобы убедиться в неизменности содержимого (полезной нагрузки) — повторного запроса.
Для возможности оперативного управления механизмом проверки идемпотентности добавили новую функциональную опцию «Используется проверка идемпотентности запросов» и вынесли ее на форму панели администрирования. В дальнейшем все небезопасные POST-методы входящих запросов по всем сервисам конфигурации можно будет подключить к нашему механизму с привязкой к этой функциональной опции.
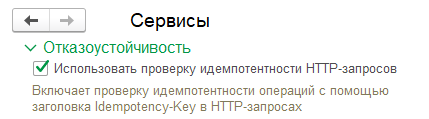
Если будет нужна большая гибкость в управлении, то можно сразу или в дальнейшем выделить отдельный регистр с настройками проверок идемпотентности для каждого сервиса в отдельности.
Ниже привожу пример подключения метода HTTP-запроса к проверке в программном коде 1С.
В контексте обработчика POST-метода устанавливаем значение булевого признака «Проверить выполнение запроса» в зависимости от состояния функциональной опции. Далее этот признак анализируется в методе «Обработать параметры запроса» общего модуля «HttpСервисы», где и происходят все проверки идемпотентности описанные в спецификации, если значение этого признака = Истина.
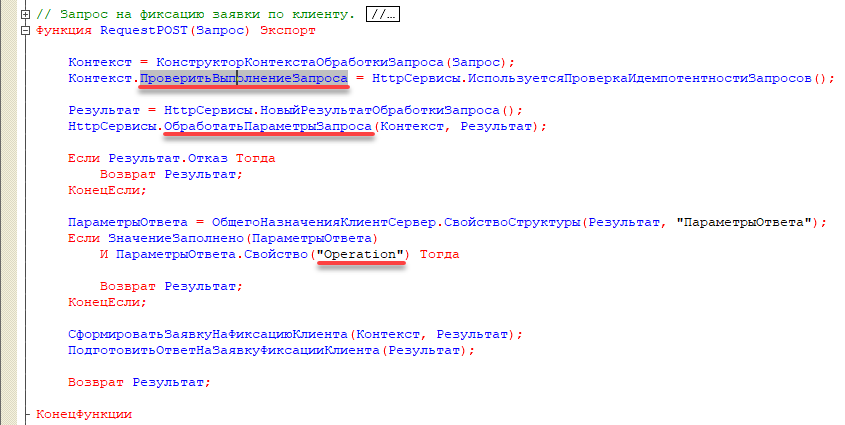
Теперь о том, какие проверки предусмотрены спецификацией и нашим механизмом.
Доступно 4 кейса, по которым выполняется проверка различных условий для входящих запросов. На основании проверок принимается решение о том, допускать ли запрос к обработке системой, отклонить его с указанием причины, или отправить в ответ на него статистическую информацию о выполняемой операции.
Первая проверка
Выполняется сразу при поступлении запроса до выполнения каких-либо действий по нему. Она смотрит на заполнение ключа идемпотентности в заголовке входящего запроса. Если ключ отсутствует или его значение не заполнено, или это значение не является строкой в формате UUIDv4, такой запрос отклоняется с кодом ошибки 400 Bad Request, а в теле ответа на входящий запрос приводится описание ошибки.

Вторая проверка
Проверяет не является ли поступивший по уникальной операции запрос повторным, и если он является повторным, то закончилась ли обработка первичного запроса и с каким результатом она закончилась. По ключу идемпотентности из заголовка повторного запроса и остальным измерениям выполняется поиск первичного запроса в регистре «Журнал входящих запросов» с датой регистрации запроса меньше даты регистрации текущего запроса.
Если первичный запрос зарегистрирован в журнале, операция по нему выполнена успешно с кодом 200 ОК и есть подготовленный ответ по ней, сравним хэши тел запросов (повторного и первичного).
Если ключи идемпотентности и хэши тел запросов совпадают, считаем эти запросы идентичными и по повторному запросу у нас не будет еще раз создаваться заявка. Состояние системы не меняется. Однако и отклонять такой запрос с ошибкой мы тоже не будем. Так как по первому запросу операции у нас в журнале уже есть готовый ответ, извлечем его из журнала и запишем в ответ на повторный запрос.
В конец тела ответа также добавим объект Operation c описанием параметров успешно выполненной операции (ключ уникальности операции и дата регистрации первичного запроса). Подготовленный ответ отправляем вызывающей стороне.
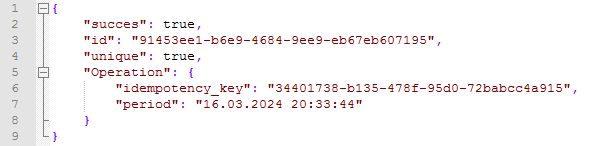
Если первичный успешный запрос не обнаружен, тогда будет выполнена попытка создать новую заявку — считаем такой запрос первичным.
Объект Operation не добавляется в тело ответа на первичный запрос. Он нужен только для повторного запроса, чтобы обозначить, что операция по такому же запросу уже была успешно выполнена ранее и текущий запрос не изменил состояние системы.
Таким образом решаем проблему согласованности и целостности данных между сайтом и CRM. Теперь при потере пакетов ответа в сети при срабатывании таймаутов сайт всегда, пока в CRM хранится запись в журнале входящих запросов, может отправить повторный запрос по интересующей его уникальной операции и получить адекватный и актуальный ответ. При этом исключается риск создания дублей объектов системы. В нашем случае исключается возможность создания лишних неуникальных заявок на фиксацию клиентов.
Третья проверка
Является логическим продолжением предыдущей проверки и выполняет контроль повторных запросов на предмет изменения «полезной нагрузки» относительно первичного запроса. В случае поступления повторного запроса, у которого Idempotency-Key совпадает с Idempotency-Key первичного успешно обработанного запроса, но хэши тел этих запросов отличаются, выдаем ответ с кодом 422 Unprocessable Entity (Необрабатываемый объект).
Такая ситуация может возникнуть, если сайт попытается использовать один и тот же ключ идемпотентности в запросах на создание разных по своему содержанию заявок. Воспринимаем это как попытку выполнить разные операции с одним и тем же идентификатором. Такой запрос будет отвергнут, состояние системы останется без изменений.

Четвертая проверка
Теперь открытым остается только вопрос реагирования на возможные ситуации с «гонкой запросов», когда начинается конкуренция нескольких входящих запросов по одной операции между собой. Решить его нам поможет четвертая проверка, которая в ходе реализации выросла в отдельный блок механизма.
Для возможности оперативного управления этой проверкой добавляем в конфигурацию еще одну новую функциональную опцию «Использовать проверку HTTP‑запросов на конфликты» и выносим ее на форму панели администрирования сервисов. Так как она подчинена предыдущей функциональной опции и зависит от неё, разместим ее на соответствующем уровне иерархии настроек.
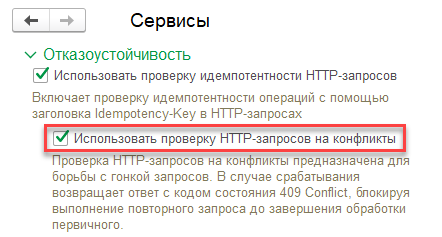
В случае поступления повторного запроса в то время, как первичный или предыдущий повторный запрос с тем же Idempotency-Key еще находится в обработке (то есть запрос зарегистрирован в журнале входящих запросов, но по нему еще нет ответа и не установлен код состояния), выдается ответ с кодом ошибки 409 Conflict.
| Период | Ресурс | Запрос | Ответ | Код состояния |
|---|---|---|---|---|
| 16:55:17 | /v1/request | <Тело запроса и его параметры> | ... | ... |
| 16:55:18 | /v1/request | <Тело запроса и его параметры> | Код состояния: 409. Причина Conflict... | 409 |
| 16:55:19 | /v1/request | <Тело запроса и его параметры> | Код состояния: 409. Причина Conflict... | 409 |
В теле ответа указываем причину конфликта. Выполнение обработки запроса блокируется, состояние системы не изменяется.

В такой ситуации следующим повторным запросам, чтобы постоянно не получать ошибку с кодом 409 Conflict, нужно дождаться одного из перечисленных ниже вариантов разрешения конфликта:
- Нормального завершения обработки предыдущего запроса, если он действительно еще до сих пор выполняется.
- Если предыдущий запрос из-за сбоя не может быть никогда полностью обработан (т. е. не может получить код состояния и сформировать ответ), дождаться пока такая запись из регистра журнала входящих запросов будет удалена вручную.
- Автоматической разблокировки запроса регламентным заданием согласно настройкам.
Появление конфликтов, которые нужно принудительно разблокировать — это скорее исключительная ситуация, которая возникает в результате какого-то серьезного, чаще внутреннего сбоя нашей системы или инфраструктуры. Таких, например, как:
- Обрыв соединения сервера приложений с СУБД во время обработки первичного запроса.
- Ошибка компиляции модуля системы из-за ошибки в метаданных или в коде модулей, которая может помешать успешной обработке запроса напрямую или косвенно.
- Аварийное завершение процесса сервера и т. д.
Возможность автоматической разблокировки конфликтного запроса появилась не сразу и не описана в спецификации. В процессе эксплуатации, когда проверка на конфликты стала срабатывать, стало понятно, что вручную разблокировать на постоянной основе очень неудобно, так как требует участия специалиста, знакомого с этим механизмом, который выяснит причины блокировки и знает, каким образом можно разблокировать заблокированный запрос. Однако за время, которое может потребоваться на разбор причины и её устранение лимит на количество повторных запросов со стороны сайта может быть исчерпан, а нужная операция так и не будет выполнена. Так появилась необходимость в дальнейшем развитии механизма и было принято решение разработать регламентное задание «Разблокировка конфликтных HTTP‑запросов».
Регламентное задание «Разблокировка конфликтных HTTP‑запросов»
С одной стороны, конфликт может быть вызван серьезной системной ошибкой, в том числе и не связанной непосредственно с HTTP-сервисом, до устранения которой нет смысла разблокировать запросы. Почему не имеет смысла? Потому что с большой вероятностью блокировка запросов будет массовой и количество заблокированных запросов будет только расти, ведь система не сможет их корректно обработать. Поэтому без участия специалиста здесь не обойтись, так как системную ошибку нужно локализовать и устранить.
С другой стороны, конфликты могут быть вызваны временным всплеском нагрузки на ресурсы сервера, с которой он не может эффективно справится какое-то время. Например, запустились какие-то тяжелые регламентные задания. Такая нагрузка, не связанная напрямую с нашим сервисом, может спровоцировать значительное увеличение времени на обработку входящих запросов. Веб-сервер начинает в ответ на них отвечать ошибкой 504 Gateway Timeout, сайт реагирует на это отправкой повторных запросов, такие запросы тоже блокируются. Так происходит до тех пор пока сервер 1С не обработает первичные запросы и не начнет в ответ на повторные запросы отдавать корректные ответы об уже завершенных и успешно выполненных операциях.
В обоих случаях можно, исходя из определенной статистики, поручить автоматическое разблокирование конфликтных запросов регламентному заданию. Так как ранее уже приходилось выполнять разблокирование конфликтных запросов вручную, у нас было понимание причин, по которым чаще всего это происходит и по какому алгоритму можно выстроить автоматическое разблокирование.
В качестве статистических параметров для настройки регламентного задания мы использовали следующие метрики:
- Повторов до автоматической разблокировки. Количество заблокированных повторных запросов при достижении которого выполняется их автоматическое разблокирование путем удаления блокирующей записи первичного запроса из журнала входящих запросов.
- Порог разблокировки конфликтных HTTP‑запросов. Количество заблокированных уникальных первичных запросов с момента последнего выполнения регламентного задания. Значение при достижении которого разблокирование временно приостанавливается до момента восстановления допустимого значения. Допустимым считается значение меньше установленного.
- Период проверки достижения порога разблокировки конфликтных HTTP‑запросов. Интервал времени в минутах, за который вычисляется количество заблокированных запросов и выполняется контроль достижения порога разблокировки. Рекомендуется устанавливать здесь значение не меньше, чем интервал выполнения регламентного задания в соответствии с настройками его расписания. Можно устанавливать большее значение.
Так как это параметры, которые могут периодически изменяться, особенно в период подбора наиболее эффективной их комбинации под конкретную ситуацию, их оформили в виде отдельных констант и вынесли на форму панели администрирования сервисов.

Кроме того, для работы регламентного задания по автоматической разблокировки и для возможности мониторинга заблокированных запросов, которые могут в какой-то момент накапливаться, добавили регистр сведений «Журнал конфликтов HTTP‑запросов», в котором хранится информация о заблокированных в результате конфликта запросах. Запись с данными запроса в него добавляется сразу при обнаружении конфликта.
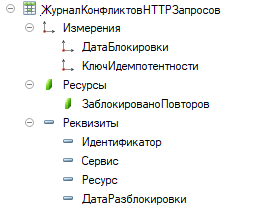
Регламентное задание по расписанию в соответствии с заданными в настройках параметрами проверяет в этом регистре наличие записей с ещё не разблокированными запросами. Затем выполняет разблокирование подходящих по параметрам запросов, удаляя запись заблокированного запроса из журнала входящих запросов. При удалении такой записи из журнала входящих запросов открывается «дорога» для последующих повторных запросов, выполнение которых может привести к успешному выполнению операции, если все препятствия для этого действительно устранены.
Повторный запрос может снова заблокироваться, если с настройкой пороговых значений при настройке регламентного задания не угадали или все еще не устранены другие препятствия для успешной обработки запроса. При следующем выполнении регламентного задания вновь заблокированные запросы снова будут подвергнуты анализу и выполнится попытка разблокировать их еще раз.
Если повторные блокирования происходят часто, значит либо какая-то проблема в системе долго не устраняется, либо можно попробовать подобрать более подходящие под вашу ситуацию параметры разблокировки.
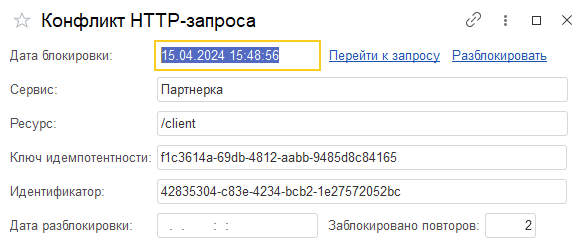
Дополнительно в форме записи регистра заблокированных запросов присутствует возможность перехода к запросу в журнале входящих запросов и его ручного разблокирования. Такая возможность может пригодиться, когда разблокировать запрос нужно раньше, чем это сделает регламентное задание или чтобы посмотреть все детали заблокированного запроса для анализа.
Заключение
Реализация всего блока по выявлению, блокированию и автоматическому разблокированию конфликтных запросов позволила эффективно решить проблему возможного возникновения ситуации с «гонкой запросов» и проявила себя в эксплуатации как надежная защита от «спама» запросами со стороны сайта.
Весь механизм проверки идемпотентности запросов помог решить задачу обеспечения отказоустойчивости сервиса в целом, сделать небезопасные методы HTTP‑запросов относительно «безопасными» и управляемыми. С помощью ключа идемпотентности в заголовках запросов стало гораздо проще читать логи журнала входящих запросов, стало возможным выявлять и устранять проблемы намного раньше, чем это станет проблемой для бизнеса.
Описанный механизм является универсальным, может быть реализован и использован в любой конфигурации независимо от области применения. Главное условие для его реализации — это наличие механизма логирования входящих HTTP‑запросов, так как механизм проверки идемпотентности использует журнал входящих запросов в качестве основного источника данных для принятия решения.
Если логирование не настроено, то необходимо будет предварительно его разработать. При этом важно, чтобы такой механизм фиксировал тело входящего запроса и его остальные параметры в журнале сразу при его поступлении, а не после полной обработки запроса и формирования ответа.
Подобные механизмы используются крупными электронными площадками и сервисами самой разной направленности: e‑commerce, облачные сервис-провайдеры, банкинг, CMS — API Yandex Cloud, PayPal, Django, Open Banking и многие другие. Более подробный, но далеко не полный перечень приведен в спецификации.
От экспертов «1С-Рарус»

















