


Оглавление
- Введение
- Использование постоянно подключенной системы мониторинга вместо эпизодического анализа
- Типовой набор эксперта при расследовании задач производительности
- Серверные вызовы по времени
- Серверные вызовы по контексту
- Запросы (PostgreSQL и MS SQL) по времени
- Запросы (PostgreSQL и MS SQL) по текстам запросов
- Клиент-серверные вызовы
- Отвечаем на вопрос, какой код вызывает нагрузку, но не попал в логи
- Серверные вызовы по потреблению памяти и процессора
- Взаимоблокировки и таймауты
- Расследование взаимоблокировки
- Расследования таймаутов и взаимоблокировок в классической экспертизе
- Использование сторонних систем визуализации данных совместно с «1С-Рарус: Мониторинг производительности»
- Выводы
Введение
В данной серии статей мы хотим порассуждать на тему удобных инструментов для анализа и мониторинга проблем производительности на крупных проектах в целом, а не о конкретном случае расследования таких проблем.
В нашей команде экспертов производительности 1С мы использовали разные инструменты, а также классический подход через парсинг лога ТЖ посредством bash scripts, пока не решили написать свой собственный. Сегодня мы покажем вам жизненный цикл анализа проблем в системе при помощи продукта «1С-Рарус: Мониторинг производительности», а также сравним предлагаемые нами подходы с классическими подходами, которые приняты и имеют, можно сказать, статус золотого стандарта де-факто в экспертной среде у коллег.
Использование постоянно подключенной системы мониторинга вместо эпизодического анализа
Жизненный цикл экспертного расследования при использовании какой-либо постоянно подключенной системы мониторинга отличается от случая, когда постоянного мониторинга нет. В нашей практике чаще всего происходит так, что эксперт подключается на проект ситуационно. И казалось бы, зачем в таком случае нам постоянно мониторить информационную базу 1С и сопутствующие показатели? Но дело именно в сокращении цикла расследования.
В момент, когда возникают жалобы от пользователей, важно не тратить время на повторное воспроизведение проблемы, а сразу приступить к ее расследованию.
В случае, если сбор логов не производится на постоянной основе, мы не можем сразу же приступить к анализу и цикл экспертного расследования будет достаточно большим:
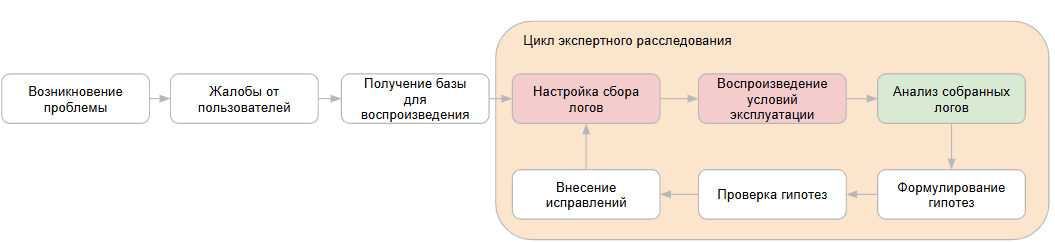
Если же мы уже имеем настроенную систему мониторинга, то цикл расследования исключает настройку сбора логов и повторное воспроизведение. Это значительно ускоряет процесс и позволяет не заниматься рутинными действиями, а сразу переходить к анализу собранных данных:
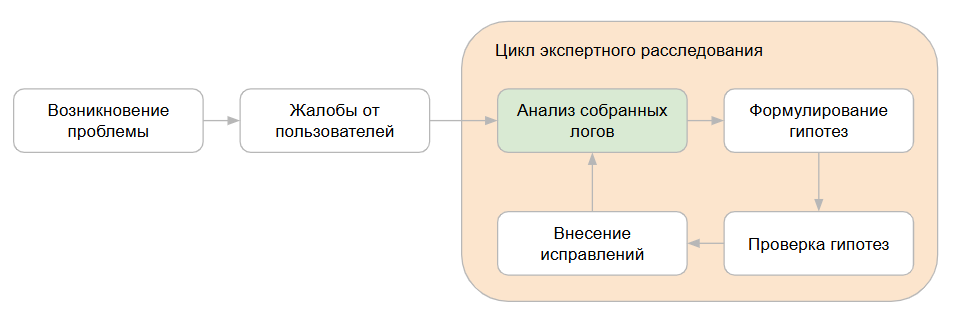
Безусловно, можно настроить сбор логов технологического журнала 1С, счетчиков оборудования, показателей СУБД без дополнительных внешних инструментов для анализа. Однако, для полноценного анализа должны обеспечиваться:
- Полнота сбора информации. В частности, в случае со сбором логов технологического журнала 1С мы должны исходить из сбора всех основных событий лога, которые могут нам понадобиться для анализа длительных клиент-серверных вызовов, длительных запросов, превышения времени ожидания блокировок и т. д.
- Глубина сбора информации. Объем логов должен быть достаточным, чтобы иметь возможность произвести ретроспективный анализ за определенный промежуток времени. По нашему опыту, может понадобиться информация, как минимум, за последние несколько дней, но может быть и больше.
Эти два условия в случае, например, со сбором логов технологического журнала 1С на больших проектах могут потребовать для хранения такого объема логов практически неограниченного объема дискового пространства, так как собираться будут буквально терабайты текстовой информации.
Поэтому здесь стоит задуматься также о необходимости более компактного хранения собранной информации, нежели в сыром виде, так как ее собирает платформа 1С. Эта задача решена в «1С-Рарус: Мониторинг производительности», в частности, при помощи использования аналитических СУБД для хранения данных. Одно из преимуществ таких СУБД в сжатии исходного сырого массива данных, причем порядково. Далее мы эти цифры продемонстрируем.
Конечно, для того, чтобы хранить данные в табличном виде, необходимо в этот самый табличный вид их сперва конвертировать. Это еще одна задача, которая решена в «1С-Рарус: Мониторинг производительности», при помощи математики преобразования исходных сырых логов в формат, который может быть с легкостью загружен в аналитическую СУБД.
Как устроен цикл сбора и накопления логов в 1С-Рарус: Мониторинг производительности
Рассмотрим общую схему функционирования системы «1С-Рарус: Мониторинг производительности»:
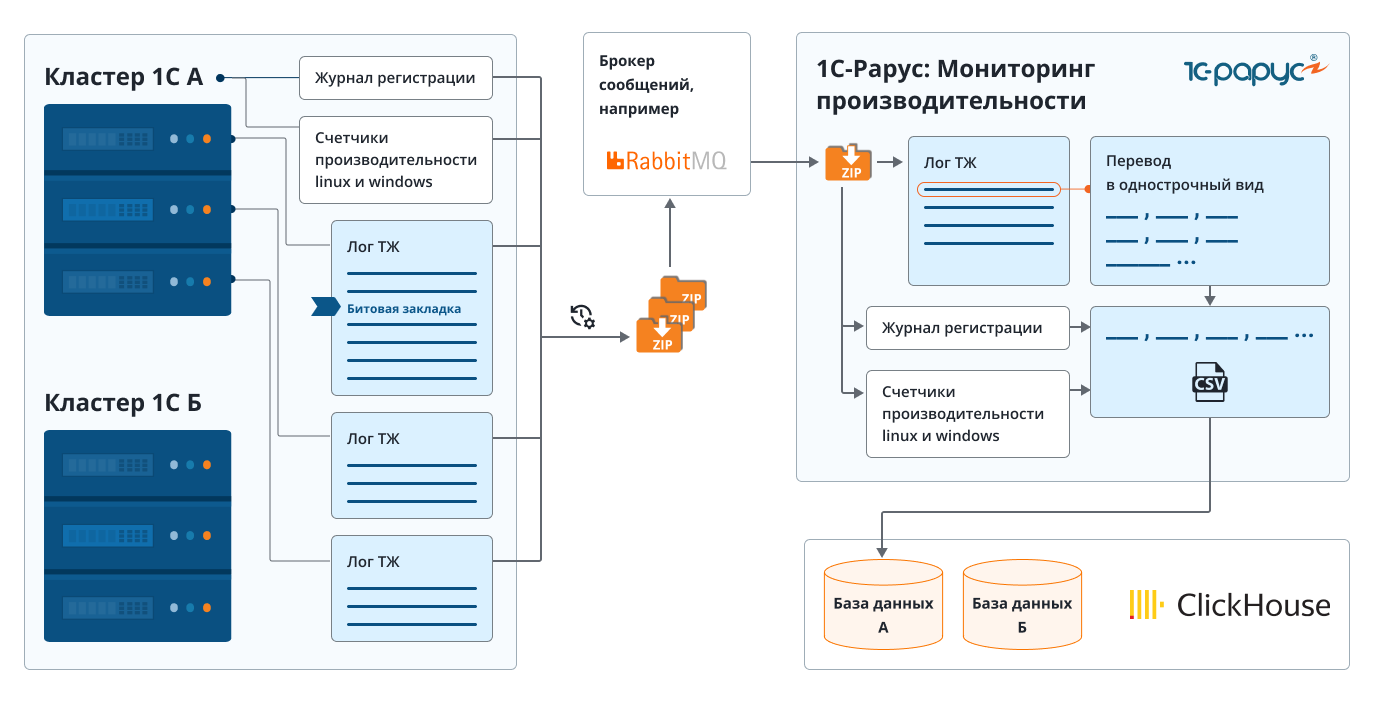
Собирать логи мы можем с нескольких серверов кластера 1С, а также сервера СУБД одновременно. На каждом из серверов необходимо запустить по расписанию специальный скрипт на языке python, который будет забирать новые накопившиеся логи технологического журнала 1С, либо журнала регистрации выбранной информационной базы, либо счетчики оборудования, архивировать их и отправлять в брокер сообщений.
Далее на стороне мониторинга производительности логи забираются из брокера, разархивируются и преобразуются в табличный вид. После преобразования данные отправляются в источник хранения — колоночную аналитическую СУБД ClickHouse.
Как собираются данные логов (чтобы это было быстро)
Так как сырые данные логов пишутся постоянно и непрерывно, то нам необходимо обеспечить как можно меньшую задержку от момента возникновения новой текстовой информации, до момента ее отображения и возможности анализа в базе мониторинга. В частности, логи технологического журнала 1С пишутся в разные файлы с ротацией в 1 час. Скрипт отправки новых данных при этом запускается гораздо чаще, а значит нам необходимо обеспечить дозагрузку данных из одного и того же файла, чтобы в мониторинг каждый раз попадали только новые накопившиеся логи.
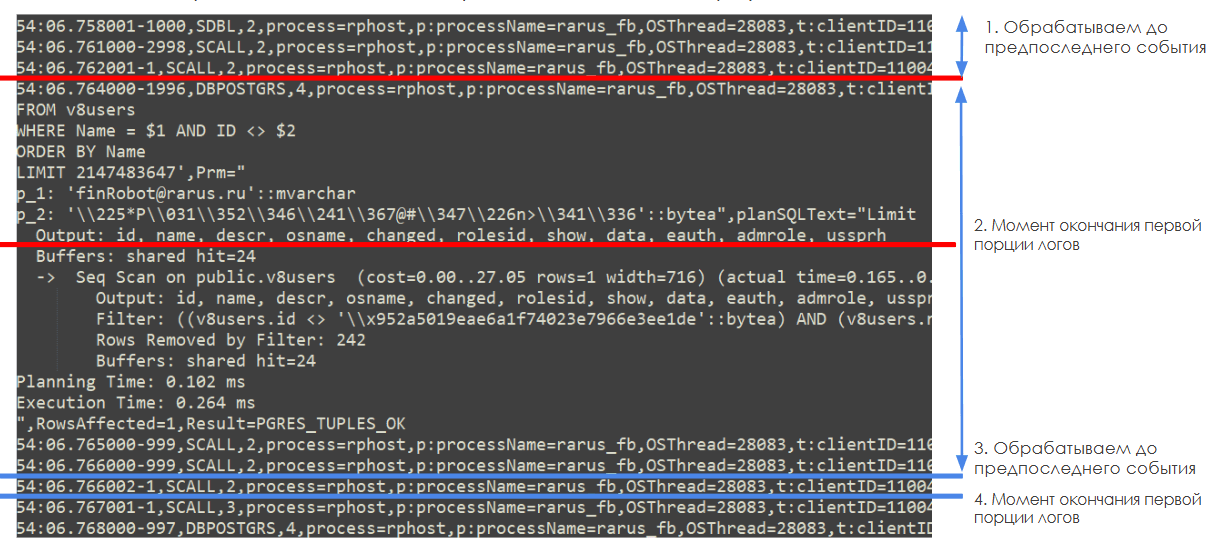
Для ее решения мы использовали идею битовой закладки. Когда мы в течение часа несколько раз читаем один и тот же файл лога, мы создаем битовую закладку, которая указывает, где закончилось предыдущее чтение файла лога и где начать следующее.
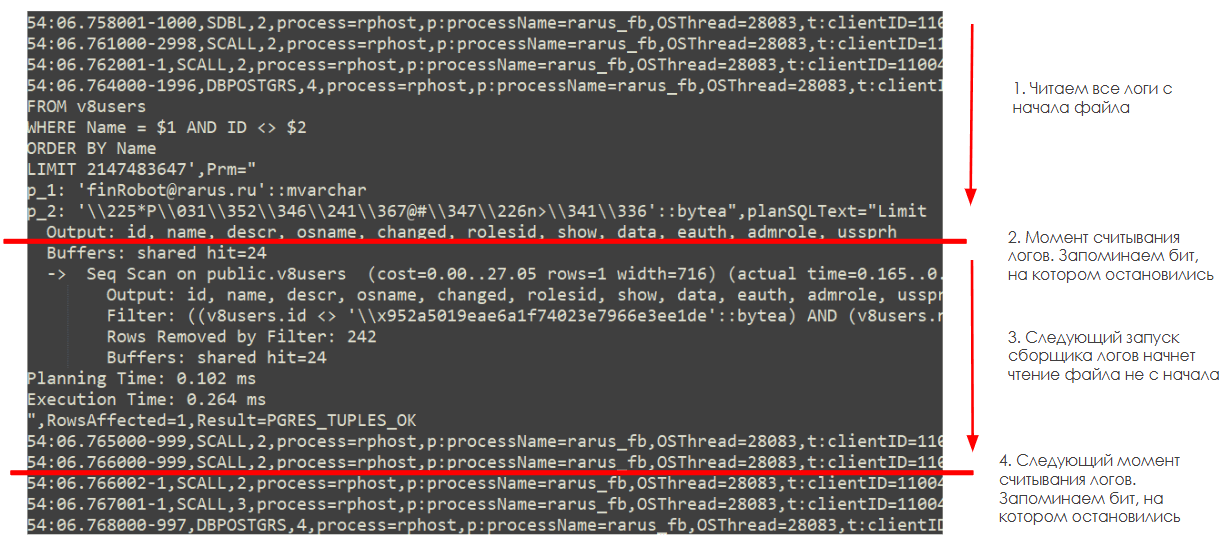
При этом стоит обратить внимание, что в момент считывания логов мы не всегда начинаем с начала нового события логов технологического журнала 1С. Иногда платформа может находиться в этот момент в процессе записи какого-то большого события лога (например с текстом запроса) и мы дочитаем файл только до середины события. Поэтому при обработке логов, чтобы получить гарантированно всю информацию по событию, логи обрабатываются до предпоследнего события включительно.
Последнее же событие будет обработано в момент следующего запуска обработки логов, когда в новой порции данных, пришедшей с сервера, мы сможем считать возможную недостающую часть этого события.
Что касается скорости обработки данных логов. Самыми большими по объему собранной информации чаще всего являются логи технологического журнала 1С. Для обработки больших объемов текстовой информации мы применяем специальные скрипты, написанные на языке python. Python отлично подходит для обработки текстовой информации и в нашей конкретной задаче, которая состояла в преобразовании исходных файлов логов в табличный вид, обходит по скорости работы не только 1С, но и некоторые компилируемые языки программирования. Более подробные результаты замеров и сравнение мы покажем во второй части статьи.
Типовой набор эксперта при расследовании задач производительности
Итак, когда мы разобрались в необходимости постоянного сбора логов для возможности быстрого анализа проблем производительности в системе, остановимся подробней непосредственно на том, как улучшить процесс анализа, сделать его быстрее и эффективнее.
На наш взгляд, важно предоставить эксперту по производительности некоторые базовые настройки инструментов для экспресс анализа «из коробки», а также богатый набор возможностей для настройки инструментов «под себя» для отслеживания и анализа более специфичных частных случаев.
Под экспресс-анализом мы здесь будем иметь в виду быстрый взгляд на наличие узких мест в системе на стороне кластера серверов 1С и сервера СУБД. К таким узким местам можно отнести:
- неоптимальные запросы;
- неоптимальный код;
- загрузка процессора кластером 1С;
- ожидания на блокировках;
- утечки памяти;
- чрезмерное обращение к дисковой подсистеме.
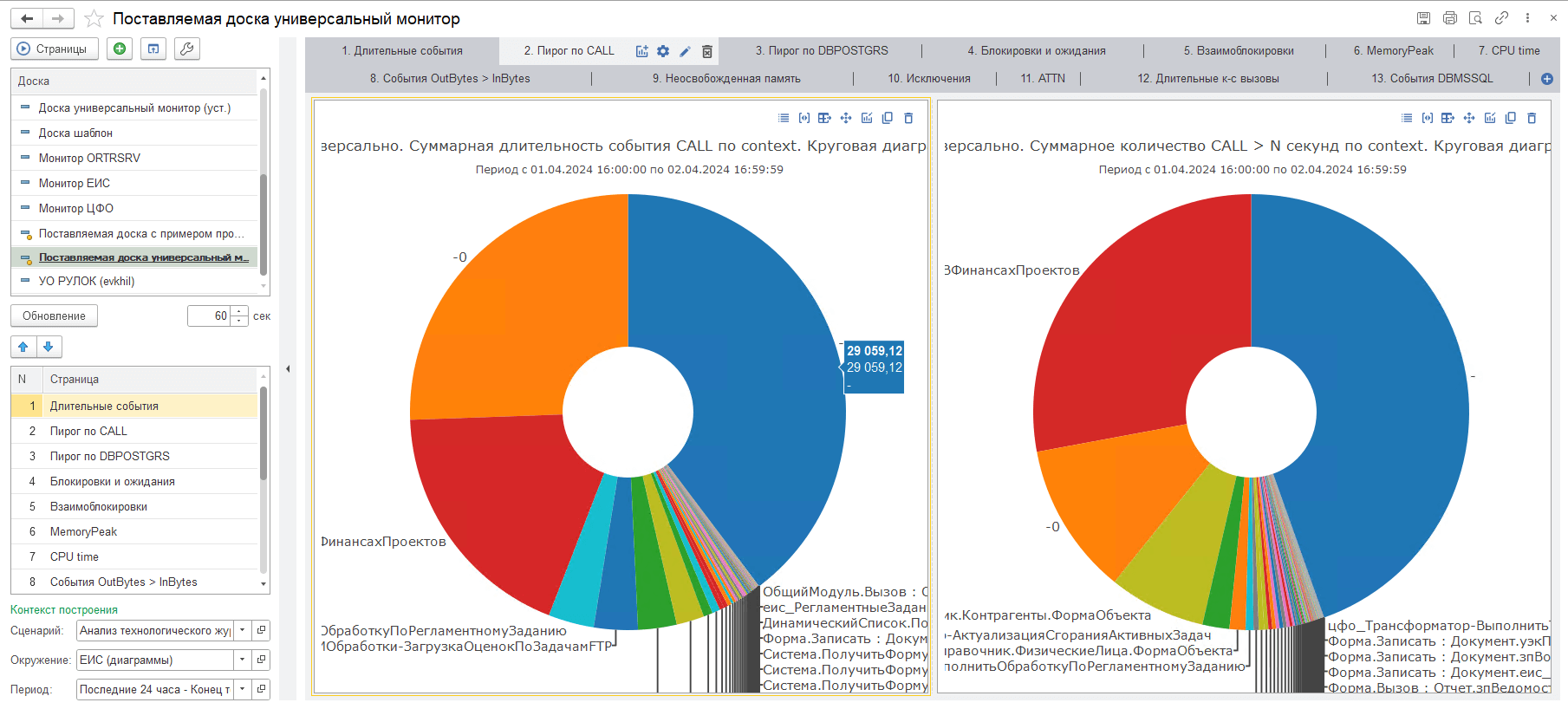
Для ускорения анализа в «1С-Рарус: Мониторинг производительности» мы используем отображение данных при помощи подсистемы диаграмм. Диаграммная система позволяет настроить доски и смотреть данные в виде диаграмм в режиме реального времени.
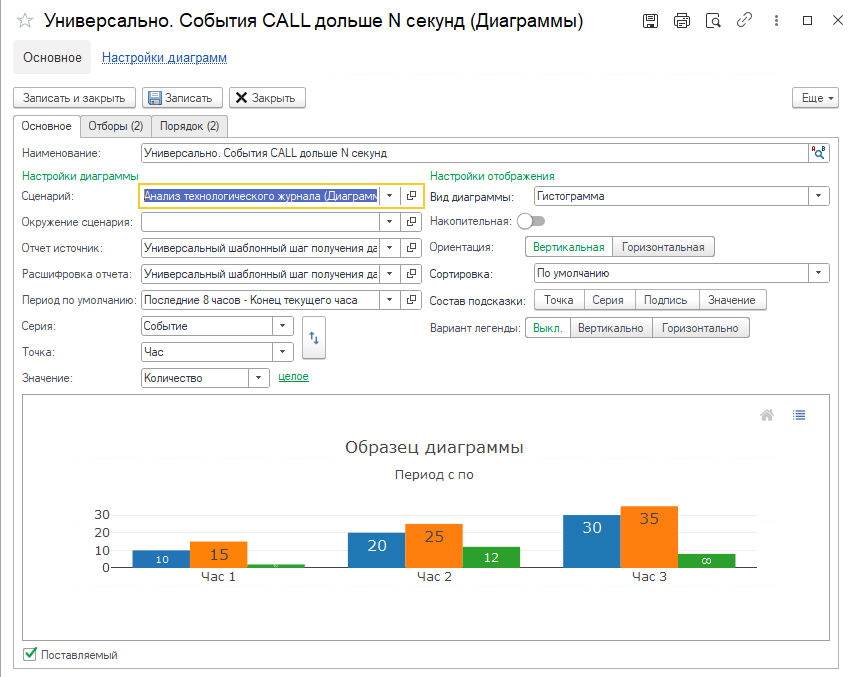
Каждая диаграмма на доске имеет собственные настройки, где мы можем задать:
- Окружение клиентского сценария, в котором находятся параметры диаграммы, характеризующие контекст для получения данных.
- Период, за которые мы получаем данные.
- Вид диаграммы.
- Имена колонок, которые будут являться точками и сериями в результирующем наборе данных, который вернет шаг алгоритма.
- Отборы, которые будут установлены при получении данных для диаграммы.
- Порядок вывода данных при получении данных для расшифровки, которую мы получим при двойном нажатии на колонку диаграммы.
Также, дополнительно мы можем изменить параметры:
- Отчет источник. Это ссылка на специальный справочник «Шаги сценария». Она содержит алгоритм, который будет выполнен для получения данных для построения диаграммы.
- Расшифровка отчета. Это также ссылка на специальный справочник «Шаги сценария». Она содержит алгоритм, который будет выполнен для получения данных расшифровки, которую мы получим при двойном нажатии на колонку диаграммы.
По умолчанию, в «1С-Рарус: Мониторинг производительности» уже предоставляется набор шагов, которые необходимы для получения данных для диаграмм, получения данных расшифровки диаграмм, а также специальные функции для обработки строк данных из расшифровки диаграмм. Это позволяет покрыть основные потребности эксперта, но ничего не мешает ему писать собственные шаги для получения данных и обработки расшифровки, реализующие специфические алгоритмы, не входящие в состав «1С-Рарус: Мониторинг производительности». Более подробно о написании собственных шагов с произвольным алгоритмом мы расскажем вам в рамках второй части статьи.
В составе дистрибутива решения мы предоставляем предопределенный набор досок диаграмм для того, чтобы иметь возможность выводить данные в виде графиков, а также производить детальный анализ вышеописанных возможных узких мест в системе. Среди поставляемых досок стоит выделить следующие:
Поставляемая доска универсальный монитор.
Основная доска эксперта производительности. Содержит 14 вкладок для отслеживания и анализа такой информации, как:
- Длительные серверные вызовы.
- Длительные запросы.
- Ожидания и блокировки.
- Взаимоблокировки.
- Использование памяти серверными вызовами.
- Использование процессора серверными вызовами.
Поставляемая доска с примером произвольного запроса Clickhouse.
На данной доске представлен пример того, как можно настроить собственную диаграмму применив произвольный запрос к аналитической СУБД, в которой хранятся данные логов. Более подробно о данном механизме мы расскажем вам во второй части статьи.
Поставляемая доска по журналу регистрации.
Содержит набор диаграмм, которые строятся на основе данных журнала регистрации, собранного на стороне сервера 1С.
Поставляемая доска счетчики оборудования windows/linux.
Доски содержат набор диаграмм, которые строятся на основе данных счетчиков производительности, поддерживается работа с серверами под управлением Linux и Windows.
Далее мы будем рассматривать диаграммы, входящие в поставляемую доску, а также сравнивать с подходами, которые мы бы использовали, имея на руках только лишь инструменты bash.
По необходимости, также мы будем переходить от общего к частному, применяя к расшифровкам диаграмм специальные функции, которые позволят вывести возможные причины поведения системы в тот или иной момент.
Серверные вызовы по времени
Данная диаграмма позволяет нам ответить на вопрос о распределении нагрузки в зависимости от времени суток:
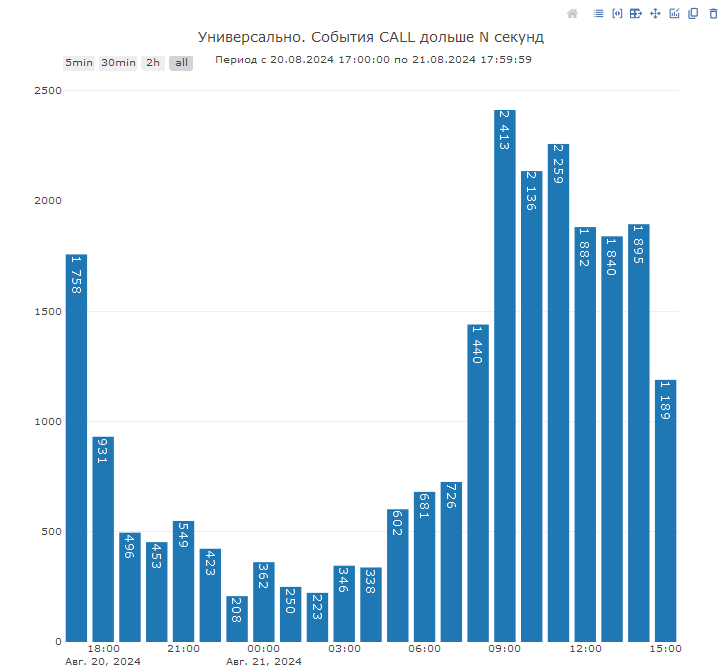
Здесь мы можем видеть количество событий CALL, превысившие определенный порог по длительности, который мы можем настроить в отборах диаграммы, например, дольше 5 секунд.
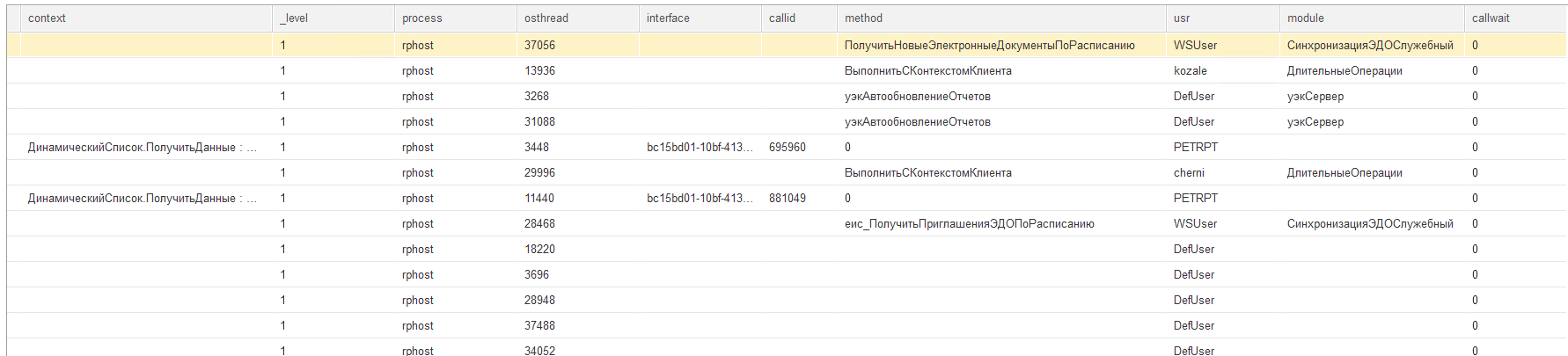
В данных расшифровки мы можем увидеть контекст возникших событий, а также дополнительную информацию:
Как бы мы действовали имея на руках только инструменты bash? Обычно задача состоит в поиске наиболее длительных вызовов, вероятнее всего мы бы воспользовались примерно таким скриптом:
И здесь мы бы вывели самые длительные по времени вызовы, однако, получить такую же статистику как на диаграмме и расшифровке диаграммы, да ещё и с отбором по периоду с помощью скрипта не так-то просто:
Серверные вызовы по контексту
На данной диаграмме мы можем увидеть события CALL сгруппированные по строкам кода, а также количество таких CALL либо их суммарную длительность:
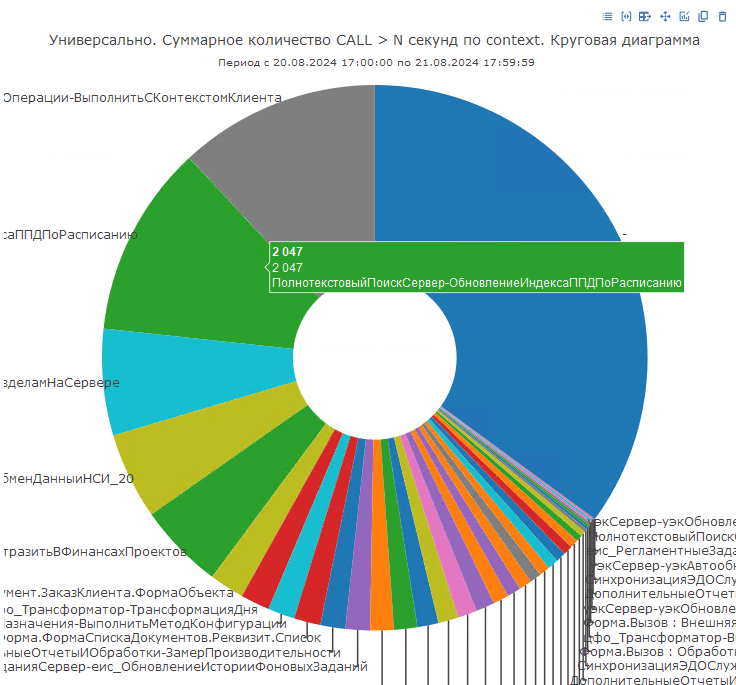
Такое представление данных позволяет нам увидеть не только единичные долгие вызовы, но и если один и тот же единичный вызов выполняется быстро, но в сумме все его выполнения дают значительную цифру по длительности или количеству срабатываний.
Например, так можно отловить мелкие клиент-серверные вызовы в цикле, когда каждый уход на сервер будет занимать время на передачу контекста формы, тогда как можно было бы все эти вызовы объединить в один.
На диаграмме можно даже не переходя в расшифровку уже увидеть контекст событий, которые создают нагрузку.
В случае похожего расследования, но без мониторинга, мы бы воспользовались следующим скриптом:
Данный скрипт также группирует вызовы по контексту и выводит их суммарную/среднюю длительность, а также количество таких событий:

Запросы (PostgreSQL и MS SQL) по времени
Для того, чтобы ответить на вопрос о количестве запросов, которые превысили определенный порог по времени исполнения, можно воспользоваться соответствующей диаграммой. Она отвечает на вопрос, когда была самая большая запросная нагрузка:
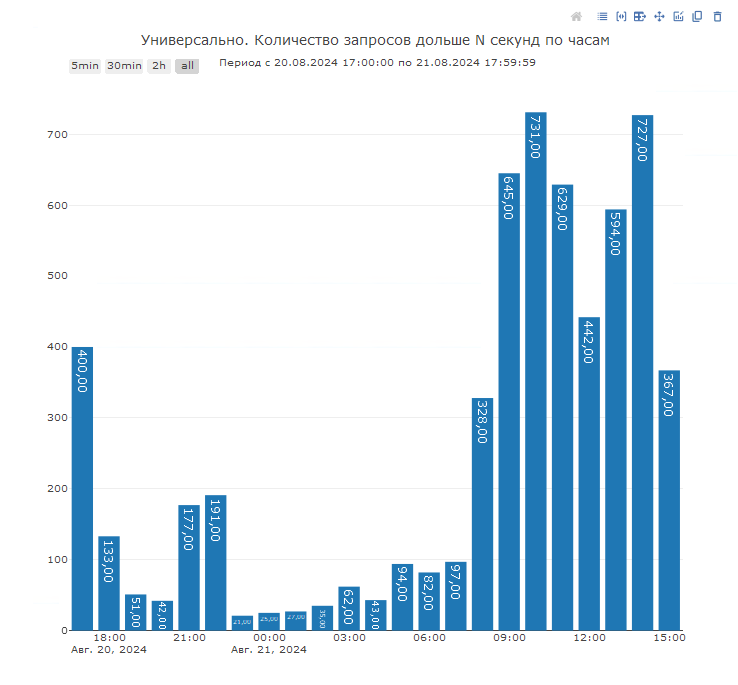
Диаграмму по запросной нагрузке можно и нужно сопоставлять со счетчиками СУБД, например, с Page life expectancy или же с загрузкой процессора или диска на стороне сервера СУБД. Такие диаграммы также предоставляются мониторингом производительности в специальной доске «Поставляемая доска счетчики оборудования»:
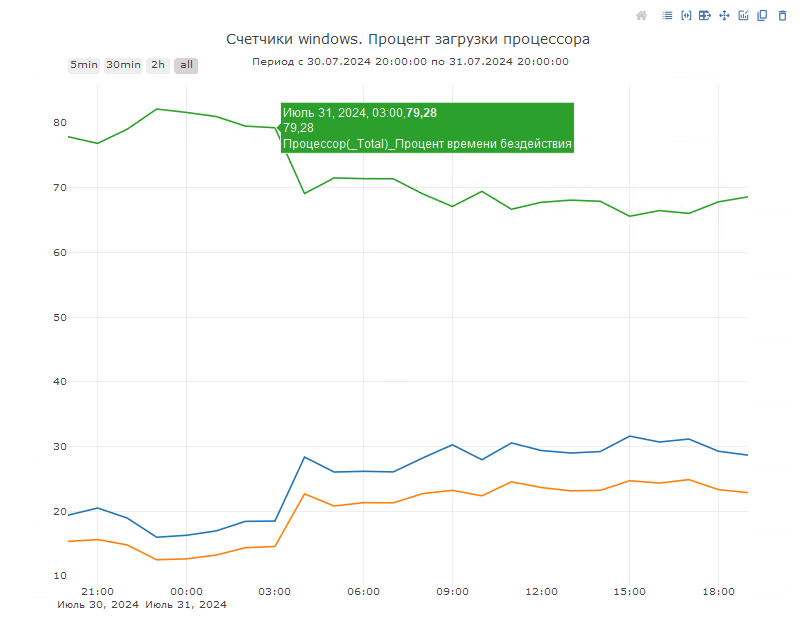
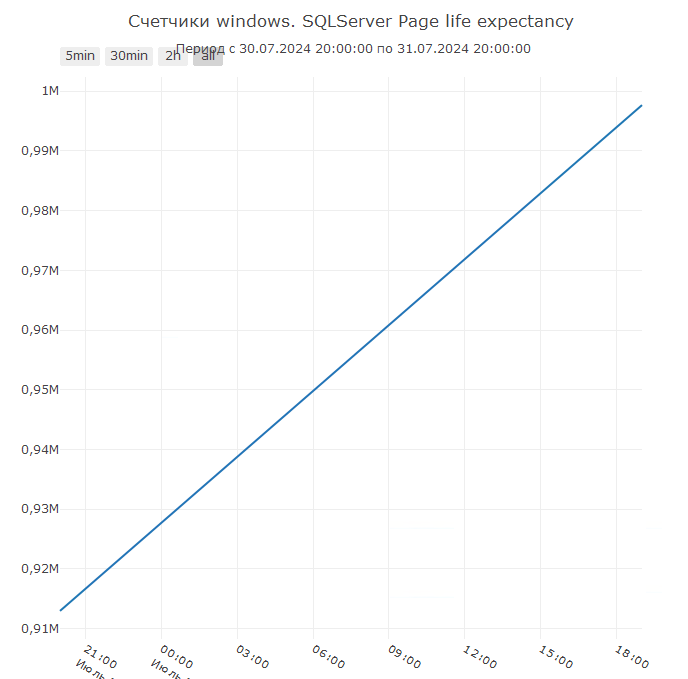
График по Page life expectancy также предоставляется отдельной диаграммой:
В случае использования инструментов bash мы бы воспользовались следующей конструкцией:
Здесь мы получим топ-5 самых длительных событий DBMSSQL в разрезе текста запроса:
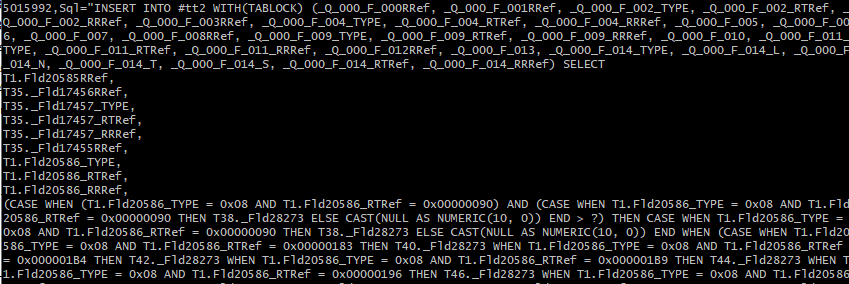
К тексту запроса в мониторинге можно легко перейти из расшифровки любой колонки диаграммы. Для этого необходимо найти колонку sql:
И показать значение в отдельном окне:
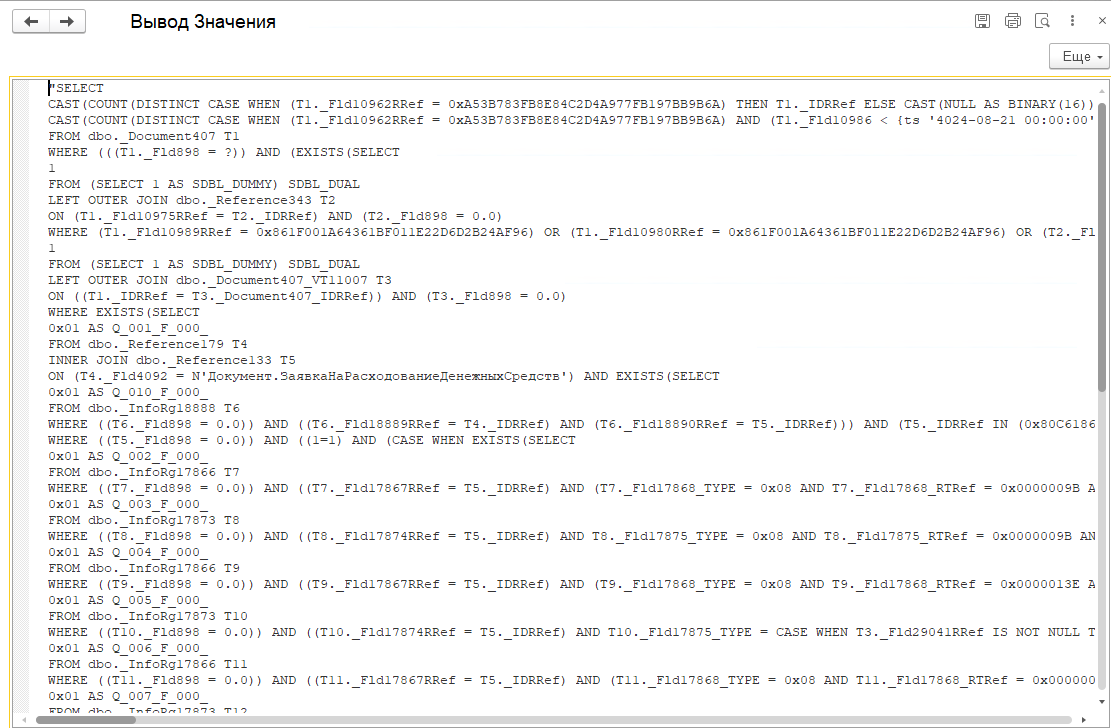
Запросы (PostgreSQL и MS SQL) по текстам запросов
Также, часто возникает необходимость сгруппировать события не по контексту, а по текстам запросов. И в «1С‑Рарус: Мониторинг производительности» есть специальная диаграмма, которая отвечает на вопрос о том, какие запросы или их кумулятивный эффект создает наибольшую запросную нагрузку:
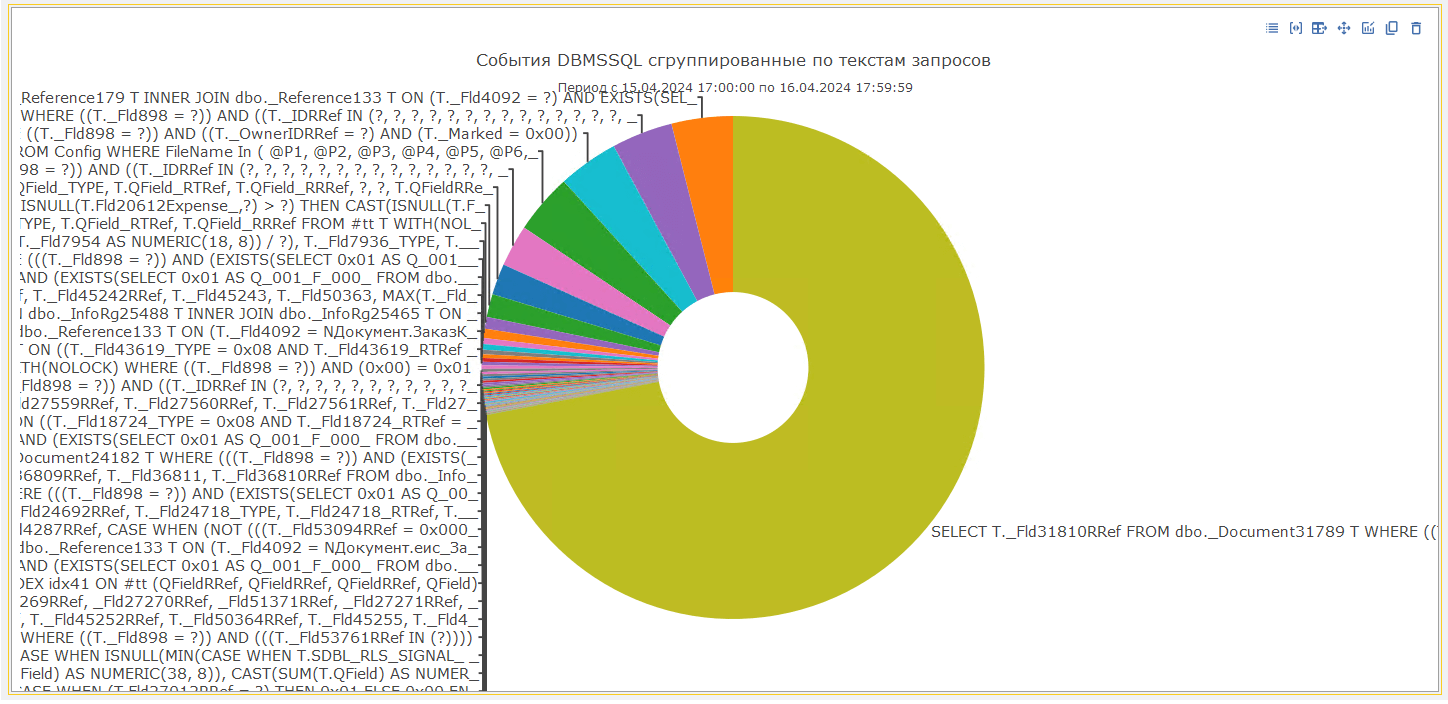
Стоит понимать, что группировка текстов запросов возможна только после их предварительной нормализации. Поэтому в таблицу ClickHouse была добавлена специальная колонка sql_normalized, которая содержит преобразованный текст запроса, по которому возможна группировка.
Говоря простым языком, нормализация — это приведение текстов запросов к единому виду. Под этим понимается удаление имен временных таблиц и параметров запроса, т. к. и те, и другие могут меняться при каждом выполнении одного и того же запроса. А нам важно получить статистику по всем аналогичным запросам, без учета этих «плавающих» элементов. Например, таких:
p_0: 0N
p_1: 0xF2F584181A81D949A82B1EDEB0FE9ED0
p_2: 0N
INSERT INTO #tt13
Для получения аналогичной свертки по текстам запросов через инструменты bash можно использовать следующий скрипт:
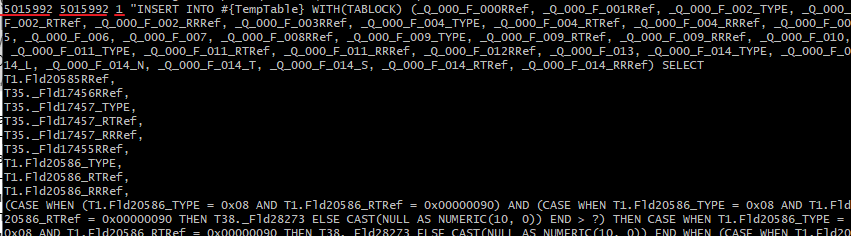
Причем эта задача несколько сложнее, чем с серверными вызовами, потому как в скрипте также присутствует нормализация текстов запросов.
Также есть вариант для получения статистики по количеству/длительности запросов по последней строке контекста:

В «1С‑Рарус: Мониторинг производительности» для группировки запросов по контексту исполнения также есть специальная диаграмма:
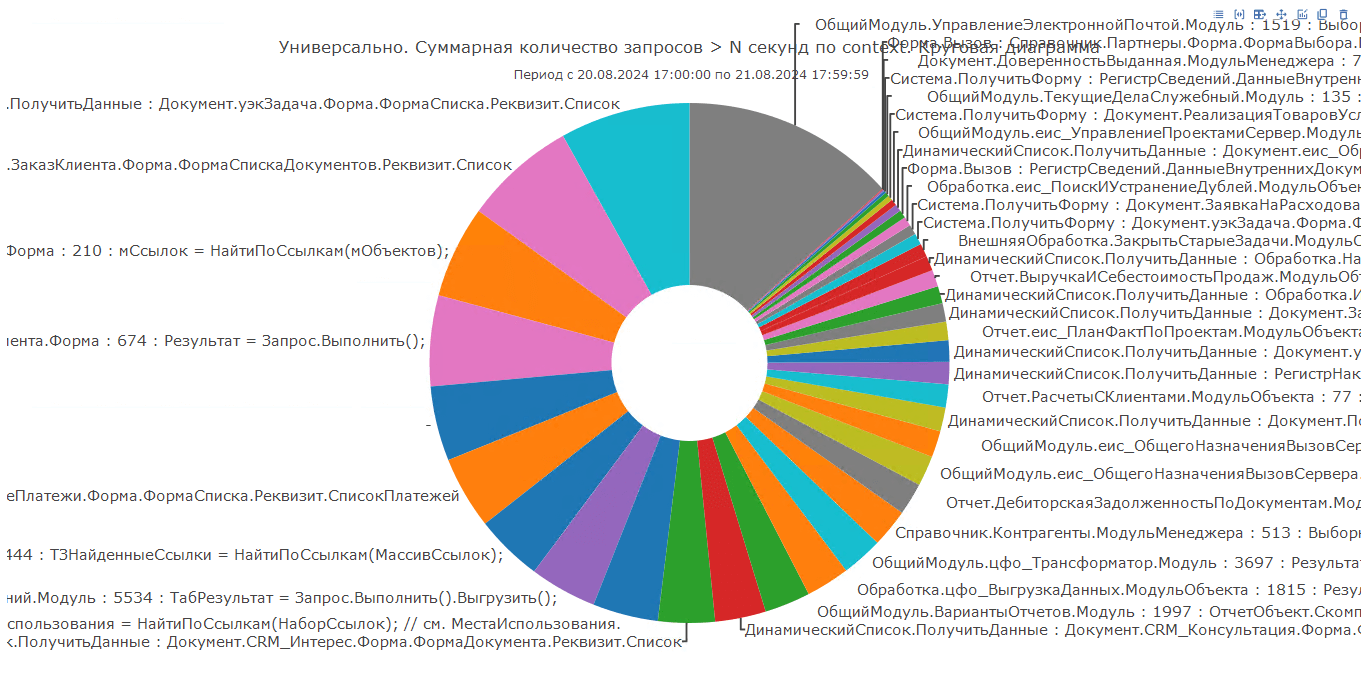
По ней мы сразу можем увидеть, какой сектор занимает самую большую долю среди всех запросов и перейти к детальному анализу запросов, выполняемых в указанном контексте.
Клиент-серверные вызовы
Для того, чтобы проанализировать все события клиент-серверного вызова, а также узнать длительность такого вызова, в «1С‑Рарус: Мониторинг производительности» используется анализ события VRSREQUEST и VRSRESPONSE, которые фиксируются как на стороне сервера, так и на стороне клиента. Данные события являются парными и по ним очень удобно выделять начало и конец клиент-серверного взаимодействия в системе.
Мы разработали специальную диаграмму, которая анализирует пары событий VRSREQUEST и VRSRESPONSE, считает сколько времени прошло между ними, и затем выбирает только те, которые проходят по фильтру длительности. В результате мы можем увидеть количество длительных клиент-серверных вызовов в определенном периоде:
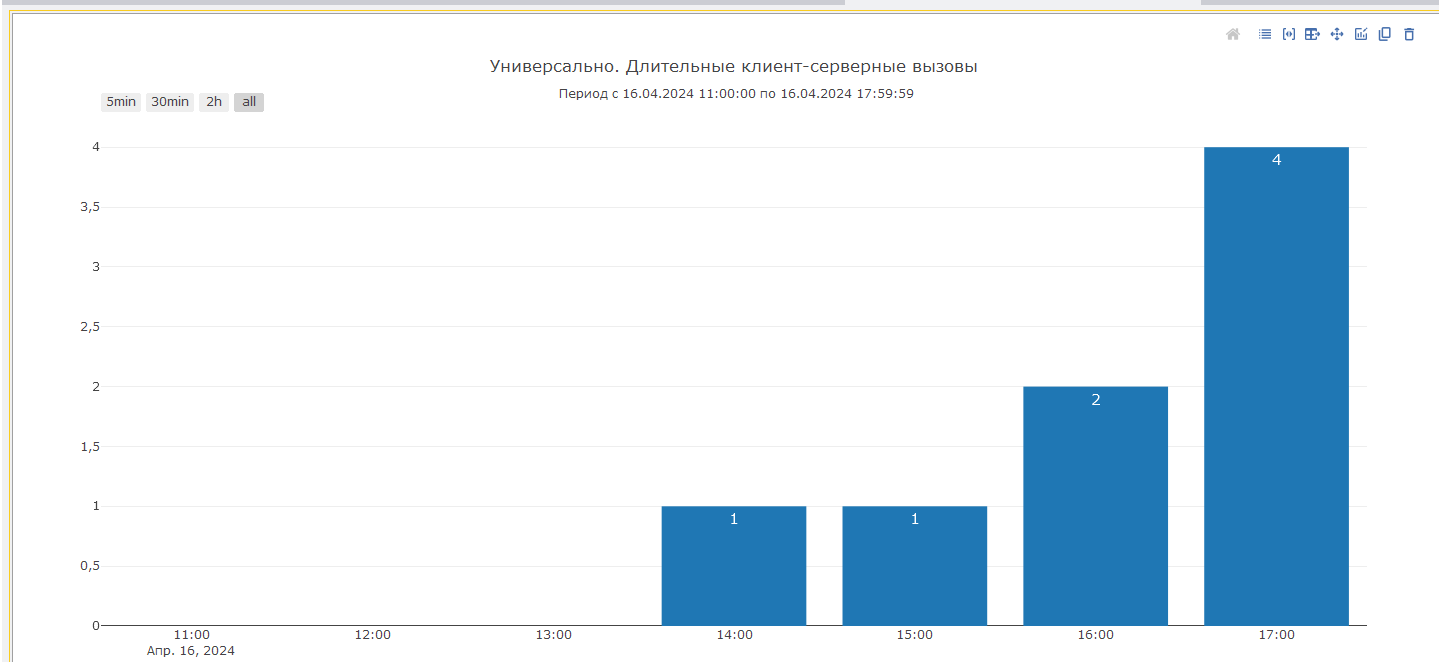
Это позволяет нам ответить на вопрос о количестве таких длительных операций, как формирование отчетов, проведение документов, открытие справочников. То есть, мы рассматриваем такие операции, как целостные блоки при расследовании:
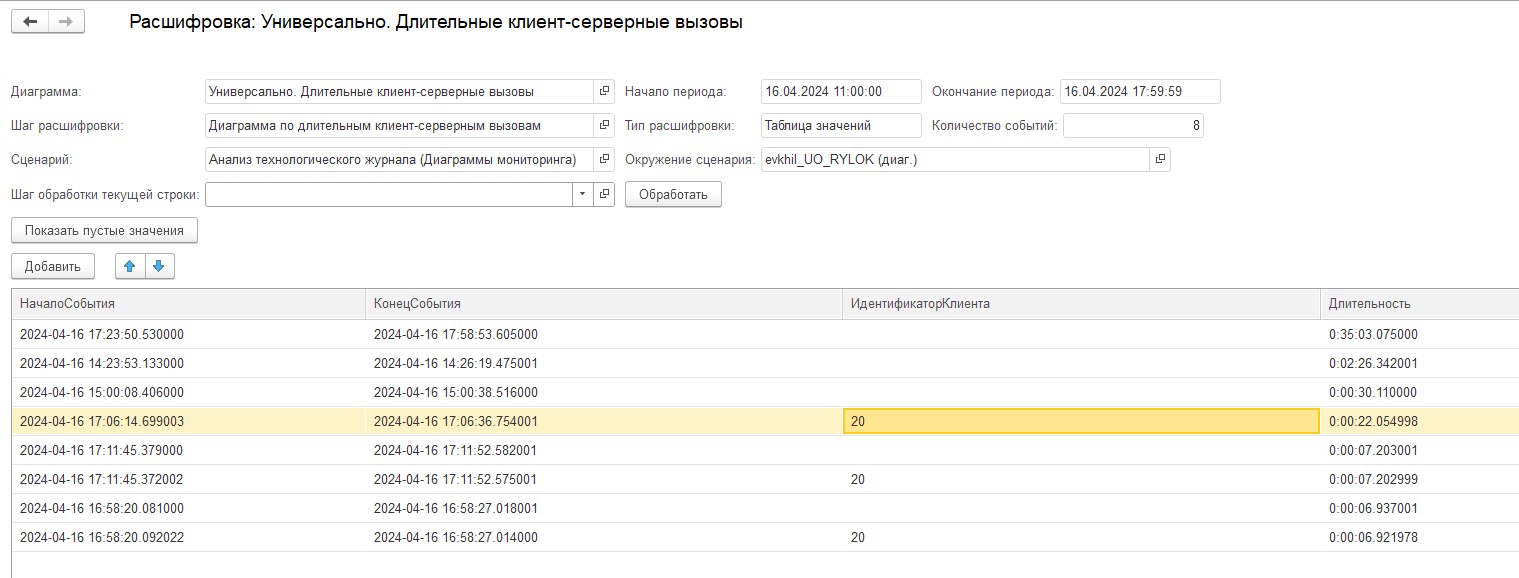
В расшифровке диаграммы необходимо выбрать шаг «События клиент-серверного вызова»:
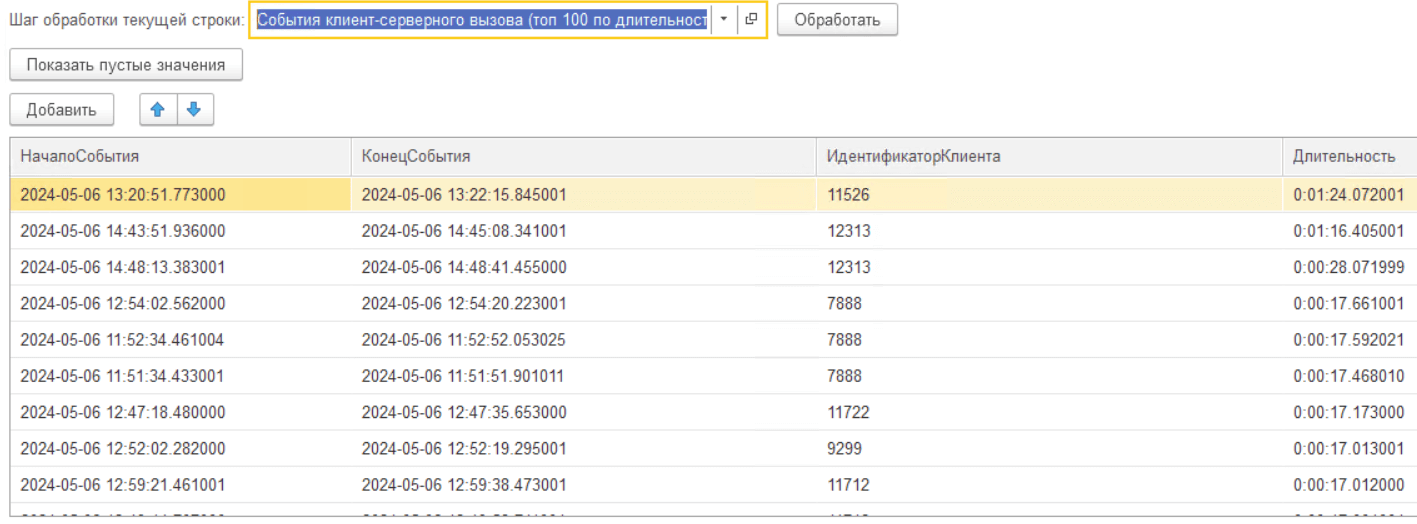
Система проанализирует события, которые были зафиксированы в логах с найденным идентификатором клиента и которые произошли в указанном промежутке времени, и выведет их либо в порядке следования на оси времени, либо же в порядке убывания длительности:
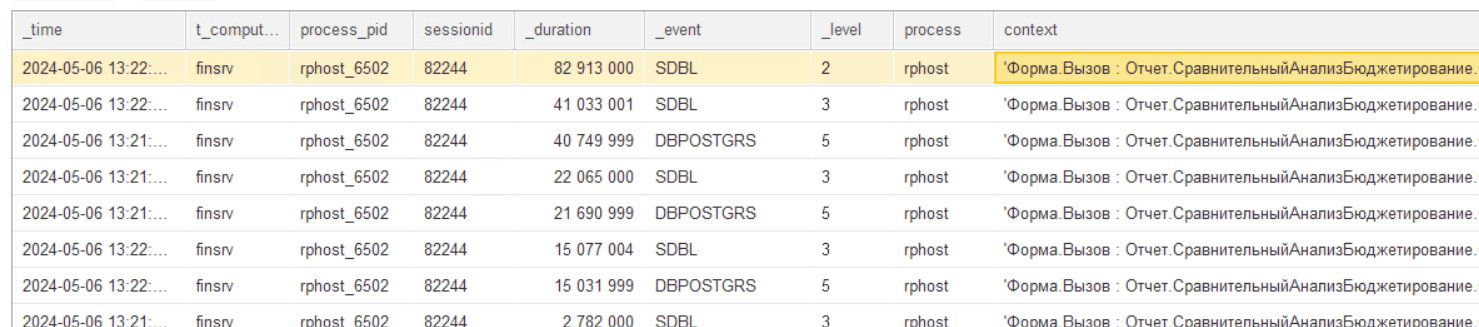
В найденных строках уже можно перейти вплоть до строки контекста данных, что позволит нам быстро понять причину зафиксированного длительного вызова.
Отвечаем на вопрос, какой код вызывает нагрузку, но не попал в логи
Как мы уже упомянули ранее, логи технологического журнала 1С содержат множество событий, однако, логированию подлежат далеко не все строки кода, которые выполняются сервером 1С.
Даже если собрать полный технологический журнал, без фильтрации по событиям, мы все равно можем не увидеть всех мест, которые нагружают систему.
Часто возникают такие ситуации, когда мы видим фиксацию какого-то события в логи, например, DBMSSQL длительностью несколько миллисекунд, однако предыдущее по порядку событие лога зафиксировалось не на несколько миллисекунд ранее от предыдущего, а, скажем, на несколько секунд или на несколько десятков секунд ранее.
Для того, чтобы ответить на вопрос, что же происходило в системе все это время мы можем воспользоваться специальной функцией мониторинга «Поиск GAPов». Данную функцию можно применить к любой детальной строке лога ТЖ события CALL:
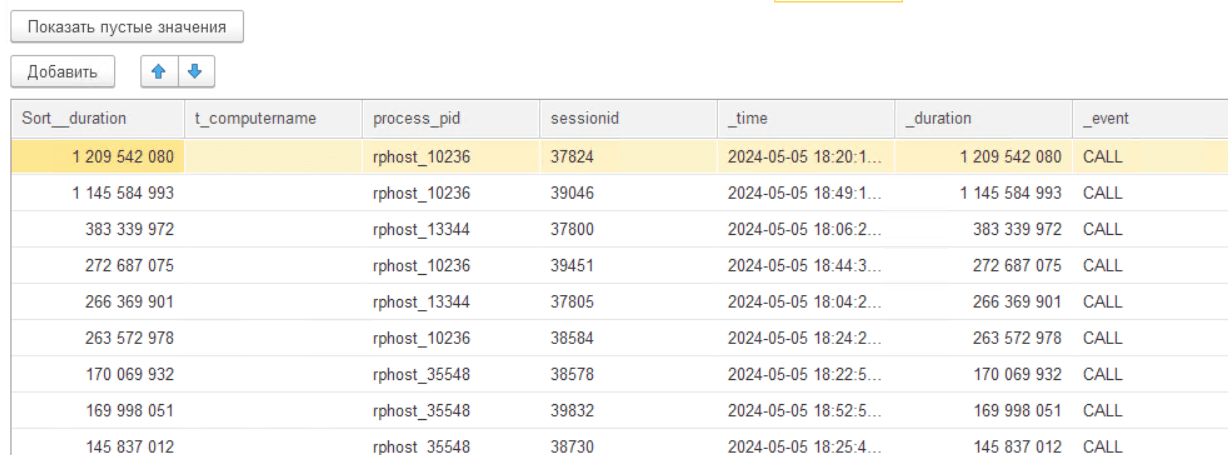
При её выполнении будут собраны все события в том же клиент-серверном вызове, что и выбранная строка расшифровки. Далее рассчитана разница во времени выполнения между каждой парой последовательных событий за вычетом их длительности. И в итоге мы получим топ событий, в которых такой «разрыв во времени» с предыдущим событием максимален, плюс контекст исполнения этих строк.
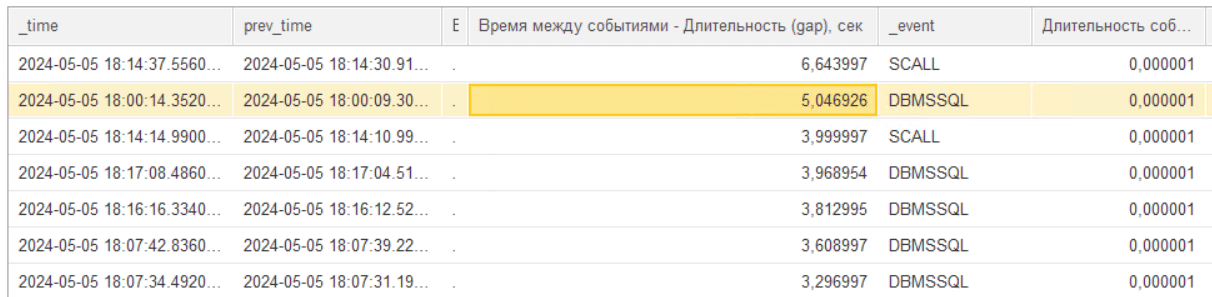

Далее, зная контексты строк, мы можем понять, что код, который выполнялся между этими двумя строками был длительным и провести анализ в конфигураторе.
Как выглядит решение задачи поиска GAPов при «ручном» разборе? Обычно мы отталкиваемся от некоего длительного вызова.
Например, есть такое событие:
Нам нужно найти все события в рамках того же клиент-серверного вызова. В ТЖ клиент-серверный вызов обрамляется парой граничных событий:
- VRSREQUEST
- VRSRESPONSE
Так что мы выбираем все события начала клиент-серверного вызова VRSREQUEST с тем же номером соединения:
И далее ищем в полученном списке ближайшее событие до нашего события:
- 05:48.554001-0,VRSREQUEST
- 08:42.393001-0,VRSREQUEST
Следующим этапом нужно выбрать все события между VRSREQUEST и CALL:
И уже среди полученных событий ищем большой «разрыв» во времени:
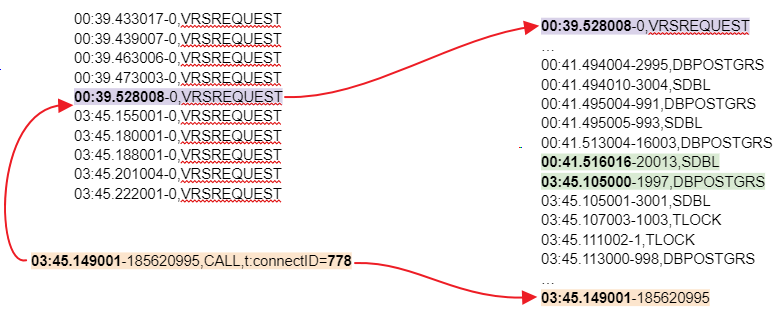
Помимо того, что мы просто можем просмотреть найденные события, можно также воспользоваться специальным скриптом для случаев, когда событий очень много:
Как видите, задача нетривиальная и решается далеко не одним скриптом.
Серверные вызовы по потреблению памяти и процессора
Часто возникает ситуация, когда нам необходимо определить нагрузку на систему не только по длительности выполнения кода или запросов, а и по потреблению памяти и загрузке процессора. Для этого в «1С-Рарус: Мониторинг производительности» предоставляется несколько диаграмм, которые анализируют события CALL.
Первая диаграмма показывает суммарное количество памяти занятой и не освобожденной при серверном вызове выше определенного порога в байтах, который можно задать в отборах:
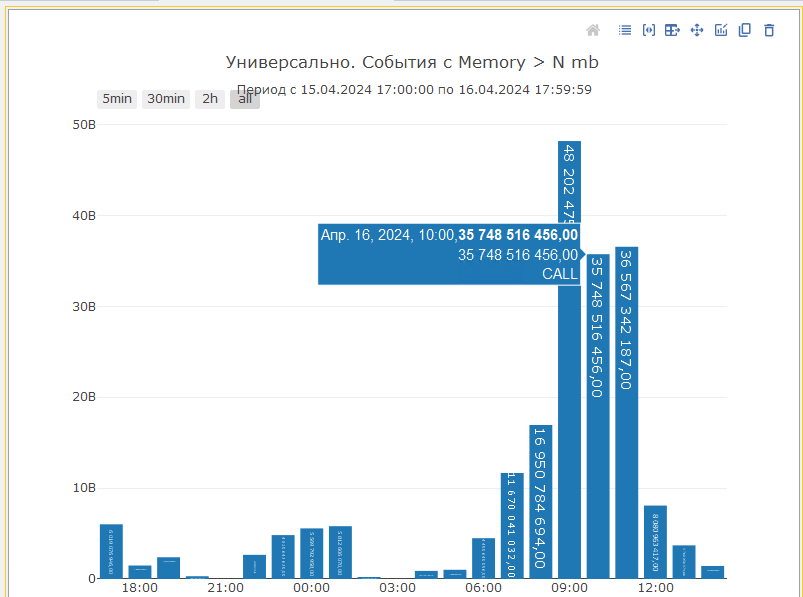
Стоит отметить, факт того, что память была занята, но не освобождена — еще не означает утечку памяти. При нахождении таких мест данные логов технологического журнала 1С необходимо дополнительно сравнивать со счетчиками оборудования сервера 1С, в частности, рост потребления оперативной памяти рабочими процессами, на очередь к диску и т. д.
Ряд показателей можно получить напрямую в «1С‑Рарус: Мониторинг производительности» при условии, что мы собираем счетчики оборудования:
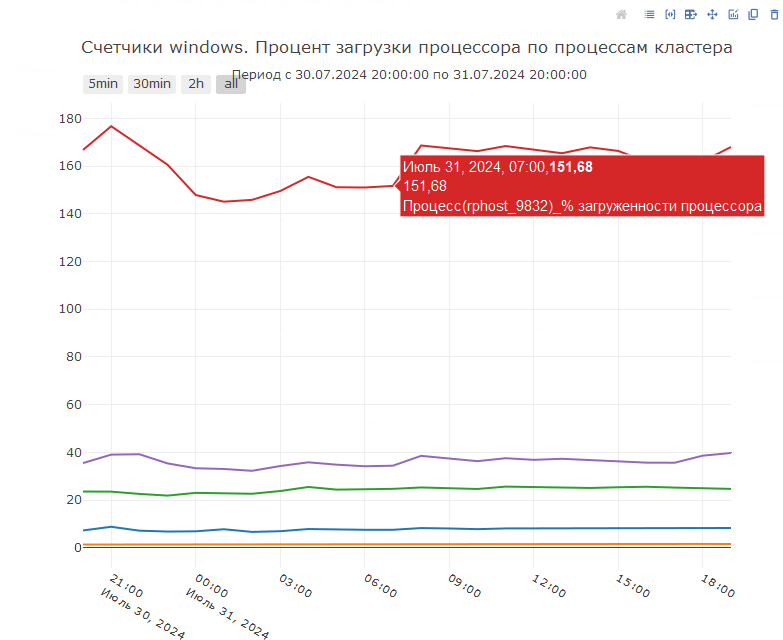
Также есть специальная диаграмма, которая покажет нам расклад по использованию процессорного времени серверными вызовами 1С. Для построения данной диаграммы мы будем использовать отбор и сортировку по свойству cputime событий CALL технологического журнала 1С:
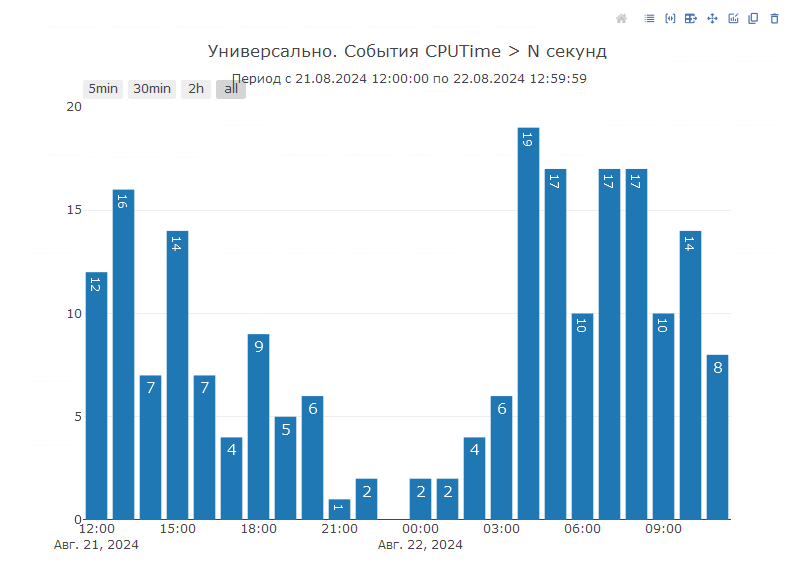
При возникновении подозрений на неоправданно процессорно интенсивные операции необходимо также сопоставить данные со счетчиками оборудования по проценту загруженности процессора в это же время:
При использовании bash-скриптов мы смогли бы проанализировать события логов технологического журнала 1С следующим образом:
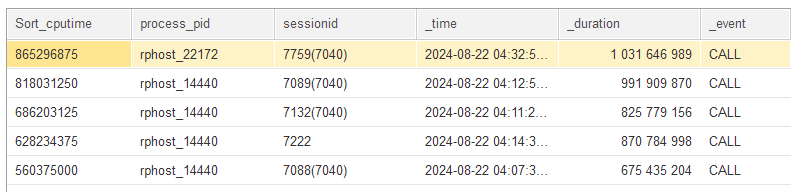
- Скрипт получения первых пяти событий CALL по полю Memory:
- Скрипт получения первых пяти событий CALL по полю CpuTime:
Взаимоблокировки и таймауты
Отслеживание превышения времени ожидания на блокировках, а также взаимоблокировок в системе, является очень важным при расследовании проблем производительности. Ведь при возникновении таких ситуаций со стороны пользователя это выглядит как замедление работы системы. При этом, если смотреть на ресурсы системы, то существенной нагрузки на них оказываться не будет.
В «1С-Рарус: Мониторинг производительности» мы предусмотрели несколько диаграмм, связанных с отслеживанием вышеописанных процессов. Прежде всего, в системе можгут не фиксироваться таймауты, но при этом время ожидания в системе из-за блокировк все равно будет. Это происходит, когда ожидания не доходят до порогового значения для возникновения таймаутов. Чтобы отслеживать такую ситуацию была разработана диаграмма, которая покажет события TLOCK, которые длились дольше заданного порога в секундах:
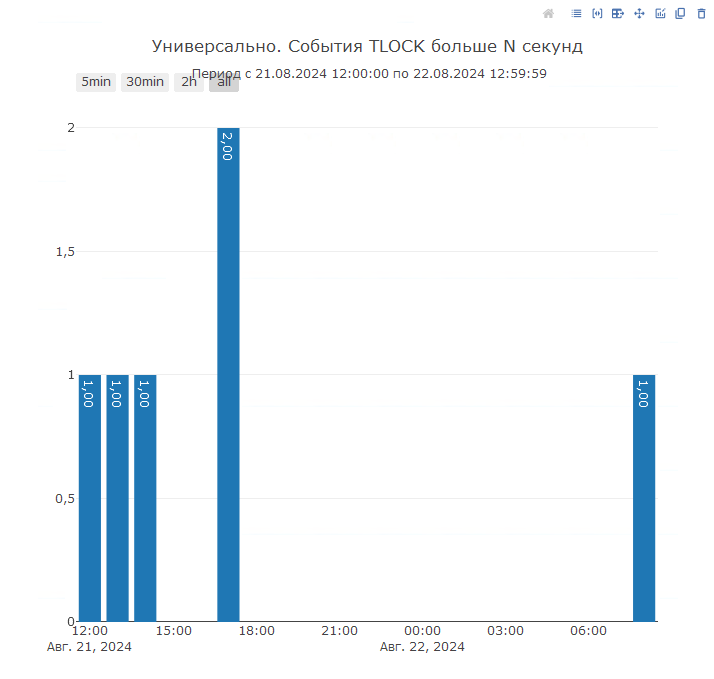
Это позволит еще до возникновения критичных ошибок на экранах пользователей обнаруживать и исправлять такие потенциально опасные места:

Если же таймаут уже возник, то необходимо определить контексты виновника и жертвы блокировки. Давайте посмотрим, как это сделать при помощи «1С‑Рарус: Мониторинг производительности». В системе есть диаграмма «События TTIMEOUT», которая покажет нам события, зафиксированные в момент возникновения ошибки превышения ожидания на блокировках:
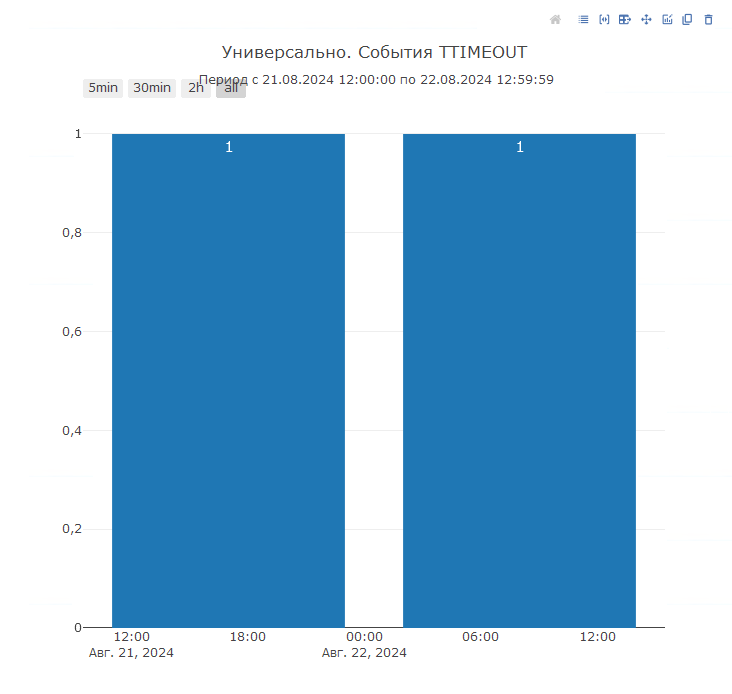
Далее, перейдя в расшифровку и применив специальную функцию обработки строки для события TTIMEOUT «Виновник блокировки», мы сможем непосредственно перейти к событиям TLOCK, которые были зафиксированы для жертвы и для виновника блокировки:
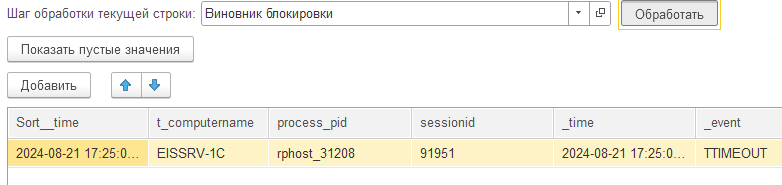

Для того, чтобы получить данную информацию о жертве блокировки, мы должны найти событие TLOCK, ближайшее на оси времени, которое произошло позже TTIMEOUT с тем же connectid и waitconnections:

После этого, чтобы получить информацию о виновнике блокировки, мы должны найти событие TLOCK, ближайшее на оси времени, которое раньше TTIMEOUT с connectid из waitconnections жертвы, а также пересекающимися пространствами блокировок, которые мы можем получить из свойства Regions. При поиске обращаем внимание на свойство «alreadyLocked», которое не должно быть в значении True:
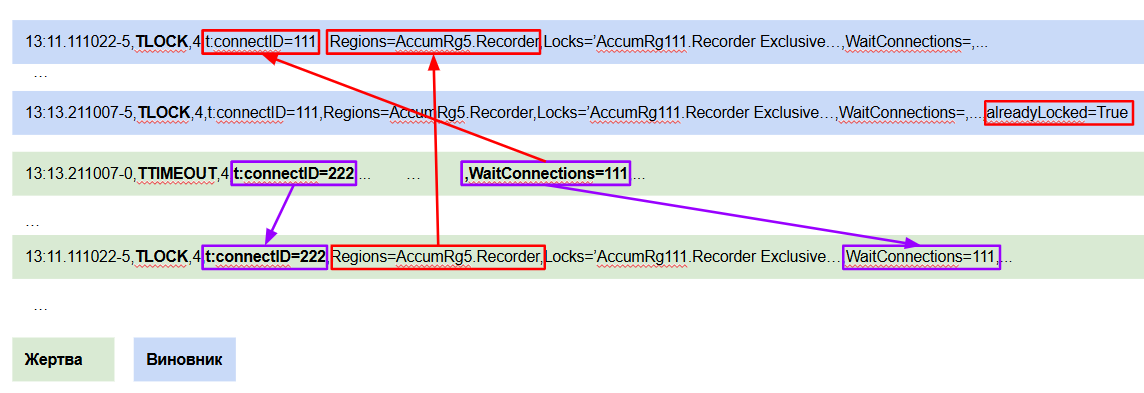
Таким образом мы можем перейти к контексту жертвы и виновника превышения ожидания на блокировке и уже непосредственно по коду конфигурации производить расследование причин такого поведения системы.
Расследование взаимоблокировки
В конфигурации «1С‑Рарус: Мониторинг производительности» предусмотрена диаграмма, которая позволяет расследовать возникающие в системе взаимоблокировки:
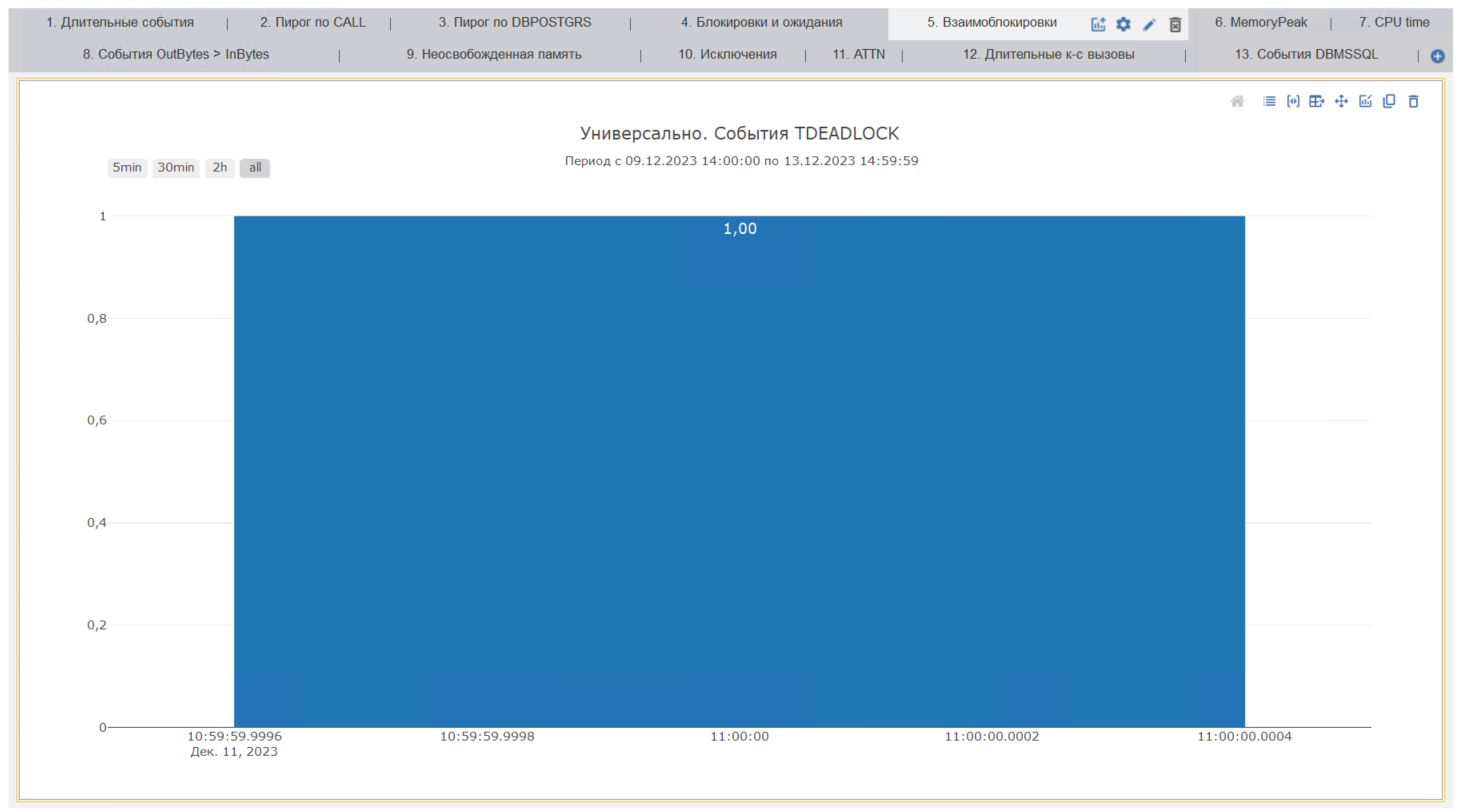
Наличие взаимоблокировок чаще всего являются первым, с чем стоит работать при анализе проблем в системе.
«Мониторинг производительности» позволяет найти строки с контекстами жертв и виновников взаимоблокировок простым вызовом функции «Виновник взаимоблокировки» для найденного события TDEADLOCK:
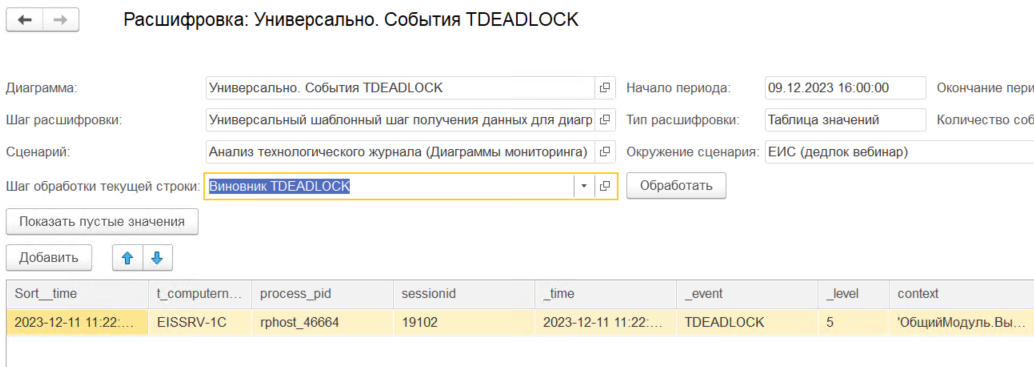

Рассмотрим процесс расследования взаимоблокировок подробнее. Для взаимоблокировки необходимо найти две пары событий TLOCK, которые в ней участвовали. В этом нам поможет свойство Deadlock connections intersection из TDEADLOCK. В нем будут указаны две пары connect_id, которые пересеклись.
Первая пара событий:
- От события взаимоблокировки производится поиск события TLOCK в логах, которое произошло позже и имеет тот же session_id и connect_id, а в свойстве wait_connections будет содержаться connect_id виновника. Это будет жертва блокировки.
- Виновником блокировки будет TLOCK, который был раньше TDEADLOCK, с connect_id из wait_connections жертвы и пересекающимися пространствами блокировок (свойства Regions и Locks пересекаются).
Вторая пара событий ищется ровно наоборот:
- От события взаимоблокировки производится поиск события TLOCK в логах, которое произошло позже и имеет тот же connect_id виновника, а в свойстве wait_connections будет содержаться connect_id жертвы. Это будет второй TLOCK виновника блокировки.
- Второй TLOCK жертвы же будет раньше TDEADLOCK, с connect_id из wait_connections виновника и пересекающимися пространствами блокировок (свойства Regions и Locks пересекаются).
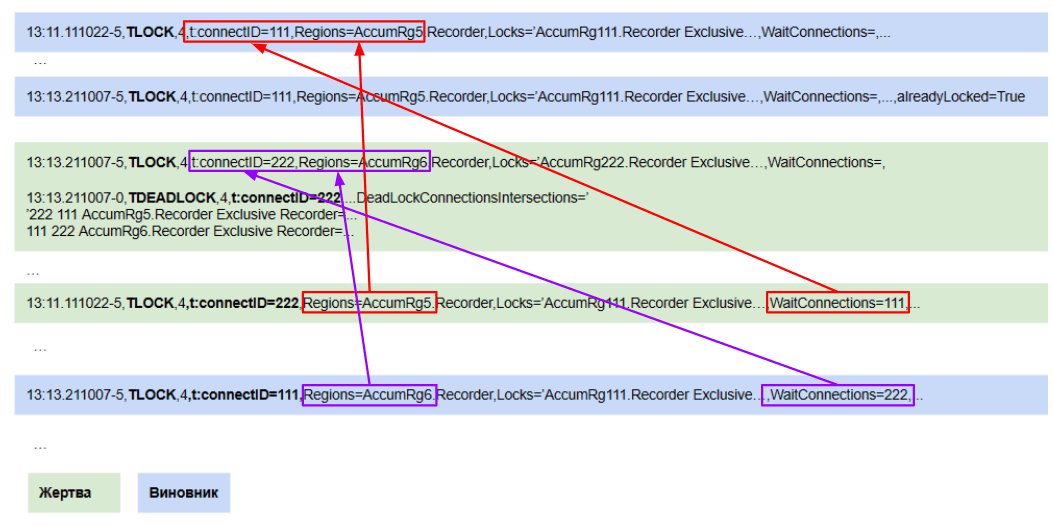
Таким образом мы получим всю необходимую для расследования информацию о контекстах событий, которые стали виновниками и жертвами взаимоблокировки в один клик.
Расследования таймаутов и взаимоблокировок в классической экспертизе
В случае таймаута нам нужно было бы:
- Сначала найти в логе события TTIMEOUT:
- Найти событие TLOCK жертвы по номерам соединения жертвы и виновника:
- Далее найти событие TLOCK виновника по номеру соединения виновника и тому же пространству:
В случае взаимоблокировки логика похожа:
- Сначала найти в логе события TDEADLOCK:
- Ищем TLOCK жертвы по номеру соединения жертвы/виновника и пространствам, искомый TLOCK первый после TDEADLOCK:
- После ищем TLOCK виновника по номеру соединения виновника и пространству из события жертвы. Искомое событие последнее до TDEADLOCK:
- Таким же образом находим вторую пару событий жертва-виновник.
Использование сторонних систем визуализации данных совместно с «1С‑Рарус: Мониторинг производительности»
Так как мы храним данные преобразованных логов технологического журнала 1С, журнала регистрации, счетчиков производительности в аналитической СУБД ClickHouse, это открывает богатые возможности для использования этих данных в сторонних системах визуализации посредством обращения напрямую к источнику данных.
Продемонстрируем данную возможность на примере Grafana. Это система визуализации данных, реализованная как веб‑приложение в стиле панелей с диаграммами, графиками, таблицами, предупреждениями.
Это одна из самых популярных систем с своем классе и она содержит расширение для работы с ClickHouse:
После установки расширения необходимо добавить новый источник данных:

Указываем параметры подключения к серверу и сохраняем подключение:
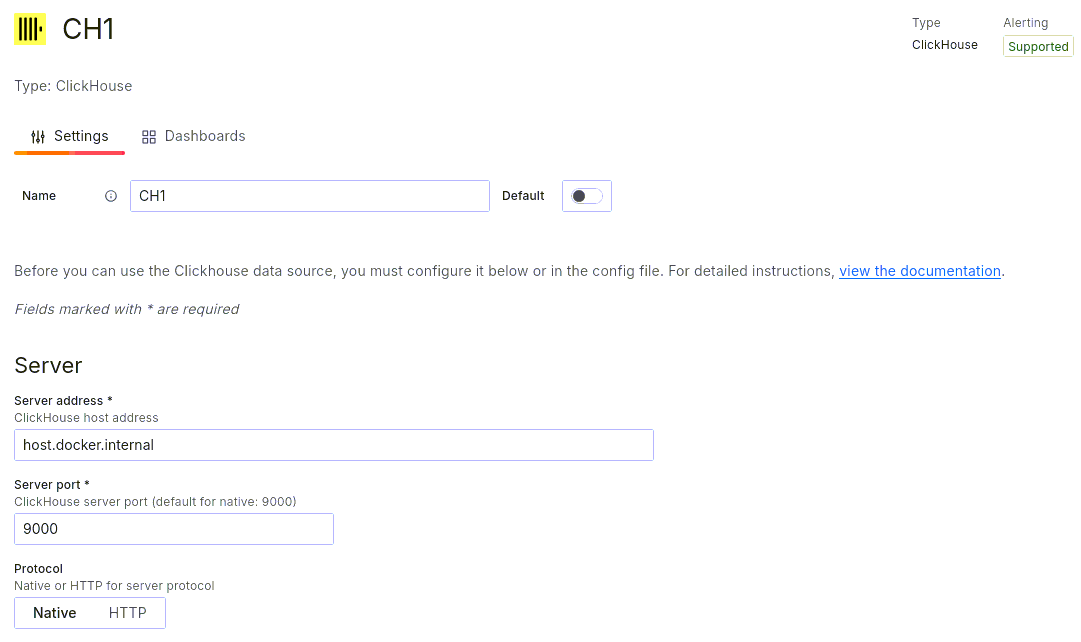
После того, как источник данных был добавлен, можно переходить к созданию собственной доски с данными. При создании доски выбираем только что добавленный источник данных и попадаем в меню настройки панели:
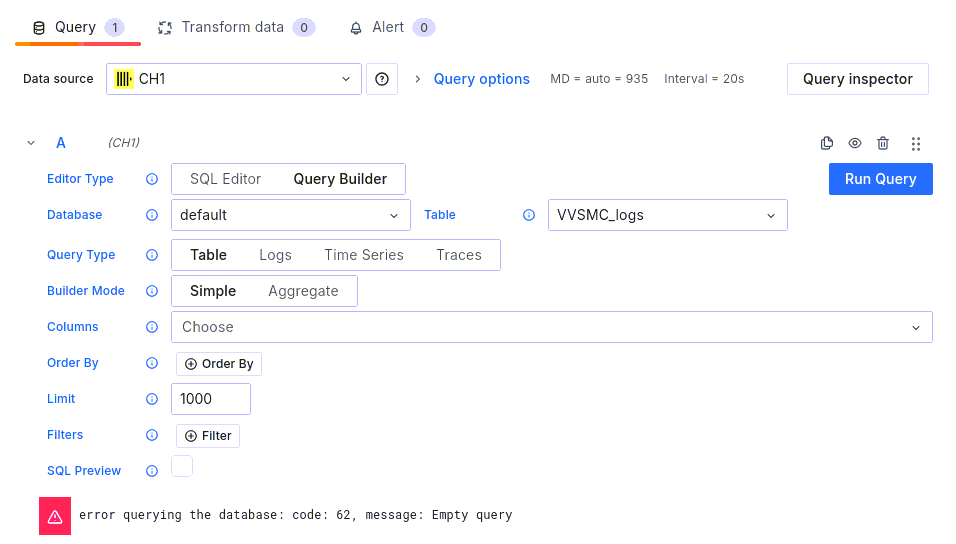
Существует два варианта настройки выборки данных для диаграммы — при помощи построителя запроса (Query Builder), а также при помощи написания текста запроса вручную (SQL Editor):
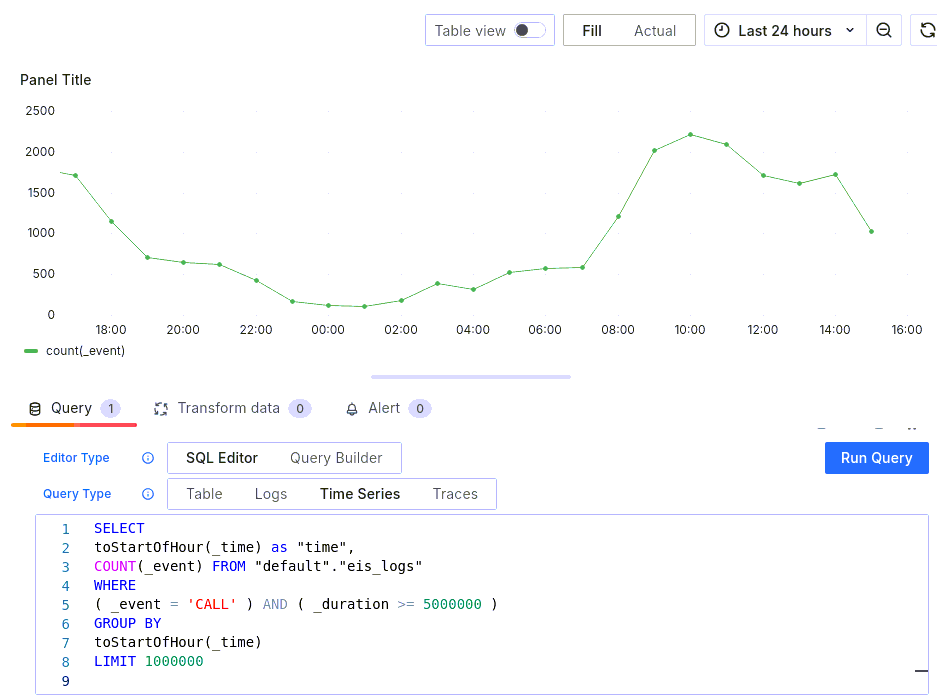
Давайте настроим первую диаграмму. Выберем количество событий CALL, длительность которых превысила 5 секунд. Для удобства выберем режим редактирования SQL текста запроса и напишем свой запрос:
SELECT
toStartOfHour(_time) as "time",
COUNT(_event) FROM "default"."eis_logs"
WHERE
( _event = 'CALL' ) AND ( _duration >= 5000000 )
GROUP BY
toStartOfHour(_time)
LIMIT 1000000После выполнения запроса получим график следующего вида:
Давайте настроим еще несколько диаграмм:
- Длительность событий DBMSSQL, сгруппированная по часам:
Select top 1000
_event as _event,
toStartOfHour(_time) as Hour,
sum(_duration/1000000) as duration
from
default.eis_logs
where
_event IN 'DBMSSQL'
and default.eis_logs._duration > 5 * 1000000
group by
_event,
toStartOfHour(_time) as Hour
order by
sum(_duration) DESC
- События TTIMEOUT по часам:
SELECT
toStartOfHour(_time) as "time",
COUNT(_event) FROM "default"."eis_logs"
WHERE
( _event = 'TTIMEOUT' )
GROUP BY
toStartOfHour(_time)
LIMIT 1000000В итоге получим небольшую тестовую доску, которая будет выглядеть так:
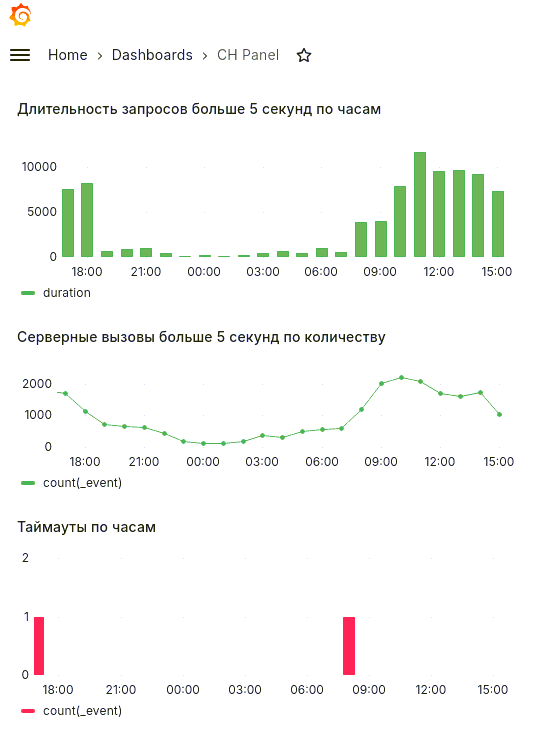
Как мы видим, использование преобразованных «1С‑Рарус: Мониторинг производительности» данных во внешних системах визуализации не представляет никаких трудностей, однако, стоит понимать, что когда речь зайдет о более сложном анализе, например, когда необходимо будет найти виновника блокировки, задачи с манипуляцией данных станут все сложнее и сложнее и повторить функционал встроенной подсистемы диаграмм из «1С‑Рарус: Мониторинг производительности» станет сложнее. К тому же, как уже говорилось ранее, диаграммы предоставляют лишь общий взгляд на состояние системы. Для эксперта же особую ценность имеют расшифровки данных диаграмм, а также специальные функции, которые содержат более сложные и специфичные алгоритмы, которые можно применить к данным расшифровки диаграмм. Мы покажем пример написания собственных шагов расшифровки с произвольным алгоритмом во второй части статьи. Такого функционала при помощи внешних систем будет добиться крайне сложно.
Выводы
Как мы видим, типовой набор досок и диаграмм предоставляет необходимый инструментарий для того, чтобы произвести анализ причин падения производительности в системе быстро и без необходимости менять и редактировать код скриптов или же состав регулярных выражений.
Мы показали далеко не все возможности для расследования, которые предоставляет «1С‑Рарус: Мониторинг производительности». Однако в рамках одной статьи уместить все, что мы хотели бы вам рассказать не получится, поэтому в рамках второй части статьи мы коснемся таких тем, как:
- Восстановление полного текста запроса для получения плана запроса без необходимости его сбора через технологический журнал 1С на постоянной основе.
- Использование данных журнала регистрации для связывания контекста исполнения кода в 1С, данных счетчиков производительности с конкретными объектами документов, справочников, записей регистров.
- Использование подсистемы оповещений для того, чтобы иметь возможность в оперативном режиме получать информацию о возникающих в системе критических ситуациях.
- Использование произвольных запросов к аналитической СУБД для построения нетиповых диаграмм, которые выходят за рамки стандартных возможностей, предоставляемых системой.
- И многое другое.
Можно сказать, что разработанный нами инструментарий позволяет нам выявлять проблемы в системе быстро и удобно, сосредоточиться на составлении гипотез и их подтверждении, а не на рутинных операциях, связанных с анализом логов технологического журнала 1С, например, инструментами bash.
Следите за выходом новых статей на сайте rarus.ru в разделе от экспертов.
От экспертов «1С-Рарус»















