



Оглавление
- Долгое закрытие месяца при консолидации данных трёх заводов
- Самостоятельная оптимизация, выполненная клиентом
- Подключение команды «1С-Рарус», разворачивание тестового сервера
- Ищем долгие этапы расчета себестоимости и определяем причину их задержек
- Этапы «ЗаполнениеПартийВРегистреСебестоимостьТоваров» и «СкорректироватьСтоимостьСписанияНезавершенногоПроизводства»
- Этап «ЗаписатьСформированныеДвижения»
- Строим гипотезы возможного ускорения этапа «ЗаписатьСформированныеДвижения»
- Гипотеза №1. Изменение параметров закрытия месяца
- Гипотеза №2. Разработать механизм параллельной записи порций, определяя несвязанные подграфы в общем графе сформированных движений
- Гипотеза №3. Альтернативный механизм параллельной записи порций или можно ли параллельно записывать порции данных по регистраторам без учета связанности?
- Результаты ускорения закрытия месяца
- Применимость гипотез №2 и №3 на практике
Долгое закрытие месяца при консолидации данных трёх заводов
Анализ производительности выполнялся для крупного предприятия, которое производит продукцию для строительства многоквартирных домов по четырем основным направлениям: фасадные решения, инженерные решения, конструкторские решения, решения для благоустройства.
В состав компании входит три предприятия, основной вид деятельности которых выпуск железобетонных домовых панелей. Информационная учетная система разработана на базе «1С:ERP Управление строительной организацией 2.5». Каждый завод закрывал месяц в своей обособленной базе, затем производилась консолидация в единую базу. Руководством было принято решение о том, что операцию «закрытие месяца» необходимо выполнять сразу консолидировано по всем трем организациям.
После объединения данных всех организаций в единой базе расчет себестоимости начал проходить неприлично долго. В особо «нагруженные» месяца, где количество первичных документов было на ~30% больше по сравнению с другими месяцами, расчет себестоимости длился на ~6 часов дольше, доходя до 30 часов.
Работа производилась в «1С:ERP Управление строительной организацией 2.5.12.185», на момент анализа релиз был месячной давности, каких-либо глобальных доработок внесено не было.
В базе вводилось множество документов, влияющих непосредственно на расчет себестоимости, к примеру, только документов «Перемещение товаров» за месяц вводилось 20000–25000 штук, причем документы в массе многострочные.
Самостоятельная оптимизация, выполненная клиентом
До момента обращения к нам клиент своими силами проводил оптимизацию этапа расчета себестоимости. Что было сделано:
Сокращение количества партий выпуска продукции путем «свертки» за каждый день документов с одинаковыми строками по столбцу «Аналитика учета номенклатуры». Свертка была сделана для документов «Производство без заказа» по некоторым из организаций.
Документ «Производство без заказа» предназначен для отражения производства продукции или работ и списания материалов с баланса складов и цеховых кладовых, а также работ с баланса подразделений, и их отнесение на себестоимость выпущенной продукцию. Свертка производилась для сокращения количества связей по графам при расчете себестоимости. Более детально об этом расскажем далее в разделе оптимизации этапа заполнение партий для регистра себестоимости.Изменение параметра операций закрытия месяца — параметр расчет себестоимости «Отключить редуцирование графа при решении системы линейных уравнений» установлен в значение «Да» (по рекомендации 1С ЦКТП).
Тут следует прокомментировать, что данный параметр при включении влияет на способ обработки сложных расчетов, связанных с учетом зависимости между различными элементами (например, затратами, запасами и т.д.) при закрытии месяца, но также он может отрицательно влиять на время расчета себестоимости при больших объемах данных и значительно замедлять этапы, где рассчитываются данные по графам. В нашем случае отключение редуцирования привело к существенному сокращению времени расчета себестоимости. Проиллюстрируем графы до и после редуцирования, а для примера возьмем простейший граф зависимости затрат на выпуск продукции.Предположим, что у нас есть следующие переменные и фиксированные затраты для двух продуктов: A и B.
- Переменные затраты на продукт A (VC_A).
- Переменные затраты на продукт B (VC_B).
- Фиксированные затраты (FC).
Граф может выглядеть следующим образом:
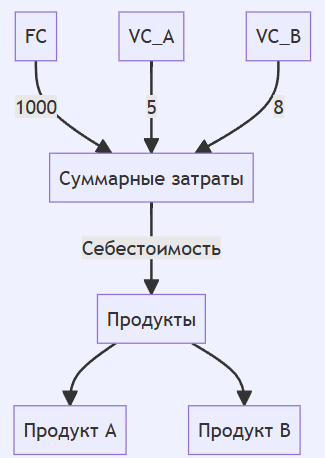
После редуцирования зависимости затрат, фиксированные затраты можно объединить с переменными, чтобы упростить граф:
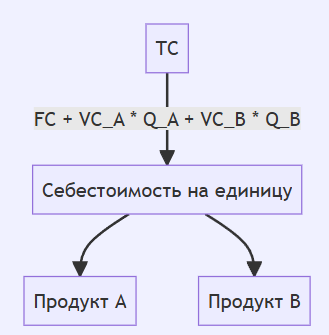
До редуцирования: В первой версии графа каждая зависимость представлена по отдельности, что делает его более сложным.
После редуцирования: Во второй версии графа все переменные и фиксированные затраты объединены в одну общую сумму, что значительно упрощает анализ себестоимости и зависимостей.
В итоге удалось сократить время этапа расчета себестоимости с 30 часов до 22 ч. 34 мин. Это время также не устроило руководство и было решено дальше проводить изыскания по оптимизации этапа расчета себестоимости.
Подключение команды «1С‑Рарус», разворачивание тестового сервера
Расчет себестоимости решено было выполнять на тестовом сервере, который максимально был приближен по параметрам железа к продуктивному серверу. Анализируя ведения учета на предприятии можно выделить особенностью то, что необходимо рассчитать себестоимость по каждому подразделению, которых более 100 по каждой из организаций. В большинстве из подразделений расчет себестоимости идет без обособления по конкретным партиям при выбытии в производство, что приводит к огромному количеству «связей» при подборе партий выбытия в момент расчета себестоимости.
Под обособленным обеспечением производства понимается выявление объекта обособления, под который будет выполняться обеспечение производства материалами.
Существую следующие варианты обособления:
- По направлению деятельности — позволяет обеспечить потребность в материалах для производства продукции под направление деятельности. Такие материалы могут быть использованы для производства продукции в рамках того направления деятельности, под которое они были зарезервированы. Объектом обособления выступает направление деятельности.
- По назначению продукции — позволяет обеспечить потребность в материалах с обособлением под заказ клиента, которым зафиксирована необходимость в поставке продукции. Рекомендуется использовать, если приобретение материалов для целевого (обособленного) выпуска продукции происходит до создания заказов на производство. Объектом обособления материалов, планируемых к использованию в рамках производства продукции, выступает клиентский заказ.
- По этапу производства — позволяет обеспечить потребность в материалах под каждый этап производства. Объектом обособления выступают этапы производства.
- По заказу на производство — позволяет обеспечить потребность в материалах по заказу на производство без детализации до этапов. Выполняется общее обеспечение потребности в материалах для выпуска всей продукции одного заказа на производство. Такой вариант обособления позволяет закупать материалы до создания этапов производства. Объектом обособления выступают заказы на производство.
Далее приступили к процедуре закрытия месяца.
Ключевые характеристики аппаратной и программной части тестового сервера
Сервер СУБД:
- СУБД: MSSQL.
- Платформа: 8.3.23.1912.
- Продукт: 1С:ERP Управление строительной организацией 2.5.12.185.
- Оперативная память: 320 ГБ.
- ЦПУ: Intel® Xeon® CPU E5-2680 v2 @ 2.80GHz, 20 ядер.
Сервер приложений:
- Оперативная память: 488 ГБ.
- ЦПУ: Intel® Xeon® Gold 6342 CPU @ 2.80GHz, 48 ядер.
После выполнения процедуры закрытия месяца то, с чего начинается анализ — это протокол расчета себестоимости, где описаны все шаги расчёта, которые помогают выявить основные длительные этапы и ход выполнения расчета себестоимости. Как читать протокол можно ознакомиться в статье Выявляем причины долгого «Закрытия месяца» в 1С:ERP и ускоряем выполнение операции. Часть I.
Ищем долгие этапы расчета себестоимости и определяем причину их задержек
Для определения узких мест обратимся к протоколу расчета. Это отчет, позволяющий увидеть ключевые характеристики прохождения конкретного этапа расчета себестоимости.
Нас интересует топ самых длительных операций по расчету себестоимости, рассмотрим их.
Видим, что Этапы №94, №77 и №17 суммарно занимают более 9 ч, т. е. занимают около 40% от всей процедуры расчета себестоимости.
Этапы «ЗаполнениеПартийВРегистреСебестоимостьТоваров» и «СкорректироватьСтоимостьСписанияНезавершенногоПроизводства»
Первые этапы, которые анализировались, были «ЗаполнениеПартийВРегистре СебестоимостьТоваров» и «СкорректироватьСтоимость СписанияНезавершенногоПроизводства». Они рассматривались в едином контексте, так как на первом этапе происходит распределение партий, а на втором — формирование движений по регистрам «СебестоимостьТоваров» и «ПрочиеРасходы НезавершенногоПроизводства».
Длительность данных этапов напрямую зависит от большого количества записей по вышеописанным регистрам. Поэтому, сократив количество записей в движениях регистров, время по обоим этапам, предположительно, должно уменьшиться. Именно поэтому мы начинаем с них, ожидая, что оптимизация этих этапов приведет и к оптимизации самого длительного этапа №94 «Партионный учет: ЗаписатьСформированныеДвижения».
Из протокола следует, что этап состоит из сбора данных для формирования партий регистров себестоимости (Себестоимость товаров, Прочие расходы незавершенного производства, Прочие расходы) и из расчета графов для определения партий для каждого расхода товара (в нашем случае передача в производство) в количественном выражении по партиям приходов (остатки и приходы).
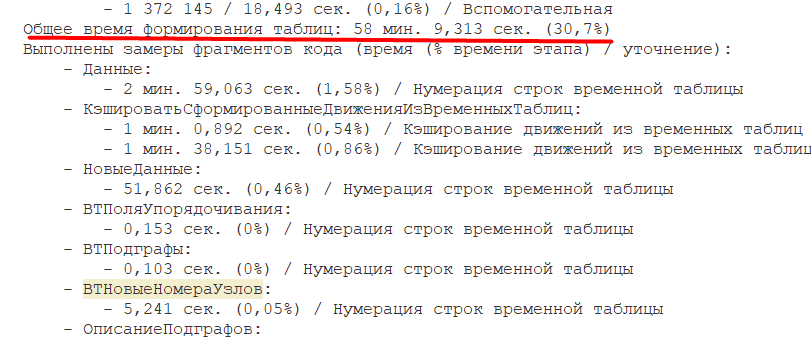
В эталонном месяце (таким месяцем был определен июнь, так как больше всего первичных документов было в этом месяце и, соответсвенно, выполнялся расчет себестоимости в этом месяце дольше) время расчета по этапу составило 3 часа 9 минут, где на формирование таблиц ушло 58 минут, остальное время на расчет связей по графам. Анализируя протокол расчета, стало ясно, что длительность этапа напрямую зависит от количества связей между документами для поиска партий выбытия. Далее смотрим расшифровки.
В результате анализа расшифровки протокола было установлено, что основная доля пришлась на комбинации:
- Перемещение товаров → Производство без заказа, 18,9 млн.
- Перемещение товаров → Движение продукции и материалов, 47,3 млн.
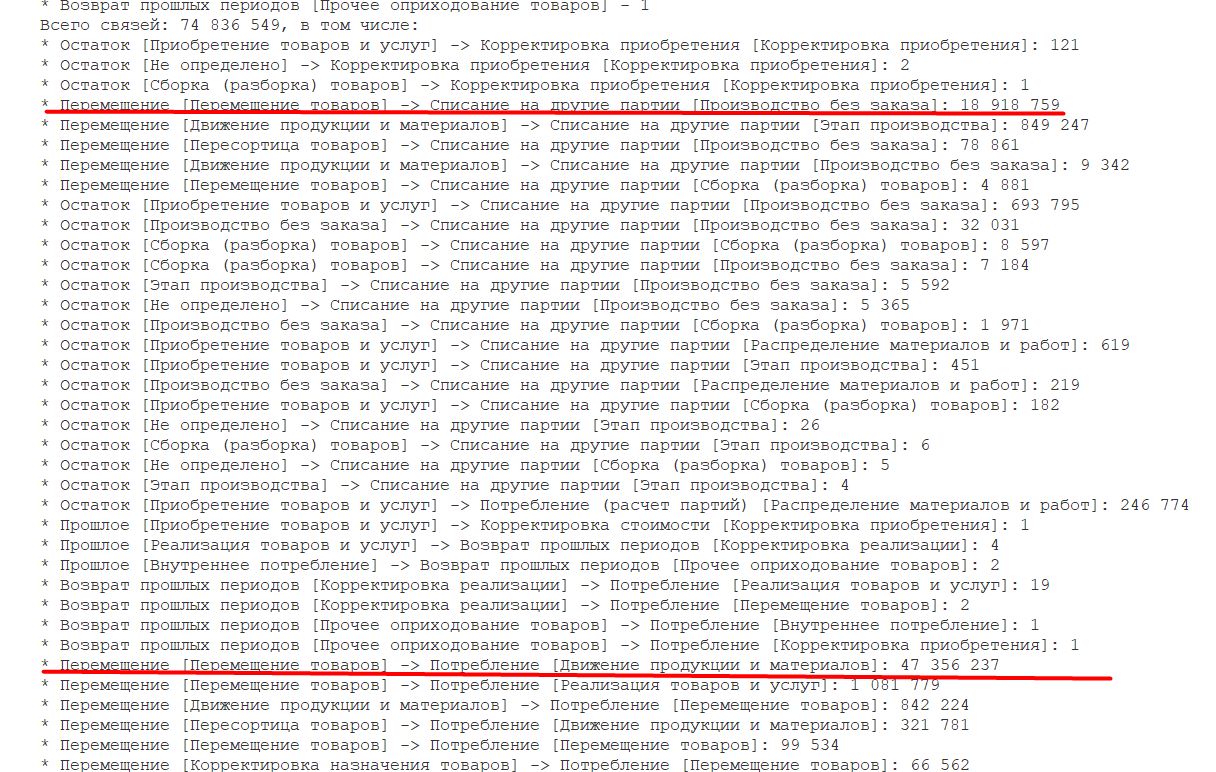
В первом приближении видно — при консолидации данных по разным организациям в одной базе в первую очередь на длительность повлияло то, что в системе появилось большое количество партиеобразующих документов, в том числе, с десятками тысяч строк. Это привело к огромному количеству связей при определении партий выбытия.
К такой ситуации приводит совокупность следующих причин:
Заказчик использует в своей работе документы «Движение продукции и материалов» с хоз. операцией «Передача материалов в производство». Такой подход предполагает, что указанный документ обязательно будет использовать аналитику распоряжения в виде документа «Этап производства». Аналитика распоряжения — реквизит связи c этапами производства, который используется для анализа данных о перемещении и использовании материалов и готовой продукции в процессе производства. Типами могут быть либо Этап производство либо Заказ на перемещение материлов в производство. В нашем случае это будет Этап.
Простыми словами, на каждый этап производства формируется отдельный документ «Движение продукции и материалов», что приводит к росту количества связей при определении партий для расходов в производство и рост происходит кратно формируемым документам.
В базе Заказчика далеко не для каждого подразделения используется обособленное обеспечение материалов под каждый выпуск, что приводит к тому что количество связей для определения партий выбытия и, как следствие, количество формируемых движений по регистрам, будет вычисляться, как произведение всех движений приходов по каждому документу на движение расходов по каждому документу:
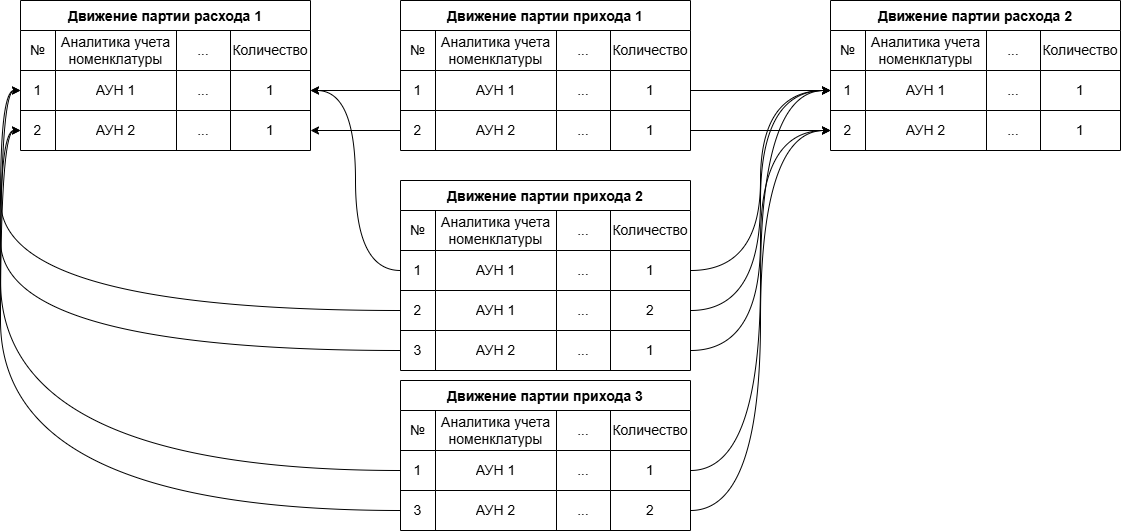 Определение количества связей без учета обособленного обеспечения материалов на этапе «ЗаполнениеПартий ВРегистреСебестоимость Товаров» вычисляется как произведение всех движений приходов по каждому документу на движение расходов по каждому документу, именно поэтому, как было показано выше, мы имеем многомиллионные связи между документам прихода и расхода при заполнении партий в регистре себестоимости, что напрямую и сказывается на длительном выполнении этапа.
Определение количества связей без учета обособленного обеспечения материалов на этапе «ЗаполнениеПартий ВРегистреСебестоимость Товаров» вычисляется как произведение всех движений приходов по каждому документу на движение расходов по каждому документу, именно поэтому, как было показано выше, мы имеем многомиллионные связи между документам прихода и расхода при заполнении партий в регистре себестоимости, что напрямую и сказывается на длительном выполнении этапа.
Для оптимизации этапа «ЗаполнениеПартий ВРегистреСебестоимость Товаров», в первую очередь, необходимо сократить количество связей для расходных документов «Производство без заказа» и «Движение продукции и материалов». Это возможно сделать путем сокращения приходных и расходных документов.
Приходными документами у заказчика на производственный склад, в основном, являются документы «Перемещения товаров», их количество Заказчик сокращать не может, так как каждый приход должен контролироваться МОЛом. Было решено сократить количество связей по партиям следующим образом:
- Для документов «Производство без заказа» в разрезе каждого дня свернуть документы по одинаковой аналитике по организациям, где такой свертки еще нет (в начале статьи писалось что по некоторым организациям свертку заказчик уже проводил самостоятельно).
- Для документов «Движение продукции и материалов» решено было перейти на учет материалов для выпуска под этапы единым документом. Для этого на эталонном месяце расчета была реализована следующая схема:
- С периодичностью один раз в день был сформирован документ «Движение продукции и материалов» с хоз. операцией «Передача материалов в кладовую» на основании потребностей документа «Этап производства», а документы «Движение продукции и материалов» с хоз. операцией «Передача материалов в производство» , которые были созданы на основании этого же этапа, были помечены на удаление.
- В документах «Этап производства» вместо производственного склада в табличной части «Обеспечение материалов» была проставлена созданная цеховая кладовая — «_ЦК».
Все измененные документы «Этап производства» перепроведены.
В ходе реализованной схемы удалось добиться следующих показателей:
- Расчет этапа «ЗаполнениеПартийВРегистреСебестоимостьТоваров» удалось сократить с 3 ч. 9 мин. до 1 ч. 45 мин. Анализ протокола показывает, что существенно сократилось количество связей для документов «Производство без заказа» и «Движение продукции и материалов».
- Расчет этапа «Скорректировать СтоимостьСписанияНезавершенногоПроизводства» удалось сократить с 2 ч. 5 мин. до 1 ч. 25 мин.
- Так как данные этапы формируют движения по регистрам, то логично, что сокращение количества связей по рассмотренным выше этапам привело к уменьшению количества проводок по регистрам по данным этапам. В следствии чего расчет этапа «ЗаписатьСформированныеДвижения» сократился с 3 ч. 45 мин. до 3 ч. 25 мин.
- Общее время других этапов расчета себестоимости также сократилось. В итоге общее время расчета себестоимости сократилось с 21 ч. 34 мин. до 17 ч. 30 мин.
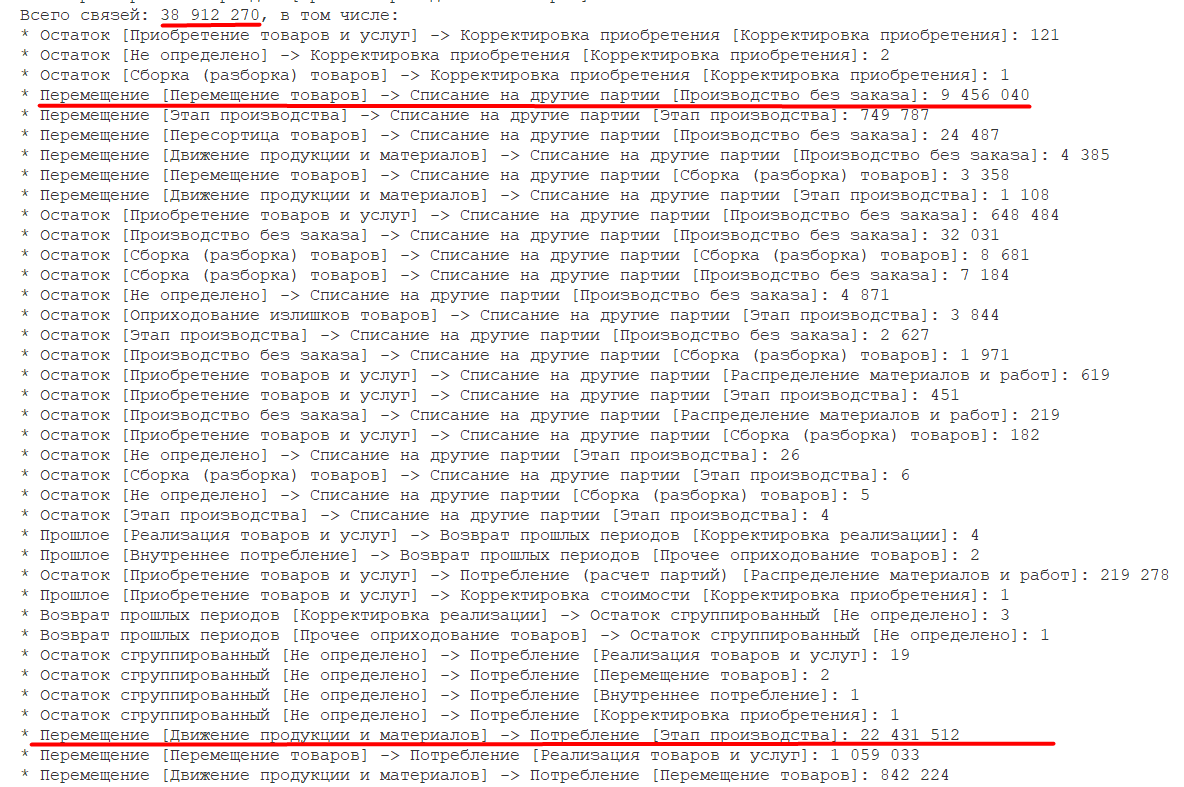
Изменения по количеству связей приведены в таблице ниже:
| Показатель этапа | До оптимизации этапа | После оптимизации этапа |
|---|---|---|
| Количество связей Перемещение товаров → Производство без заказа | 18918759 | 9456040 |
| Количество связей Перемещение товаров → Движение продукции и материалов/Движение продукции и материалов → Этап производства | 47356237 | 22431512 |
| Количество графов для расчета связей | 204 | 80 |
Этап «ЗаписатьСформированныеДвижения»
После проведенных работ по сокращению партий в базе заказчика время этапа «ЗаписатьСформированныеДвижения» все еще оставляло желать лучшего. Поэтому необходимо было выяснить причину долго выполнения этапа и предложить метод оптимизации.
Этап «ЗаписатьСформированныеДвижения» — это важный этап расчета себестоимости, где записываются наборы записей регистров по ранее полученным таблицам движений. В ходе анализа у клиента было выявлено, что данный этап выполняется более 3 часов и является самым длительным этапом расчета.
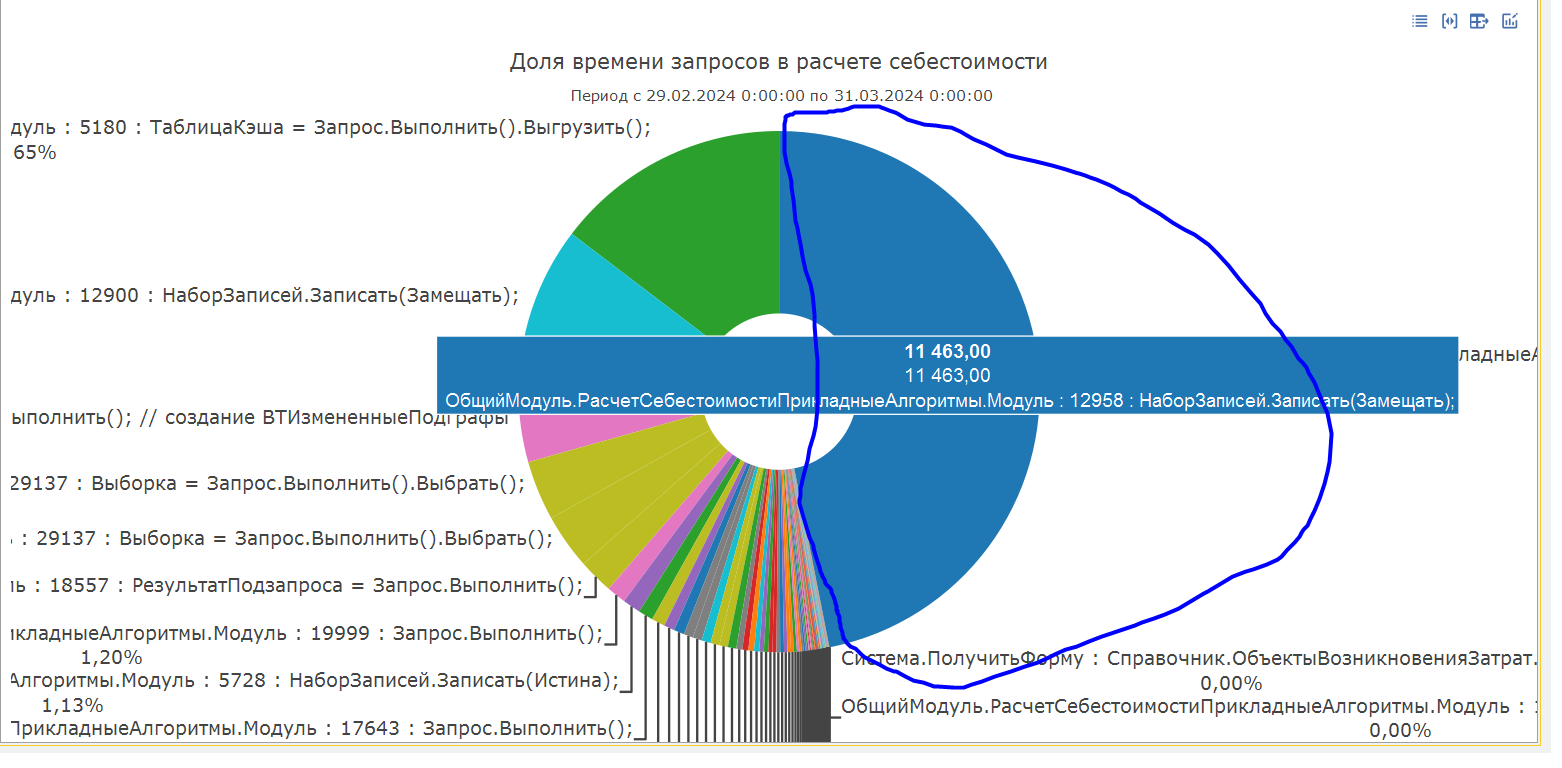
Проведя анализ наиболее часто выполняемых запросов при расчете себестоимости с помощью инструмента «1С‑Рарус: Мониторинг производительности» установлено, что основной процент всех запросов относится к этапу «ЗаписатьСформированныеДвижения» и имеет следующий контекст выполнения:
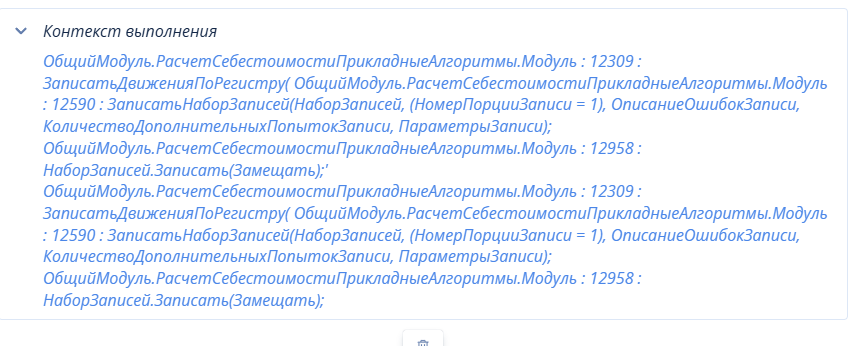
Проведя анализ времени выполнения запросов по убыванию, выявляется следующий список запросов:
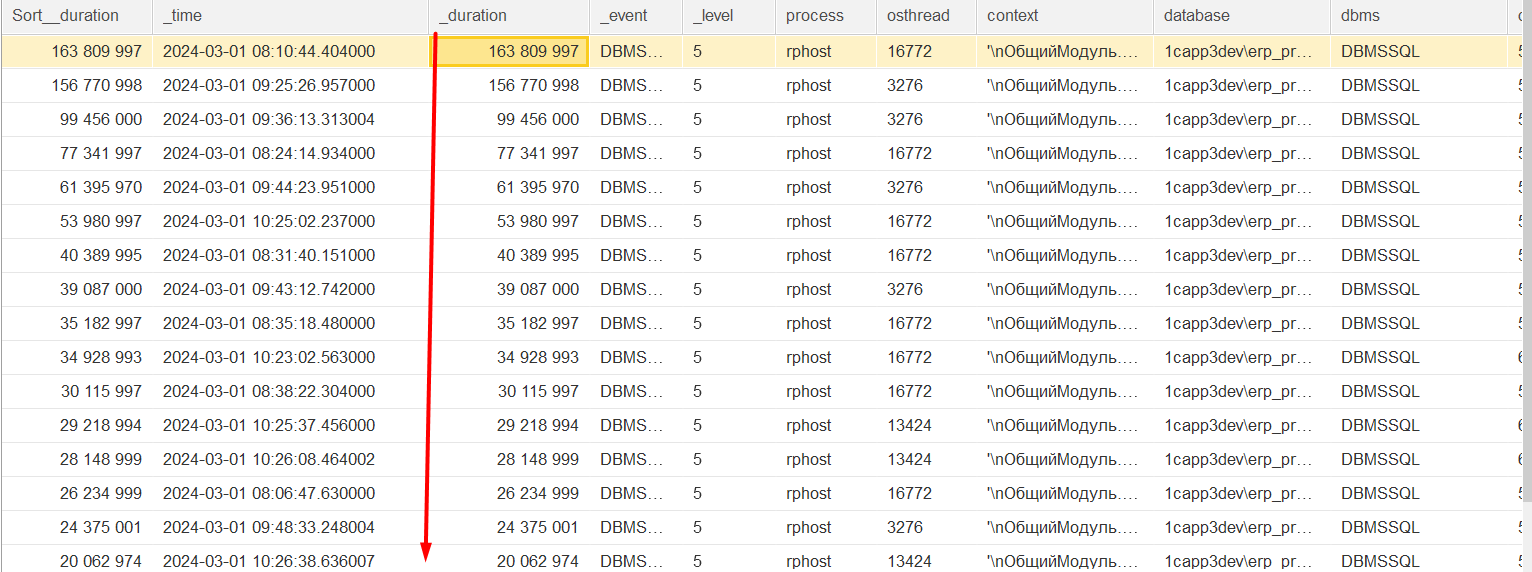
Самое длительное время выполнения запроса около 3 минут, а в массе запросы выполняются не более 10-20 секунд. Данные запросы выполняются последовательно по каждому регистру отдельно, что и приводит к длительному выполнению этапа в целом так как записей по регистрам очень много:

В таком случае, имеет смысл заниматься не оптимизацией данного запроса, а пересмотром логики алгоритма, с целью минимизации количества выполнений данного запроса.
Анализируя типовой код этапа «ЗаписатьСформированныеДвижения» конфигурации УСО 2.5.12.185 (в ERP код аналогичен) можно увидеть, что данные для записи в регистры сначала кэшируются во временной таблице разбиваясь на порции по параметру закрытия месяца «Максимальное количество одновременно выполняемых заданий записи» и только затем пишутся в регистр поочередно:
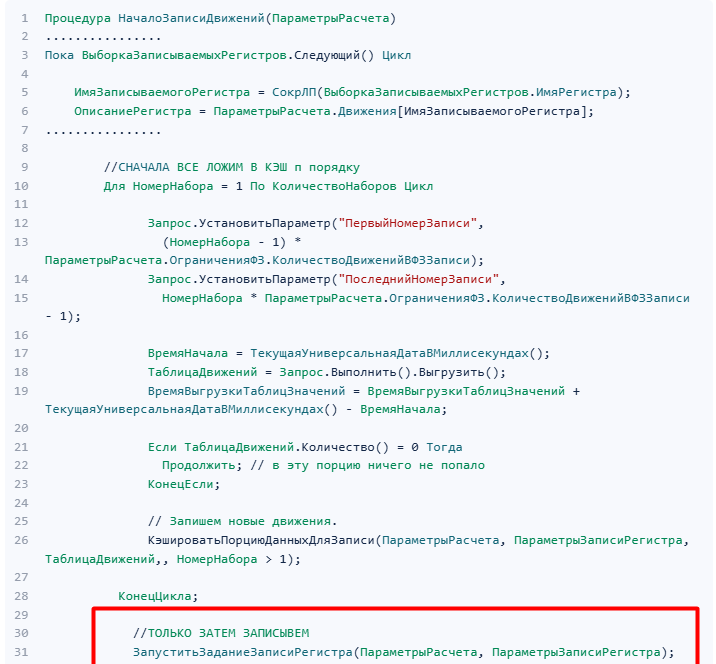
Собственно, в нашем случае, где записей десятки миллионов, поочередная запись порций данных регистров является основной причиной замедления этапа «ЗаписатьСформированныеДвижения» и поэтому для оптимизации данного этапа необходимо было определиться с возможными методами ускорения, о чем поговорим ниже.
Строим гипотезы возможного ускорения этапа «ЗаписатьСформированныеДвижения»
Ускорение этапа нужно реализовывать за счет параллельной записи порций данных по регистрам так, чтобы не было ожиданий на блокировках и взаимоблокировок при формировании параллельной записи данных в разрезе одного регистра.
Гипотеза №1. Изменение параметров закрытия месяца
Для начала было решено попробовать измененить штатные параметры закрытия месяца «Максимальное количество движений в порции данных для записи» и «Максимальное количество одновременно выполняемых потоков расчета партий», чтобы ускорить рассматриваемый этап. Изначальные и измененные в ходе анализа параметры расчета себестоимости представлены на скринах ниже:
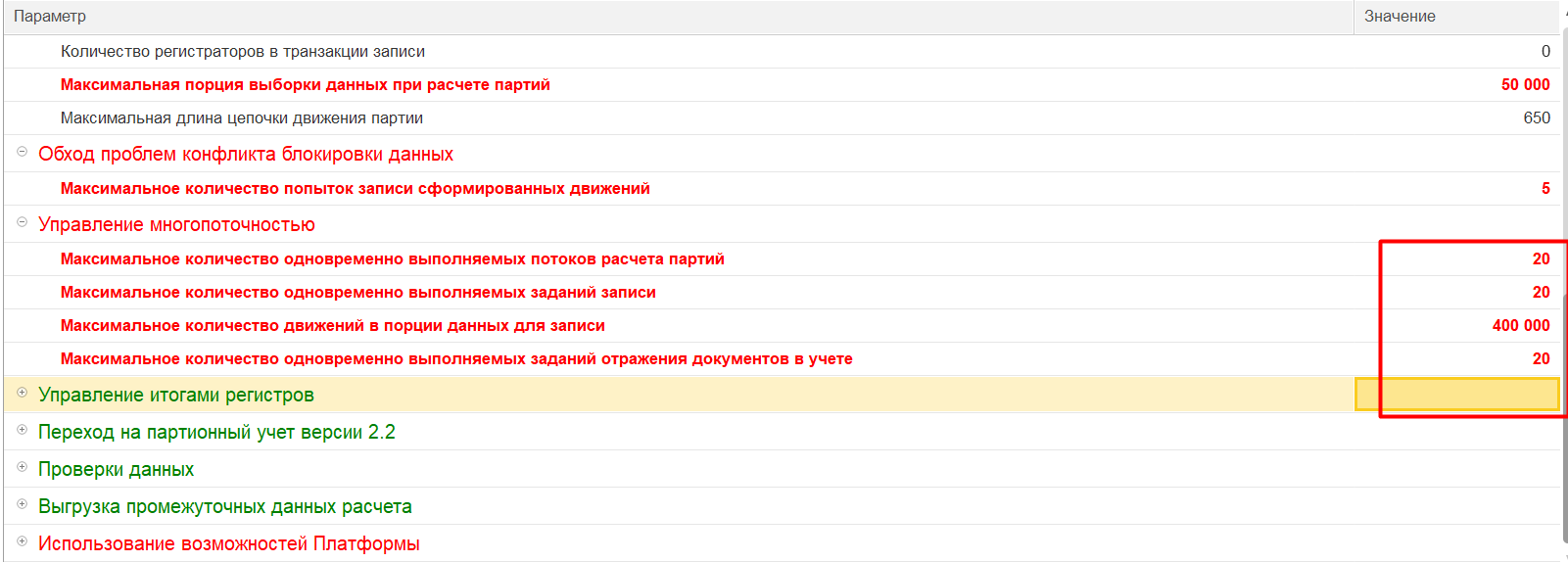
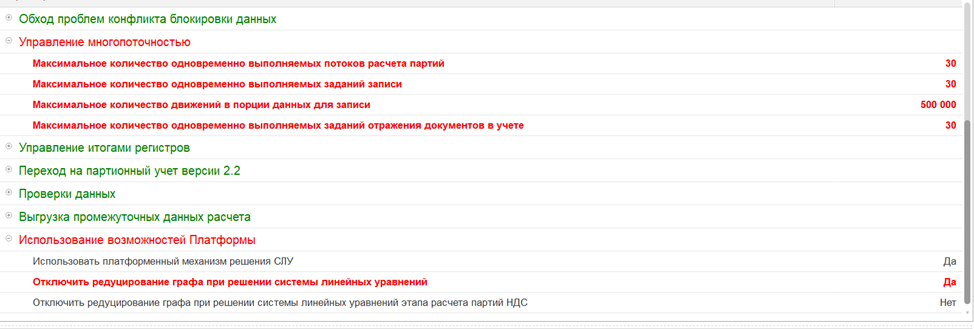
В ходе анализа менялся параметр «Максимальное количество движений в порции данных для записи» и происходили замеры изменения длительности этапов. Изначально значение у заказчика было выставлено 400 000. При увеличении объема движений до 500 000 были зафиксированы небольшие изменения во времени этапа «ЗаписатьСформированныеДвижения» в размере 5–10 минут. Такой подход возможно применить, но прирост будет незначителен.
Также ускорить этап пробовали, устанавливая стандартные параметры «Максимальное количество одновременно выполняемых потоков расчета партий», «Максимальное количество одновременно выполняемых заданий записи», «Максимальное количество одновременно выполняемых заданий отражения документов в учете» в значении 30. При таких значениях время выполнения этапа записи по регистрам по наблюдениям сократилось не более чем на 10 минут, но так как по вышеперечисленным параметрам многопоточности были выставлены более высокие значения, это ожидаемо привело к тому, что серверу СУБД стало не хватать памяти и значительно увеличилось потребление процессорных ресурсов. В итоге, из‑за увеличения нагрузки на оборудование, данные параметры решили установить в значения, которые были изначально у заказчика.
Также для ускорения расчета изменялся параметр «Порог изменения алгоритма расчета», который задает порог сложности СЛАУ (системы линейных алгебраических уравнений), при достижении которого система выбирает более быстрый, но менее точный итерационный метод расчета СЛАУ.
Подробнее в документации к платформе на ИТС: its.1c.ru/db/v8322doc#bookmark:dev:TI000002182.
Выдержка из статьи приведена ниже:

Для примера, при выставленном значении по умолчанию = 10 000:

Расчет себестоимости в целом с учетом уже произведенных оптимизаций составил 17 ч. 30 мин., а при выставлении параметра в 1 000, расчет занял на 30 минут меньше и составил 17 ч. 00 минут. При этом на этап «ЗаписатьСфорированныеДвижения» данные изменения повлияли незначительно, сократив время выполнения с 3 ч. 05 мин. до 2 ч. 50 мин.
Отметим, что при некоторых вариантах систем уравнений, в зависимости от того, как лягут затраты и партии по тому или иному юридическому лицу, применение итерационного алгоритма может замедлить расчет. Однако в данном случае наблюдается небольшое ускорение.
В целом гипотеза изменения штатных параметров расчета себестоимости принесла определенные «плоды», сократив общее время расчета в совокупности на ~40 минут, в свою очередь на требующий оптимизации этап «ЗаписатьСфорированныеДвижения» пришлась практически половина этого времени, то есть ~20 минут.
Такой прирост не мог устроить заказчика, и мы продолжили изыскания дальше, сосредоточившись на сокращении времени выполнения этапа «ЗаписатьСформированныеДвижения».
Гипотеза №2. Разработать механизм параллельной записи порций, определяя несвязанные подграфы в общем графе сформированных движений
Как было выяснено ранее, на этапе «ЗаписатьСформированныеДвижения» конфигурации УСО 2.5.12.185 рассчитанные данные для регистров себестоимости, коими являются регистры накопления «Себестоимость товаров», «Прочие расходы», «Прочие расходы незавершенного производства» и т. д, и о них детально речь пойдет далее, записываются поочередно в регистры согласно параметру расчета «Максимальное количество одновременно выполняемых заданий записи».
Основная мысль была в том, чтобы разработать такой механизм, который позволит рассчитанные движения по регистрам себестоимости писать порциями параллельно в разрезе каждого регистра, формируя отдельные фоновые задания. Для этого определим следующие шаги:
- Определим список регистров накопления, по которым будем разбивать данные на порции.
- Определим, как по рассматриваемым регистрам строится граф сформированных движений.
- Декомпозируем получившиеся графы по регистрам на несвязные подграфы путем написание алгоритма поиска компонентов сильной связности.
- По каждому определенному подграфу формируем отдельный поток на запись порции данных рассматриваемого регистра.
Но для начала немного теории.
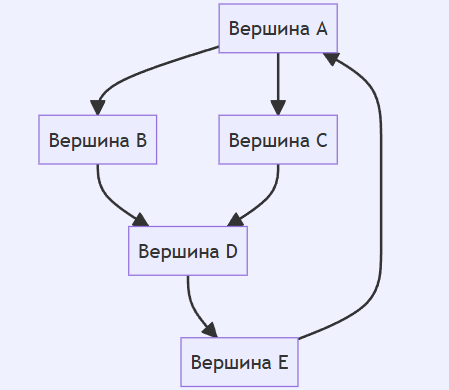
Ориентированный граф (кратко орграф) — (мульти) граф, рёбрам которого присвоено направление. Направленные рёбра именуются также дугами, а в некоторых источниках и просто рёбрами. Граф, ни одному ребру которого не присвоено направление, называется неориентированным графом или неорграфом.
Вот пример ориентированного графа. Ориентированный граф (или направленный граф) состоит из вершин и направленных рёбер, указывающих на одну сторону.
Граф называется связным, если между каждой парой вершин есть путь. От каждой вершины к любой другой вершине должен быть некоторый путь для прохождения. Это называется связностью графа. Граф с несколькими несвязанными вершинами и ребрами называется несвязным.
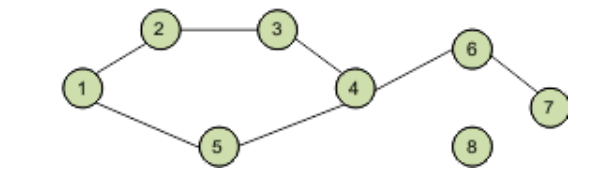
В данном примере существует хотя бы одна вершина, не связанная с другими поэтому данный граф можно считать несвязным.
Ориентированный граф (орграф) называется сильно связным, если любые две его вершины s и t сильно связны, то есть если существует ориентированный путь из s в t и одновременно ориентированный путь из t в s.
Компонентами сильной связности орграфа называются его максимальные по включению сильно связные подграфы.
Областью сильной связности называется множество вершин компонентов сильной связности.
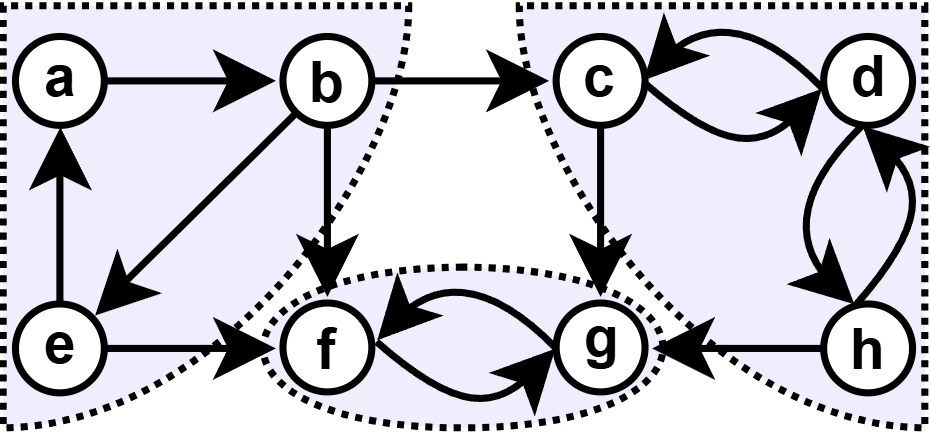
Источник: wikipedia.org
Теперь перейдем к детальному описанию шагов оптимизации этапа «ЗаписатьСформированныеДвижения», которые тезисно были описаны выше.
Определим список регистров накопления, по которым будем разбивать данные на порции
Анализируя протокол расчета себестоимости определим список регистров, по которым было сформировано больше всего записей и которые соответственно напрямую влияют на длительность выполнения этапа записи движений:
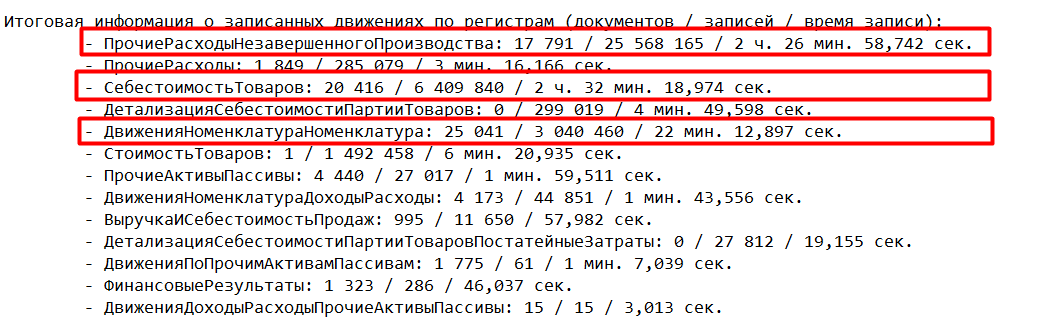
Для начала определим этапы расчета себестоимости, которые формируют записи по рассматриваемым регистрам и визуализируем их через общий граф расчета себестоимости:
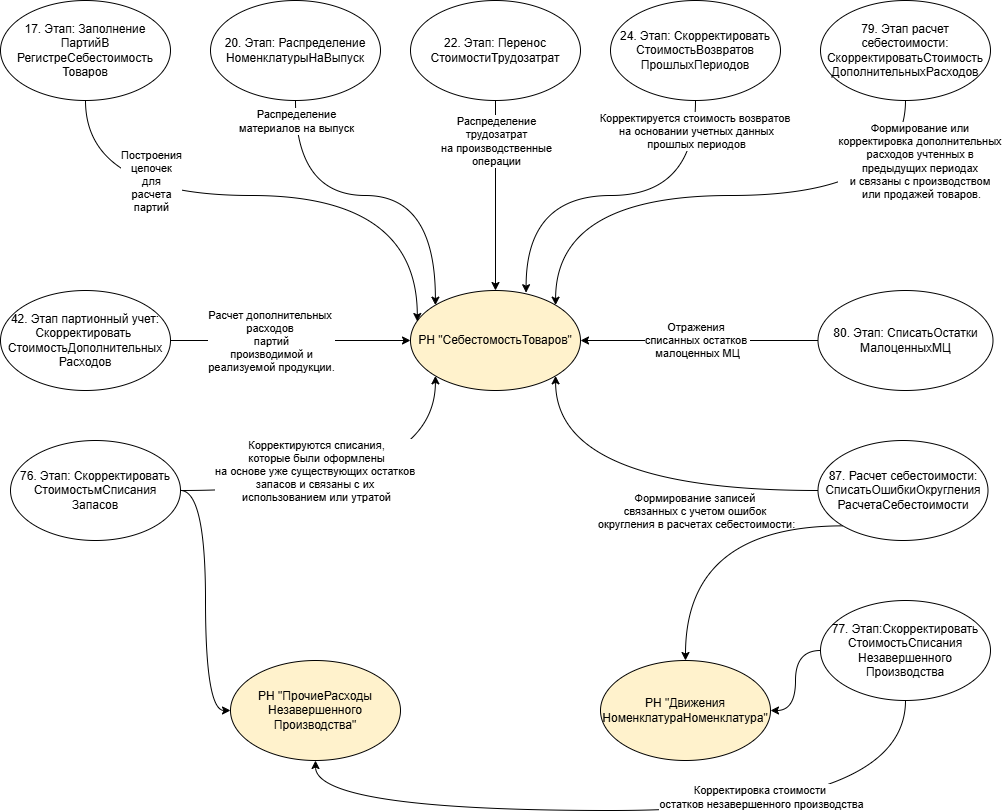
Посмотрим составленный граф процедуры расчета себестоимости и опишем, как формируются данные для этапа «ЗаписатьСформированныеДвижения» по шагам:
- Наборы записей в регистр накопления «СебестоимостьТоваров» формируются на этапах:
- «Партионный учет: ЗаполнениеПартийВРегистреСебестоимостьТоваров»;
- «Партионный учет: РаспределениеНоменклатурыНаВыпуск»;
- «Партионный учет: ПереносСтоимостиТрудозатрат»;
«Расчет себестоимости: СкорректироватьСтоимостьВозвратовПрошлыхПериодов»; - «Партионный учет: СкорректироватьСтоимостьДополнительныхРасходов»;
- «Расчет себестоимости: СкорректироватьСтоимостьСписанияЗапасов»;
- «Расчет себестоимости: СкорректироватьСтоимость Списания НезавершенногоПроизводства»;
- «Расчет себестоимости: Скорректировать СтоимостьДополнительныхРасходов»;
- «Расчет себестоимости: СписатьОстаткиМалоценныхМЦ»;
- «Расчет себестоимости: СписатьОшибкиОкругленияРасчетаСебестоимости»
(что именно происходит на этапах описано в ребрах графа) формируя движения и записывая их в кэш данных «ВТКэшСебестоимостьТоваров».
- Наборы записей в регистр накопления «ПрочиеРасходыНезавершенногоПроизводства» формируются на этапах:
- «Расчет себестоимости: СкорректироватьСтоимостьСписанияЗапасов»;
- «Расчет себестоимости: СкорректироватьСтоимостьСписанияНезавершенногоПроизводства»
формируя движения и записывая их в кэш данных «ВТКэшПрочиеРасходы НезавершенногоПроизводства».
- Данные в регистр накопления «ДвиженияНоменклатураНоменклатура» формируются на этапах:
- «Расчет себестоимости: СкорректироватьСтоимостьСписанияНезавершенногоПроизводства»,
- «Расчет себестоимости: СписатьОшибкиОкругленияРасчетаСебестоимости»
формируя движения и записывая их кэш данных «ВтКэшДвижения НоменклатураНоменклатура».
- На этапе «Партионный учет: ЗаписатьСформированныеДвижения» все данные по списку рассматриваемых регистров уже рассчитаны и хранятся во временных таблицах. Далее по каждому регистру на этом этапе происходит формирования общего набора записей из собранных данных по кэшам — назовем его «граф сформированных движений» и далее более детально его опишем, так как именно его оптимизация по задумке должна ускорить этап формирования движений и, как следствие, в целом операции расчета себестоимости.
Определим структуру регистров, на которых строим граф сформированных движений
Итак, определён список регистров, запись которых мы собрались оптимизировать. Теперь вкратце пройдемся по их структуре, чтобы понимать, как построить граф сформированных движений и понять возможность разбиение его на подграфы для параллельной записи в фоне.
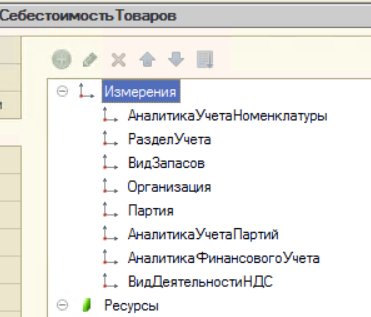
РН «СебестоимостьТоваров»
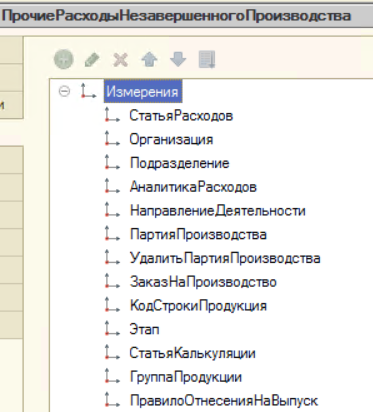
РН «ПрочиеРасходыНезавершенногоПроизводства»
РН «ДвиженияНоменклатураНоменклатура»
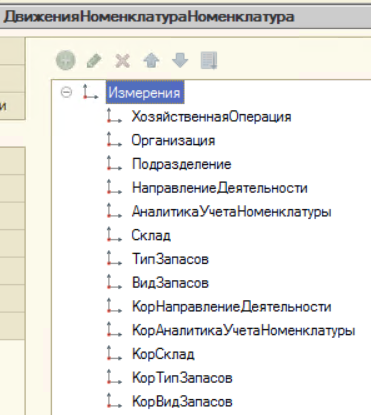
Как строится граф сформированных движений
На каких этапах собираются данные для регистров мы определили выше. Теперь давайте пройдемся по алгоритму формирования записей, которые непосредственно пишутся в регистры и на основании этого визуализируем граф сформированных движений:
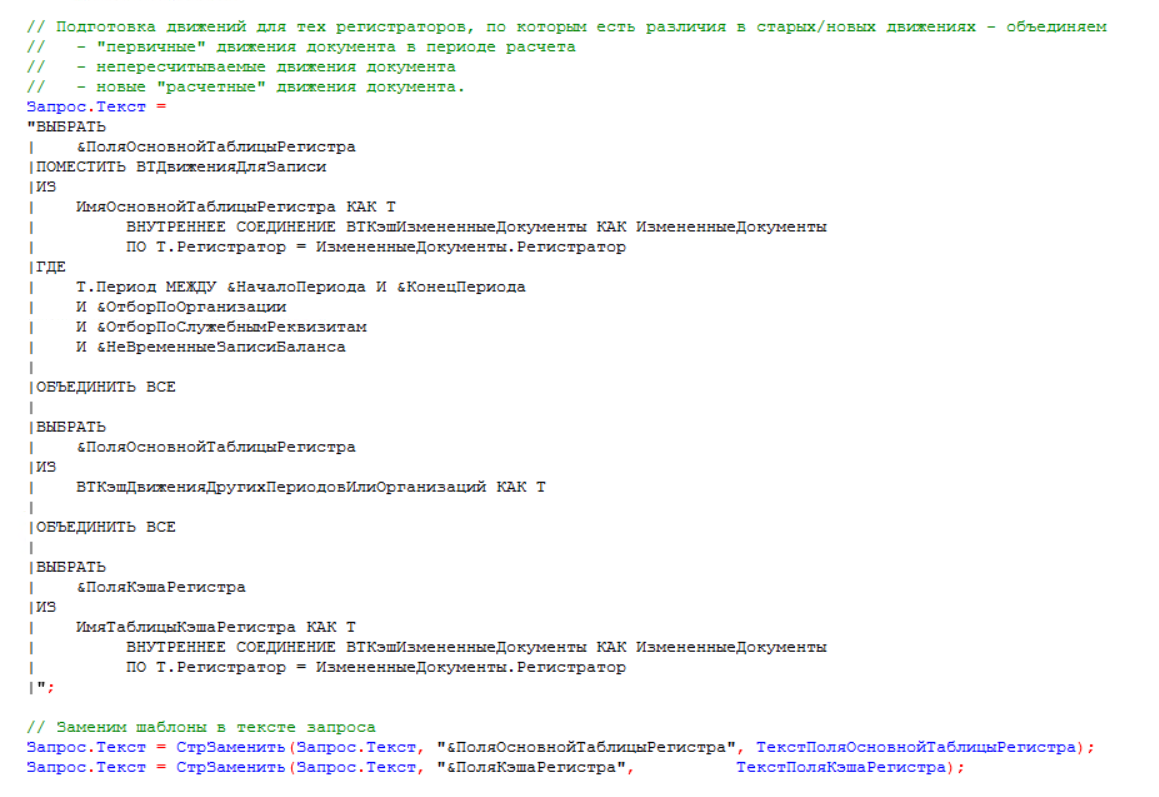
Первым шагом подготавливаются движения для записи по первичным движениям, которые еще не былы расчитаны в себестоимости и для «пересчитываемых» движений — данных, изменившихся в периоде расчета. Все изменения по регистраторам хранятся в кэше «ВтКэшИзмененные Документы». Также данные собираются и из кэша «ВтКэшДвиженияДругихПериодовИлиОрганизаций», где собираются данные, которые не влияют на пересчет себестоимости в результате изменения исходных данных, например, статистические, служебные или специфичные накладные. Все данные помещаются во временную таблицу «ВТДвиженияДляЗаписи». Ниже приведен запрос, в котором собираются исходные данные для записи по регистрам:
Далее, чтобы за один вызов не произвести чтение и запись огромного количества данных, происходит разбиение данных на порции согласно параметра расчета себестоимости «Максимальное количество движений в порции данных для записи», где критерием разбивки выступает количество движений в регистраторе- это происходит в функции «РазделитьВременнуюТаблицуНаПорции», там же и происходит определение максимального количества пакетов, которые пойдут на запись в регистр.
Также можно обратить внимание на параметр «РегистраторыСБольшимиНаборами» — это те регистраторы, которые не помещаются в порции, заданые в параметре «Максимальное количество движений в порции данных для записи», по таким регистраторам разбиение на порции будет происходить в первую очередь. Все данные, распределенные по порциям, аккумулируются во временной таблице «ВтДвиженияДокументов», данные для которой берутся из временной таблицы «ВТДвиженияДляЗаписи», описанной в п. 1. Ниже приведен код разбиения на порции собранных данных для записи:
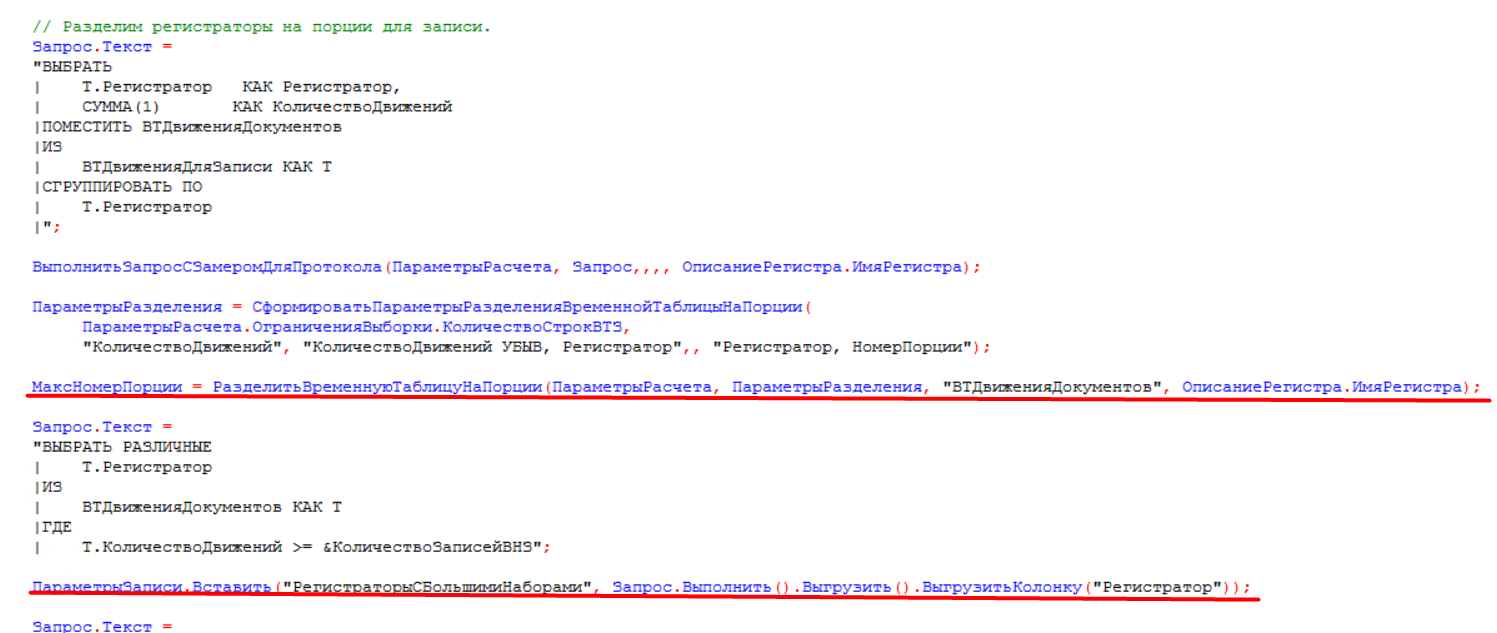
Разбиение временной таблицы «ВТДвижениеДокументов» на порции происходит в функции «РазделитьВременнуюТаблицуНаПроции», куда передаются параметры разделения, по которым порции и будут расчитываться.
В эти параметры входят:
- РазмерПорции — параметр закрытия месяца «Максимальное количество движений в порции данных для записи».
- ИмяПоляВесаСтроки — поле, по которому определяется помещается ли обрабатываемая строка в текущую порцию. В нашем случае — это поле «КоличествоДвижений» временной таблицы «ВТДвиженияДокументов».
Следом в этой процедуре во временной таблице «ВТДвиженияДокументов» добавляетя колонка «НомерПорции», куда номера порции проставляются исходя из того, что при обходе регистраторов с их количеством движений (в коде поле определяется через параметр разделения «ИмяПоляВесаСтроки»), проверяется входит ли текущая строка с ее количеством записей в порцию определенную параметром разделения «РазмерПорции», в свою очередь, если размер порции на текущей строке не превышен, то количество записей обработанных регистраторов помещается в переменную «РазмерТекущейПорции».
И далее, как видно по коду, по условию проверяется, если «РазмерТекущейПорции» больше параметра разделения «РазмерПорции», то определяем новую порцию путем приращение на единцу переменной «НомерПорции» и происходит присваивание номера этой порции текущей строке таблицы «ВТДвиженияДокументов»:
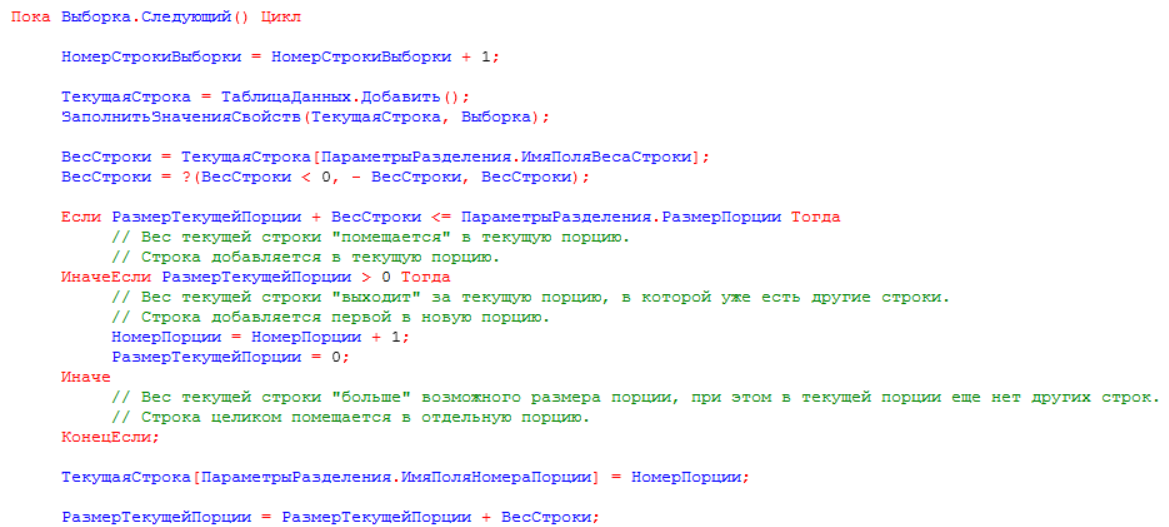
- Последним шагом обходим последовательно порции данных и записываем их в регистр. На скриншоте можно увидеть, что сначала формируется запрос, где есть условие отбора по номеру порции, а затем в цикле обходим все номера порций данных и передаем их в параметр запроса. На каждую порцию делаем выборку данных по запросу и записываем их:
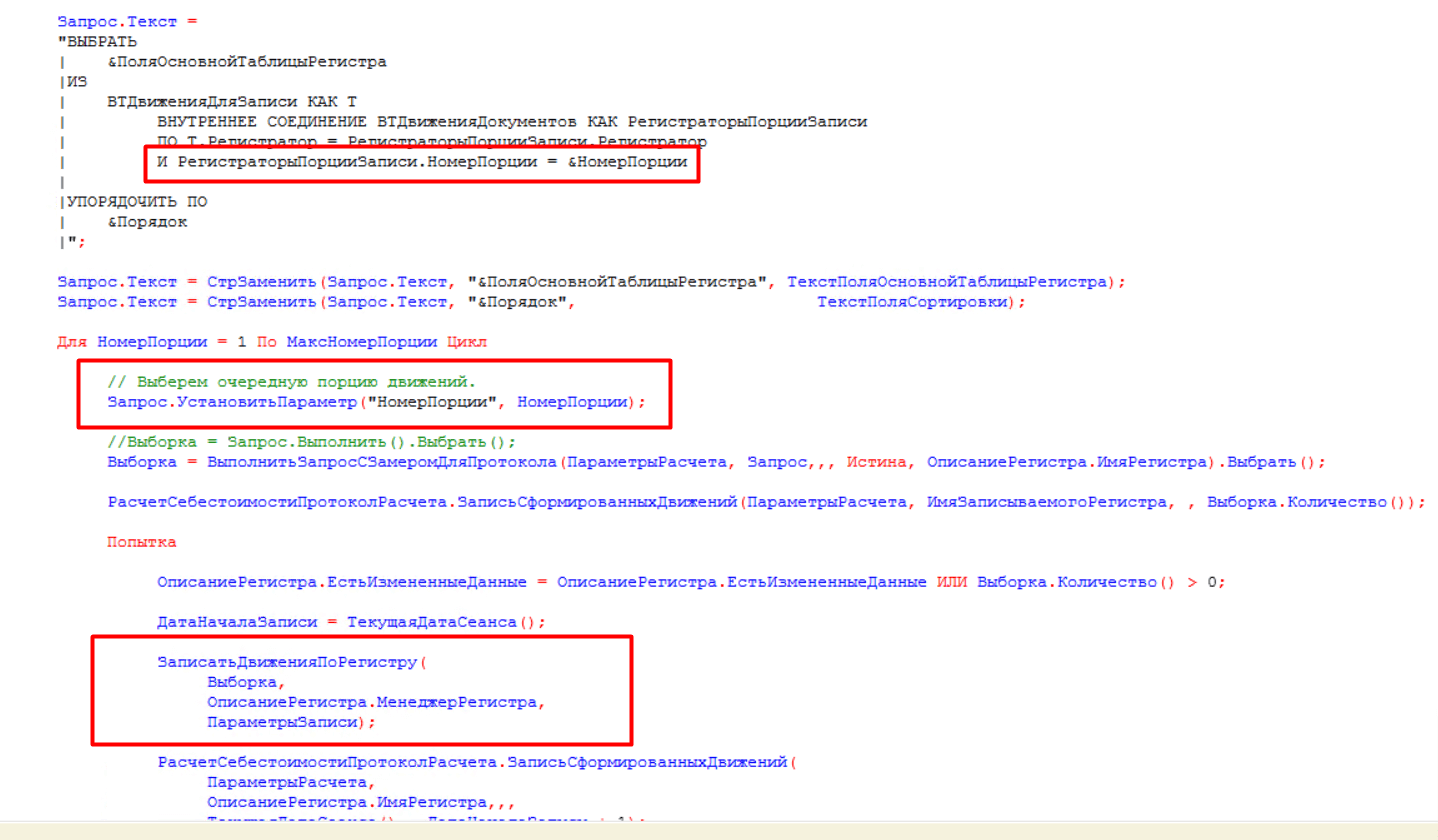
На момент оптимизации этапа «ЗаписатьСформированныеДвижения» визуализация графа записанных движений по регистрам выглядела примерно так:
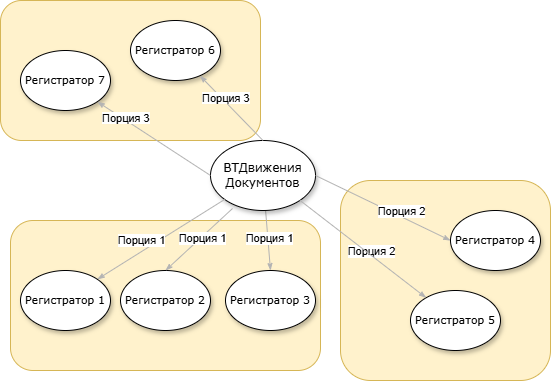
Оптимизация графа сформированных движений и определение логики параллельной записи порций
Первое, что нужно сделать для оптимизации этапа, это определить критерии, по которым нужно формировать параллельные порции для записи в регистры. В нашем случае критериями будут выступать следующие пункты:
- Размер порции будет примерно соответствовать ограничению на максимальный размер таблицы значений.
- Один документ не может присутствовать в нескольких порциях — иначе одно задание записи затрет результаты другого.
- «Большие» документы пишутся по одному документу на порцию — считаем, что движения документа всегда «поместятся» в таблицу значений.
- В одну порцию кладутся все взаимосвязанные регистраторы по пересекающимся аналитикам, которые для каждого регистра определяются отдельно (например для РН «Себестоимость товаров» это будет аналитика учета номенклатуры).
При таком делении можем записывать движения одного регистра несколькими потоками, не боясь возможных блокировок, т. к. мы изначально разделили записи движений так, чтобы их аналитики не пересекались.
Далее для реализации функционала параллельной записи по порциям перейдем к нашему графу сформированных движений. Для нахождения несвязанных подграфов в графе с использованием компонент сильной связи нужно следовать алгоритму, который определяет все компоненты сильной связи в графе сформированных движений. Затем каждую из этих компонент можно рассматривать как подграф, состоящий из вершин, которые взаимно достижимы. Далее уже на каждый определенный подграф нужно будет сформировать порции данных для записи их в фоновых заданиях.
Для начала визуализируем, как должен выглядеть сильно связный подграф для реализации нашего функционала на примере РН «Себестоимость товаров»:
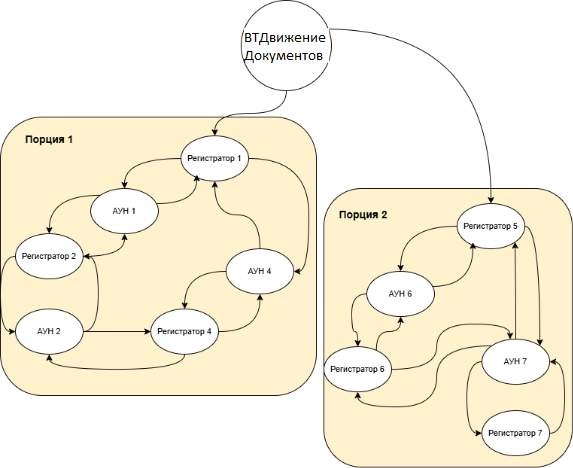
Далее необходимо приступить к реализации алгоритма разбиение графа на несвязанные подграфы, используя поиск компонентов сильной связи.
За основу решения задачи взяли алгоритм обхода графа в глубину, максимально упростив его. В итоге для решения задачи были определены следующие шаги:
- Для разбиения графа сформированных движений на подграфы для каждого рассматриваемого регистра была определена аналитика связности (измерения регистров), по которым на следующих шагах были определены компоненты связи данных:
- Для РН «СебестоимостьТоваров» аналитика связности — измерение «АналитикаУчетаНоменклатуры» + Регистратор.
- Для РН «ПрочиеРасходыНезавершенногоПроизводства» аналитика связности — измерение «СтатьяРасходов» + Регистратор.
- Для РН «ДвиженияНоменклатураНоменклатура» аналитика связности — измерение «АналитикаУчетаНоменклатуры» + Регистратор.
В коде модуля «РасчетСебестоимостиПрикладныеАлгоритмы» в процедуре «НачатьЗаписьДвижений» проверяем имя записываемых регистров, и если это регистры, которые мы определили выше, а количество записей больше параметра «Максимальное количество движений в порции данных для записи» (если равно или меньше параметра все уместиться в одной порции), то мы реализуем распараллеливание наборов записей на потоки:
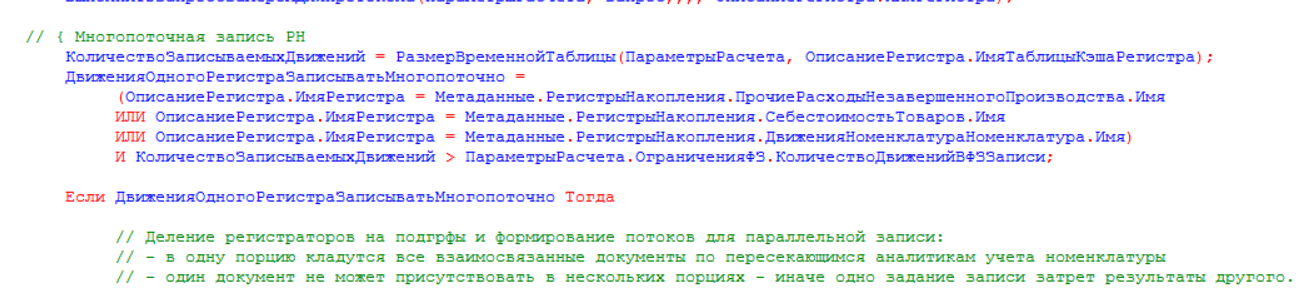
- Добавим в граф сформированных движений, алгоритм которого описывался выше, данные по тем аналитикам, которые были определены в п.1 данного списка. По этим аналитикам в дальнейшем будет происходить разделение графа на подграфы, путем поиска компонентов сильной связности. Добавим номера порций в ребра подграфа (изначально везде 0), чтобы в дальнейшем нумеровать сформированные для выполнения параллельной записи подграфы, а также выделим по каждому регистратору количество записей для контроля размера записываемой порции данных согласно параметра закрытия месяца «Максимальное количество движений в порции данных для записи»:
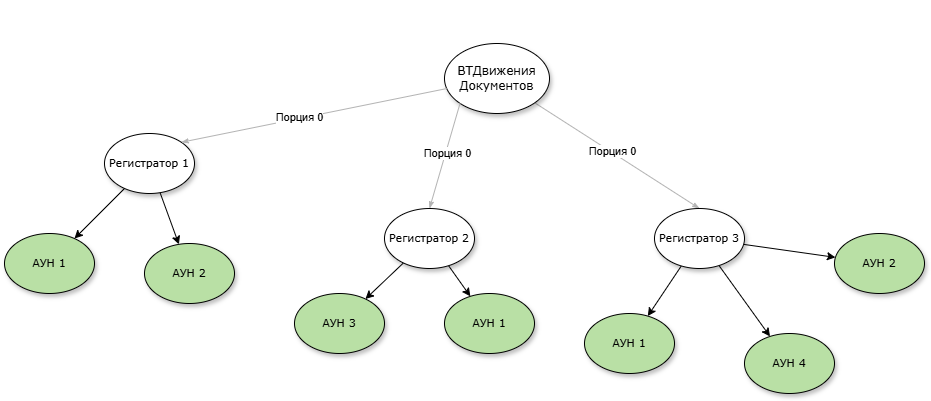 Пример модификации графа сформированных движений для РН «СебестоимостьТоваров» путем добавление аналитики связанности.
Пример модификации графа сформированных движений для РН «СебестоимостьТоваров» путем добавление аналитики связанности.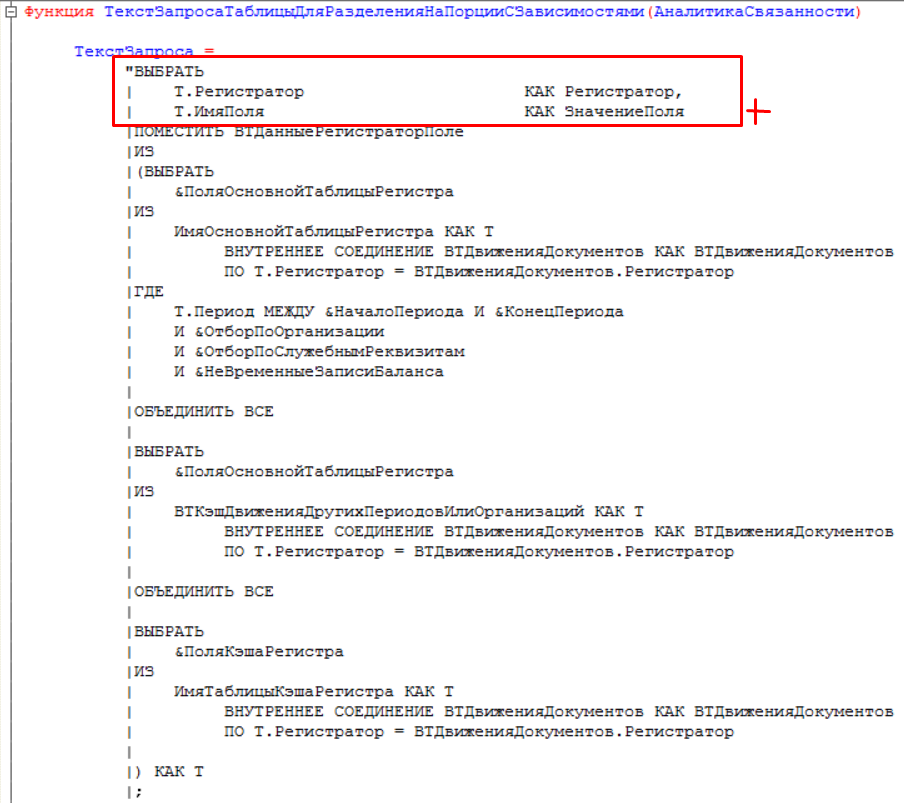 Модифицируем типовой граф сформированных движений, добавляя вершины аналитик (значение поля), по которым будем стараться найти компоненты связности для построения подграфов. Данные нужных аналитик мы получаем из временных таблицы, где в параметр &ПоляОсновнойТаблицыРегистра передаются все поля рассматриваемого регистра.
Модифицируем типовой граф сформированных движений, добавляя вершины аналитик (значение поля), по которым будем стараться найти компоненты связности для построения подграфов. Данные нужных аналитик мы получаем из временных таблицы, где в параметр &ПоляОсновнойТаблицыРегистра передаются все поля рассматриваемого регистра. Добавляем номера порции в ребра модифицированного графа. В терминах 1С добавляем новое поле «Номер порции» во временную таблицу «ВТДанныеРегистраторПоле», в дальнейшей выборке получим таблицу значений, где будем эти номера порций проставлять согласно алгоритма поиска компонентов связности.
Добавляем номера порции в ребра модифицированного графа. В терминах 1С добавляем новое поле «Номер порции» во временную таблицу «ВТДанныеРегистраторПоле», в дальнейшей выборке получим таблицу значений, где будем эти номера порций проставлять согласно алгоритма поиска компонентов связности.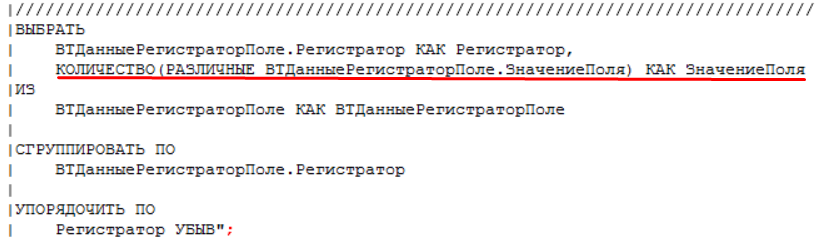 Определяем количество записей по каждому регистратору, для того чтобы размер порций данных не превышал параметра «Максимальное количество движений в порции данных для записи».
Определяем количество записей по каждому регистратору, для того чтобы размер порций данных не превышал параметра «Максимальное количество движений в порции данных для записи». - Далее по данным модифицированного графа сформированных движений выделяем две таблицы:
- РегистраторыНаРаспределениеПоПорциям — собственно это и есть модифицированный граф с информацией о номерах порций в ребрах, в котором осуществляется поиск подграфов с компонентами сильной связности и по найденным подграфам будут проставляться номера порции данных на запись. Назовем его таблица поиска.
- РегистраторыПоКоличествуДанныхАналитики — таблица регистраторов с количеством уникальных записей аналитики связности. Смысл данной таблицы — первичный обход регистраторов для осуществления поиска компонентов сильной связности в таблице поиска, а также контроль размера определяемых порций по параметру «Максимальное количество движений в порции данных для записи»:

Ниже проиллюстрируем механизм работы поиска компонентов связности, который выполняется в процедуре «РазбитьНаПодграфыСЗависимостямиПоАналитикам». Код процедуры можно скачать для изучения:
 Пример кода процедуры «РазбитьНаПодграфыСЗависимостямиПоАналитикам»25.12.2024 TXT, 6.55 КБ
Пример кода процедуры «РазбитьНаПодграфыСЗависимостямиПоАналитикам»25.12.2024 TXT, 6.55 КБАлгоритм производит заполнение во всех строках таблицы поиска значений колонки «НомерПорции».
Заполнение производится с учетом поиска взаимосвязей по переданной аналитике связности среди всех документов, то есть, например, для РН «СебестоимостьТоваров» аналитикой связности является измерение «АналитикаУчетаНоменклатуры» и в одну порцию попадут не только все регистраторы, у которых в табличных частях есть строки с определенной аналитикой учета номенклатуры, но и другие регистраторы, у которых в составе табличных частей есть аналогичные аналитики, если эти аналитики участвуют в табличных частях связанных документов-регистраторов.
Проилюстрируем по шагам работу алгоритма на примере поиска компонентов сильной связности в графе для РН «СебестоимостьТоваров»:
- В модифицированном графе последовательно обходим вершины с регистраторами и получаем по ним аналитики связности:
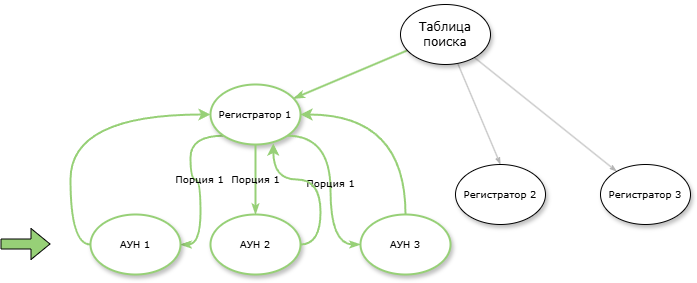

Обходим вершины с регистраторами и определяем получаемые аналитики для следующего обхода (в нашем случае АУН).
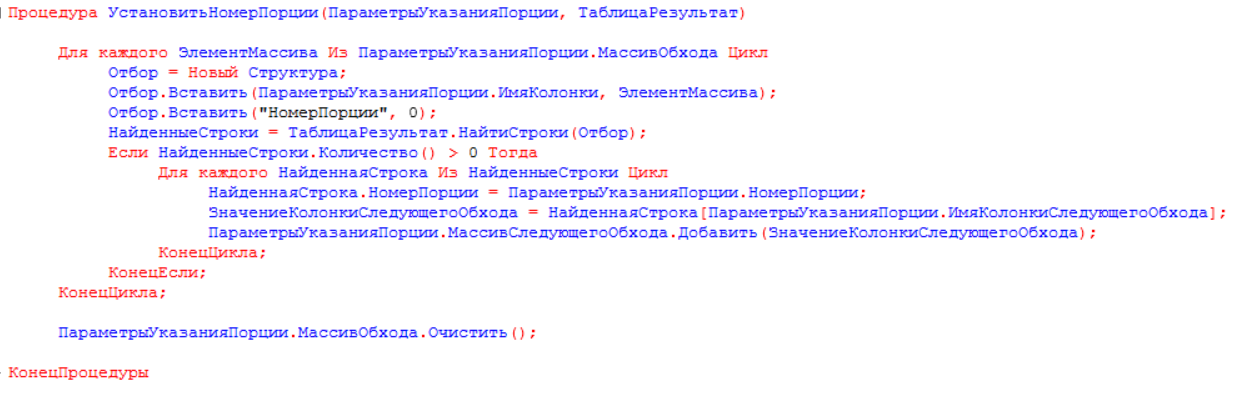
Устанавливаем номер порции по переданному массиву обхода (регистраторы) и заполняем значения последующего обхода (АУНы преданного регистратора). По полученным аналитикам продолжаем определять компоненты связности для графа.
- Далее обходим полученные аналитики связности из шага 1 и уже по ним ищем связанные регистраторы. Проставляем по ним номера порций, там самым формируя подграф с компонентами сильной связи:
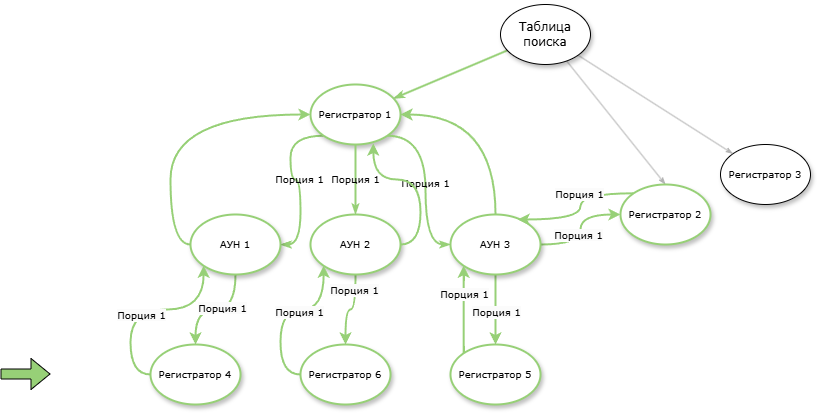

Устанавливаем номер порции по переданному массиву обхода (АУН по регистраторам) и заполняем значения последующего обхода (все связанные регистраторы по АУН). Таким образом проставляя номера порций образуем подграф с компонентами сильной связи (все с друг другом связанно).
Повторяя шаги 1 и 2 для вершин с данными регистраторов и нумеруя порции в таблице поиска мы получаем нужные нам подграфы с компонентами сильной связности.
Тут следует сделать небольшое отступление по теме аналитки связностей. На нашем примере для поиска подграфов с компонентами сильной связности мы использовали в дополнение к регистратору в качестве аналитки одно измерение — АУН. Это было сделано с целью упрощения изложения материала, но следует также сказать, что для поиска подграфов может использоваться не только одна аналитика — можно расширять комбинации аналитик для поиска связей.
Например, в ходе текущих работ для поиска подграфов для РН «Себестоимость товаров» также были использованы аналитики Регистратор + Организация + АУН, Регистратор + АУН + АналитикаПартийУчета, но результат поиска по ним не отличался от поиска по рассматриваемой в статье аналитики связности Регистратор + АУН. Но так получилось для конкретной базы, а в вашем случае использование нескольких аналитик связей для поиска подграфов с компонентами сильной связности может быть намного эффективней.
- По уже опредленным подграфам формируем во временной таблице «ВТРаспределенныеДокументыПоПорциям» стеки с порциями регистраторов и передаем в основной код процедуры записи данных в регистры, но запуская запись фоновых заданий не последовательно, а параллельно:
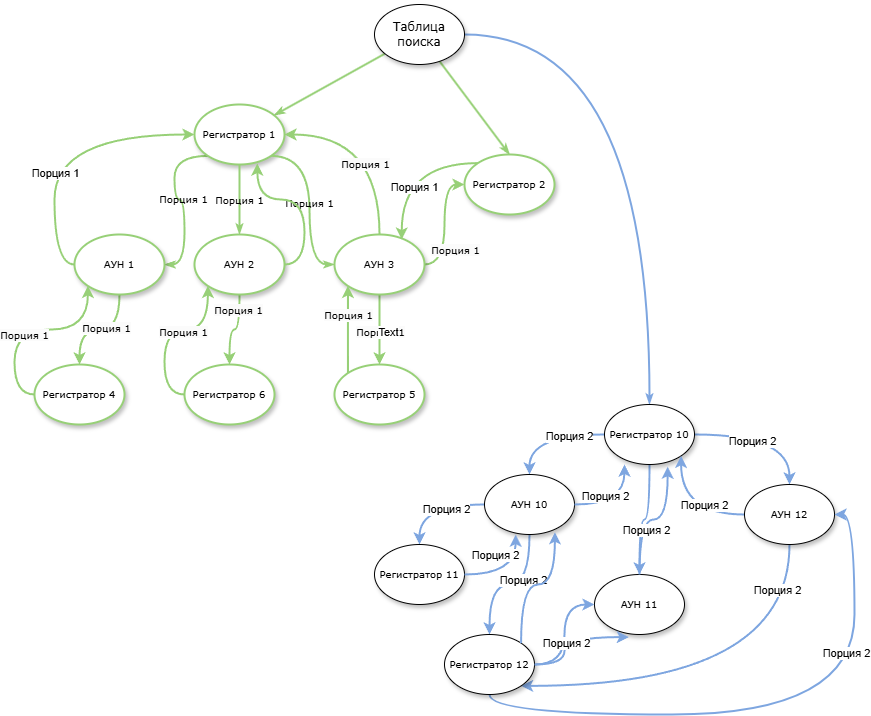 Формирование подграфов с компонентами сильной связности.
Формирование подграфов с компонентами сильной связности.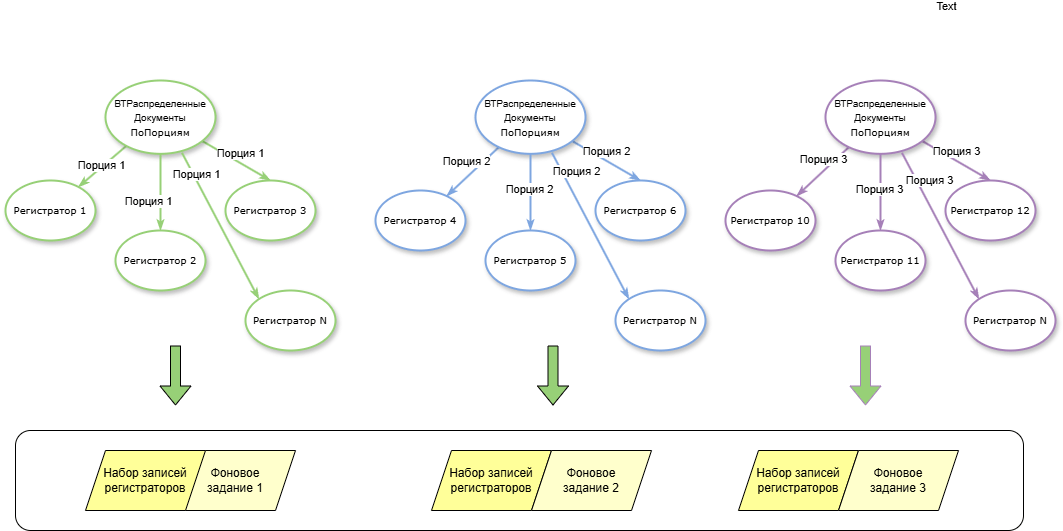 Помещение регистраторов в стеки для формирование итоговых наборов движений и их записи в свои регистры.
Помещение регистраторов в стеки для формирование итоговых наборов движений и их записи в свои регистры. Из таблицы поиска с распределенными номерами порций, выделяем регистраторы и помещаем их во временную таблицу для дальнейшего использования в типовом алгоритме записи движений по регистрам.
Из таблицы поиска с распределенными номерами порций, выделяем регистраторы и помещаем их во временную таблицу для дальнейшего использования в типовом алгоритме записи движений по регистрам.
- В модифицированном графе последовательно обходим вершины с регистраторами и получаем по ним аналитики связности:
В итоге реализации описанного алгоритма для выбранных РН мы получили следующие результаты разбиения общего графа сформированных движений на подграфы и формирование порций записей:
| Имя регистра | Всего записей | Количество записей порция 1 |
Количество записей порция 2 |
|---|---|---|---|
| РН «Себестоимость товаров» | 28 863 468 | 28 863 468 | 0 |
| РН «Прочие расходы незавершенного производства» | 25 253 780 | 25 253 780 | 0 |
| РН «Движения Номенклатура — Номенклатура» | 15 646 256 | 15 128 641 | 517615 |
Как видно из таблицы на подграфы с компонентами сильной связи удалось разбить только РН «Движения Номенклатура — Номенклатура», но даже в этом случае количество данных второй порции оказалось настолько мало, что в целом таким результатом можно принебречь.
Данная гипотеза в рамках исследуемой базы можно сказать провалилась, так как все аналитики по документам оказались связаны с друг с другом и разбиение на подграфы не дало результата, а общее время расчета себестоимости стало даже больше.
Гипотеза №3. Альтернативный механизм параллельной записи порций или можно ли параллельно записывать порции данных по регистраторам без учета связанности?
Этап «ЗаписатьСформированныеДвижения» было решено оптимизировать путем доработки метода записи сформированных порций данных для типового графа сформированных движений (алгоритм формирования графа описан в этом разделе). Используя реализованный типовой функционал порционного разбиения данных по регистраторам с последовательной записью, была сделана доработка данного функционал для «проблемных» регистров, которая заключалась в параллельной записи уже сформированых порций данных с учетом решения проблемы возможных ожиданий на блокировках при оперативной работе пользователей в базе.
Размер порций также было решено контролировать параметром закрытия месяца «Максимальное количество движений в порции данных для записи».
В данном алгоритме для оптимизации этапа «ЗаписатьСформированныеДвижения» необходимо было соблюсти следующие условия:
- Размер порции будет примерно соответствовать ограничению на максимальный размер таблицы значений.
- Один документ не может присутствовать в нескольких порциях — иначе одно задание записи затрет результаты другого.
- «Большие» документы пишутся по одному документу на порцию — считаем, что движения документа всегда «поместятся» в порцию.
- Расчет себестоимости должен быть завершен, чтобы запись в регистры не затирала данные рассчитываемых данных в других этапах.
- При оперативной работе пользователей и в случае пересечения их данных с записываемыми данными порции, если случаются «ожидания на блокировках» и какая либо порция данных не записалась, то такие данных «откладывать» в отдельную структуру и затем заново перезаписывать отдельным потоком, чтобы сохранялась целостность начальных данных всех порций.
Что касается пунктов 1–3, то они уже реализованы в типовом функционале формирования графа сформированных движений и разбиение его данных на порции. Сам принцип формирования графа также описан выше, поэтому здесь подробно мы на нём останавливаться не будем.
Что касается пункта 4, то отвечая на вопрос почему можно писать одну порцию, не дожидаясь записи предыдущей можно сказать, что этап «ЗаписатьСформированныеДвижения» является одним из последних этапов в структуре расчета себестоимости и к моменту записи данных все данные для регистраторов уже были рассчитаны на прошлых этапах, поэтому в контексте процедуры расчета себестоимости, блокировок мы не встретим и параллельные записи не перезатрут данные друг друга. Также следует упомянуть, что так как расчет себестоимости уже произведен, то порядок записи регистраторов не имеет значения.
Обратная ситуация для пункта 5 списка относительно 4 пункта. То есть при оперативной работе пользователей с записями регистра, есть вероятность пересечения данных с записями порций данных выполняемых на этапе «ЗаписатьСформированныеДвижения», что может привести к ожиданиям на блокировках. И в таких случаях порции данных, которые не были записаны по истечению таймаута на блокировках, следует отдельно «откладывать» в определенную структуру и затем записывать их отложенно.
После определения всех условий для реализации алгоритма параллельной записи данных, распишем более подробно, что именно было сделано.
- В процедуре «НачалоЗаписиДвижений» модуля «РасчетСебестоимостиПрикладныеАлгоритмы» для начала добавляем условия по определению РН, где будет происходить запись данных этого регистра по потокам. Количество записей в порции определяется согласно параметру «Максимальное количество движений в порции данных для записи», а количество одновременно запущенных фоновых заданий определяется согласно параметру «Максимальное количество фоновых заданий в записи». Также здесь определяем параметры записи порций, а именно «рарОшибкаЗаписиНабора» будет информировать, что запись текущей порции завершилась по каким-либо причинам с ошибкой, а параметр «рарСоответствиеИмениРегистраПоИДКэша» хранит в себе идентификатор расчета «упавшей» порции записи, далее по этим идентификаторам и будет происходить «дозапись» порций отдельным потоком:
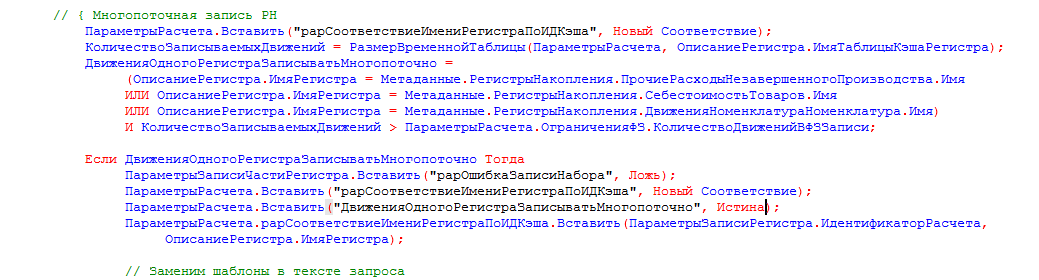
- После того как типовым кодом данные графа сформированных движений поделены на порции и их данные записаны в кэше, вызывается процедура «ЗапуститьЗаданиеЗаписиРегистра», где уже проверяется запись для какого именно РН происходит, и если это движение должно быть многопоточным, мы согласно параметрам «Максимальное количество движений в порции данных для записи» и «Максимальное количество фоновых заданий в записи» высчитываем количество порций в потоке и количество одновременно запущенных фоновых заданий на запись. Также, чтобы максимально снизить риск возникновения блокировки ожидания, мы увеличиваем в 20 раз количество попыток записи. С такими вводными количество блокировок в исследуемой базе было сведено к минимуму:
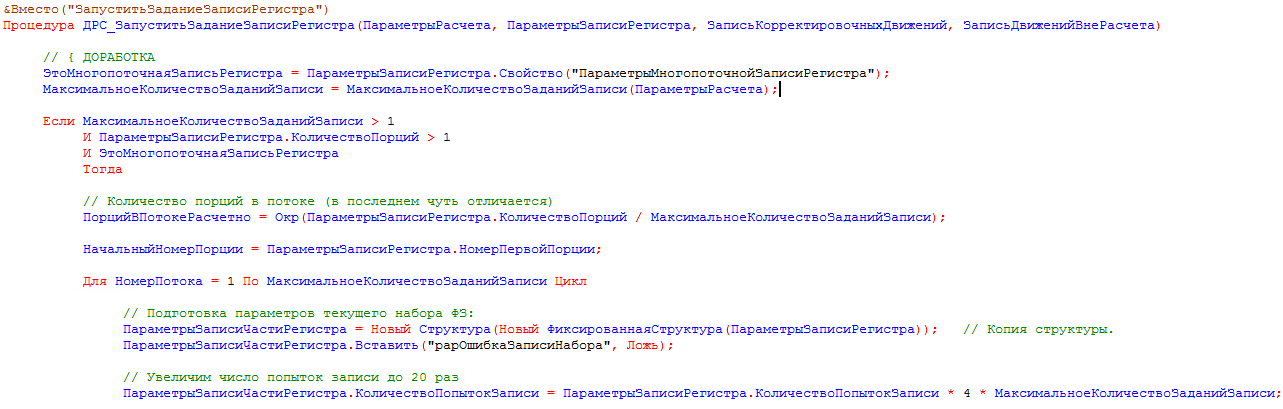 Определяем количество заданий на запись и вводим понятие «Номер потока», которое будет формировать ключ запущенного фонового задания. Также увеличиваем количество попыток записей в случае какой-либо ошибки.
Определяем количество заданий на запись и вводим понятие «Номер потока», которое будет формировать ключ запущенного фонового задания. Также увеличиваем количество попыток записей в случае какой-либо ошибки. Рассчитываем количества записей и количество порций, которые будут писаться в заданиях.
Рассчитываем количества записей и количество порций, которые будут писаться в заданиях.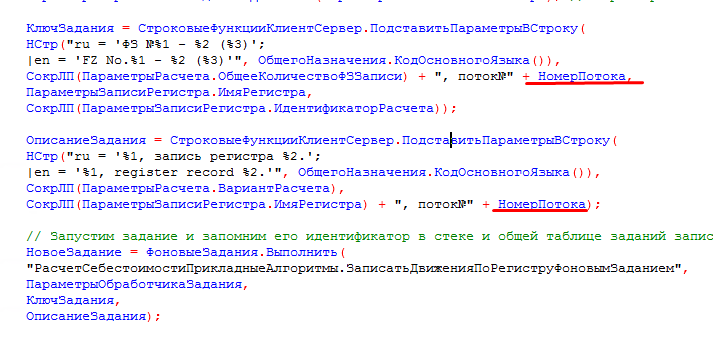 Формируем фоновые задания записи по регистрам согласно рассчитанным номерам потока.
Формируем фоновые задания записи по регистрам согласно рассчитанным номерам потока. - При записи порций данных регистра в процедуре «ЗаписатьНаборЗаписей» данные в случае ошибки пытаются записаться столько раз, сколько передано в параметре «КоличествоПопытокЗаписи», и только если запись не удалась на последней попытке, то в свойство параметров записи «рарОшибкаЗаписиНабора» передается значение «Истина» — это означает, что в процедуре «ЗаписатьДвиженияПоРегистраторуФоновымЗаданием» не будет произведена очистка кэша данной порции:
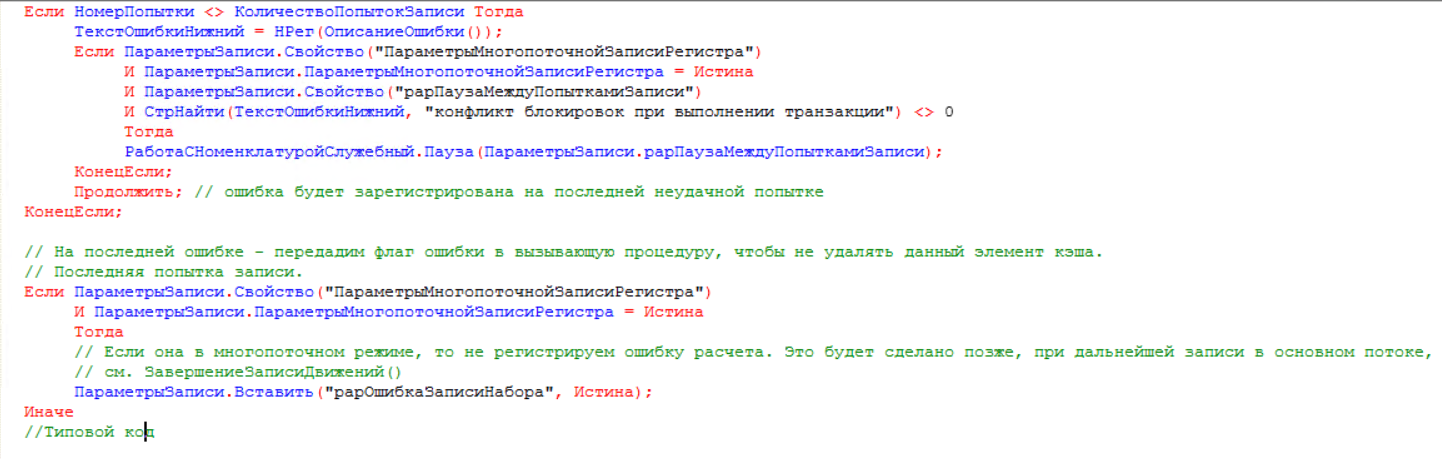
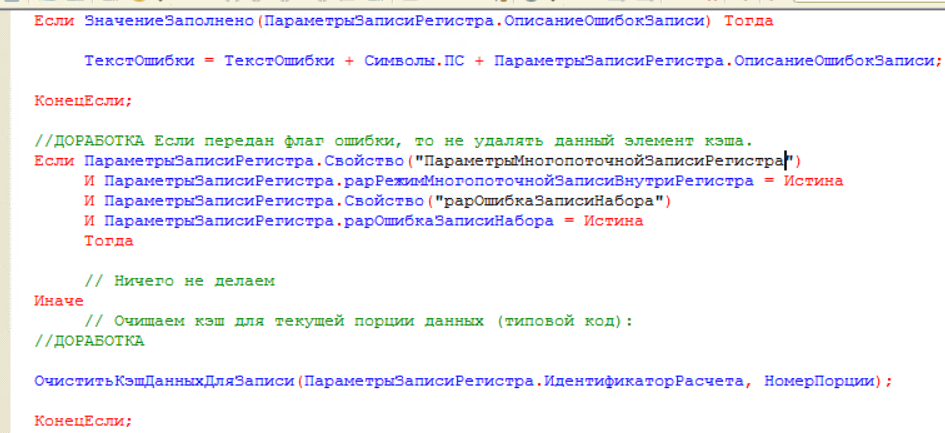
- После записи порции данных регистра вызов возвращается в процедуру «ЗаписатьДвиженияПоРегистраторуФоновымЗаданием», где проверяется успешность записи. Если параметр записи «рарОшибкаЗаписиНабора» в значении «Истина», то значит произошла ошибка записи и мы в этом случае текущую порцию не очищаем из кэша данных, а сохраняем для повторного запуска другим фоновым заданием:
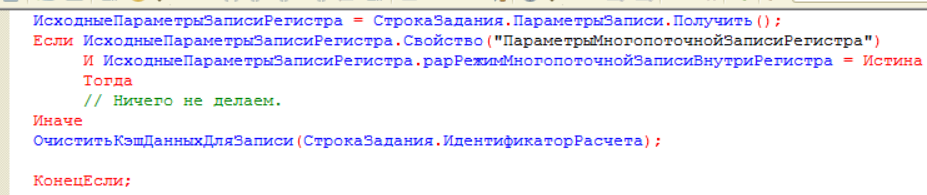
- И еще одна проверка осуществляется в процедуре «ОжидатьЗавершенияФоновогоЗаданияЗаписи», где отдельным фоновым заданием мониторится успешность выполнения записи данных в фоне. В типовом коде при ошибке записи очищаются данные порции кэша, в нашем варианте проверяем фоновое задание на ошибку записи, и в случае ошибки кэш не очищаем, а идем дальше. Очистка кэша происходит после выполнения отдельного фонового задания по «проблемным» порциям:
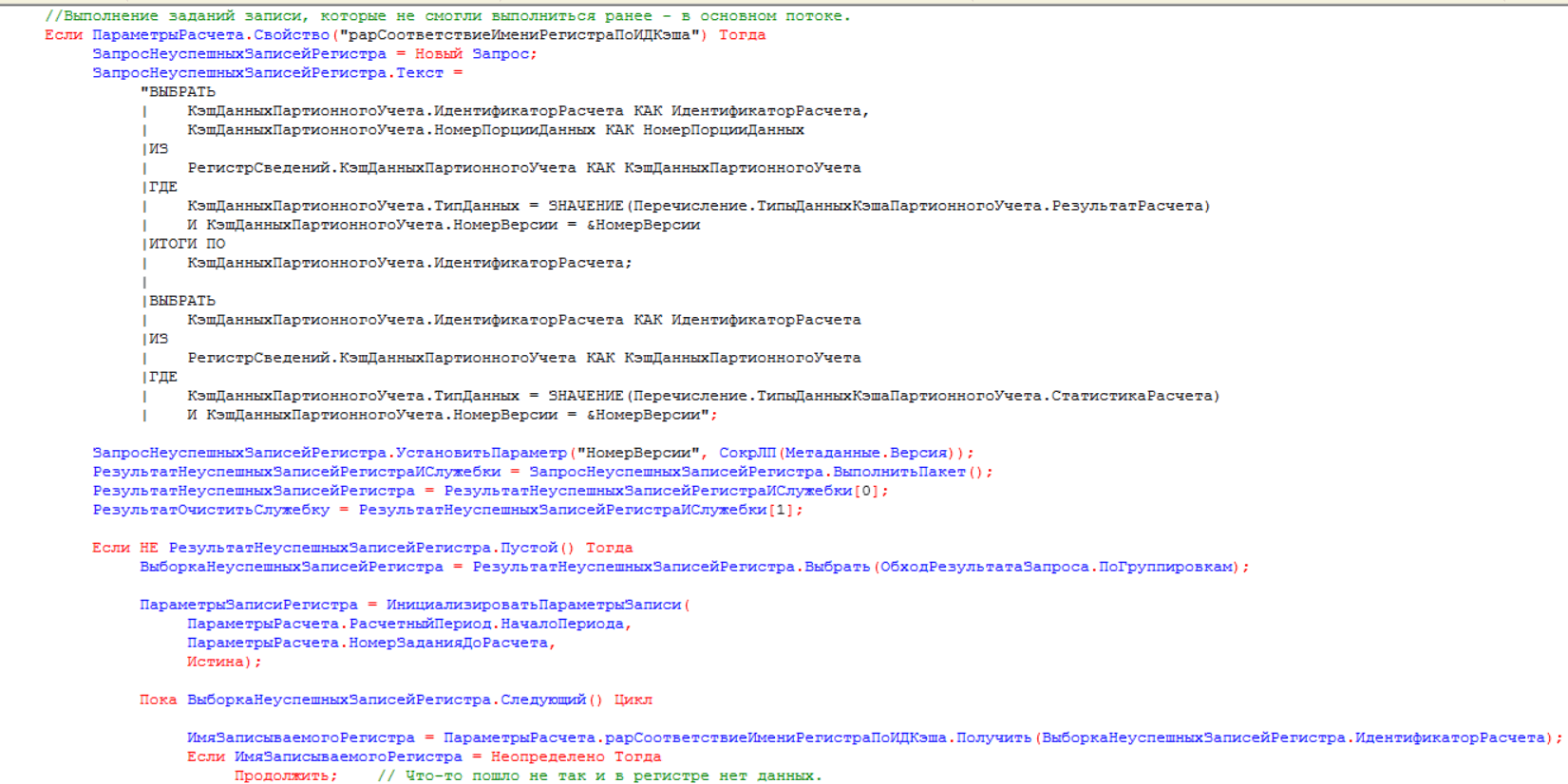
- Наконец, последним шагом все порции данных, по которым произошли ошибки записи, получаем из таблицы кэша и запускаем на запись отдельным фоновым заданием в процедуре «ЗавершениеЗаписиДвижений». При успешном его выполнении очищаем их из кэша и завершаем процедуру записей наборов регистров:

В результате выполнения функционала разбиения набора записей регистра на порции, мы получили следующие цифры по времени выполнения этапа «ЗаписатьСформированныеДвижения» и в целом по времени выполнения процедуры закрытия месяца:
- Время выполнения этапа «ЗаписатьСформированныеДвижения» сократилось с 3 ч. 5 мин. до 1 ч. 20 мин.
- Общее время расчета себестоимости сократилось с 17 ч. 0 мин. до 14 ч. 45 мин.
Также следует упомянуть, что во время тестирования функционала разбиение на порции данных в разрезе одного регистра при расчете себестоимости не было зафиксировано ожиданий на блокировках, что еще раз подтвердило гипотезу о том, что реализованный функционал не приводит к огромному количеству блокировок, которые могут сказать в целом на производительности рассчетов.
Для проверки формирования отдельного фонового задания на «отложенные» порции в связи с ошибками записи из‑за блокировок в итоге были созданы искусственные условия возникновения этих блокировок и на этих условиях успешно оттестировали данный функционал, что говорит о том, что и на реальных условиях все отработает корректно.
Результаты ускорения закрытия месяца
Как результат выполненых работ по изысканию оптимизации этапов процедуры закрытия месяца мы получили следующие цифры:
| Вариант оптимизации | Этап «Заполнение Партий ВРегистре Себестоимость Товаров» | Этап «Записать Сформированные Движения» | Общее время расчета себестоимости |
|---|---|---|---|
| Исходные данные | 3 ч. 9 мин. | 3 ч 45 мин. | 21 ч. 34 мин. |
| Оптимизация этапа заполнения партий в регистре себестоимости | 1 ч. 45 мин. | 3 ч. 05 мин. | 17 ч. 30 мин. |
| Оптимизация этапа записи движений по регистрам | 1 ч. 25 мин. | 1 ч. 20 мин. | 14 ч. 45 мин. |
Оптимизация проблемных этапов позволила сократить общее время расчета себестоимости более чем на 30%, что вполне устроило заказчика.
Применимость гипотез №2и №3 на практике
Немного поразмышляем о том, где рассматриваемые в статье алогритмы могут быть эффективны.
На каких информационных базах сработает алгоритм поиска несвязных подграфов в общем графе сформированных движений, описанный в гипотезе №2 данной статьи?
- В базах, где по измерениям регистра есть четкое разбиение документов по какой-либо аналитике, например, если бы на рассматриваемом нами РН «СебестоимостьТоваров» документы в примерно одинаковом количестве велись по нескольким разным организациям, то взяв за аналитику связанности измерение «Организация» у нас получилось бы совершенно корректно разбить данные на подграфы по компонентам сильной связности и, как следствие, была бы достигнута параллельная запись данных по потокам.
- Организация ведет учет, в котором НСИ часто меняется от партии к партии и связь между документами по составу НСИ сильно отличается. Такая ситуация позволит также как и в первом примере составить подграфы с компонентами сильной связи. Как пример, для РН «СебестоимостьТовара», если аналитика учета номенклатуры в разных документах отличается (такая ситуация может быть при реализации товаров с часто отличающимися характеристиками в зависимости от партии — мебель с разной конфигурацией) или реализации товара с разными наборами в разных документах (продажа блюд по комплексам).
Где эффективно может применяться метод разбиение даных на порции описаный в гипотезе №3?
Результат разбиения на порции на текущем проекте показал хорошие результаты, ускорив выполнение этапа «ЗаписатьСформированныеДвижения» в два раза. Данный подход эффективно может применяться в базах, где выполняются следующие условия:
- Расчет себестоимости выполняется во время наименьшей активности пользователей, чтобы свести к минимуму возможные ожидания на блокировках и не писать данные повторно отдельным фоновым заданием.
- Параметр MSSQL «Max degree of parallelism» выставлен в значение равное количеству ядер процессора у клиента, либо для PostgreSQL параметр max_parallel_maintenance_workers (максимальное количество процессов, которые могут работать параллельно в рамках одного запроса) также выставлен в значение равное количеству ядер процессора у клиента. Такая настройка позволяет максимально распараллеливать процессы записи данных, но следует мониторить ситуацию, так как на другие процессы работы данный параметр может оказать негативное воздействие.
- Оптимально настроены такие параметры закрытия месяца исследуемой системы как «Максимальное количество движений в порции данных для записи», «Максимальное количество одновременно выполняемых заданий записи», «Максимальное количество одновременно выполняемых потоков расчета партий». В нашем случае параметры были подобраны опытным путем, с помощью выполнения расчета себестоимости с разными комбинациями этих параметров.
От экспертов «1С-Рарус»

















