



Оглавление
Введение
Данная статья будет посвящена интересной методологии ведения разработки в 1С с использованием инструментов: Git, GitLab, СППР, SonarQube, 1С:Исполнитель.
Цикл разработки
Перед тем как рассказать об использовании инструментов разработки, необходимо упомянуть об общем процессе развития программного продукта.

В общем случае в процессе развития программного продукта можно выделить следующие шаги:
- Сбор клиентских требований.
- Функциональное моделирование клиентских требований.
- Техническое моделирование функциональных требований.
- Разработка по техническим требованиям.
- Тестирование.
- Сборка и публикация релиза.
- Обновление продуктивной информационной базы.
- Получение обратной связи.
Давайте разберем каждый шаг данного процесса и по ходу повествования будем детально погружаться в инструменты, которые мы будем использовать для работы.
Проектная команда
Но для начала давайте определим роли участников рассматриваемого нами процесса. Здесь мы можем выделить несколько основных ролей, которые участвуют в формировании функционала программного продукта:
- заказчик,
- методолог,
- разработчик.
Мы намеренно опустили руководящие роли, чтобы не усложнять суть повествования.
Главная задача проектной команды — выделить такие задачи развития программного продукта, выполнение которых приведет к наибольшей пользе при наименьших затратах. Соответственно, для успешной реализации данной задачи необходимо наладить такое слаженное взаимодействие внутри команды, чтобы участники не просто говорили на одном языке, а думали одинаково. Как говорится: «Понимали друг друга с полуслова».
Поэтому в рамках работы команды мы постоянно исследуем и применяем различные методики взаимодействия. И особое внимание мы уделяем методологиям сбора клиентских требований.
Сбор клиентских требований
Пользовательские истории
Существует довольно много способов сбора и фиксации клиентских требований. Мы не будем их все перечислять, заострим внимание лишь на одном: «Пользовательские истории».
Пользовательские истории — это концепция, которая первоначально была введена в методологию разработки программного обеспечения «Экстремальное программирование» Кентом Беком. Он ставил важность коммуникации и обратной связи с пользователями превыше всего остального. Пользовательская история представляет собой короткое, понятное описание функционала, которое пользователь должен получить от продукта. Это позволяет команде проекта сфокусироваться на предоставлении ценности пользователей, а не просто на технической реализации.
Для того, чтобы методолог мог проверить, что клиентское требование одинаково понимается всеми участниками проекта, мы стали использовать элементы концепции пользовательских историй. И при сборе пользовательских требований ввели три основных вопроса, трех слонов, на которых бы держалось наше требование:
- цель,
- роль,
- суть.

Эти три слона проходят через каждый шаг процесса развития программного продукта, и каждый участник отвечает за то, чтобы не исказить смысл данных слонов.
Первый слон — это цель требования. Отвечает на вопрос «Для чего?» и описывает конечные точки улучшения поведения программного продукта.
Второй слон — это роль. Отвечает на вопрос «Кого данные требования затрагивают?» в рамках программного продукта. Роль определяет набор имеющихся прав и функций, под которыми пользователь работает в программе.
Третий слон — суть требования. Отвечает на вопрос «Что?» и поясняет, какие нужно добавить новые функции, или изменить существующие в рамках работы роли, для успешного достижения цели.

А для того, чтобы наши слоны твердо стояли на своих ногах, им необходима прочная основа, как панцирь черепахи. Необходима причина возникновения.
Причина возникновения требования отвечает на вопрос «Почему?» и описывает события, ситуации, из-за которых данное требование возникло, формируют контекст возникновения требования.
Кто-то может сказать, что блок «Причина возникновения» избыточен, а блок «Цель» достаточен. Однако, данный блок нам помогает в выявлении глубоких и более конкретных причин возникновения требований. Для его формулирования можно использовать методологию «Трех почему», и к первопричинам возникновения требования можно прийти, отвечая на вопросы:
- Почему требование возникло?
- Почему требование важно?
- Почему нельзя решить проблему другим путем?
В принципе, каждая проектная команда может определить свой набор «Почему», главное не останавливаться на причине, что требование необходимо, потому что так хочет пользователь, а выяснять, действительно ли оно принесет пользу для всей организации.
В итоге на одно требование у нас выходит примерно следующая история:

Примечание: В статье будут использоваться примеры требований из нашего внутреннего проекта по развитию программного продукта 1С:СППР и из некоторых других проектов.
Реестр требований
Таким образом методолог и заказчик со стороны клиента формируют реестр клиентских требований, понятный для всех, в каждой строчке которого указываются цель требования, роль, суть требования, причина возникновения:
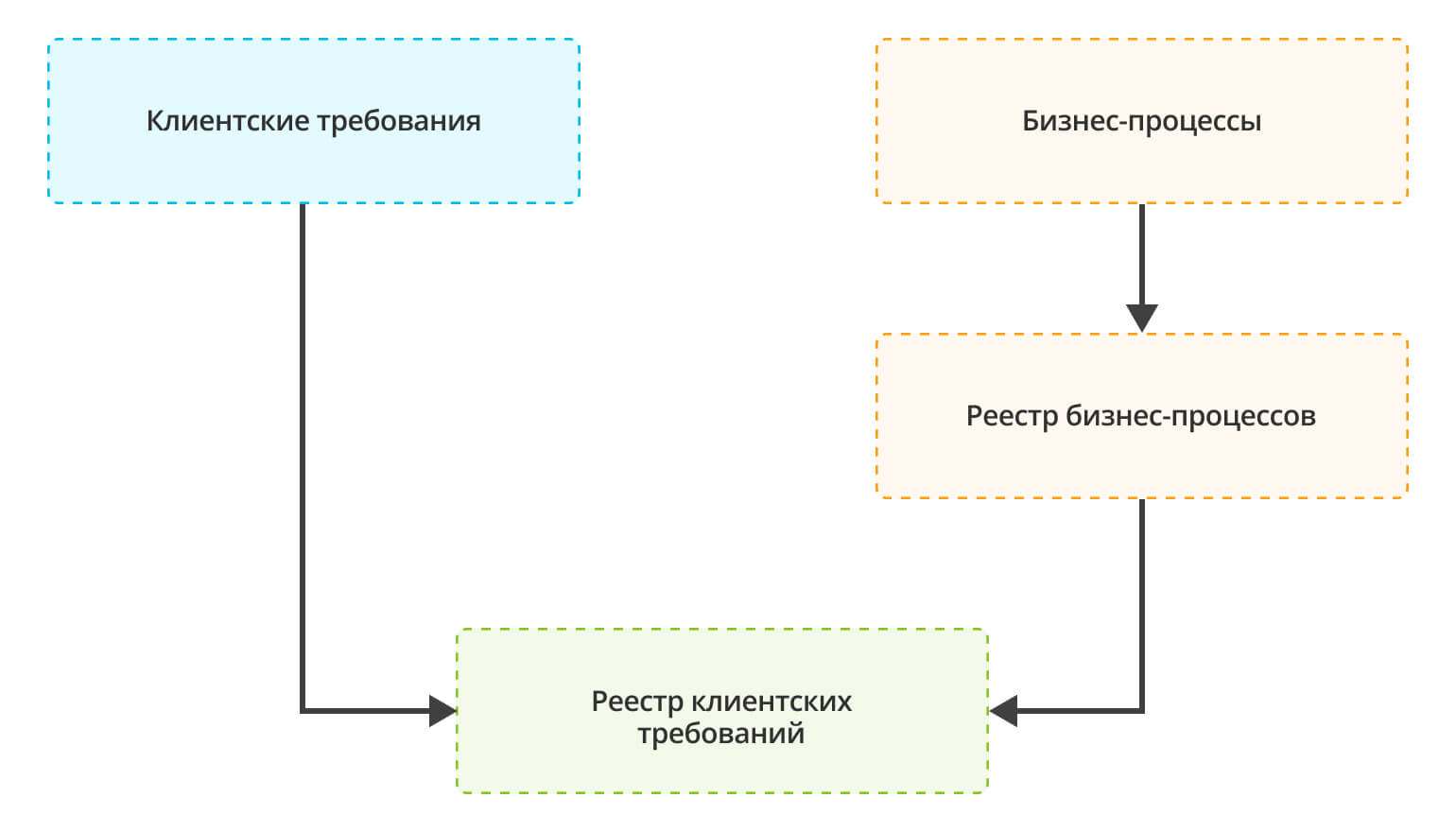
Данный реестр очень удобно приоритезировать, сортировать по срокам реализации. Особая его польза состоит в том, что по нему можно отслеживать статус выполнения именно клиентских требований. Ведь часто в рамках реализации одного клиентского требования могут возникнуть десятки прикладных задач, среди которых само клиентское требование теряется. У команды возникает ощущение, что все сделано, а у заказчика растет недовольство, что ничего не сделано. Данный реестр помогает разрешать подобные конфликты.
Однако, оторванные от бизнес-модели организации требования могут сильно навредить и вместо улучшений привести к усложнению работы. Поэтому клиентские требования собираются не сами по себе, а в контексте бизнес-процессов организации. Точнее говоря, вместе со сбором клиентских требований происходит формирование реестра бизнес-процессов, а требования соотносятся с шагами этих бизнес-процессов:
Резюме
Чтобы не запутаться к концу статьи выделим основные мысли данного раздела:
- Методолог собирает от заказчика требования в виде пользовательских историй.
- Требования консолидируются в реестре требований.
- Методолог также формирует реестр бизнес-процессов.
- Каждое требование соотносится с шагом соответствующего бизнес-процесса.
Функциональное моделирование клиентских требований
Бизнес-процессы
Когда в работу берется сразу несколько клиентских требований, которые относятся к разным шагам одного бизнес-процесса, то хорошей практикой является моделирование структуры этого бизнес-процесса. Это позволяет не упустить детали взаимосвязи между различными клиентскими требованиями. Также, очень часто фиксируются новые клиентские требования, которые изначально не были определены.
Бизнес-процессы описываются у нас в нотации обозначения бизнес-процессов BPMN (Business Process Model and Notation). В рамках модели выделяются шаги и роли из ранее собранных требований, чтобы явно была видна связь бизнес-процесса и клиентских требований, меняющих его:
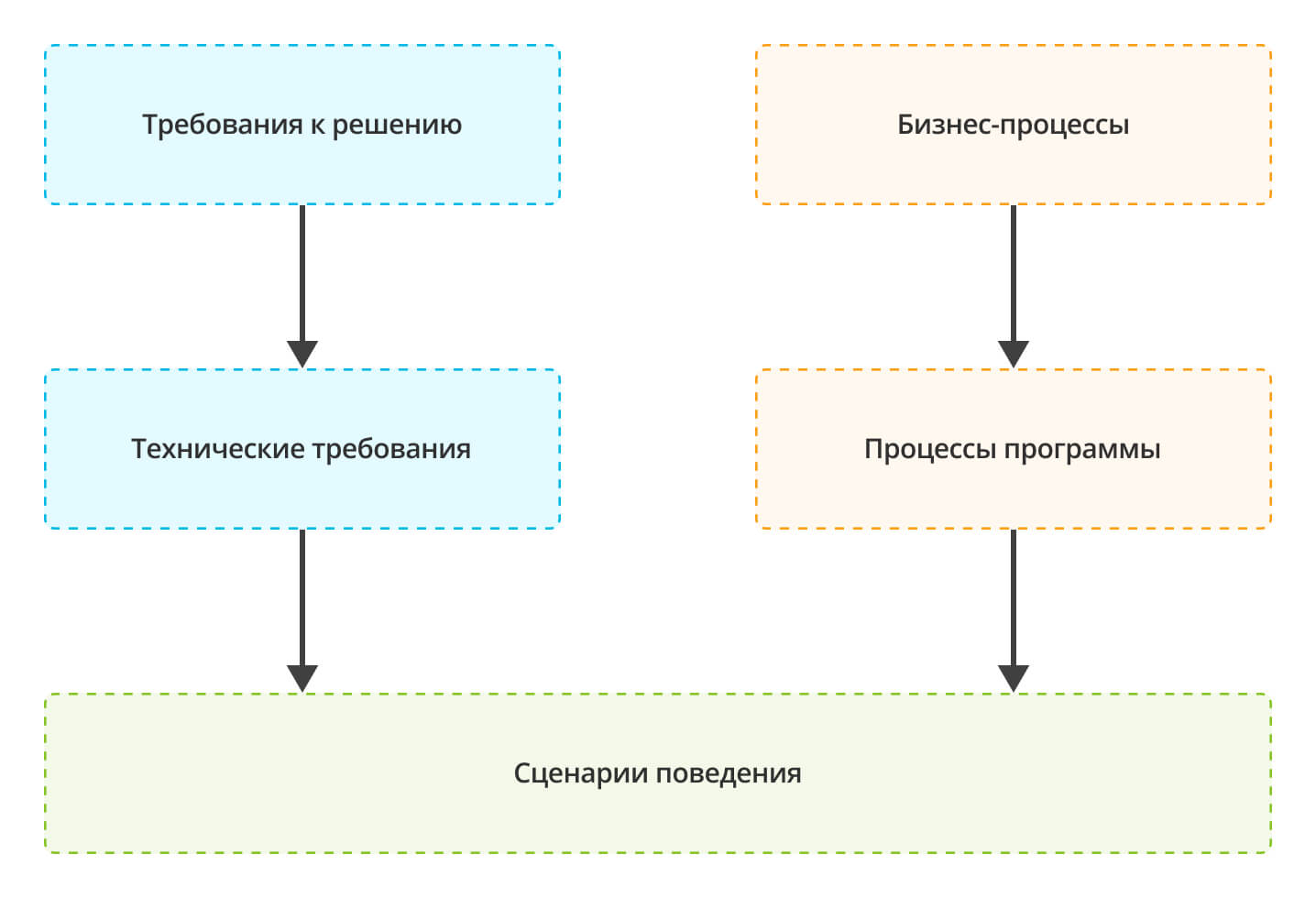
Требования к решению
После того, как большая часть клиентских требований собрана, произведена их приоритезация, определен горизонт работ, начинается функциональное моделирование. Из клиентских требований формируются требования к решению. Требования к решению можно разделить на две категории:
- функциональные требования;
- нефункциональные требования.
Каждое требование детально расписывается, в нем прорабатывается функционал программного продукта, который помогает реализовать клиентское требование. Опять же, существует множество способов наполнения требований к решению. Мы пошли от сценарного способа описания функциональности программного продукта (похожий способ описывается в книге «Современные методы описания функциональных требований к системе» автора Алистера Коберна).
В первую очередь мы формируем шапку требования к решению, которую берем из описания клиентского требования. Соответственно, шапка состоит из следующих разделов:
- цель;
- роль;
- суть;
- причина возникновения;
- шаг бизнес процесса.
Так как требование к решению всегда описывает некий шаг бизнес-процесса, то соответственно и тело самого требования мы можем представить в виде структуры, похожей на описание шага бизнес-процесса, выделив следующие разделы:
- исходные данные;
- ожидаемый результат;
- сценарий поведения.

Здесь:
- Исходные данные — это все те справочники, документы, начальные настройки в программе, которые имеются в системе в начале шага бизнес-процесса.
- Ожидаемый результат — это конечное состояние справочников, документов в программе, которые мы должны получить.
- Сценарий поведения — это те действия, который должен совершить пользователь, чтобы из начальных данных можно было получить ожидаемый результат.
Вся избыточная информация, мешающая восприятию сценария поведения, но необходимая для корректной реализации требования, помещается в конечный раздел «Детализация». Это могут быть:
- наброски форм;
- макеты;
- правила сопоставления объектов при интеграции;
- формулы расчета и т. д.
В итоге мы получаем четкое связное повествование об изменении программного продукта, которое одинаково понимается и заказчиком, и методологом, и разработчиком. Наполнение требования структурировано и каждый раздел помогает не забыть значимые детали.
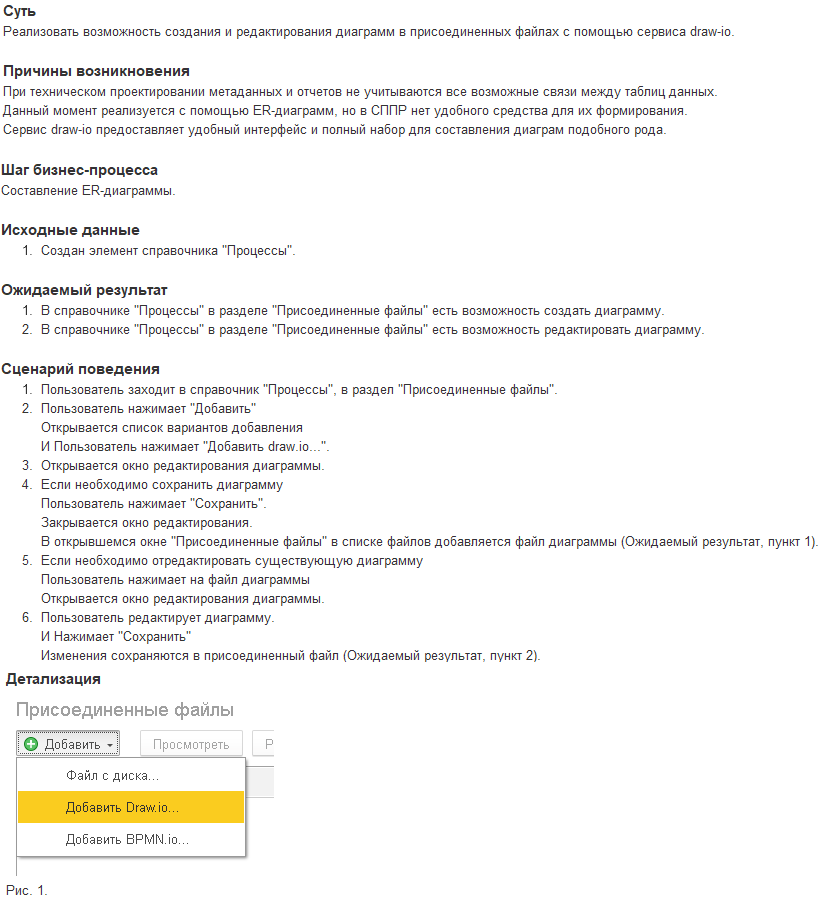
Спецификация функциональных требований
Функциональные требования, которые относятся к одному бизнес-процессу, и которые реализуют близкую логику, объединяются в спецификацию функциональных требований (СФТ).
Спецификациями удобно оперировать при согласовании функциональных решений с клиентами. По ним легче проводить оценку, их легче планировать в отличие от одиночных функциональных требований. По ним легче принимать работы. Поэтому по завершению функционального моделирования, основной единицей приемки/сдачи работ становится именно СФТ.
Также как и для требований к решению, для шапки СФТ мы определили шаблон, который состоит из следующих разделов:
- Назначение документа.
- Краткий обзор предлагаемой схемы автоматизации.
- Глоссарий.
В шапке СФТ выполняется описание развиваемого бизнес-процесса. Дается краткая аннотация по функциональным требованиям, которые будут реализованы в рамках данной спецификации:

СППР
Для организации проектирования и разработки программного продукта наша команда использует систему 1С:СППР:

Именно в этой системе методологи фиксируют все требования к решению.
Однако СППР предназначена прежде всего для разработки программного продукта с нуля без учета проектной специфики, поэтому нам пришлось ее немного доработать и изменить функциональный смысл некоторых объектов.
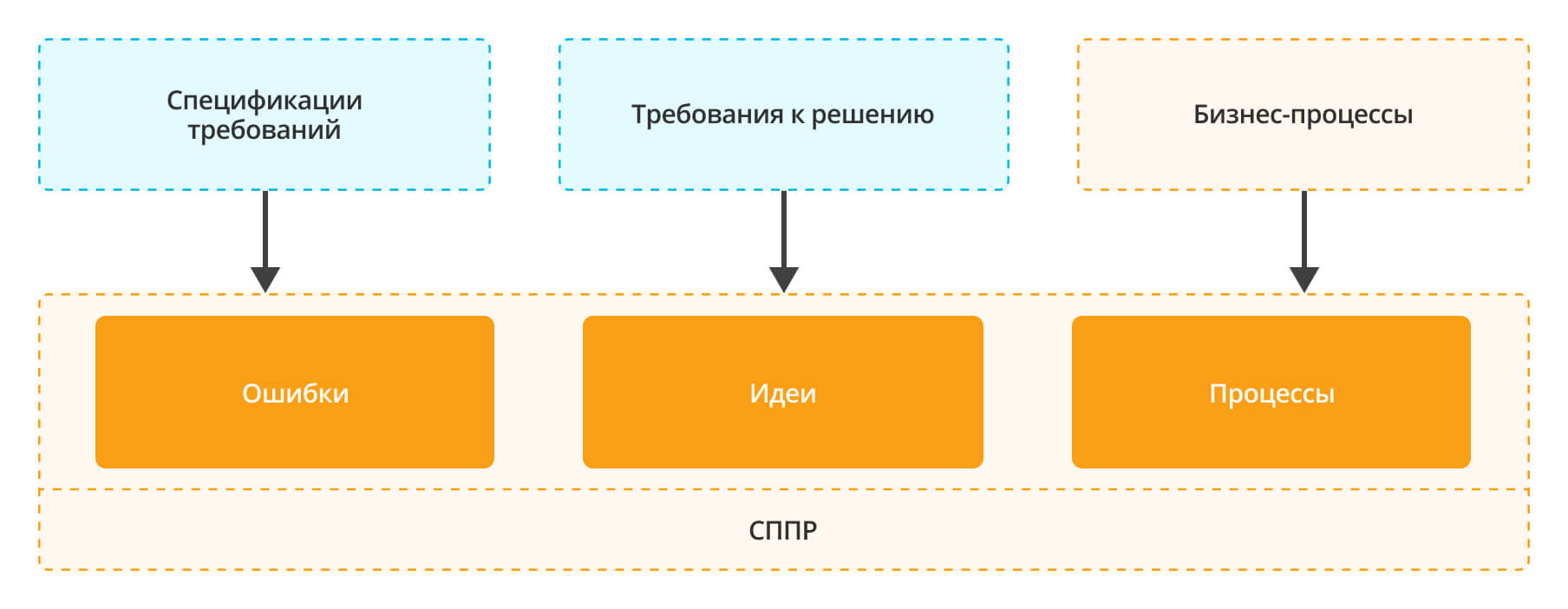
В первую очередь в системе нам понадобился объект для фиксации спецификаций функциональных требований. Для этого по своей функциональности больше всего подошел справочник «Ошибки».
В данном справочнике имеются:
- Статусы, чтобы можно было видеть на каком этапе работы находится спецификация.
- Протокол взаимодействия, чтобы можно было после разработки передавать спецификацию на рассмотрение методологам.
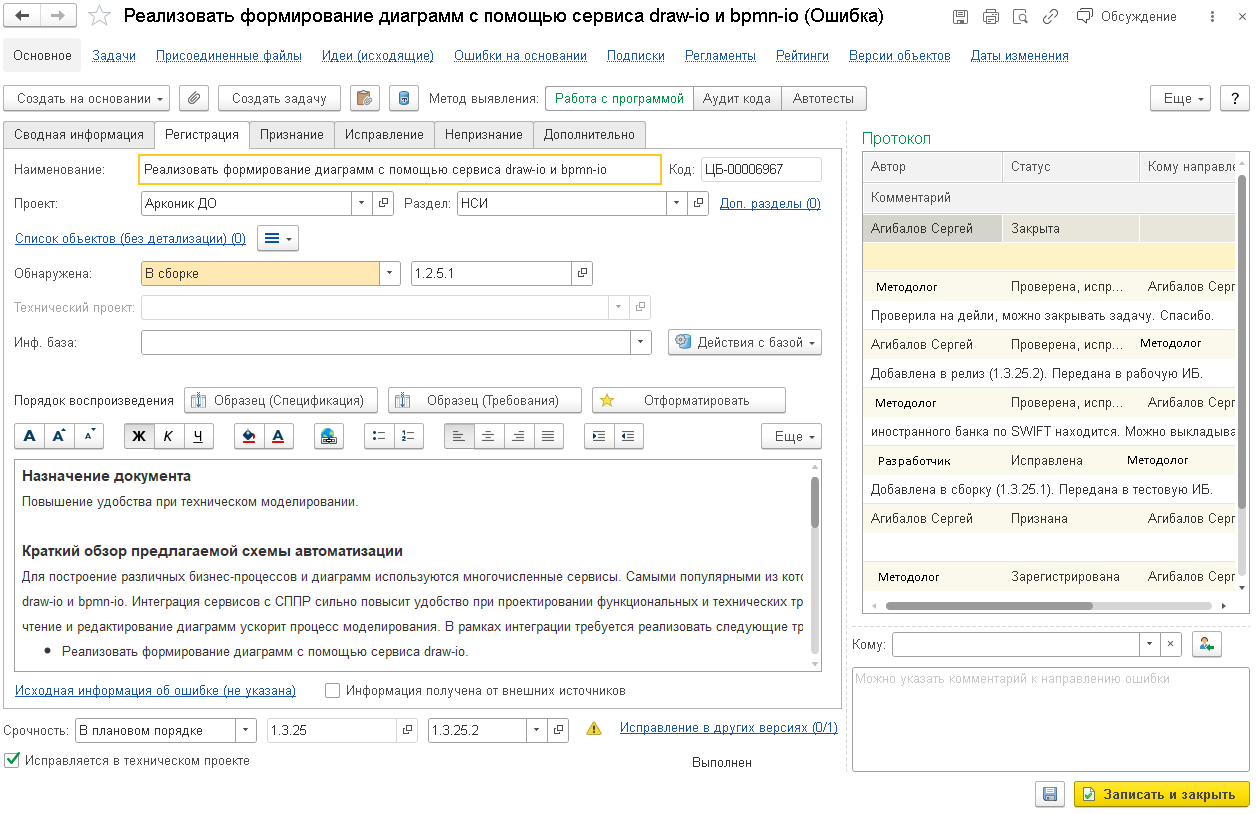
Помимо самих спецификаций в данном справочнике мы также фиксируем:
- нефункциональные требования;
- и сами ошибки.
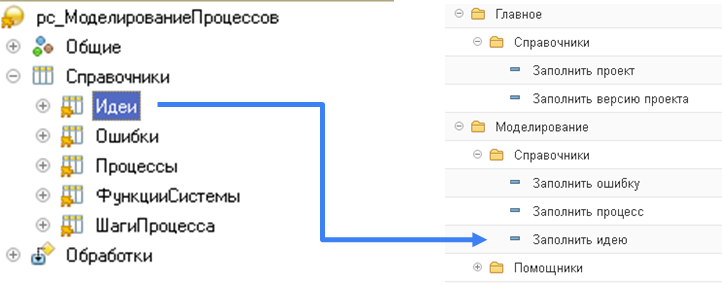
Функциональные требования мы фиксируем через справочник «Идеи», которые создаются на основании зафиксированных через справочник «Ошибки» СФТ:
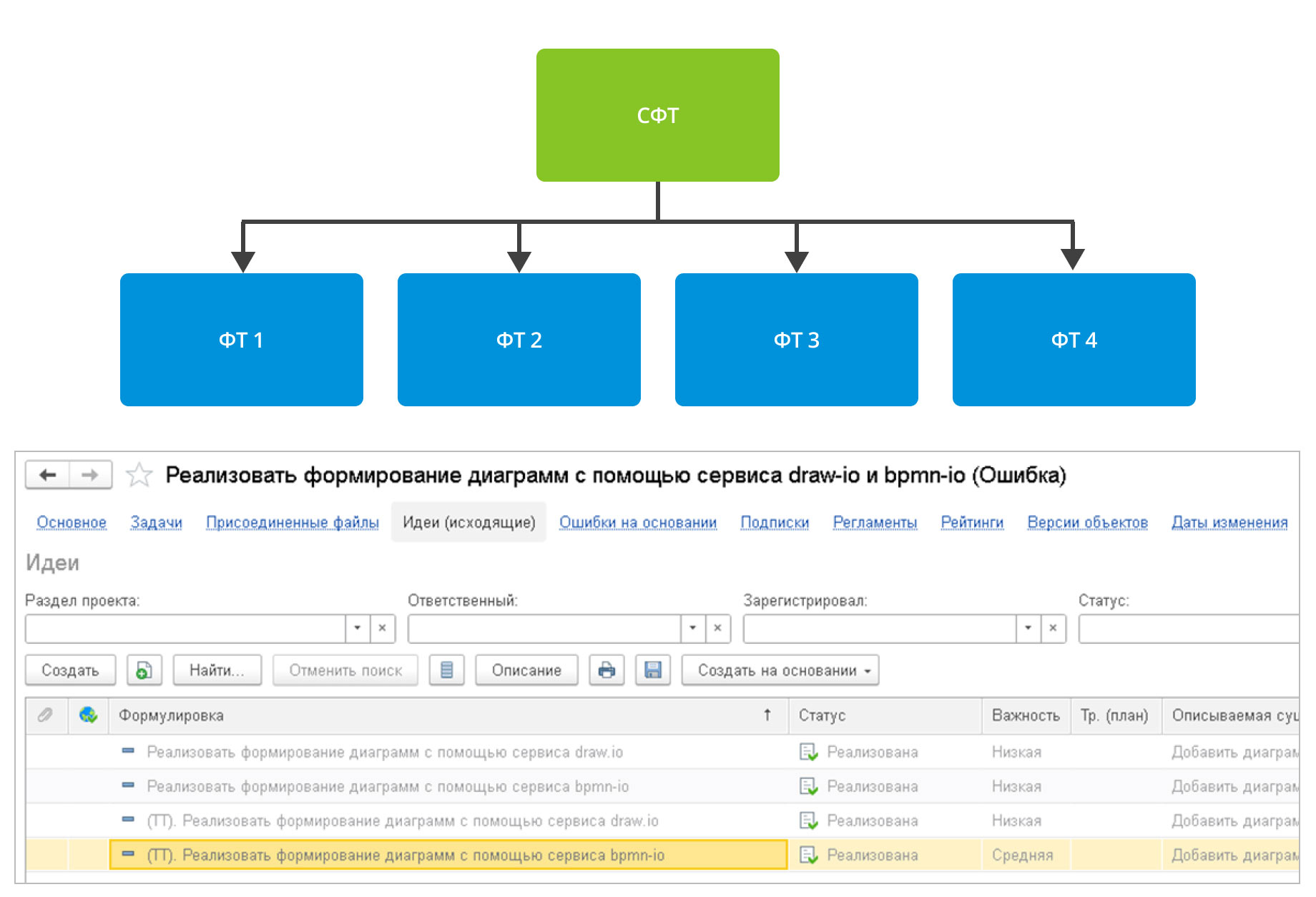
Для всех одиночных требований, мы все равно сначала фиксируем СФТ в СППР в справочнике ошибок, а потом само требование в справочнике «Идеи». Это нужно для того, чтобы не путать пользователей и организовать одинаковый порядок ввода данных.
Таким образом мы получаем следующую структуру: цветом обозначена связь спецификации требований и функциональных требований:

После фиксаций всех требований и спецификации требований, методолог может выполнить генерацию документации прямо из СППР для согласования ее с клиентом. Для этого мы выполнили доработку конфигурации, чтобы текст из форматированного документа преобразовывался в офисный документ в формате docx:
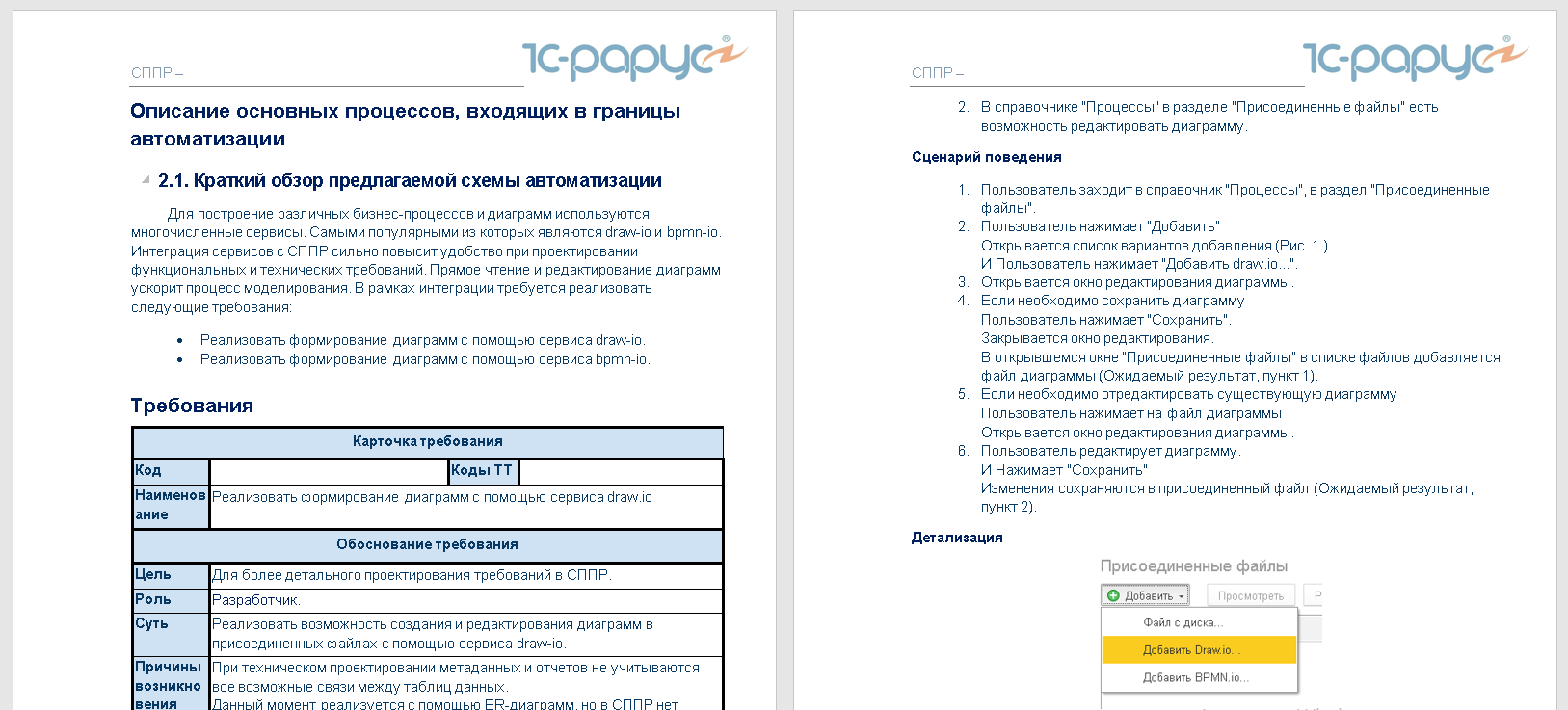
Для этого мы воспользовались возможностью БСП формирования документа из макета docx.
Так как описание всех требований у нас создается не произвольным образом, а по предварительному шаблону, то благодаря ему мы смогли из форматированного документа выделить блоки текста с группировкой по областям и эти области расположить в соответствующие области шаблона docx.
Однако в текущей логики БСП нам не хватило следующего функционала:
- Сброс нумерации списков.
- Увеличение уменьшение отступов для нумерованных и маркированных списков.
Этот функционал мы успешно добавили в текущий API модуля УправленияПечати и в ближайшем будущем отправим запрос на включение его в последние версии БСП.
Интеграция BPMN в СППР
Существует множество сервисов, предоставляющих платформы для моделирования бизнес-процессов в нотации BPMN. Мы используем свой веб‑сервис, основанный на открытом движке BPMN‑IO. Это свободно распространяемая платформа на node.js, которая используется в таких сервисах: Camunda, Stormbpmn и прочее.
Подключение библиотек довольно простое и довольно подробно описано на сайте разработчика.
Также в открытом доступе мы предоставили свой проект BPMN-IO, предназначенный для интеграции с СППР (github.com/agibalovsa/EasyBPMN):

Список бизнес-процессов мы фиксируем в справочнике «Процессы». А нотацию прикрепляем через присоединенные файлы.
Чтобы было удобней работать с нотацией, мы выполнили интеграцию СППР с внутренним веб-сервисом BPMN-IO:
Резюме
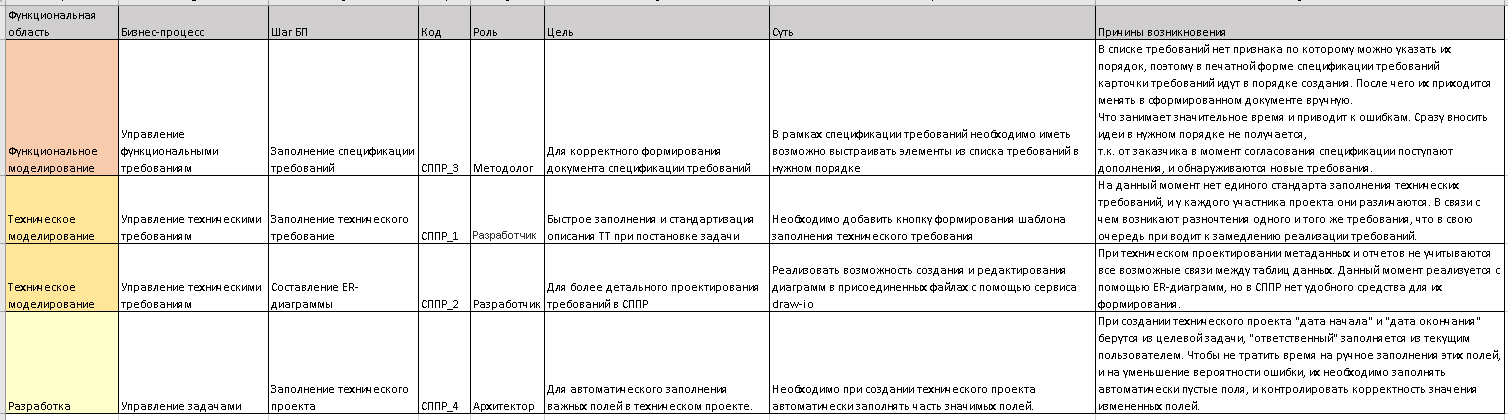
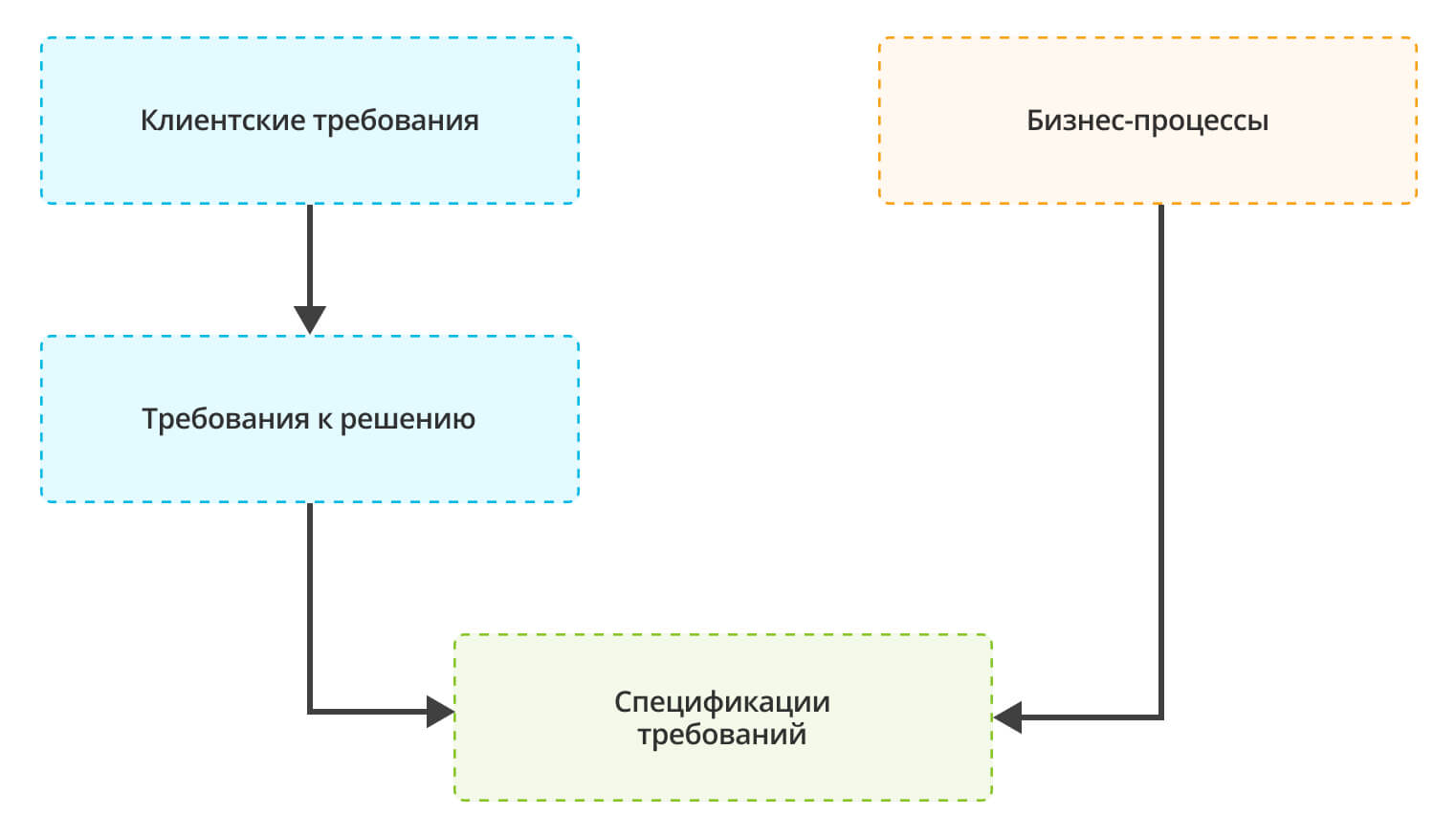
- На основании клиентских требований методолог формирует требования к решению и моделирует бизнес-процессы.
- Из требований к решению формируются спецификации требований, на основании которых строится план работ:
- Спецификации требований и требования к решению фиксируются в СППР в справочниках «Ошибки» и «Идеи» соответственно.
Бизнес-процессы фиксируются в справочнике «Процессы» с приложенной схемой BPMN:
Техническое моделирование функциональных требований
Технические требования
После фиксации в СППР всех требований к решению начинается техническое моделирование. На основании каждой идеи с функциональным требованием создается одна или несколько подчиненных идей с техническими требованиями:
В технических требованиях у нас также генерируется шаблон заполнения со следующими разделами:
- Требование к сценарию поведения.
- Требование к метаданным.
- Требование к интерфейсу.
- Требование к логике.
После создания технических требований они согласуются с архитектором. А раздел «Требование к сценарию поведения» в обязательном порядке согласуется с методологом, проверяется, что нет отличий от сценариев поведения в функциональных требованиях.
Давайте рассмотрим каждый раздел отдельно.
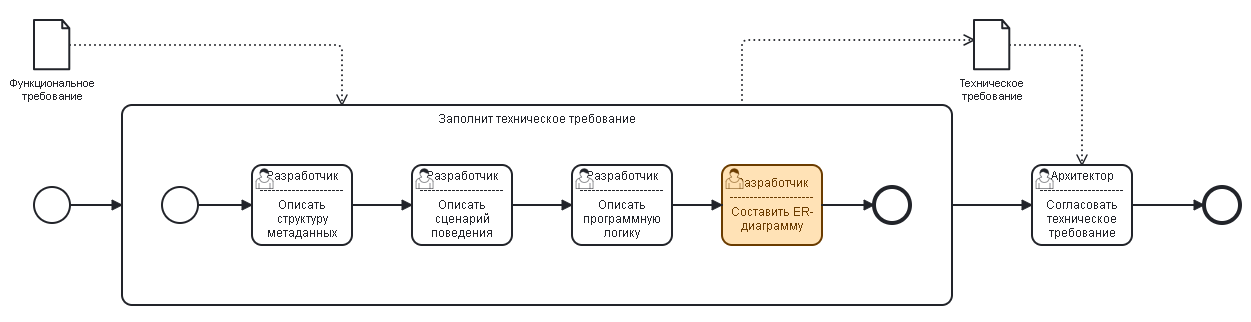
Требование к сценарию поведения
Для любого функционального требования опорным элементом проектирования является сценарий поведения, по которому, собственно говоря, и будет проводится тестирование требования. Поэтому данный раздел является самым важным в этапе технического проектирования.
Задача разработчика — описать детальнейшим образом то, как будет себя вести программа после выполнения разработки. И в этом ему помогает методология описания сценариев поведения на языке Gherkin. Формат данного языка помогает не упустить мельчайшие подробности моделируемого поведения программы.
Структура языка сценариев «Геркин» довольно проста:
Сценарий: <НаименованиеСценария> Когда <Условие возникновения действия или действие> И <Условие возникновения действия или действие> Тогда <Событие> И <Событие>
Он состоит из простых блоков: «Когда», «Тогда». Однако на основе такой простой структуры можно создать довольно детальные сценарии:

Из приведенного примера видно, что довольно легко по действиям пользователя представить требуемый интерфейс.
Сценарий поведения помогает не только согласовать будущее поведение программы с методологом с точностью до нажатия кнопок, но и подготовить подробнейший сценарий тестирования для сдачи работ. О чем мы расскажем ниже. Сейчас лишь заострим внимание на том, что задача не сможет быть выполнена, пока не будет принят протокол тестирования от разработчика, а разработчик не сможет данный протокол составить, пока заранее не согласует сценарий поведения с методологом.
Теперь вспомним, что все началось с простейшего клиентского требования, и шаг за шагом, с помощью небольшого вклада каждого участника команды, мы подошли к детальнейшему описанию нашей системы. Такой подход намного эффективнее, нежели простое написание требования «с наскоку» одним человеком.
Требования к метаданным
В данном разделе мы детально описываем все изменения метаданных, которые приводят к реструктуризации:
- добавление новых объектов метаданных;
- добавление реквизитов;
- изменение типов;
- и т. д.

В СППР есть функционал загрузки дерева конфигурации и работы с ним, можно также создавать свои объекты метаданных. Но данное дерево сложно поддерживать в актуальном состоянии. Гораздо проще описать изменения метаданных в текстовом виде.
Требование к интерфейсу
В данном разделе описываются значимые изменения формы. Интерфейс 1С легко читаем и понимаем, поэтому очень часто, как было показано выше, для его осознания нам достаточно пользовательских сценариев. Однако, бывают случаи, когда без детальной проработки интерфейса обойтись просто нельзя. Для таких случаев мы используем данный раздел. Здесь структурно, как и для раздела метаданных, описываются значимые поля. Прикрепляются зарисовки и прототипы форм.
Требование к логике
В данном разделе описывается программная логика, которая требует дополнительного внимания. В особенности это касается:
- Описание API программного интерфейса общего модуля.
- Описание API для web- или http-сервисов.
- Описание сложного алгоритма.

Проектирование процессов описания программы
Для избежания путаницы давайте зафиксируем терминологию.
Выстраивая последовательность функций в цепочку, для получения целевого состояния системы, мы формируем процесс изменения системы. Т. е. фактически каждый шаг процесса обладает своей функциональностью. В свою очередь каждую функцию можно представить как отдельный процесс с более детальными шагами. А каждый процесс, если не рассматривать его внутреннюю структуру, можно назвать функцией. Все зависит от того, на каком уровне взаимодействия происходит моделирование системы.
В итоге верны следующие высказывания:
- Система выполняет свою функцию, если в ее рамках выстроены правильно процессы.
- Процесс выполняется эффективно, если для его реализации подобраны оптимальные функции.
Итак, при моделировании системы мы определяем ее функциональность, которая нам необходима для построения процесса работы в этой системе. Функциональность системы выражается в сценариях поведения.
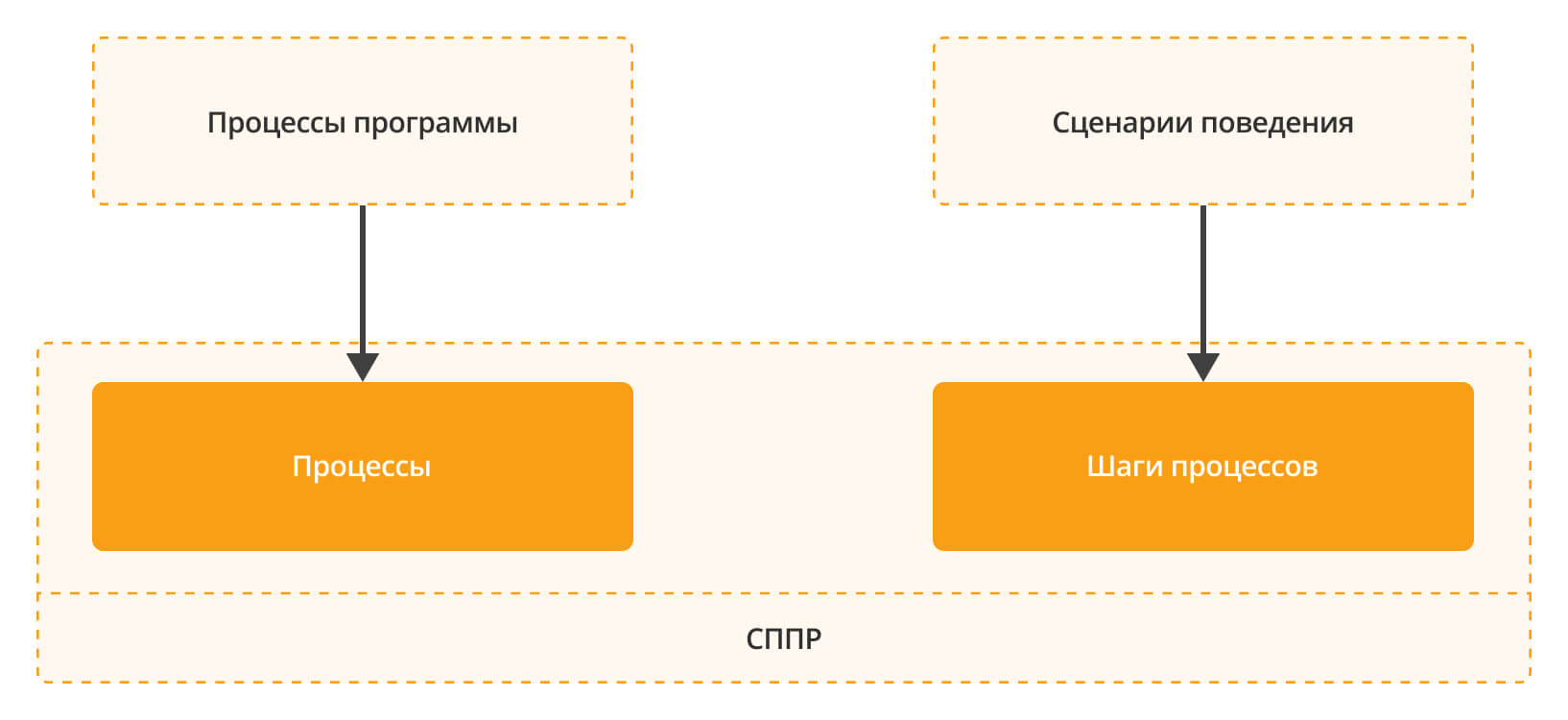
После того как были спроектированы сценарии поведения, необходимо место, где они будут зафиксированы. В требованиях сценарии поведения довольно быстро устаревают. Нам же необходимо постоянно поддерживать их актуальными, чтобы можно было всегда к ним обратиться, и вспомнить, что было сделано последним. Для этих целей мы используем справочник «Процессы».
Как указывалось выше, методологи фиксируют в этом справочнике бизнес-процессы организации. Разработчики же фиксируют процессы описания работы программы.
Бизнес-процессы организации и процессы описания работы программы логически связаны между собой, но не совпадают однозначно:
- Бизнес-процессы организации охватывают функциональность организации в целом, включая все информационные системы. А процессы программы описывают только функциональность разрабатываемого продукта.
- Также различается уровень описания процессов. Бизнес-процессы организации описываются на уровне взаимодействия сотрудник-сотрудник или сотрудник-информационная система. А процессы программы описываются на уровне взаимодействия пользователь-интерфейс.
- Функциональность шагов бизнес-процессов организации, связанных с программой, описывается через процессы работы программы.
Исходя из этой логики, мы вносим в справочник «Процессы» все процессы системы, с которыми работаем.
Обычно порядок ввода процесса следующий:
- Мы определяем в системе интерфейсный объект, с которым будем работать, например, справочник «Ошибки».
- Для интерфейсного объекта мы вносим один основной процесс, характеризующий работу с ним. Например, «Заполнение справочника «Ошибки». Или, если это отчет «Трудоемкость задач», то вносим процесс «Выполнение отчета „Трудоемкость задач“»:
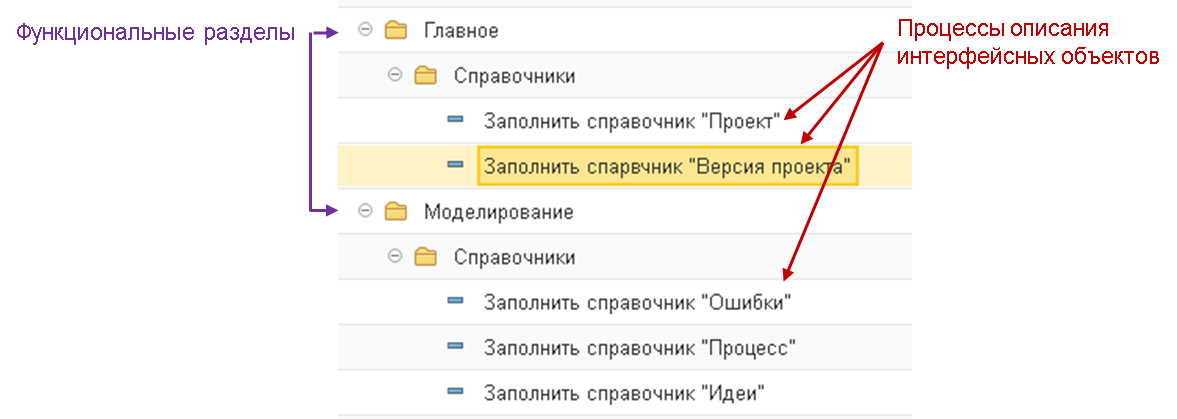
- У описываемого объекта в конфигураторе могут быть описаны интерфейсы: форма списка, форма элемента, команды заполнение, печати и т. д.
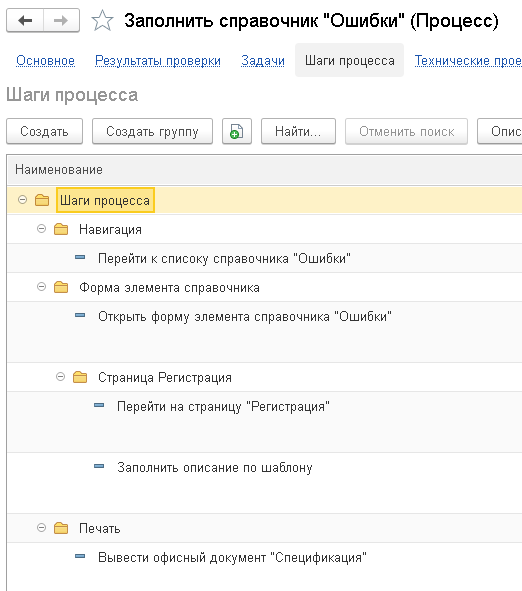
- На каждое интерфейсное действие мы создаем шаг в процессе, в котором описываем сценарии поведения на языке Геркин:
Для графического описание процессов мы интегрировали сервис PlantUML. Этот сервис позволяет автоматически генерировать диаграммы семейства UML через передаваемое ему текстовое описание структуры. В частности, мы внедрили генерацию диаграммы действий:
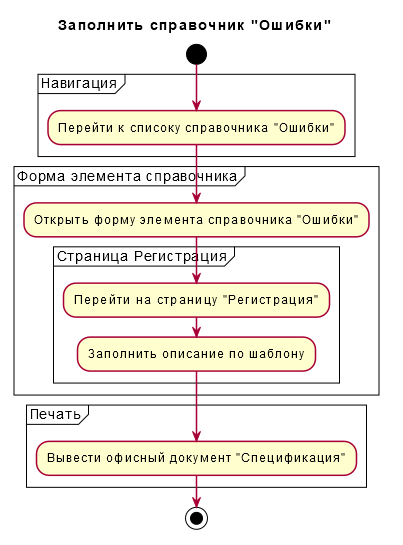
Благодаря этому для процессов мы можем одновременно группировать шаги и тут же получать для них графическое описание.
Проектирование ER-диаграмм (Entity-Relationship diagram)
При проработке отчетов, а также сложного набора метаданных используется методология проектирования модели данных сущность-связь.
Основная концепция создания ER-диаграммы заключается в выделении ключевых сущностей (entities), их атрибутов, а также связей (relationship) между этими сущностями. Благодаря чему мы можем структурно представить взаимосвязь между разными объектами данных в системе.
В качестве платформы проектирования используется draw-io, которая, также как и BPMN-IO, интегрирована с СППР:
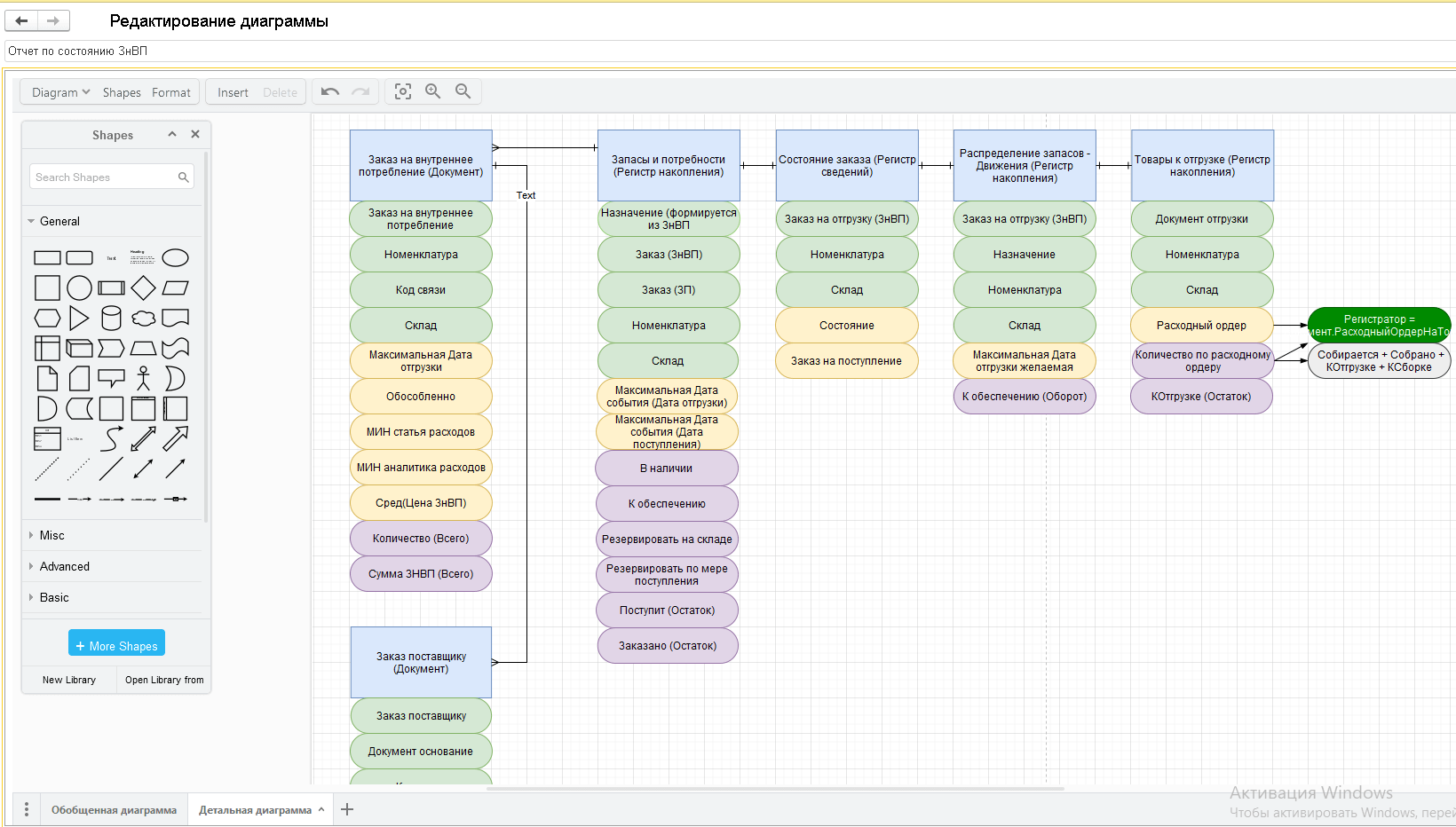
По ER-диаграмме мы можем заранее выяснить, какие сложности могут возникнуть в отчете, в связи с чем далее принимаются решения, как лучше данный отчет реализовывать.
Резюме
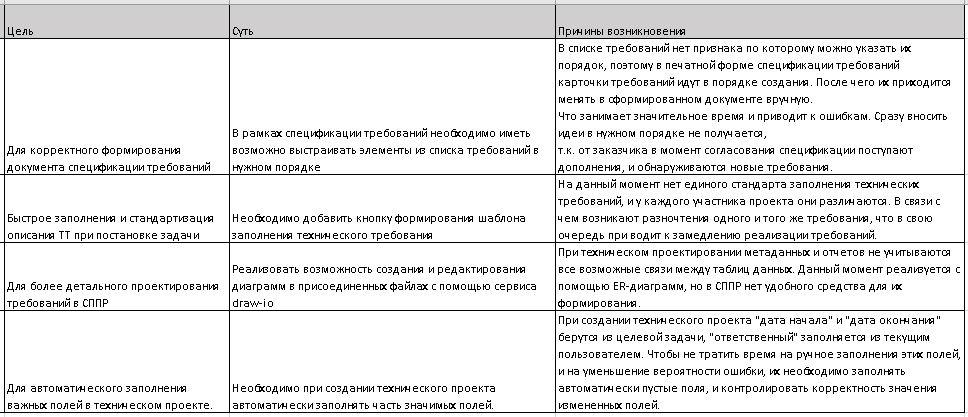
- По функциональным требования создаются технические требования.
Главным разделом технических требований является пользовательский сценарий:
Пользовательские сценарии сохраняются в шагах процесса, который создается один на функциональный объект в системе:
Разработка по техническим требованиям
Для нас разработка это не просто набор текста для корректного функционирования программы, это переложение текста из требования на человеческом языке в текст на языке 1С.
И для сохранения структуры кода, чтобы можно было потом его соотнести с ранее поставленными требованиями, мы используем следующие приемы:
- Группируем код по функциональным областям в 1С.
- Версионируем код по требованию, автору, дате изменений.
- Управляем хронологией включения версий кода в рабочую ИБ.
Рассмотрим каждый прием разработки отдельно.
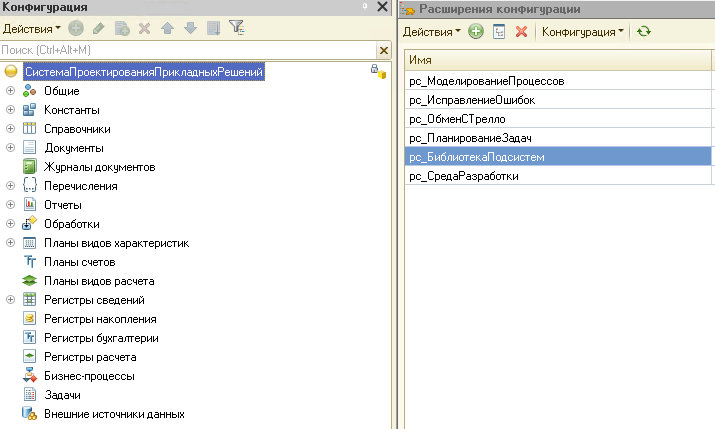
Использование расширений
В своей работе мы активно используем расширения:
- Во-первых, по сравнению с конфигурацией они очень маленькие и ими легко управлять.
- Во-вторых, применение расширений не вызывает никаких проблем по сравнению с динамическим обновлением конфигурации, что позволяет нам применять изменения без завершения работы пользователей.
- В-третьих, с помощью расширений мы можем организовать подход в разработке, близкий к модульному.
Структура внесения изменений с помощью расширений следующая:
- Все изменения в метаданных, которые приводят к реструктуризации ИБ, мы вносим в основную конфигурацию. Это безопасно. И типы из конфигурации распространяются на все расширения.
- Все остальные изменения: формы, модули, обработки и прочее мы вносим в расширения.
- Мы не помещаем весь код в одно расширение, а разделяем расширения по функциональным разделам. Т. е., например, в случае проекта СППР, мы можем разделить код по расширениям, согласно следующим функциональным разделам:
- Планирование задач. Здесь мы описываем создание задач, контроль их выполнения, контроль сроков выполнения и т. д.
- Моделирование процессов. Здесь мы описываем логику работу с техническими требованиями, с диаграммами процессов.
- Среда разработки. Здесь мы описываем логику разворачивания среды разработки.
- Библиотека подсистем. Здесь мы описываем библиотечные модули, которые можно вызывать из других расширений.
- Стоит отдельно заострить внимание на библиотечных расширениях. Их создание возможно благодаря тому, что вызов методов из модулей одного расширения в модулях другого расширения происходит без ошибок.
Функциональные области
Помимо разделения расширений по функциональным разделам, мы разделяем код по функциональным областям внутри каждого расширения. Для этого мы используем лексему #Область, с помощью которой можно разбить модуль на блоки согласно функциональности:
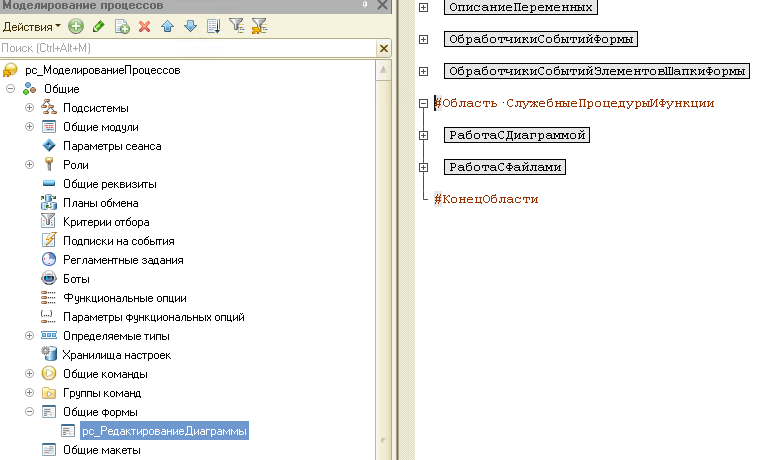
Например, в данном модуле мы выделили 2 функциональные области:
- Функции работы с диаграммой.
- Функции работы с файлами.
При написании кода мы соблюдаем несколько правил:
Мы используем типовые области согласно стандарту описания модулей на ИТС. (Структура модуля (its.1c.ru/db/v8std/content/455/hdoc)).

Внутри области СлужебныеПроцедурыИФункции мы разбиваем код на дополнительные функциональные области.

Внутри функциональных областей код разбивается еще на общие и частные подобласти.

Методы из общей области используются для вызова из других функциональных областей, а также для вызова из обработчиков событий формы.

Методы из частной области вызываются из методов общей области внутри одной функциональной области.
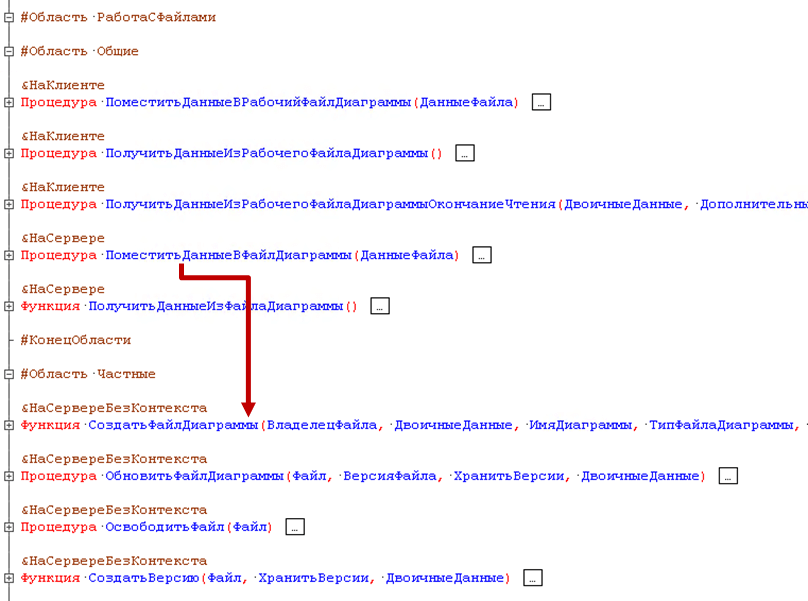
В обработчиках событий модулей форм и объектов нет никакого другого кода, кроме вызова методов из функциональных областей.

Такой поход позволяет нам получить следующие преимущества:
- Как минимум, в разы возрастает удобство навигации по модулю формы.
- Происходит создание более самостоятельных методов, что может являться заделом для библиотечных модулей.
- Резко уменьшается дублирующаяся логика. Например, одинаковый код в различных обработчиках событий.
Мышление разработчика становится более системным, код становится более строгим, логика становится поэтапной.
Раньше очень часто возникали ситуации, когда логика запутывалась, например, выборка данных перемешивалась с обработкой данных. Что приводило в итоге к сложному сопровождению, и, как следствие, к деградации системы. Сейчас разработчик приходит сам к выводу, что все данные нужно сначала выбрать, а потом обработать, и данную логику лучше разместить в разных методах.
Связь функциональных областей и процессов в СППР
Идея функциональных областей возникла не на пустом месте. Когда мы стали использовать сценарии поведения, возникла потребность, чтобы код, исполняющий данные сценарии был логически сгруппирован. Это бы нам помогло сделать его более стабильным, а логику различных функций интерфейса более независимой.
Таким образом мы стали соотносить процессы и шаги процессов с расширениями и функциональными областями.
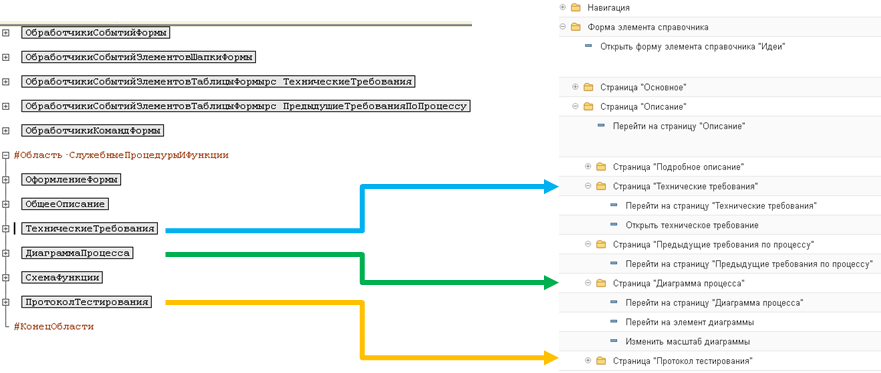
В итоге на этапе проектирования процессов стали фактически задавать функциональную структуру модулей.
Хранение версий проекта
Для хранения и управления версиями проекта мы используем распределенную систему управления версиями Git.
Что мы понимаем под версией проекта?
При выполнении спецификации требований разработчик формирует в результате своей деятельности некие артефакты, а именно:
- изменения в конфигурации;
- изменения в документации;
- изменения в настройках информационных баз.
Для сопоставления результатов деятельности разработчика с требованиями в СППР необходимо формировать некий именованный архив, куда бы мы могли положить все его изменения. Причем данный архив должен быть прозрачным, чтобы мы могли посмотреть что было до, и что стало после. А при определенных ситуациях могли бы проанализировать хронологию изменений того или иного артефакта.
Вот эти все функции и позволяет выполнять система Git.
Репозиторий проекта
Для удобной работы с проектом в Git важна грамотно организованная структура. В наших проектах мы используем структуру для двух типов хранения конфигурации:
В формате EDT:

В формате XML (конфигуратора):

Здесь можно выделить следующие каталоги:
- src — каталог с исходными файла проекта.
- script — каталог со скриптами сборки бинарных файлов конфигурации и расширения, а также скрипты обновления. Данный каталог необходим в репозитории в формате XML.
- doc — каталог с документацией проекта.
- m-data — каталог с настройками информационной базы, которые можно применять с помощью обработки загрузки/выгрузки xml с сайта ИТС (Выгрузка и загрузка данных XML — its.1c.ru/db/metod8dev/content/4126/hdoc).
- bin — каталог, который помещен в gitignore, в нем содержатся локальные настройки, служебные файлы, файлы сборки cf и cfe.
Также можно обратить внимание на файлы настройки:
- sonar-project.properties, .bsl-language-server.json — файлы настройки для SonarQube.
- project_config.json — файл настройки для скриптов 1C:CICD (открытая разработка, используемая компанией «1С‑Рарус» на проектах).
- .gitlab-ci.yml — файл настройки для gitlab ci, настройка для запуска SonarQube.
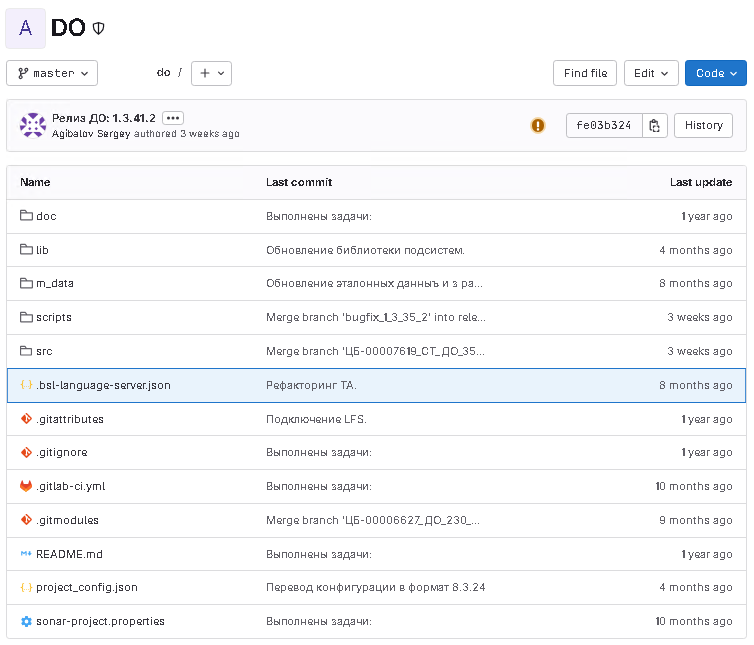
Хранение репозиториев проектов у нас централизовано и выполнено с помощью сервиса GitLab. В любой момент времени отсюда можно получить свежий срез по проекту. Также с помощью данного сервиса мы организуем сборочную линию для автоматизации рутинных операций.
Мир веток Git
Итак, основная деятельность разработчика заключается в написании кода в конфигурации. Для фиксации изменений кода он формирует в Git-репозитории ветку, которая по своему наименованию соотносится со спецификацией требований из СППР:
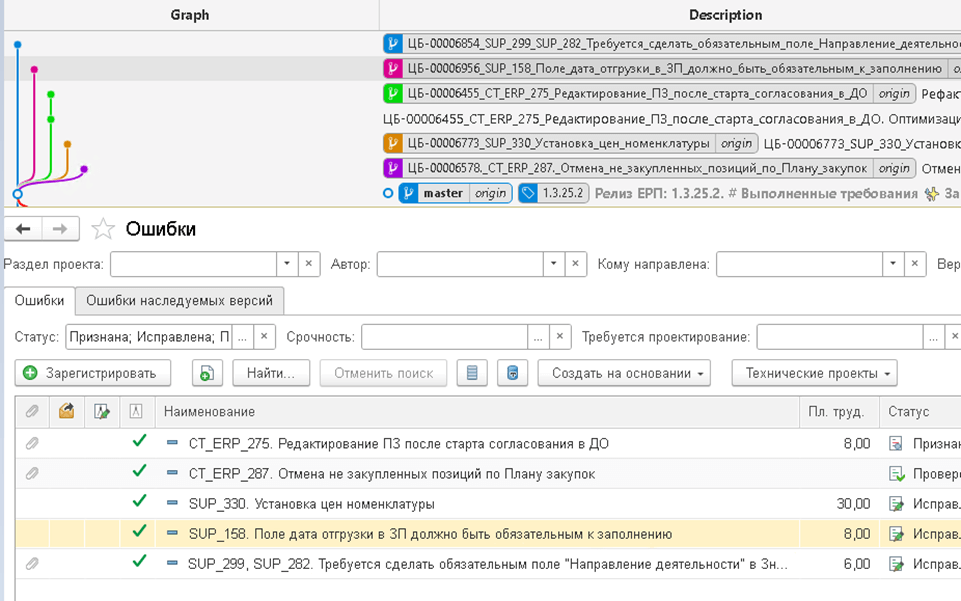
В рамках данных веток и происходит версионирование изменений. Здесь мы можем увидеть не только список измененных артефактов проекта, но и сами изменения в тексте проекта относительно предыдущей фиксации:
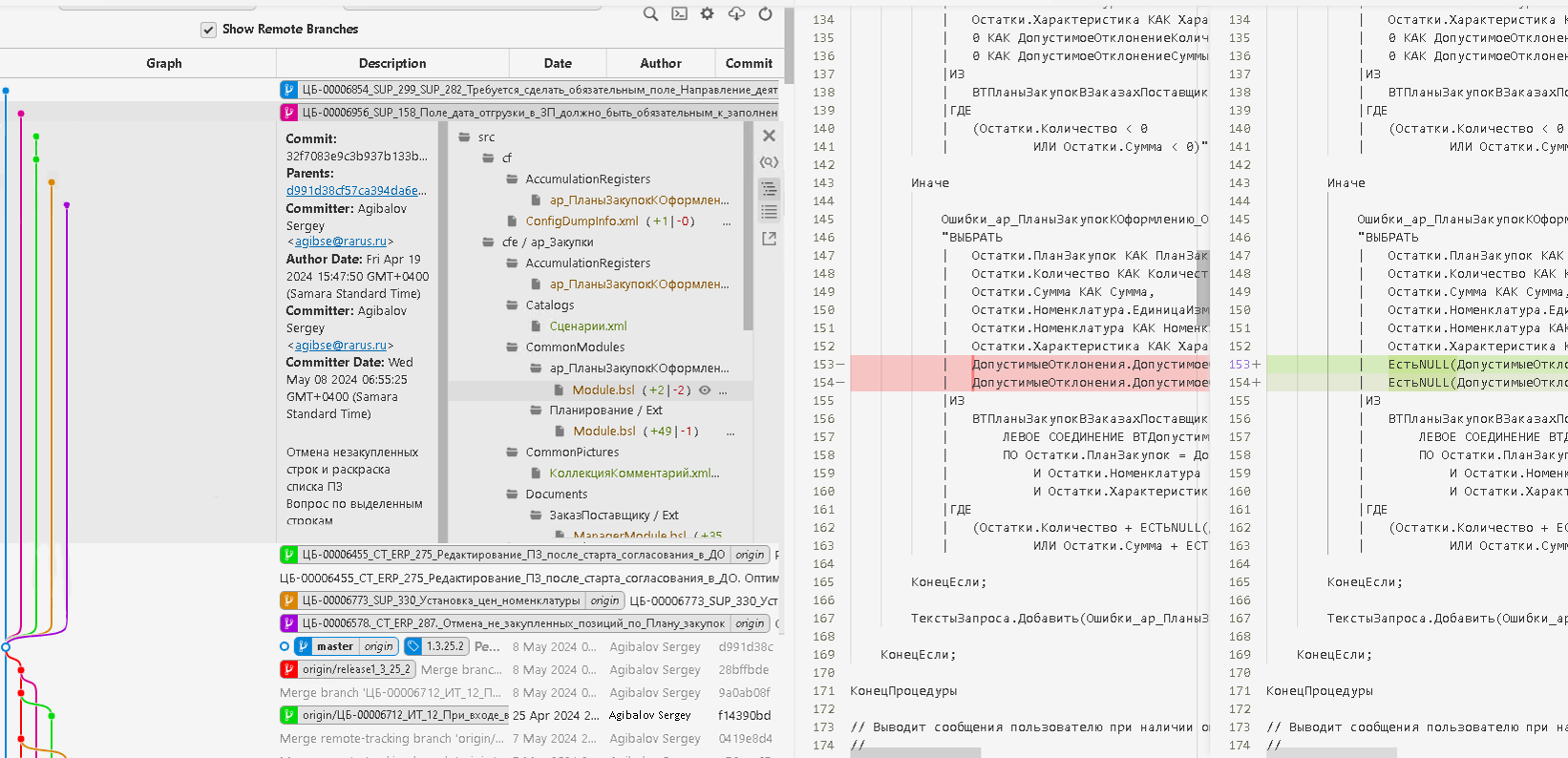
И главное, мы можем увидеть для каждой строчки кода информацию: кто, когда и в рамках какого требования изменял код:
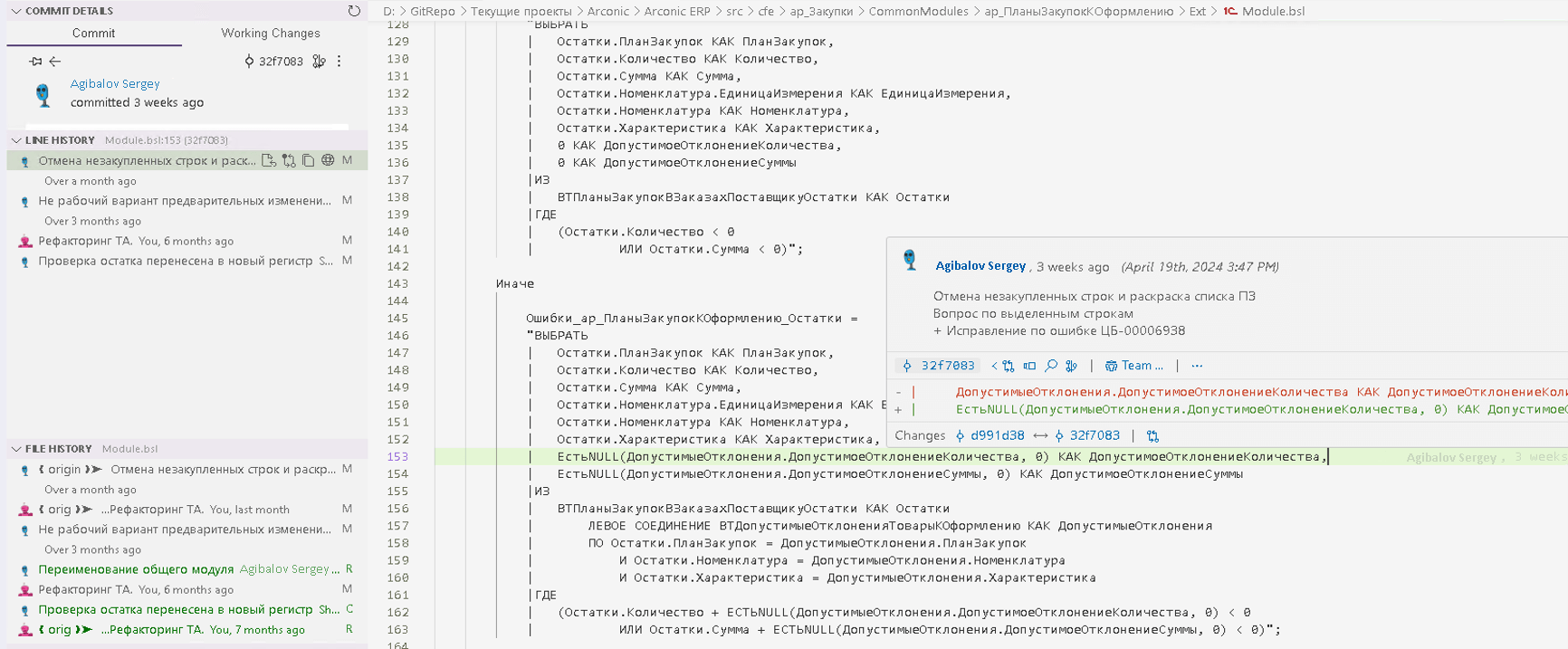
По сути дела репозиторий проекта перестает для нас быть просто каталогом с исходными файлами, а становится средством ведения хронологии документации проекта.
Сборка cf и cfe
В Git-репозитории мы не храним бинарные файлы cf или cfe. Для нас важна только файловая выгрузка конфигурации и расширений. Так как именно по ним можно вести хронологию построчных изменений.
В случае формата хранения EDT, бинарные файлы можно получить с помощью одноименной среды разработки.

В сервисе GitHub доступен открытый проект 1C:CICD (github.com/agibalovsa/-1C_CICD), в котором опубликованы данные скрипты:

Среди функционала скриптов можно выделить:
- Сборка cf, cfe из файлов XML.
- Загрузка конфигурации и расширениий из файлов XML, применение обновлений к ИБ.
- Полная выгрузка конфигурации и расширениий из файлов XML.
- Частичная выгрузка конфигурации, подготовка патча.
- Пересборка конфигурации после обновления для очистки фантомных изменений.
- Скрипты могут работать как с пакетным режимом конфигурации, так и с автономным сервером.
Вызов скриптов в разных режимах работы осуществляется через команду:
Давайте рассмотрим порядок применение скриптов во время работы.
Обновление конфигурации
Перед началом выполнения новой спецификации требований необходимо конфигурацию привести в соответствие с кодом в репозитории. Для этого у нас используется 2 скрипта:
- Обновление расширений конфигурации.
- Обновление конфигурации через патч.
В первом случае все очень просто: расширения загружаются из файлов. Данная операция выполняется довольно быстро.
Во втором случае все гораздо сложнее. Для таких крупных проектов, как ЕРП или УХ, размер репозитория достигает 12 ГБ.
Соответственно сборка cf файла может занимать как минимум 40 минут в пакетном режиме при условии, что у вас быстрые диски. Ситуация становится лучше при использовании автономного сервера (ibcmd), он создает cf за 10 минут, однако, это все еще долго. Загрузка cf или просто файлов в ИБ также занимает длительное время. Для интенсивной разработки такие задержки не подходят.
Поэтому мы составили алгоритм, который анализирует измененные файлы, и создает частичную выгрузку только для них.
Однако, есть ограничение в применении данного алгоритма. Измененные файлы выявляются относительно конфигурации поставщика, поэтому алгоритм эффективно работает только с конфигурациями, где измененные объекты частично сняты с полной с поддержки, то есть они остаются на поддержке, но появляется возможность редактирования. В ближайшем будущем мы сделаем скрипты еще более гибкими и эффективными.
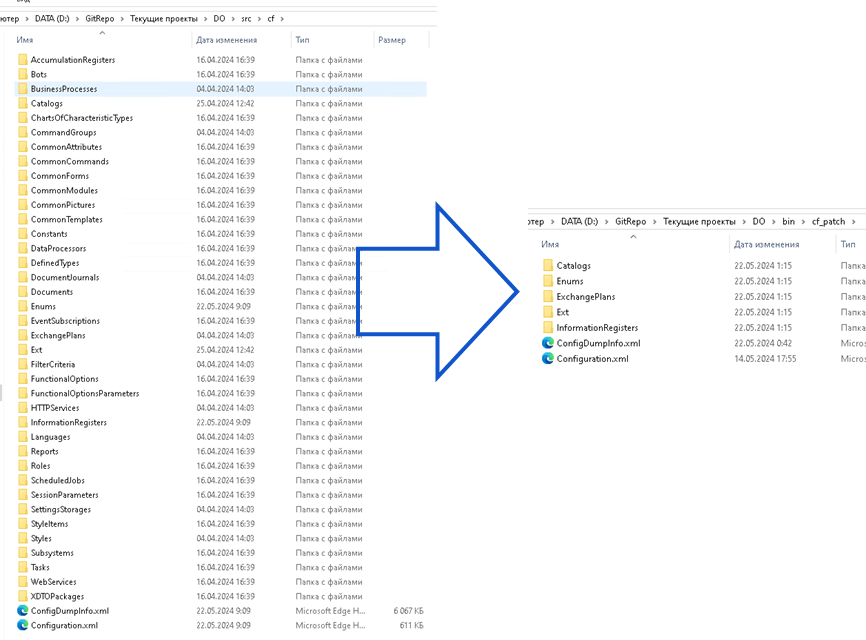
В итоге, для получения изменений из репозитория, мы загружаем не все файлы, а только измененные файлы относительно конфигурации поставщика. Создание частичной выгрузки выполняется за 1 минуту. Если аккуратно вносить изменения в основную конфигурацию, то размер выгрузки может достигать всего 12 МБ. А загрузка будет составлять всего 5 минут.
После загрузки в каталоге служебных файлов создается файл истории конфигурации для разработки ConfigDumpInfo.
Выгрузка изменений конфигурации
Опять же для расширений здесь все просто, разработчик выгружает их в репозиторий из конфигурации.
Для конфигурации выполняется следующий порядок действий:
- Разработчик выходит из конфигурации.
- Выполняется скрипт выгрузки файлов из конфигурации, для него передается как раз файл истории ConfigDumpInfo, полученный во время обновления. Благодаря чему выгружаются только добавленные объекты.
- Есть и технические ограничения платформы. Удаление или переименования метаданных в конфигурации провоцируют ее полную выгрузку вне зависимости от наличия файла ConfigDumpInfo. Но и здесь мы продумываем, как убрать эти ограничения с помощью скриптов.
Фиксация изменений в репозитории
Здесь все должно быть просто, нужно только зафиксировать изменения файлов в Git-репозитории. Однако, есть свои нюансы.
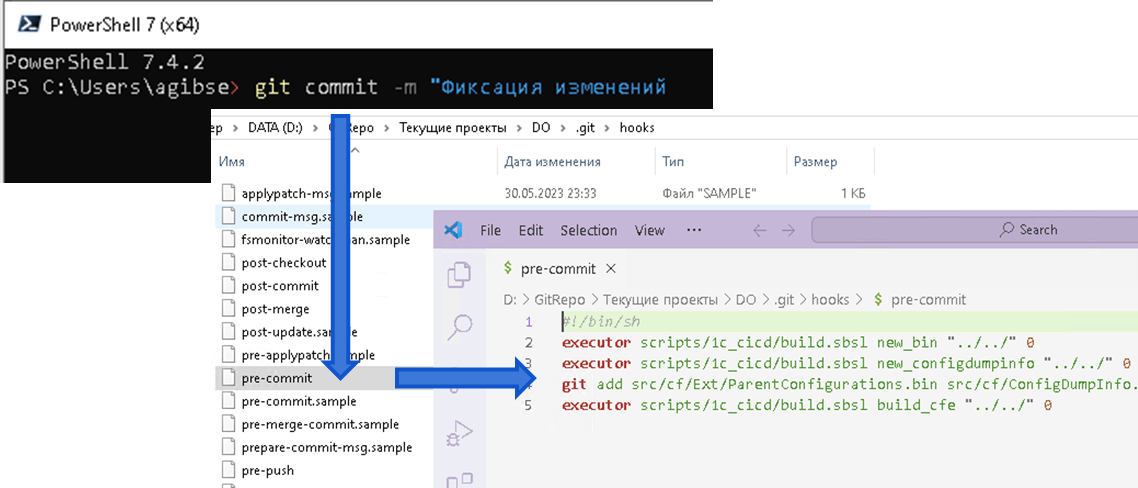
В Git можно настроить события при выполнении различных операций. Мы внесли изменения в событие pre-commit и при фиксации у нас выполняются дополнительные обработчики:
-
executor scripts/1c_cicd/main.sbsl build_cfe «.» 0
По измененным расширениям собираются cfe файлы, таким образом проверяется, что нет ошибок в структуре выгрузки. Особенно это полезно, когда происходят слияния веток проекта и возникают конфликты слияния. При разрешении конфликтов легко совершить ошибки. Проверочная сборка своевременно предупреждает о таких ошибках.
-
executor scripts/1c_cicd/main.sbsl new_configdumpinfo «.» 0
Для корректной работы скриптов в репозитории нам необходимо наличие файла ConfigDumpInfo. Однако, он содержит версии, которые у каждого разработчика свои. Поэтому мы удаляем из файла эти версии, оставляя в целостности саму структуру.
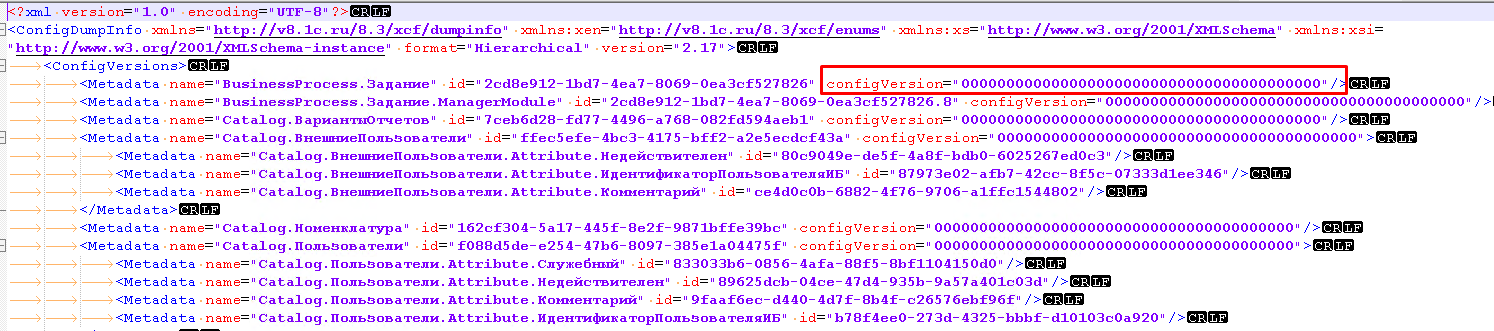
-
executor scripts/1c_cicd/main.sbsl new_bin «.» 0
Для избежания конфликтов слияния преобразуется файл ParentConfigurations. По какой-то причине разработчики 1С решили хранить в этом файле всю информацию одной строкой. Для корректной работы с репозиторием Git мы после каждой запятой поставили перенос строки. Самое интересное, что в таком виде конфигурация собирается и загружается без каких-либо проблем.
Очистка от фантомных различий после обновления
Наверное, всем известен факт, что после обновления конфигурации поставщика на новый релиз в отчете сравнения текущей конфигурации и конфигурации поставщика возникает множество фантомных изменений, которых фактически нет: изменения в описании, изменения в настройках полей форм и т. д. Как мы выяснили, данные изменения возникают из-за того, что конфигурация поставщика собирается на одной версии платформы, а наша разработка ведется на другой версии платформы, поэтому из‑за разности форматов хранения конфигураций проявляются множество незначительных различий.
В итоге мы добавили в наши скрипты команду, которая избавляет конфигурацию от этих различий:
Принцип ее работы следующий:
- После обновления конфигурации разработчик выгружает все изменения в репозиторий как есть, со всеми фантомными различиями.
- После чего запускаются скрипты в режиме build_prod:
- При выполнении скрипта конфигурация поставщика «Ext/ParentConfigurations/Конфигурация.cf» выгружается в файлы xml и из файлов собирается обратно. И потом, с новой конфигурацией поставщика, собирается обратно основная конфигурация в файл cf.
- Данный файл загружается обратно в разрабатываемую ИБ.
- И так как мы конфигурацию поставщика пересобираем на нашей версии платформы, все фантомные различия исчезают, как по волшебству.
- Хотя операция и долгая, но и в тоже время редкая. Поэтому она не мешает нашему циклу разработки.
Резюме
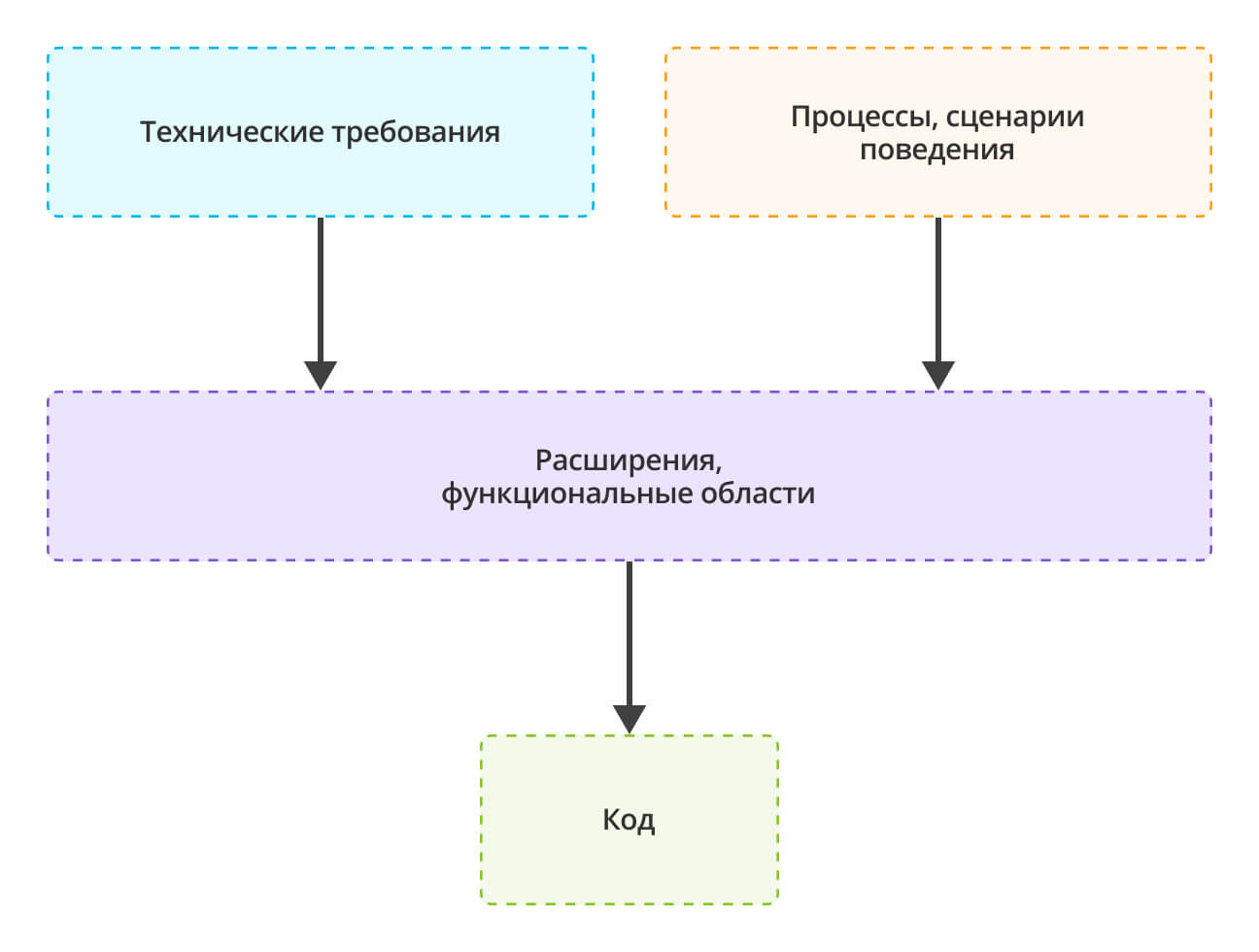
По техническим требованиям и процессам разработчик проектирует функциональные разделы и блоки в программе с помощью расширений, модулей и областей:
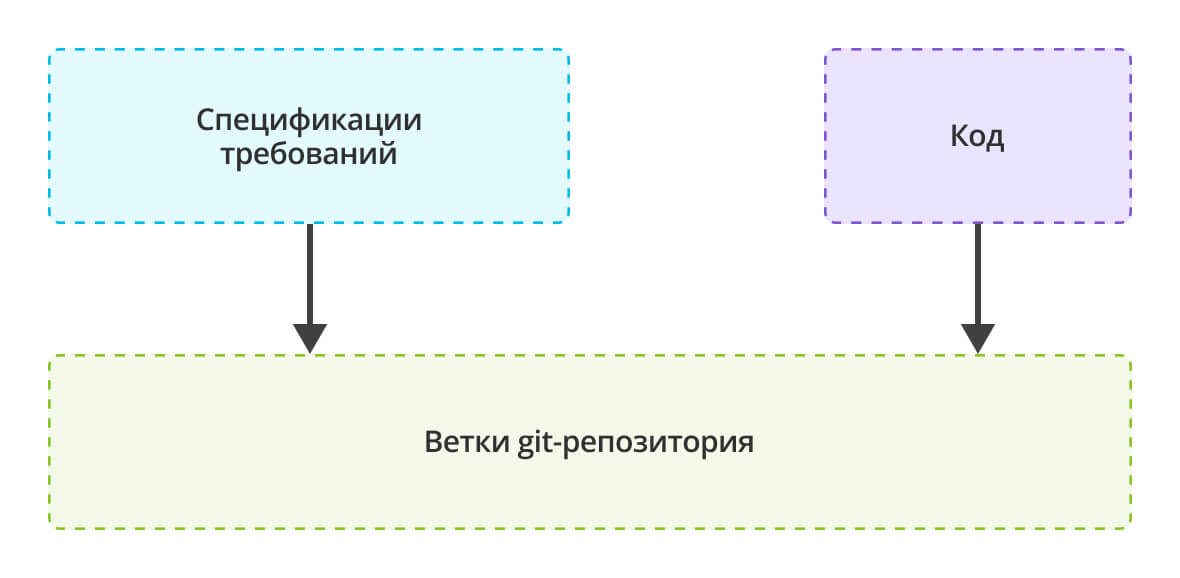
Все изменения сохраняются в репозитории проекта, а срез изменений соответствует поставленной в работу спецификации требований:
Тестирование и публикация релиза
Проверка SonarQube
Для нашей команды очень важно соблюдение стандартов написания кода. Все наверное в курсе, как сложно дорабатывать чужой код, если он по форме отличается от вашего. Также очень важно соблюдать стандарты разработки — это в разы уменьшает вероятность различных технических ошибок в будущем.
За качеством кода у нас следит SonarQube, он запускается из GitLab:
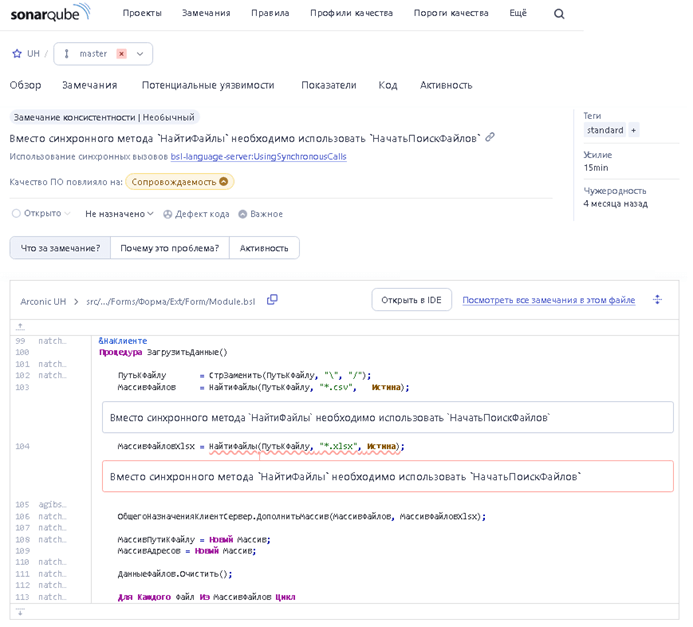
Как только разработчик размещает изменения в своей ветке, он создает запрос на слияние в GitLab. Это выступает триггером для запуска SonarQube. SonarScanner подгружает все изменения и проверяет их с помощью открытой компоненты BSL Language Server. Примерно через 10 минут формируется рассылка только по тем ошибочным строчками кода, которые были изменены в рамках указанной ветки в запросе на изменение.
Тестирование функционала
Как ранее говорилось, сценарии тестирования готовятся еще на этапе технического проектирования и они фиксируются в шагах процессов. По составленным сценариям поведения формируется протокол тестирования, по которому разработчик снимает на видео (с помощью программы ScreenToGif) все свои действия, и прикладывает получившийся файл в спецификацию требований, в качестве подтверждения окончания разработки:
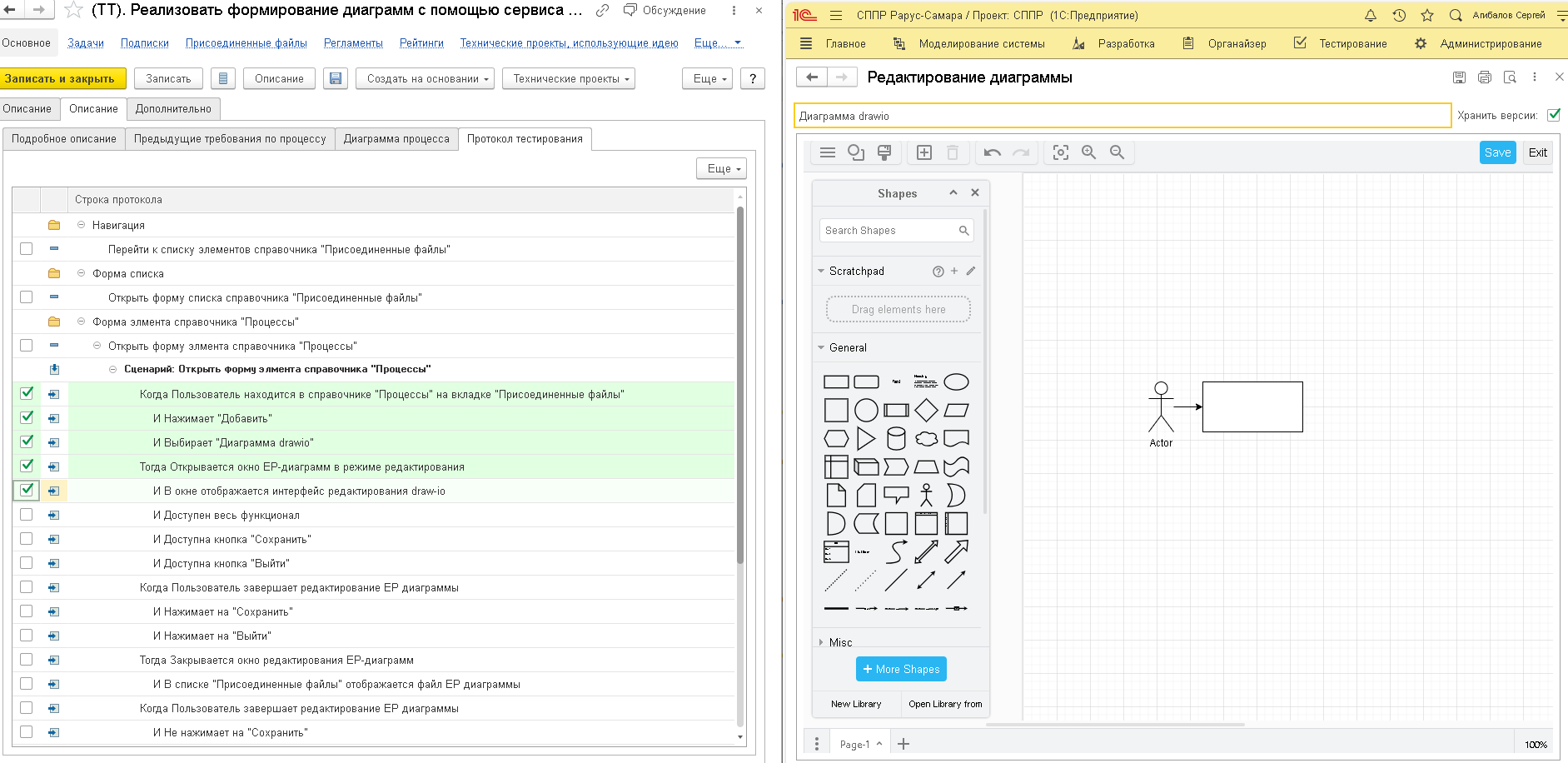
На приложенном рисунке видно, как разработчик. отмечая шаги тестирования по написанному ранее сценарию поведения, выполняет тестирование в самой системе.
При просмотре данного файла у архитектора и методолога возникает понимание, каким образом была проведена разработка, все ли моменты были учтены. Таким образом проводится предварительное тестирование руками разработчика.
Тестовая сборка
Если, например, взять неделю разработки, то наше Git-хранилище представляет из себя заросли из веток разработки.
У нас тут есть и независимые ветки, и связанные ветки. И все эти изменения нужно в итоге протестировать уже методологам. База для тестирования у нас одна, поэтому когда выкладывается изменения по одной ветке, нужно бы не забыть изменения и по другой ветке:
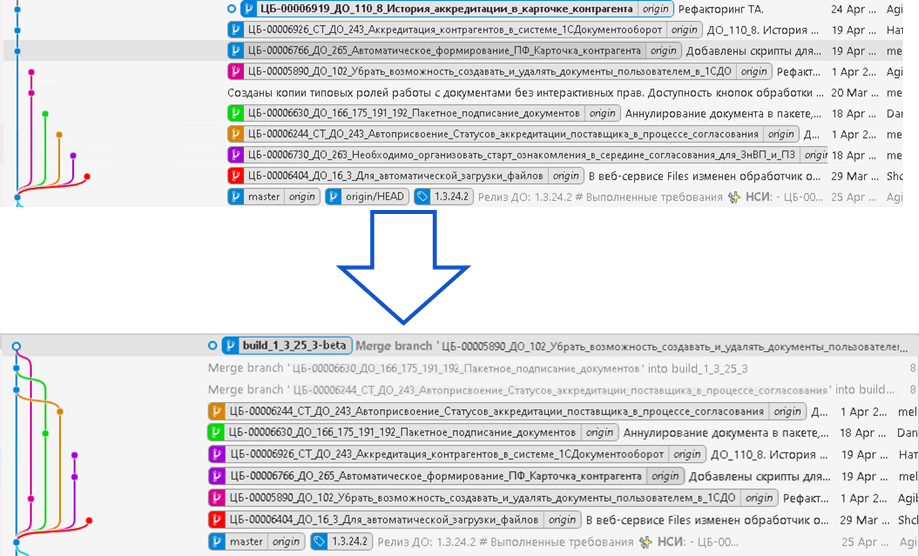
Для преодоления этой коллизии мы создаем новую ветку build. С ней сливаются все остальные ветки, которые необходимо протестировать. Нужно учесть ряд принципиальных правил, чтобы данный подход был эффективен:
- В репозитории может существовать только одна ветка сборки.
- Ветка сборки всегда временная.
- В ветку сборки нельзя помещать никаких изменений, кроме разрешения конфликтов слияния.
- Любой разработчик может вносить в ветку сборки свои ветки разработки, после чего собирать бинарные файлы проекта и обновлять тестовую ИБ.
- При помещении веток разработки в основную ветку master, ветка сборки удаляется.
В итоге разные разработчики все время дополняют общую ветку сборки своими изменениями, которые потом выносят в тестовую ИБ.
Нумерация веток сборок ведется централизованно в СППР в справочнике «Сборка версии»:
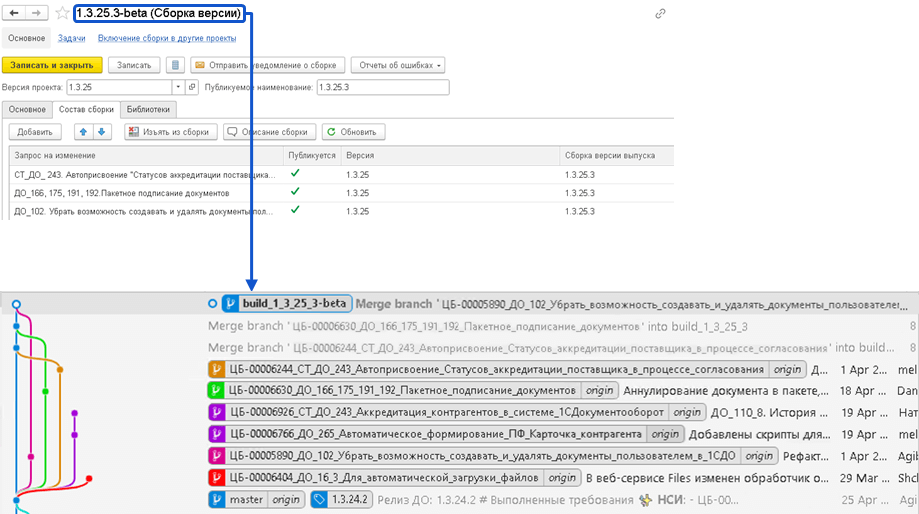
Мы специально сделали доработку, чтобы к элементу справочника «Сборка версий» можно было прикреплять спецификации требований, которые необходимо отдавать на тестирование.
После создания сборки в СППР, все спецификации автоматически передаются методологу на проверку.
Описание сборки
После формирования сборки генерируется ее описание, которое рассылается в общий чат проекта. Данное описание можно формировать несколько раз за день, выделяя новые пункты, которые попадают в сборку:
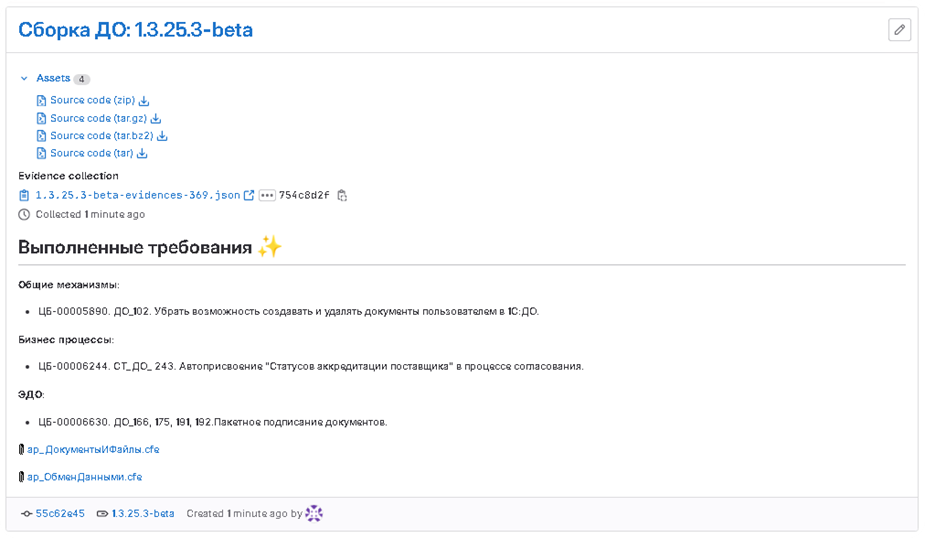
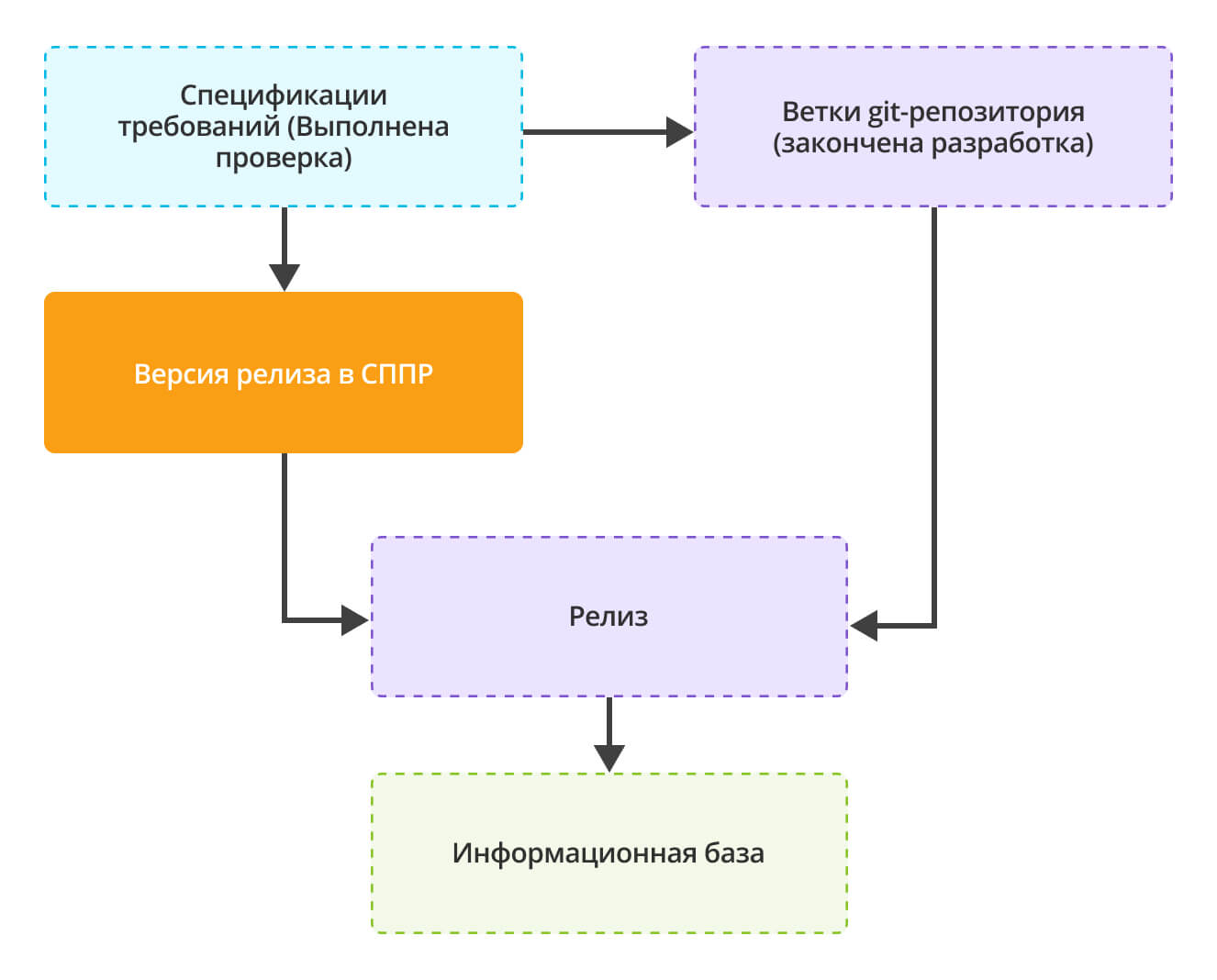
Релиз
После того, как часть спецификаций протестирована, приходит пора формирования релизной сборки. Для этого методологи в спецификациях требований выставляют соответствующий статус и передают их на технического архитектора.
Архитектор формирует в СППР финальную сборку с новым номером, а в Git формирует ветку release. Также как и разработчики он соединяет с данной веткой все проверенные ветки разработки, разрешает конфликты слияния, вносит местами незначительные правки. В итоге получившаяся ветка помещается в master. А ветка build удаляется:
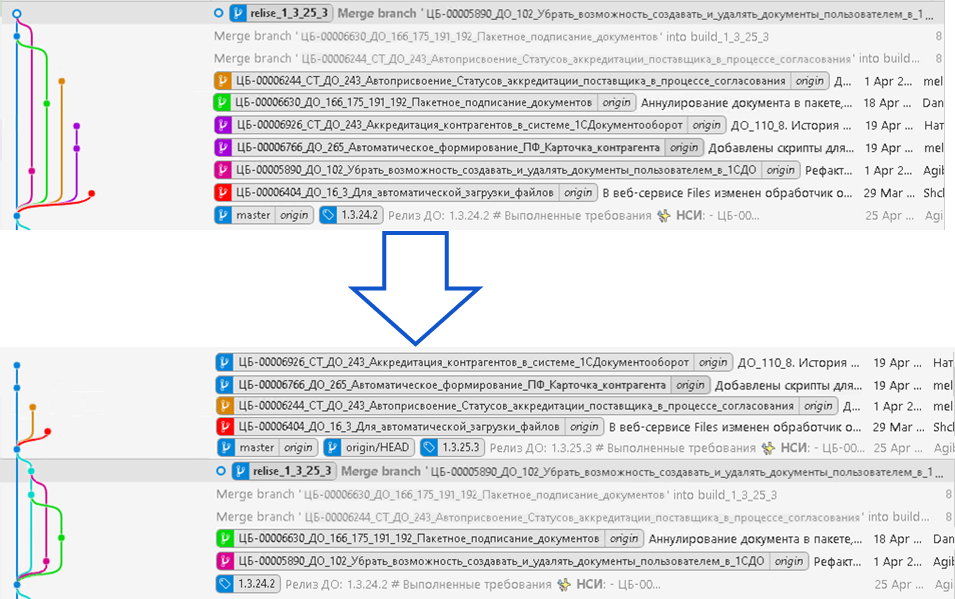
Все остальные ветки, которые не попали в релиз, перетаскиваются поверх ветки master с помощью команды git rebase. Таким образом они обновляются свежей информацией из ветки master и разработчики могут продолжать работать с данными ветками, получив все последние обновления.
По выпущенному релизу также формируется описание релиза, которое рассылается письмами заказчику:
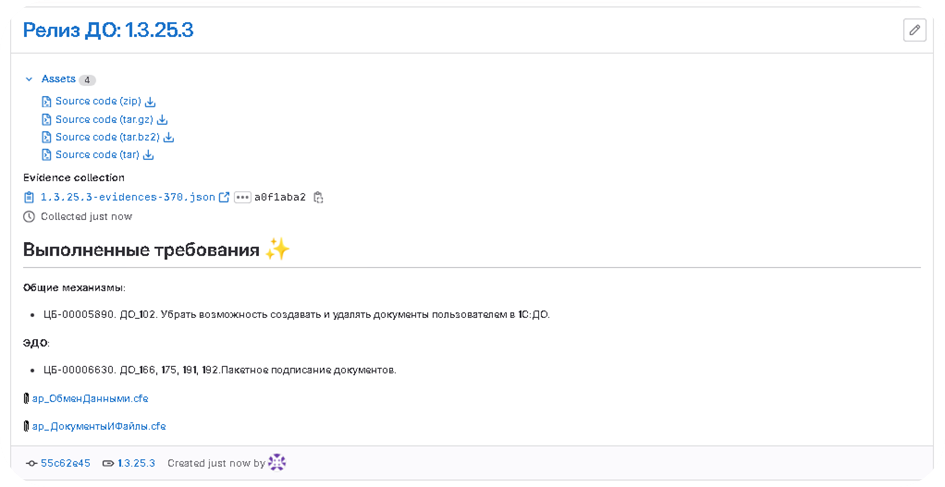
Обновление ИБ
Заключительный этап разработки — это обновление рабочей ИБ:
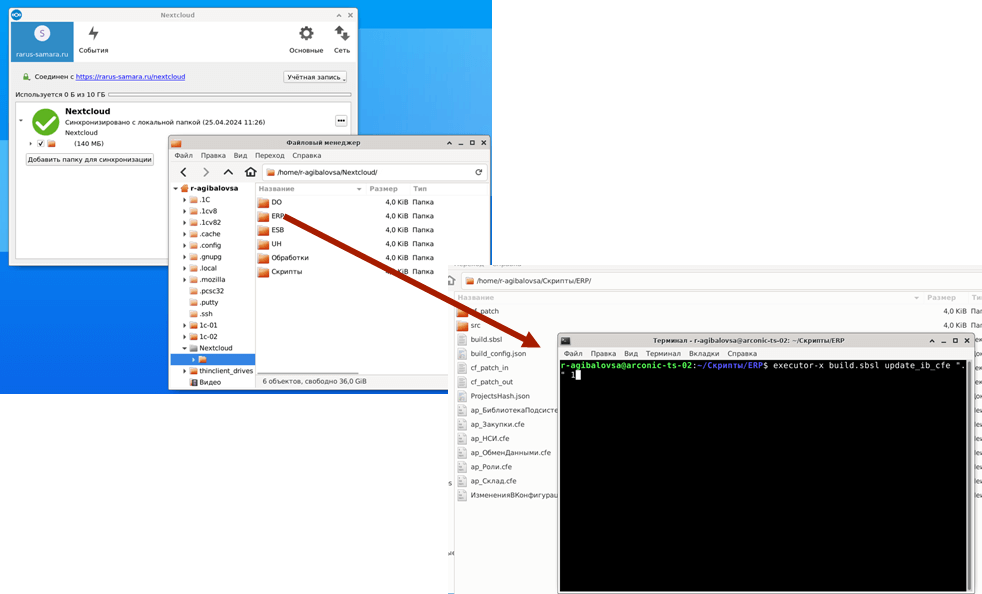
Для передачи сгенерированных бинарных файлов с одного компьютера на другой используется облачное хранилище Nextcloud. Это специализированный сервис с открытым исходным кодом для хранения и передачи файлов. С помощью агентов данный сервис может синхронизировать сразу несколько компьютеров.
Для загрузки конфигурации в ИБ используются все те же скрипты 1C:CICD (github.com/agibalovsa/-1C_CICD). Они загружают в ИБ расширения и частичную выгрузку. Для быстрого контроля метаданных основной конфигурации перед обновлением формируется файл сравнения изменения обновленной конфигурации и конфигурации в ИБ, также выполняется проверка модулей и применения расширений.
Ответственный сначала проверяет файл сравнения для основной конфигурации, что попали только нужные изменения метаданных, и только потом нажимает кнопку «Обновить».
Резюме
- По сценарию поведения разработчик выполняет внутреннее тестирование кода.
- Из веток разработок в Git собирается ветка сборки для тестирования.
Спецификации требований, соответствующие веткам разработки, которые включены в ветку сборки, передаются методологам на тестирование:
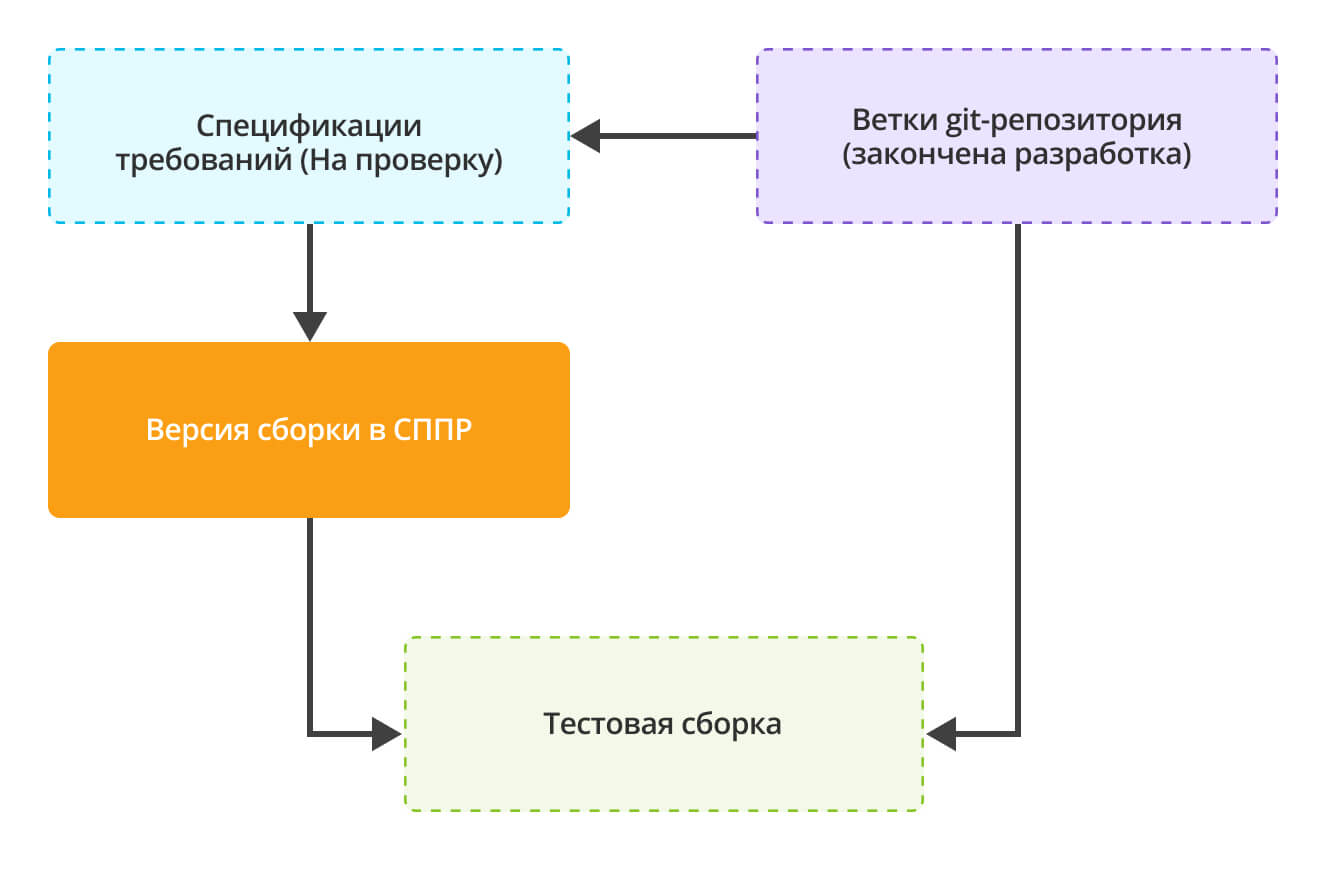
- Протестированные и подтвержденные спецификации передаются на включение в финальный релиз.
- По веткам разработки, соответствующим подтвержденным спецификациям, формируется релиз.
Релиз применяется к рабочей информационной базе:
Послесловие
Что можно сказать после всего того, что было изложено выше: написание обработки и промышленный процесс разработки это разные вещи. «Ну это же очевидно» скажет читатель. Все так, однако величину разницы стоит прочувствовать.
Цель материала не только поделиться нашим подходом к созданию сквозного процесса управления разработкой от теории до практики, но и дать возможность читателю взглянуть на картину в ее целостности и оценить масштаб. Кроме идеи управления, применяемых инструментов следует отметить следующее: для достижения цели, то есть ритмичного получения качественных изменений в рабочей ИБ, необходима воля, которая доставляет дисциплину исполнения начертанного. Воля же возможна только и исключительно при наличии ее носителя - человека. Поэтому главный вывод — профессиональные волевые сотрудники нужнее всего.
Вниманию читателя мы предлагаем запись доклада Сергея Агибалова, автора этой статьи, с 1C‑RarusTechDay 2024 «1С:СППР как система учёта задач и разработки вместе с GIT на крупных коммерческих проектах»:
От экспертов «1С-Рарус»











Читайте первыми статьи от экспертов «1С‑Рарус»
Вы можете получать оповещения по электронной почте
Или получайте уведомления в телеграм-боте







