



Оглавление
Введение
Мы продолжаем рассказывать вам о возможностях для расследования, которые предоставляет «1С-Рарус: Мониторинг производительности». На этот раз мы построим наш рассказ немного иначе и расскажем вам об использовании системы и ее возможностей в рамках набора сквозных случаев.
Мы не будем касаться базовых возможностей системы и того, как устроен цикл сбора и анализа логов в «1С-Рарус: Мониторинг производительности», а сразу перейдем к описанию экспертных случаев и методам их расследования. С вышеописанными аспектами системы вы можете ознакомиться в первой части статьи.
Случай 1. Часто исполняемые запросы
В процессе анализа проблем производительности на этапе анализа исполняемых в системе длительных запросов может возникнуть ситуация, когда среди запросов нет явных лидеров. В таком случае, следующим этапом анализа будет проверка того, какую нагрузку в системе создают самые часто исполняемые запросы.
Для рассмотрения данного случая мы пройдем все этапы настройки сбора логов технологического журнала 1С на стороне сервера, который подвергается мониторингу, а также анализ построенных на стороне «1С-Рарус: Мониторинг производительности» диаграмм.
Об исследуемой информационной базе
В качестве информационной базы, которая подвергается мониторингу, рассмотрим специальный демо-стенд, содержащий проблемный код.
Демо-стенд — это специальная информационная база, основанная на файле выгрузки ИБ «каркасной» конфигурации для решения задач при подготовке к экзамену «1С:Специалист» по платформе «1С:Предприятие 8» (static.1c.ru/rus/partners/training/files/new_carcass_8_3_17_1496.dt). В конфигурации был добавлен ряд объектов для демонстрации возможностей «1С-Рарус: Мониторинг производительности» безотносительно исследуемой информационной базы.
Нашей задачей будет подключить развернутую информационную базу с демо-стендом на сервере 1С к мониторингу и произвести анализ возникающих в системе проблем, в частности, показать возможности анализа часто исполняемых запросов.
Настройка сбора и отправки логов при помощи «Агента настройки компонентов мониторинга»
Давайте настроим сбор и отправку логов технологического журнала 1С при помощи специальной формы «Агента настройки компонентов мониторинга». Данная форма представляет из себя специальную программу, которая поставляется в дистрибутиве «1С‑Рарус: Мониторинг производительности» в подкаталоге «agent»:
Каталог содержит исполняемый файл для запуска программы, а также ряд вспомогательных конфигурационных файлов и скриптов python, которые и занимаются сбором и отправкой логов.
Скопируем данный каталог на сторону сервера, который будем мониторить и запустим исполняемый файл от имени администратора. Форма настройки содержит набор вкладок, переключение между которыми осуществляется при помощи кнопок на боковой панели. Рекомендуется идти по вкладкам в порядке их расположения в боковом меню и настроить необходимые компоненты. На первой вкладке агента настройки предлагается настроить путь к каталогу с установленным python. В том случае, если python на сервере еще не установлен, то есть возможность его установки путем нажатия на соответствующую кнопку:
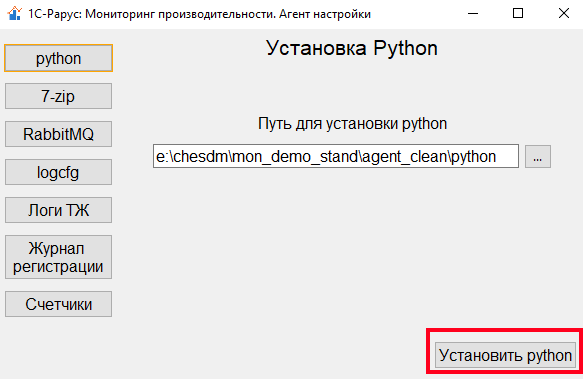
Для сбора отправки логов технологического журнала 1С нам также понадобится архиватор 7-zip. Его также можно установить при помощи агента настройки на соответствующей вкладке:
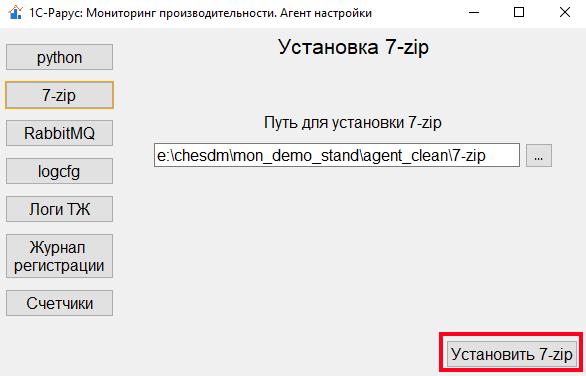
Следующим компонентом, необходимым для работы мониторинга, является брокер сообщений, через который данные логов передаются на сторону «1С‑Рарус: Мониторинг производительности». В качестве брокера сообщений система использует RabbitMQ, поэтому в агенте мониторинга необходимо указать соответствующие параметры подключения. Более подробную информацию об установке этого инструмента вы можете найти на официальном сайте, где также можно скачать его дистрибутив. Протестировать соединение с брокером можно по нажатию соответствующей клавиши:
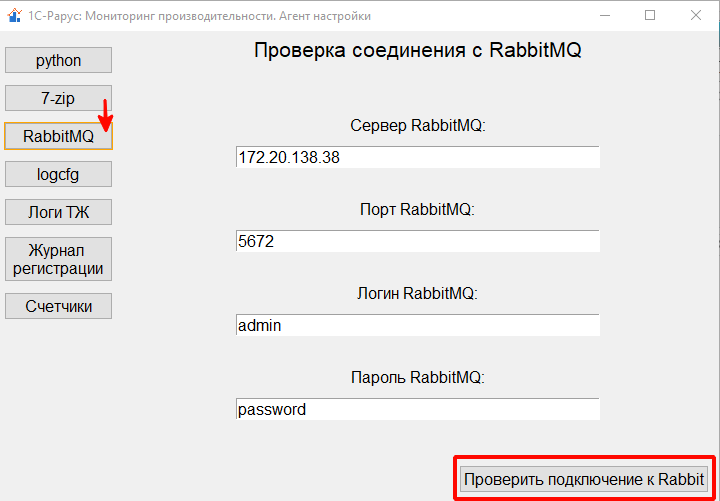
Стоит отметить, что в дальнейшем мы будем развивать поддержку альтернативных способов передачи данных на сторону «1С‑Рарус: Мониторинг производительности».
Далее настроим сбор событий логов технологического журнала 1С при помощи модификации конфигурационного файла logcfg.xml. Сделать это можно также на отдельной вкладке агента настройки, указав: путь к каталогу, в который будет производить сбор данных; путь к файлу logcfg.xml, при условии, что расположения файла конфигурации не стандартное; а также опционально можно указать имя информационной базы в кластере, которую мы предпочитаем мониторить.
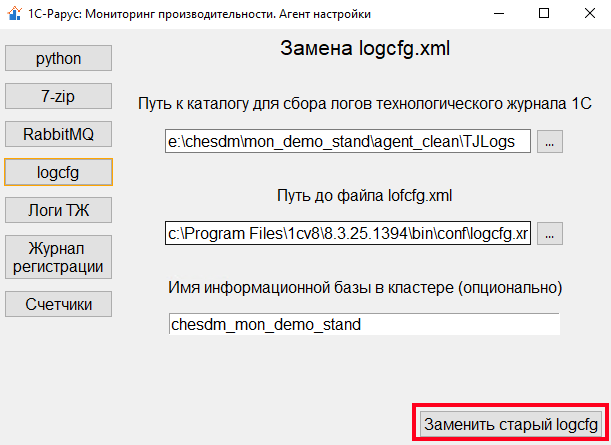
Старый файл logcfg.xml будет заменен новым, предлагаемым агентом по умолчанию. Предлагаемый конфигурационный файл содержит весь необходимый для анализа на стороне «1С‑Рарус: Мониторинг производительности» набор событий и отборов.
Пример такого logcfg.xml:
<?xml version='1.0' encoding='utf-8'?>
<config xmlns="http://v8.1c.ru/v8/tech-log">
<log history="1" location="e:\chesdm\mon_demo_stand\agent_clean\TJLogs">
<event>
<eq value="CALL" property="Name" />
<eq value="chesdm_mon_demo_stand" property="p:processName" />
</event>
<event>
<eq value="SCALL" property="Name" />
<eq value="chesdm_mon_demo_stand" property="p:processName" />
</event>
<event>
<eq value="TLOCK" property="Name" />
<eq value="chesdm_mon_demo_stand" property="p:processName" />
</event>
<event>
<eq value="TDEADLOCK" property="Name" />
<eq value="chesdm_mon_demo_stand" property="p:processName" />
</event>
<event>
<eq value="TTIMEOUT" property="Name" />
<eq value="chesdm_mon_demo_stand" property="p:processName" />
</event>
<event>
<eq value="DBPOSTGRS" property="Name" />
<eq value="chesdm_mon_demo_stand" property="p:processName" />
</event>
<event>
<eq value="DBMSSQL" property="Name" />
<eq value="chesdm_mon_demo_stand" property="p:processName" />
</event>
<event>
<eq value="DBDA" property="Name" />
<eq value="chesdm_mon_demo_stand" property="p:processName" />
</event>
<event>
<eq value="SDBL" property="Name" />
<eq value="chesdm_mon_demo_stand" property="p:processName" />
</event>
<event>
<eq value="SESN" property="Name" />
</event>
<event>
<eq value="DBCOPIES" property="Name" />
</event>
<event>
<eq value="CONN" property="Name" />
</event>
<event>
<eq value="ATTN" property="Name" />
</event>
<event>
<eq value="VRSREQUEST" property="Name" />
</event>
<event>
<eq value="VRSRESPONSE" property="Name" />
</event>
<event>
<eq value="EXCP" property="Name" />
</event>
<event>
<eq value="EXCPCNTX" property="Name" />
</event>
<event>
<eq value="CLSTR" property="Name" />
</event>
<property name="all" />
</log>
</config>
Проверим, что логи начали собираться в указанный каталог:
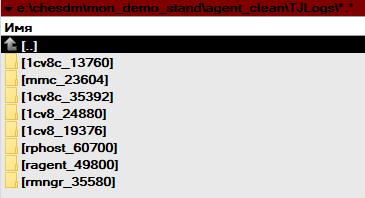
После того, как мы стартовали сбор логов путем настройки logcfg.xml, перейдем на вкладку «Логи ТЖ». На данной вкладке агента настройки зададим параметры сбора и отправки логов технологического журнала 1С в очередь сообщений RabbitMQ. Если на предыдущих шагах мы указали параметры расположения python, 7-zip и RabbitMQ, а также каталог сбора логов, то все что остается — это назначить имя очереди в брокере и интервал сбора данных:
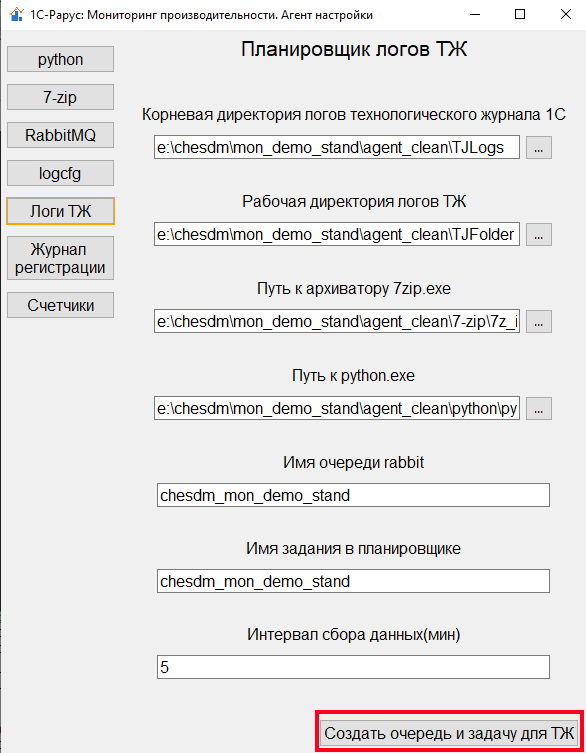
В результате будет создана задача в планировщике событий Windows Scheduler, которая будет запускать скрипт сбора и отправки данных в брокер сообщений:
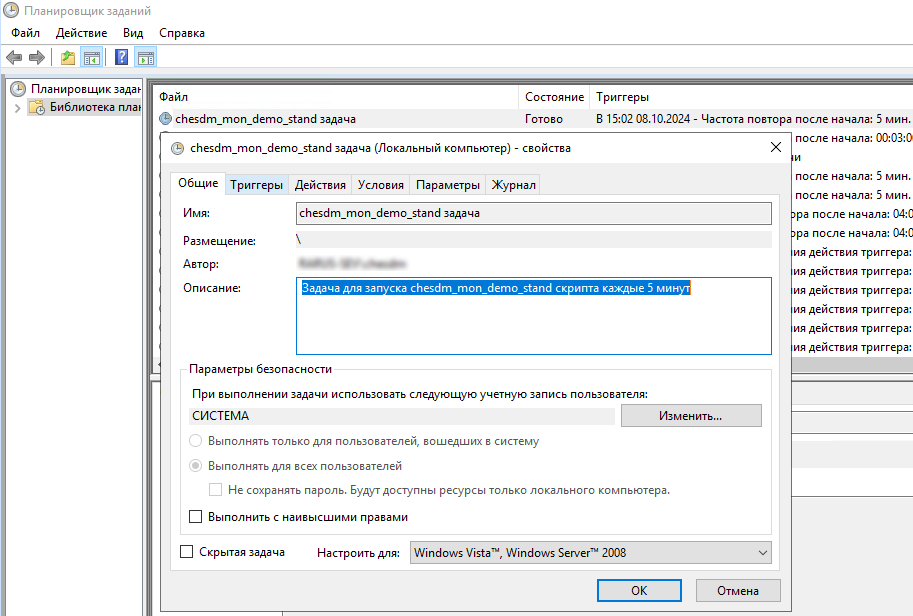
Как мы уже показывали на схеме жизненного цикла сбора и анализа данных в первой части статьи, скрипт будет собирать только новые накопившиеся с прошлого запуска логи, архивировать их и отправлять в брокер.
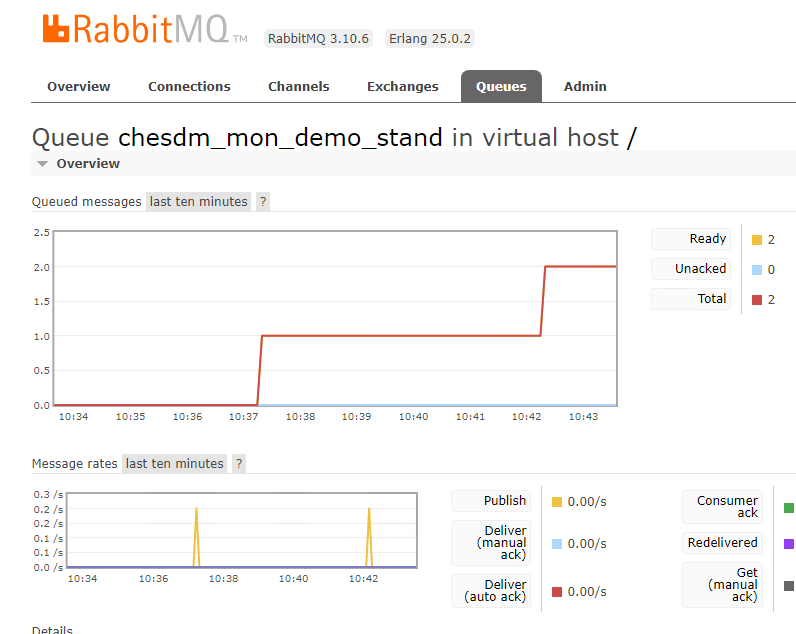
Результатом работы агента настройки будет наличие в очереди в брокере сообщений с логами технологического журнала исследуемой информационной базы. Все вышеописанные действия можно произвести буквально за несколько минут при помощи агента настройки компонент мониторинга.
Настройка анализа логов на стороне «1С‑Рарус: Мониторинг производительности»
После того, как мы настроили сбор и отправку логов технологического журнала 1С на стороне сервера, который подвергается мониторингу, нам необходимо настроить анализ поступающих логов на стороне «1С‑Рарус: Мониторинг производительности».
Для анализа логов в решении существует специальный сценарий «Анализ технологического журнала мониторинг», который разделен на два подсценария: служебный, выполняемый один раз при инициализации нового анализа, а также каждый раз при переходе системы на новый релиз, и серверный, который и занимается преобразованием полученных логов и их отправкой в место хранения — СУБД ClickHouse. Данный сценарий выполняется на постоянной основе по расписанию.
Сценарий «Анализ технологического журнала мониторинг (служебный)» позволяет развернуть основную инфраструктуру для работы механизма: каталоги со скриптами, каталоги для временного хранения и обработки логов счетчиков производительности.
В окружении служебного сценария необходимо указать такие параметры, как путь к рабочему каталогу для хранения служебных файлов, а также путь к Python на стороне «1С‑Рарус: Мониторинг производительности» для того, чтобы система смогла установить и обновить набор библиотек, необходимых для парсинга логов. Также важно указать правильный вид источника данных, так как система умеет работать с логами технологического журнала 1С, логами журнала регистрации и значениями счетчиков оборудования.
В нашем случае мы анализируем логи технологического журнала 1С. После настройки окружения сценарий необходимо выполнить вручную нажатием соответствующей кнопки:
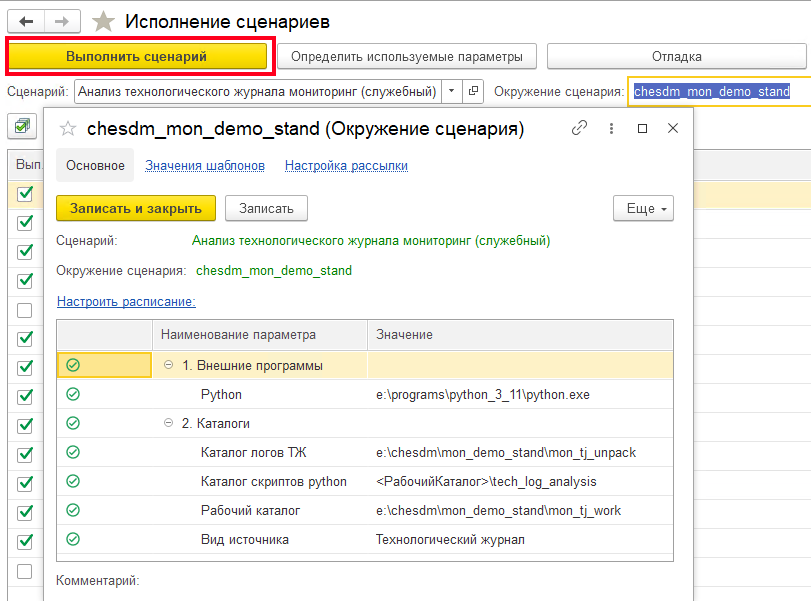
Далее перейдем в сценарий «Анализ технологического журнала мониторинг (сервер)». Основное назначение данного сценария — выполнение загрузки счетчиков из RabbitMQ, их обработка и отправка в ClickHouse. В параметрах окружения серверного сценария необходимо дополнительно указать параметры подключения к RabbitMQ, откуда система будет забирать сообщения с логами, а также параметры подключения к ClickHouse, в который будет производиться отправка преобразованных логов:
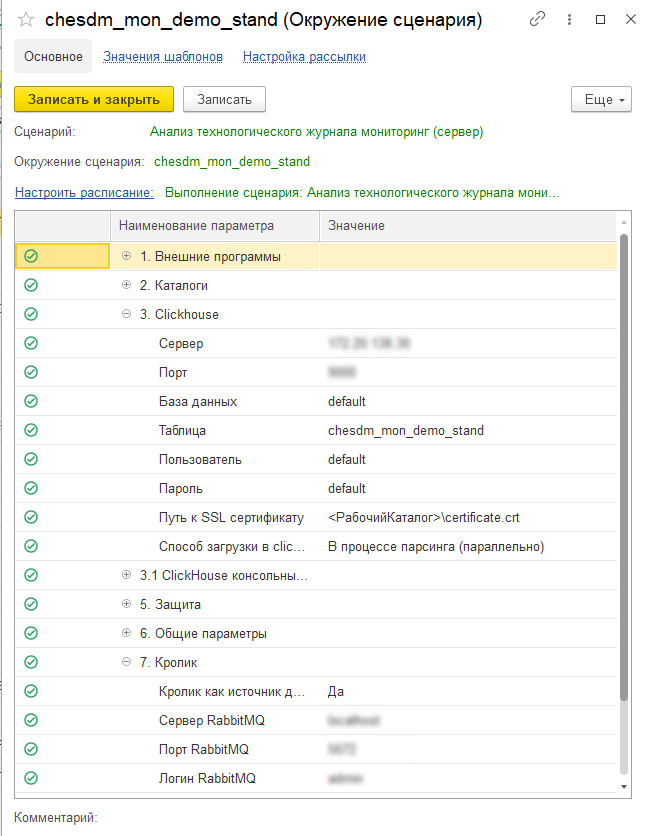
Выполнение сценария необходимо настроить по расписанию, время повтора должно быть не больше, чем время отправки сообщений в очередь на стороне сервера, который подвергается мониторингу:
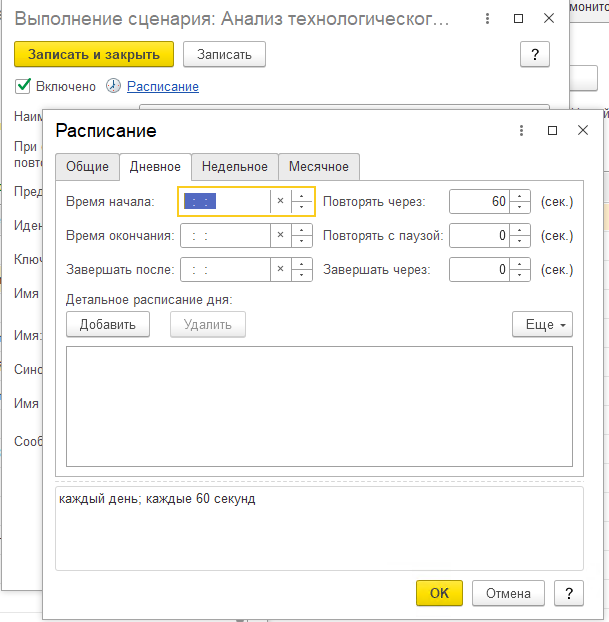
Результатом настройки должно стать наличие записей в указанной в параметрах таблице в СУБД ClickHouse:
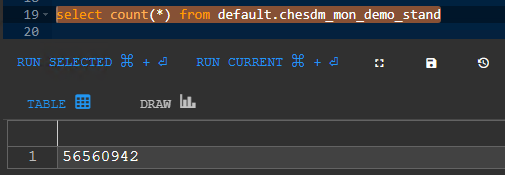
После выполнения вышеописанных действий можно переходить к анализу логов при помощи досок диаграмм. Стоит отметить, что данные действия выполняются единоразово и далее нам понадобятся только диаграммы и их расшифровки, о чем поговорим далее.
Конфигурирование исследуемой информационной базы
После того, как сбор и преобразование логов настроены, можем приступить к воспроизведению рассматриваемого случая. Как мы уже упоминали ранее, для того, чтобы показать расследование часто исполняемых в системе запросов безотносительно конкретных случаев, которые возникают у клиентов, для демонстрации данного случая мы используем специальный демо-стенд.
Предположим, что у нас есть неоптимально написанный код, который содержит запрос в цикле. Добавим специальную обработку, которая будет копировать документы «Приходная накладная» и проводить их в цикле указанное количество раз, что будет эмулировать проведение документа, часто используемого в крупных системах:
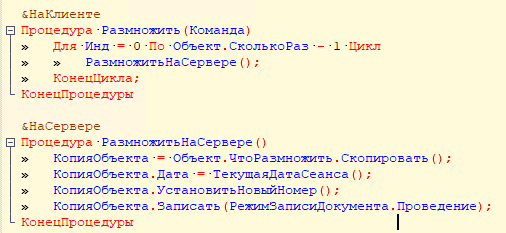
При этом в обработке проведения приходной накладной разработчик при обходе табличной части обращается к реквизиту номенклатуры «ВидНоменклатуры» для фильтрации данных для движений:

И все бы хорошо, вот только такая конструкция создаст неявный запрос к СУБД в цикле, причем выбраны будут не только вид номенклатуры, но и все реквизиты записи. При этом, номенклатура часто является одним из самых нагруженных справочников в системе по количеству и составу реквизитов, которые, в том числе, могут быть двоичными данными:
Сгенерируем элементы справочника номенклатуры и эталонный документ «Приходная накладная», который будем копировать. В изображение номенклатуры поместим большое gif изображение размером 25 МБ:
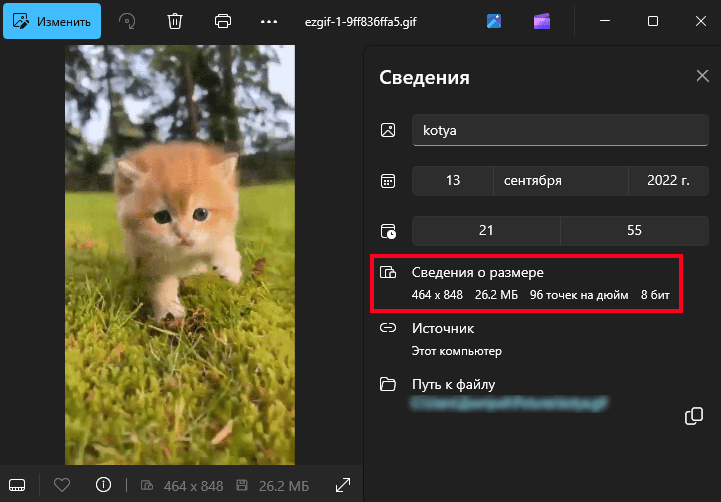
Сама же приходная накладная будет содержать всего 3 строки в табличной части:
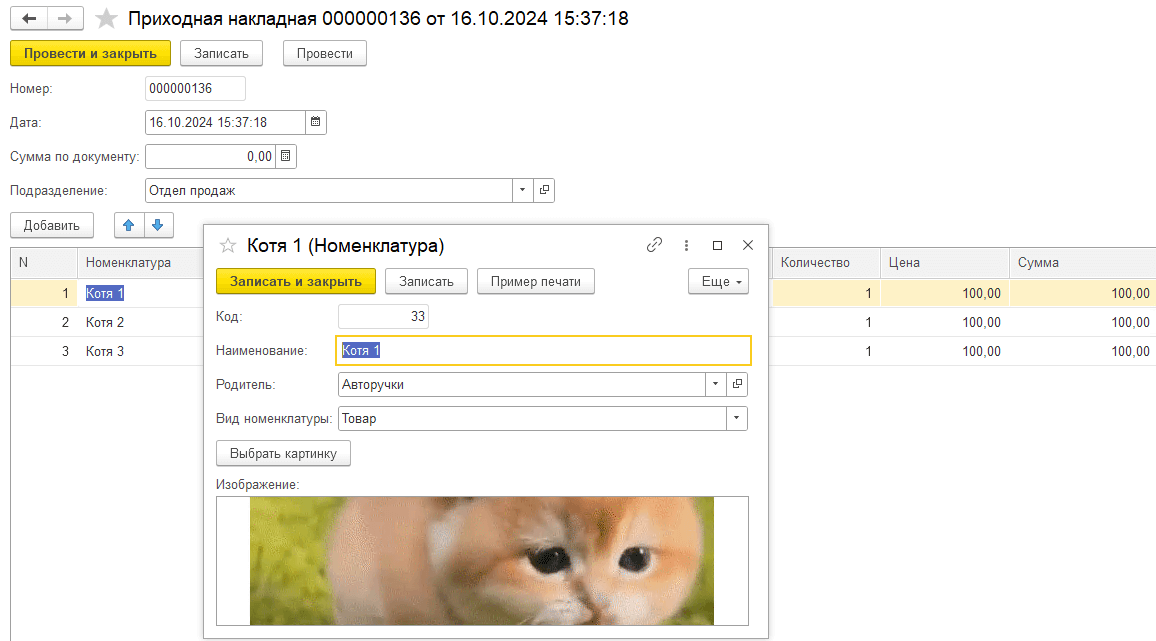
В результате, такой, казалось бы, тривиальный код порождает проблемы при проведении даже на пустой базе. Ведь изображение может быть размером в несколько мегабайт.
Попробуем отловить данный неоптимальный код при помощи анализа логов в «1С‑Рарус: Мониторинг производительности».
Анализ часто исполняемых запросов
Итак, чтобы произвести анализ необходимо открыть рабочее место «Доски диаграмм», о котором мы уже рассказывали в первой части статьи. Для анализа запросов нам понадобится доска «Поставляемая доска универсальный монитор». В левой нижней части рабочего места необходимо указать контекст построения, в том числе, окружение с параметрами, необходимыми для анализа. В первую очередь это параметры источника данных — СУБД ClickHouse и таблицы, из которой необходимо забрать данные для построения диаграмм:
Далее строим доску нажатием соответствующей кнопки и переходим на вкладку «Пирог по запросам». Подробней про состав универсальной доски мы уже рассказывали в первой части статьи, здесь лишь отмечу, что для текущего анализа нам могут понадобиться диаграммы «Суммарная длительность запросов по context», «Суммарная длительность запросов по sql», а также «Суммарная длительность CALL по context».
Данные диаграммы покажут нам разные данные, потому что у нас могут быть случаи, когда один и тот же запрос выполняется из разных мест системы, и случаи, когда одна и та же строка контекста порождает несколько запросов.
Взглянем на диаграмму с группировкой по контексту. Как мы видим, одним из лидеров является как раз строка из обработки проведения приходной накладной в демо стенде:
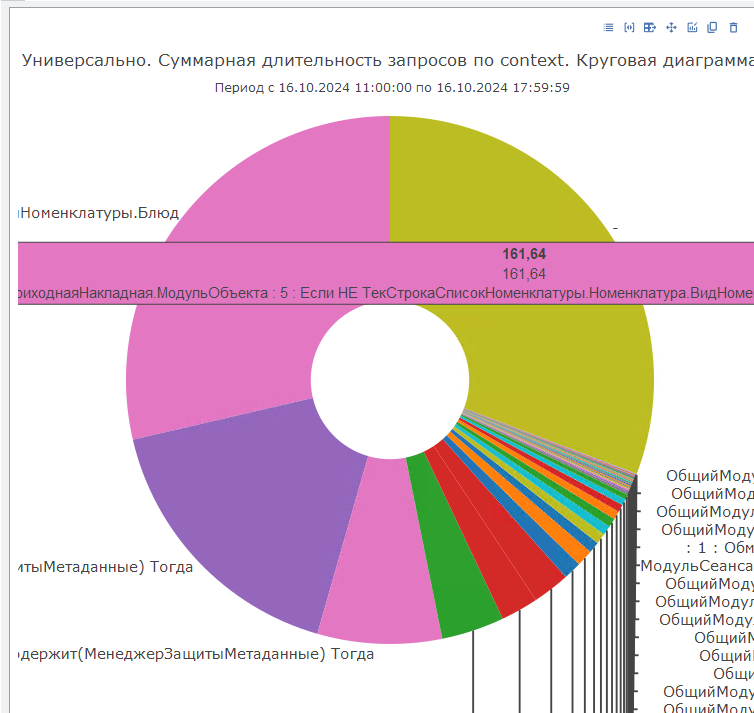
Переходим к подробной детализации и видим, что по одной и той же строке контекста выполнялись запросы от 1.3 до 0.5 секунд:
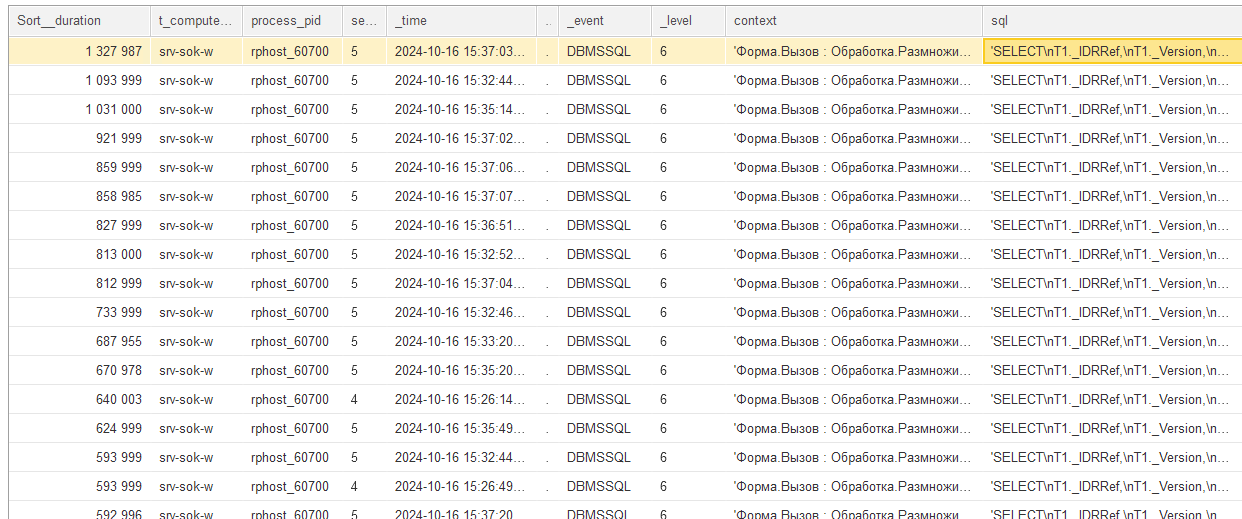
Сам контекст — это как раз проверка вида номенклатуры в цикле:

Если взглянуть на текст запроса в поле sql, то можно увидеть, что запрос выбрал все поля справочника, а не только вид номенклатуры:
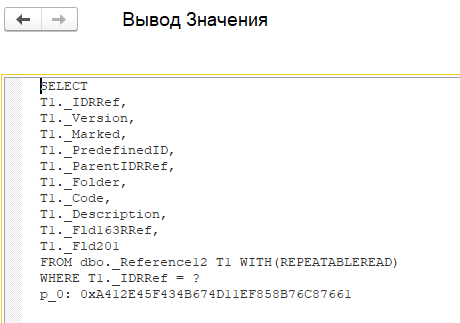
Запрос выглядит несложным, почему же он занимает значительное время? Давайте попробуем выяснить. Для этого воспользуемся функцией расшифровки строки «Сборка пакетного запроса». Подробней о работе данной функции мы расскажем в следующей статье цикла. Сейчас нам необходим один из ее эффектов — это подстановка значений параметров в текст запроса для возможности его выполнения напрямую в СУБД. В результате получим преобразованный текст запроса:

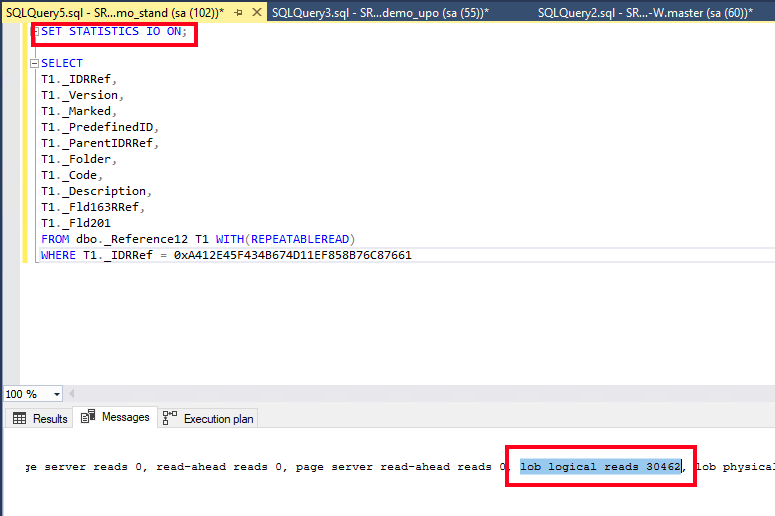
Выполним данный запрос в MSSQL Management Studio, дополнительно добавив опцию SET STATISTICS IO ON. В результате в окне сообщений увидим дополнительную статистику по операциям ввода-вывода, которые были выполнены в процессе исполнения запроса. Обращаем внимание на поле «lob logical reads» и «lob physical reads»:
LOB logical reads — это один из параметров, отображаемых при использовании команды SET STATISTICS IO в SQL Server. Он показывает количество логических операций чтения, связанных с объектами типа LOB (Large Object), такими как:
- TEXT,
- NTEXT,
- IMAGE,
- VARCHAR(MAX),
- NVARCHAR(MAX),
- VARBINARY(MAX),
- XML.
Высокое значение LOB logical reads может свидетельствовать о большом объеме данных, считываемых в запросе, особенно, если используются большие текстовые или двоичные поля. Именно это и происходит в нашем запросе, в котором данный показатель равен 30462 страницам.
Произведем оптимизацию выполняемого запроса. Для этого вынесем получение вида номенклатуры в отдельный запрос за пределами цикла:

Снова запустим обработку генерации документов и найдем связанные с этим строки серверных вызовов, вызовем функцию получения всех событий вызова для нахождения запроса к СУБД из обработки проведения приходной накладной:
Ищем событие DBMSSQL, совпадающее по контексту с исполнением преобразованного текста запроса в обработке проведения документа:
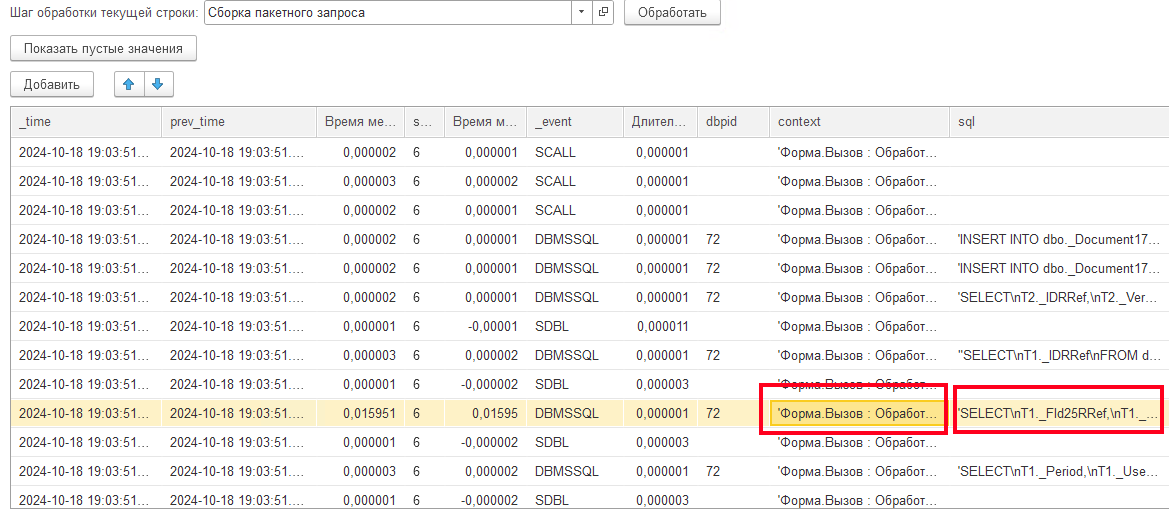
Далее вызовем функцию получения полного текста запроса для его исполнения на стороне СУБД:
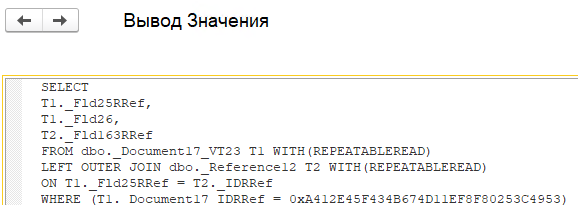
Выполним данный запрос с опцией SET STATISTICS IO и проанализируем результаты. Ожидаемо значение lob logical reads и lob physical reads стало нулевым, так как реквизит с двоичными данными больше не входит в выборку:
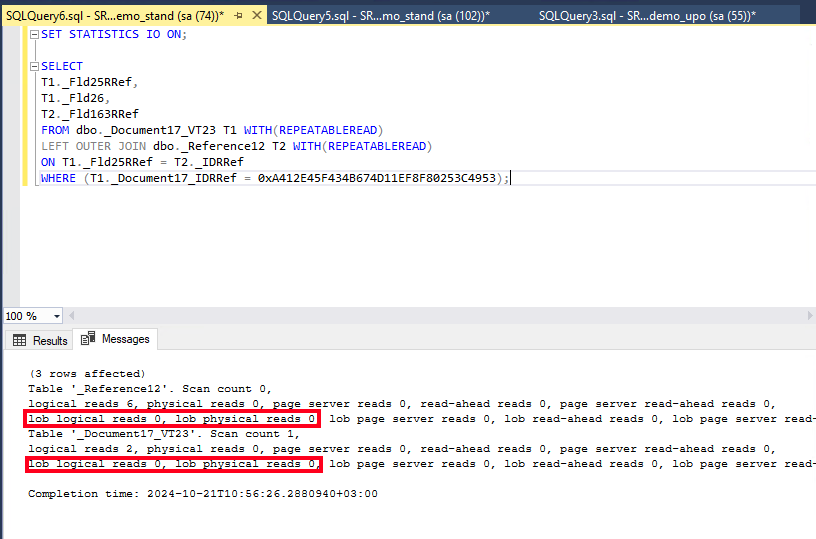
Таким образом можно провести анализ возникающих в системе часто исполняющихся запросов при помощи «1С‑Рарус: Мониторинг производительности».
Случай 2. Отслеживание проблем с оборудованием при росте TempDB
В этом разделе статьи мы поговорим с вами о том, как настроить сбор счетчиков оборудования и оповещений об их критическом изменении для последующего анализа в конфигурации «1С‑Рарус:Мониторинг производительности».
Как бы нам ни хотелось сосредоточиться только на поиске причин блокировок и оптимизации кода и запросов, проблемы с оборудованием всё равно могут возникать. Поэтому за его состоянием тоже нужно внимательно следить. Например, если у вас в один прекрасный момент закончится свободное место на диске, сотрудники точно не будут вам благодарны.
Ранее мы уже описывали ситуацию, когда из-за выполнения запроса свободное место на дисках начинало резко сокращаться (подробнее об этом можно прочитать в статье https://rarus.ru/publications/20230530-ot-ekspertov-tempdb-pgtemp-1c-597587/).
Давайте кратко вспомним, что там происходило:
Механизм закрытия месяца используется во многих типовых решениях, таких как 1С:ERP, «1С:Бухгалтерия», «1С:Управление нашей фирмой» и других. Хотя реализация закрытия месяца в разных решениях может отличаться, общая идея остается схожей: выполнение ряда операций, для которых необходимо обработать данные за месяц и правильно их преобразовать. Именно в этой обработке и кроется проблема: иногда для выполнения операций требуются запросы в цикле, а иногда достаточно простого запроса, но с большим объемом данных. Один из таких запросов и приводил к росту файлов TempDB.
В то время еще не существовало конфигурации «1С‑Рарус: Мониторинг производительности», поэтому для решения этой проблемы нам потребовалось использовать сторонние инструменты. А как бы изменилась ситуация, если бы она уже существовала? И как правильно настроить эту связку?
Настройка сбора данных счетчиков производительности
Конфигурация «1С‑Рарус Мониторинг производительности» предоставляет возможность загружать и обрабатывать счетчики производительности оборудования. Для этого необходимо выполнить ряд шагов с помощью специального агента настройки, который входит в состав дистрибутива конфигурации. Если серверов несколько, например, отдельный под 1С и отдельный под СУБД, то настраивать сбор счетчиков потребуется на каждом сервере.
После выполнения этих шагов будут запущены процессы сбора логов, их подготовки к отправке в очередь RabbitMQ с использованием планировщика заданий, а затем их обработки на сервере конфигурации и отправки в хранилище данных ClickHouse.
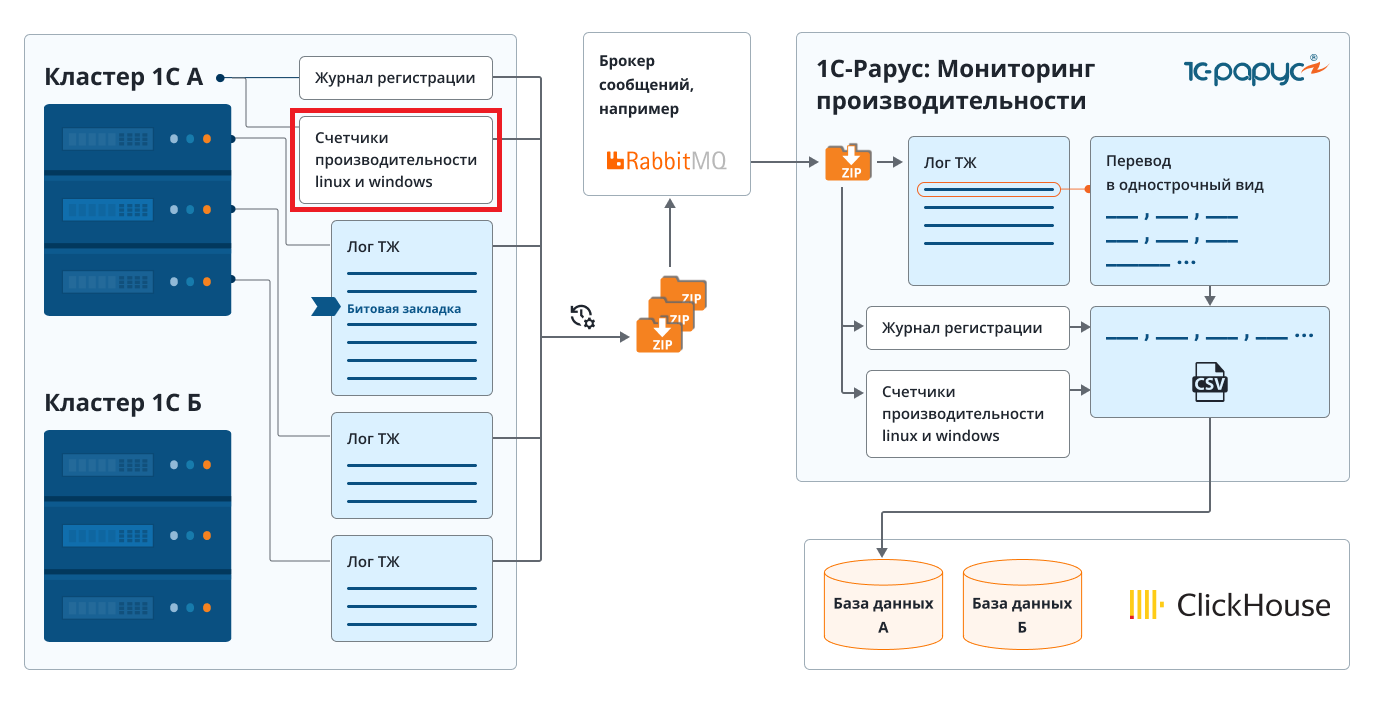
Процесс настройки сбора счетчиков производительности для операционных систем Windows и Linux во многом похож. Основное различие заключается в компоненте, отвечающей за сбор данных: в Windows это «Системный монитор» (Performance Monitor), а в Linux — библиотека Python «psutil». Рассмотрим настройку для Windows.
Для запуска агента настройки «1С‑Рарус:Мониторинг производительности» необходимо из каталога развернутого дистрибутива выполнить запуск agent.exe с правами администратора:
Далее необходимо пройтись по вкладкам агента. Для настройки сбора счетчиков нам понадобятся вкладки «Python», «7-zip», «RabbitMQ» и «Счетчики». Для выявления возможных причин изменений счетчиков нам могут потребоваться логи технологического журнала. В этом случае потребуется обработать вкладки «logcfg» и «Логи ТЖ». Например, если счетчик «% активности диска» резко вырос до 95%, то сам этот факт мало что нам скажет. Но если будет возможность сопоставить их с происходящим в 1С, то можно будет строить гипотезы и расследовать причины таких изменений.
Мы уже рассказали, как установить Python, 7-zip и RabbitMQ, а также начать сбор логов технологического журнала 1С при помощи агента настройки компонентов мониторинга при рассмотрении первого случая, который касался анализа часто исполняемых в системе запросов. Во втором случае настройка не будет отличаться, разве что назначение собранных данных будет дополнено новыми задачами: обработка, упаковка и передача счетчиков производительности.
После установки утилит и их настройки в выше указанных вкладках агента, остается заполнить вкладку «Счетчики» и нажать на кнопку «Создать очередь и задачу для счетчиков».
На этой вкладке можно указать каталоги для хранения собранных логов и расположения подготовленных к отправке файлов, пути к необходимым программам, имя очереди RabbitMQ, в которую будут отправляться подготовленные данные, а также можно задать имя задания в планировщике заданий и установить интервал подготовки файлов к отправке:
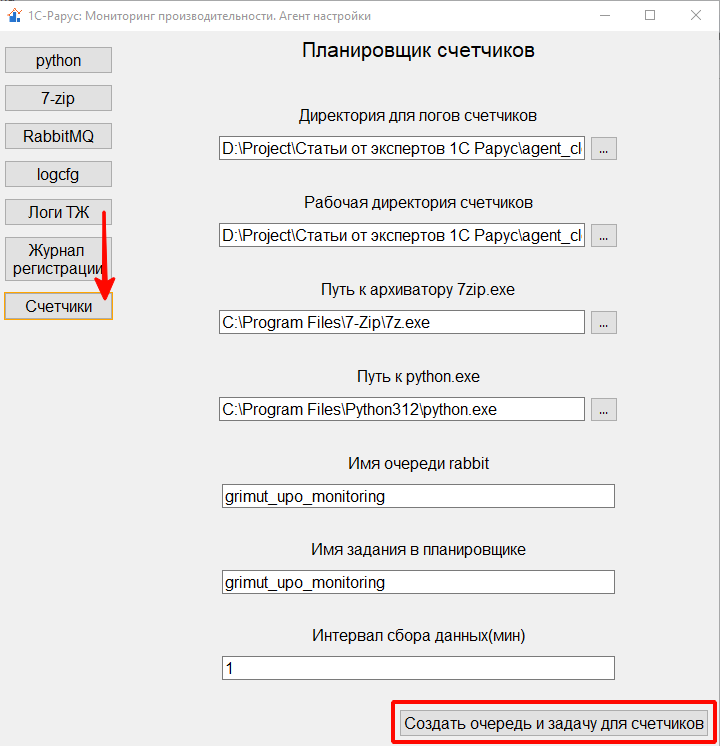
На этом начальная инициализация компонент будет завершена.
Стоит отметить, что набор собираемых счетчиков оборудования под Windows можно расширять любыми доступными счетчиками системного монитора. Настройка выполняется несколькими способами.
Первый способ — явно указать счетчики в файле config_logman.ini. Затем запустить агент настройки и на вкладке «Счетчики» повторно выполнить действие «Создать очередь и задачу для счетчиков ». Этот файл содержит предопределенные группы счетчиков, но его можно модифицировать, отключив ненужные группы счетчиков в поле collectors_properties или включив дополнительные счетчики в поле non_default_collectors_properties, перечислив их через запятую:

Второй способ — воспользоваться графическим интерфейсом системного монитора.
Для этого вызвать окно «Выполнить» (Win+R), указать perfmon и нажать ОК:
Далее перейти в «Группы сборщиков данных», развернуть «Особые», выбрать группу с именем, указанным в поле «Имя задания в планировщике» в агенте настроек, и вызвать свойства счетчиков:
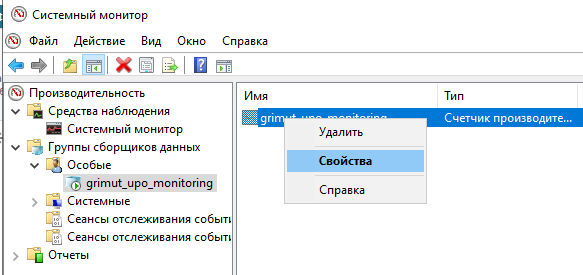
После чего выполнить добавление интересующих счетчиков:
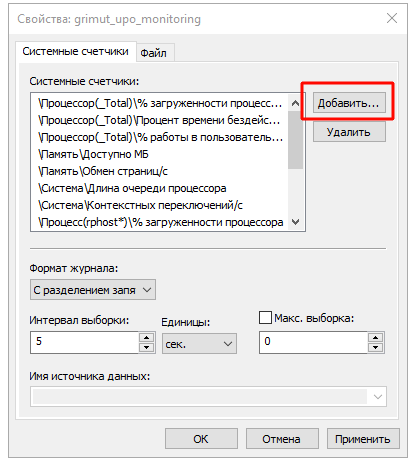
В ходе данного кейса нам потребуется анализировать состояние свободного пространства TempDB, который не входит в список предопределенных счетчиков. Поэтому выполним добавление счетчика «Свободное пространство в tempdb (КБ)» и сохраним подобранные счетчики:
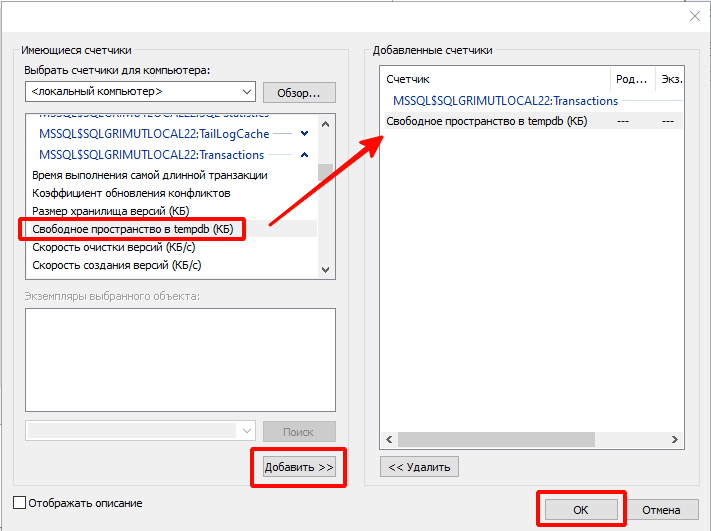
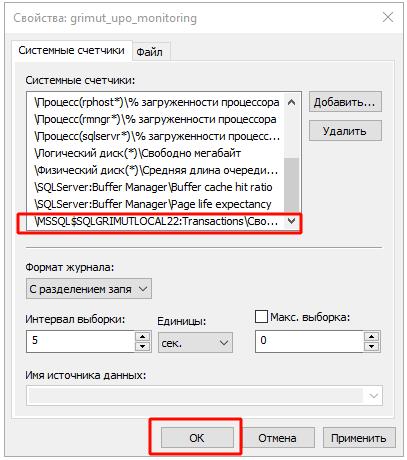
На этом расширение событий может быть завершено. Однако, чтобы данные счетчики не сбросились агентом настройки при повторной настройке, рекомендуется указать новые счетчики явно в файле config_logman.ini. Важно отметить, что фактическое название счетчика может отличаться от синонима, который видно в графическом интерфейсе.
Для получения фактического названия необходимо сохранить группу счетчиков как шаблон:
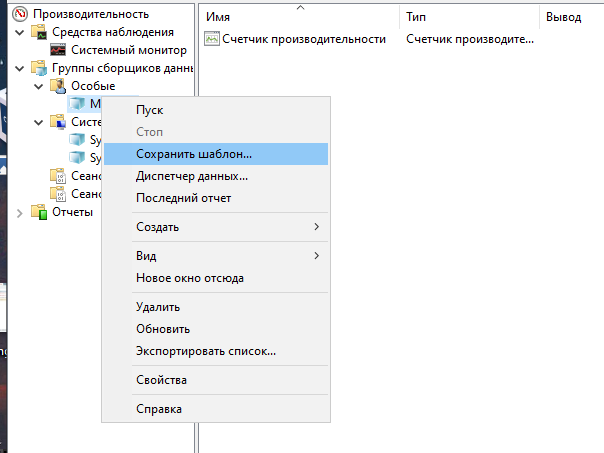
После чего открыть созданный файл и найти в нем необходимый счетчик по синониму. Фактическое название счетчика будет располагаться по аналогичному порядковому номеру синонима.
Например, синоним счетчика \MSSQL$SQLGRIMUTLOCAL22:Transactions\Свободное пространство в tempdb (КБ) располагается пятнадцатым элементом CounterDisplayName, соответственно, фактическое название будет пятнадцатым элементом Counter — \MSSQL$SQLGRIMUTLOCAL22:Transactions\Free Space in tempdb (KB):
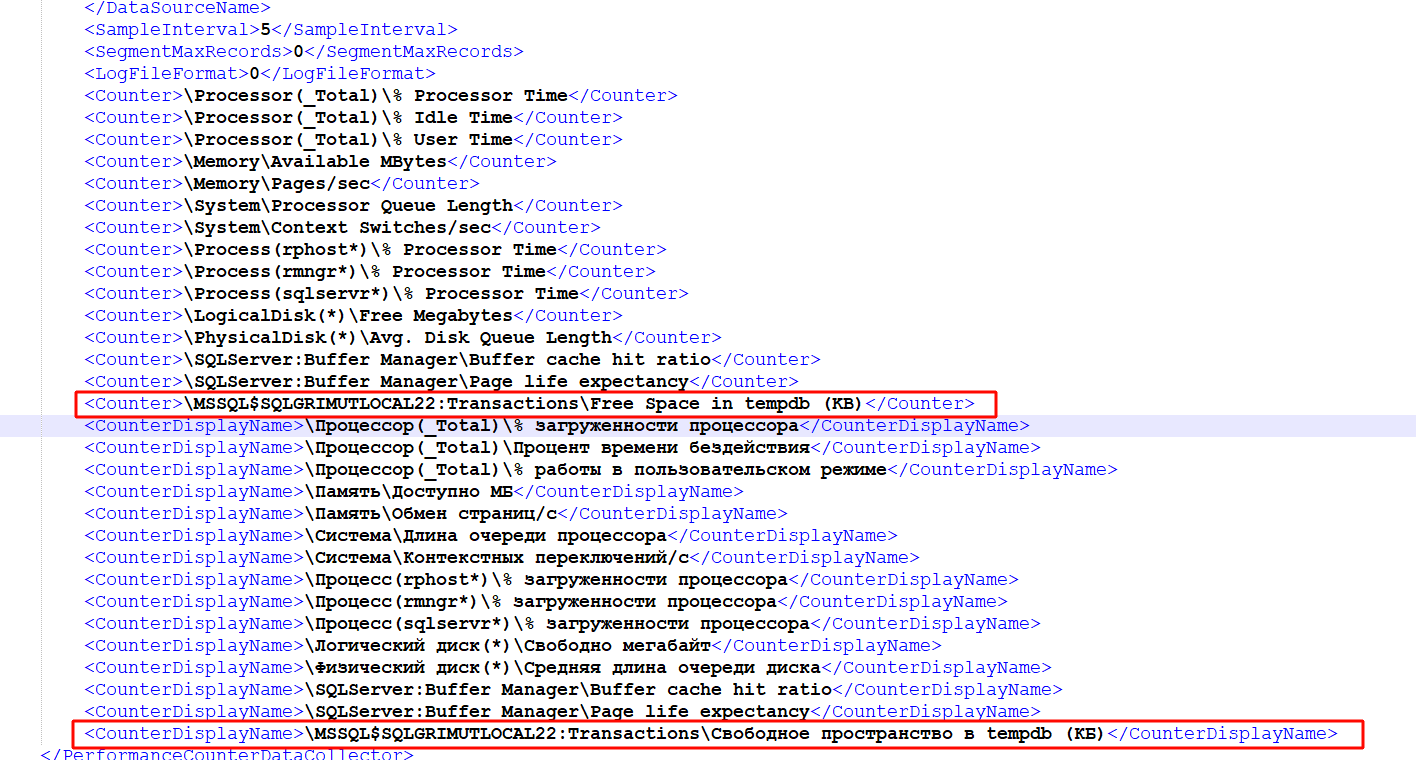
Остается лишь расположить фактическое название в файле config_logman.ini:

Настройка в «1С‑Рарус:Мониторинг производительности»
Для получения счетчиков производительности из RabbitMQ и их дальнейшей обработки необходимо заранее подготовить окружения трех сценариев: «Анализ технологического журнала мониторинг (служебный)», «Анализ технологического журнала мониторинг (сервер)» и «Анализ технологического журнала (Диаграммы мониторинга)». Об их настройке на примере анализа логов технологического журнала 1С уже было сказано при описании первого случая, который касался часто исполняемых в системе запросов, однако, давайте кратко рассмотрим отличия в настройке для анализа счетчиков оборудования.
Перейдем в подсистему «Управление сценариями» и откроем обработку «Исполнение сценариев»:
Далее выберем сценарий «Анализ технологического журнала мониторинг (служебный) и создадим новое окружение. О параметрах окружения мы уже рассказывали выше, отметим лишь, что в созданном окружении необходимо установить параметр «Вид источника» в значение «Счетчики оборудования»:

После чего можно записать и закрыть окружение и выполнить данный сценарий:

Далее необходимо выбрать сценарий «Анализ технологического журнала мониторинг (сервер)». Отличием от настройки окружения для анализа логов технологического журнала 1С будет, опять же, ревизит «Вид источника», как и в служебном сценарии:
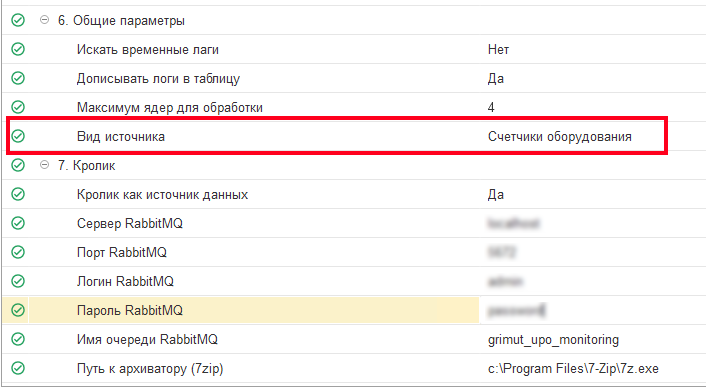
Также не забываем настроить выполнение серверного сценария на выполнение по расписанию. Периодичность выполнения регламентного задания рекомендуем устанавливать в зависимости от загруженности системы сбора и скорости обработки конфигурацией. Так как тут важно достичь баланс между «хочется видеть все показали сразу» и «сервер не успевает обрабатывать сообщения»:
Остается создать и настроить окружение для сценария «Анализ технологического журнала (Диаграммы мониторинга)», которое будет использоваться непосредственно для визуального просмотра диаграмм. Опять же, не забываем установить правильный вид источника данных:
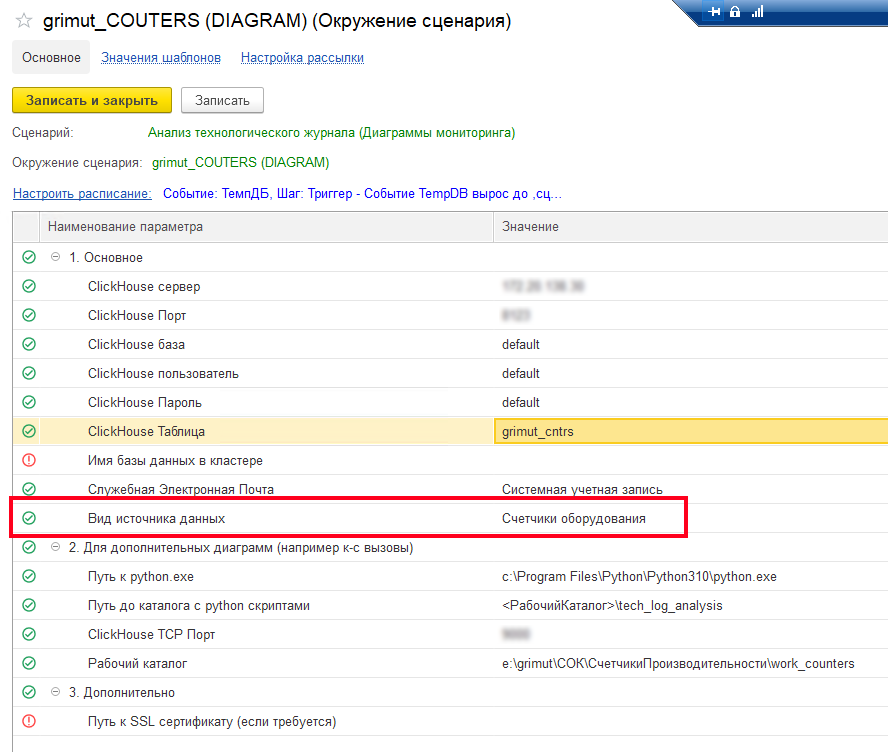
После его записи основная настройка окружений будет завершена.
Настройка оповещений и рассылки
Ранее мы выполнили подготовительные шаги, которые позволяют конфигурации «1С‑Рарус: Мониторинг производительности» обрабатывать счетчики производительности. Давайте перейдем к ответу на вопрос: как настроить рассылку оповещений о проблемах производительности?
В первую очередь нам потребуется подготовить почтовый аккаунт, от которого будет происходить рассылка сообщений. Для этого перейдем в Администрирование — Органайзер:
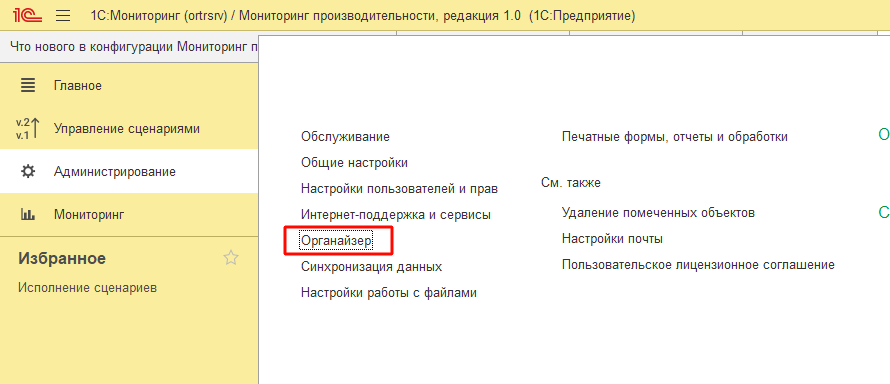
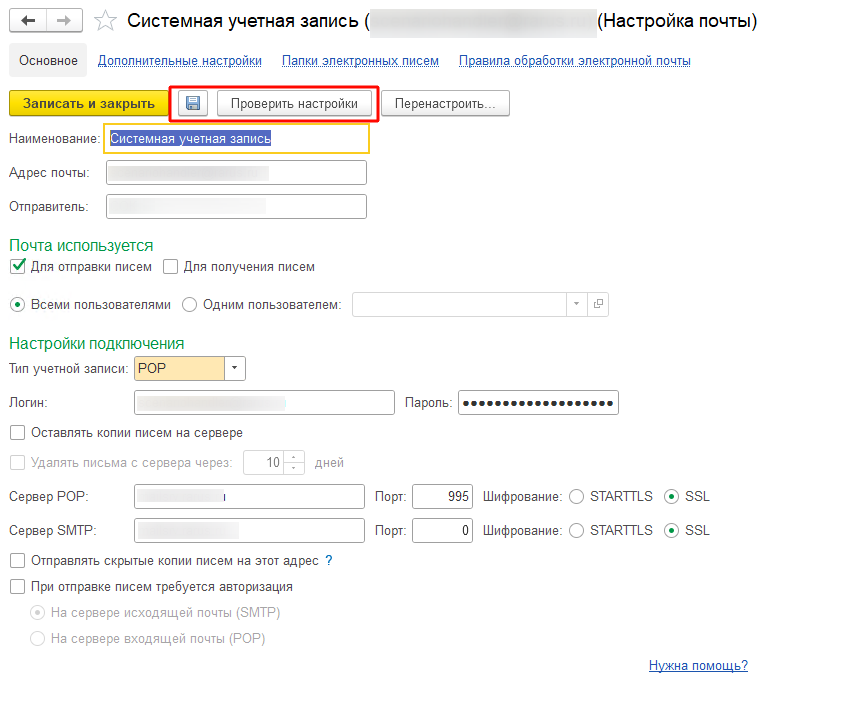
Далее надо переёти в «Настройка системной учетной записи» и установить параметры отправки писем или же перейти в настройки почты и завести дополнительный почтовый аккаунт:
Следующим шагом в настройке оповещений станет выбор оптимального алгоритма для сбора и анализа показателей, а также отправки тревожных писем в случае возникновения проблем. Для этого мы вернемся в обработку исполнения сценариев (Управление сценариями — Исполнение сценариев) и установим сценарий «Анализ технологического журнала (Диаграммы мониторинга)».
В данном расследовании нам потребуется анализ события «Свободное пространство в tempdb». Чтобы настроить оповещение о достижении его критических значений нам потребуется завести свой шаг, который можно создать с нуля или скопировать наиболее приближенный. Для анализа счетчиков оборудования рекомендуем оттолкнуться от шага «Триггер — Счетчик оборудования X вырос до Y»:

Давайте поподробнее остановимся на его содержимом. На входе данного шага определяются ряд параметров:
НазваниеСчетчика (Строка) — представление счетчика, по которому будет осуществляться отбор.
ПоследниеМинут (Число) — период, за который необходимо анализировать изменения показателей на устройствах.
ПоказательПоНормеУвеличивается (Булево) — данный показатель определяет направление роста. Допустим, у нас есть счетчик «% загруженности процессора» и его увеличение говорит о получении нагрузки на систему и, следовательно, чем он выше, тем больше за ним стоит следить. Потому необходимо установить значение параметра в «Ложь». Если же мы рассмотрим счетчик «Доступная память МБ», то его увеличение наоборот говорит о снижении нагрузки. Следовательно, значение параметра необходимо поставить в «Истина».
Что же касается счетчика «Свободное пространство в tempdb», то его снижение говорит о потреблении памяти, например, помещении большого количества строк во временную таблицу, и тут хочется сказать «давай следить за его снижением». Однако, если выделенной памяти не хватает, то система начнет увеличивать размер пространства на указанный объем, а такой резкий рост может привести к проблеме. Потому анализ данного счетчика стоит проводить либо двумя отдельными шагами с разной периодичностью и параметрами, либо анализировать наиболее интересующие состояние: объём памяти уменьшается или растет.
КритичноеЗначение (Число) — значение показателя, от которого система начнет анализ. Например, если «% загруженности процессора» увеличится с 5 до 20%, то, скорее всего, это нормальное поведение, а вот если от 80 до 95%, то уже стоит обратить внимание.
ОбратныйКоэффициентЕдиницыИзмерения (Число) — коэффициент преобразования показателя в значимый. Допустим у нас есть значения счетчика «Свободное пространство в tempdb», которые указываются в килобайтах. Изменения этого показателя на пару килобайт за определенный период могут быть не так важны для нас, а вот изменение на пару гигабайт — весьма существенно. Потому предлагается указывать значение, которое будет преобразовывать исходное и в случае если округление до целой части будет равно 0, то такой рост будет пропускаться.
Сам алгоритм шага можно описать следующей последовательностью:
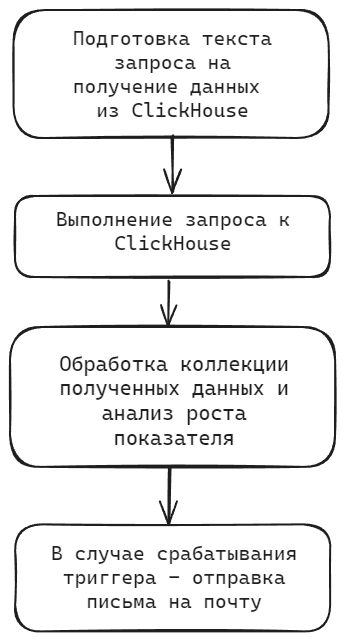
Начинается все с подготовки текста запроса. На текущий момент для выборки логов счетчиков оборудования доступны следующие показатели:
- date — дата события.
- device_name — имя устройства, на котором собирались логи.
- property_name — представление счетчика.
- value — значение замера счетчика.
Соответственно, если нам необходимо получить замеры счетчика оборудования «Свободное пространство в tempdb» за минуту, то будет использоваться подобный текст запроса:
SELECT
date, device_name, value
FROM default.grimut_cntrs
WHERE
date BETWEEN '2024-10-09 19:10:00' AND '2024-10-09 19:11:00'
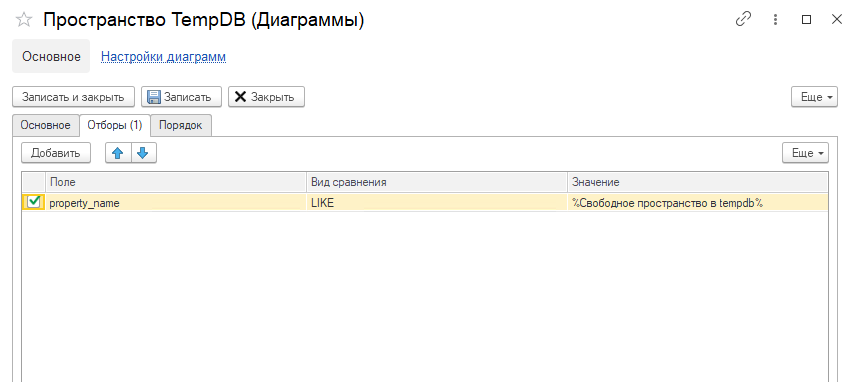
AND property_name LIKE '%Свободное пространство в tempdb%'
ORDER BY date ASC
После выполнения данного запроса начнется обход результата. В ходе которого система начнет сравнивать динамику роста показателя на всех устройствах:
ПредыдущиеСтроки = Новый Соответствие;
РостВТеченииПериодаСохраняется = Ложь;
Для Каждого СтрокаКЗ ИЗ ОтветСтруктура.data Цикл
НоваяСтрока = ТаблицаЗначений.Добавить();
ЗаполнитьЗначенияСвойств(НоваяСтрока, СтрокаКЗ);
НоваяСтрока.Период = Дата(СтрокаКЗ.PeriodInSec);
ДанныеПоУстройству = ПредыдущиеСтроки[СтрокаКЗ.device_name];
Если ДанныеПоУстройству = Неопределено Тогда
ДанныеПоУстройству = Новый Структура;
ДанныеПоУстройству.Вставить("ПредыдущаяСтрока", НоваяСтрока);
ДанныеПоУстройству.Вставить("РостВТеченииПериодаСохраняется");
ПредыдущиеСтроки[СтрокаКЗ.device_name] = ДанныеПоУстройству;
Продолжить;
КонецЕсли;
ПредыдущаяСтрока = ДанныеПоУстройству.ПредыдущаяСтрока;
ПрошлоВремени = НоваяСтрока.Период - ПредыдущаяСтрока.Период;
РостЗначения = НоваяСтрока.value - ПредыдущаяСтрока.value;
Если НЕ ВходныеПараметры.ОбратныйКоэффициентЕдиницыИзмерения = 0 Тогда
РостЗначения = РостЗначения / ВходныеПараметры.ОбратныйКоэффициентЕдиницыИзмерения;
КонецЕсли;
Если Окр(РостЗначения) = 0
ИЛИ ВходныеПараметры.ПоказательПоНормеУвеличивается
И РостЗначения < 0
ИЛИ НЕ ВходныеПараметры.ПоказательПоНормеУвеличивается
И РостЗначения > 0 Тогда
НоваяСтрока.ДинамикаРоста = 0;
Продолжить;
КонецЕсли;
Если РостЗначения < 0 Тогда
РостЗначения = -РостЗначения;
КонецЕсли;
НоваяСтрока.ДинамикаРоста = РостЗначения / ПрошлоВремени;
Если НоваяСтрока.ДинамикаРоста < ПредыдущаяСтрока.ДинамикаРоста
ИЛИ РостЗначения < ВходныеПараметры.КритичноеЗначение Тогда
ДанныеПоУстройству.РостВТеченииПериодаСохраняется = Ложь;
Продолжить;
КонецЕсли;
ДанныеПоУстройству.РостВТеченииПериодаСохраняется = НЕ ДанныеПоУстройству.РостВТеченииПериодаСохраняется = ЛОЖЬ;
КонецЦикла;
РостВТеченииПериодаСохраняется = Ложь;
Для Каждого ТекСтрока Из ПредыдущиеСтроки Цикл
РостВТеченииПериодаСохраняется = РостВТеченииПериодаСохраняется Или ТекСтрока.Значение.РостВТеченииПериодаСохраняется = Истина;
КонецЦикла;Если же в течении указанного периода показатель будет расти и будет превышать критическое значение, то система отправит письмо ответственным сотрудникам с приложенной динамикой роста показателя.
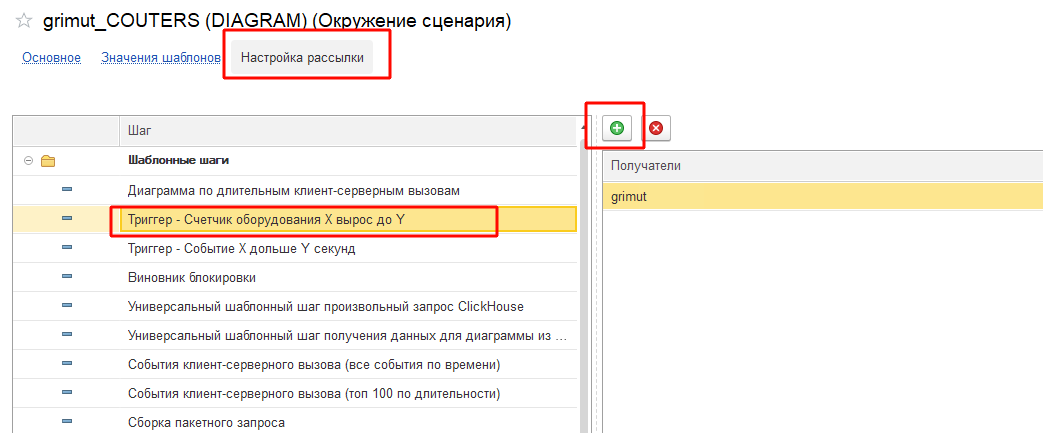
Для определения ответственных сотрудников необходимо перейти в «Настройку рассылки» в карточке окружения сценария. Выбрать соответствующий шаг и добавить пользователей:
После завершения работы с окружением и шагами останется лишь включить сами оповещения, которые можно открыть из подсистемы Мониторинг — События:
Далее завести новый элемент справочника, указать наименование, сценарий и окружение, выбрать созданный шаг и настроить расписание анализа:
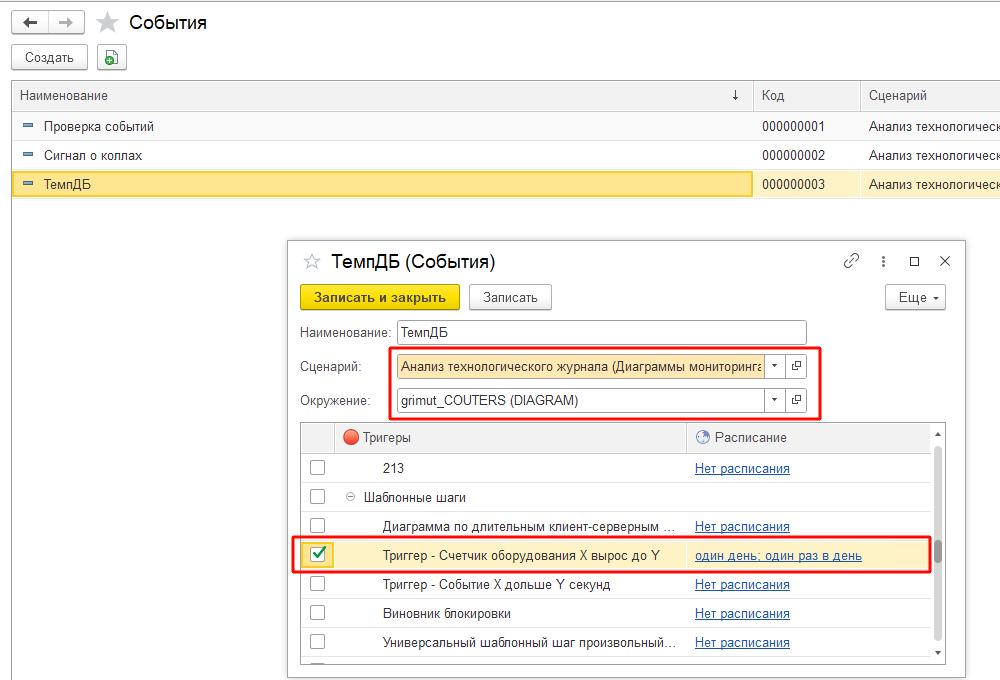
После записи элемента настройка оповещений будет завершена.
Добавление диаграммы по счетчикам оборудования
При расследованиях производительности может быть полезно и графическое представление значений счетчиков оборудования, которые можно увидеть из АРМа Доска диаграмм (подсистема Мониторинг):
По умолчанию конфигурация предоставляет ряд предопределенных досок. В том числе, для анализа счетчиков оборудования «Поставляемая доска счетчики оборудования windows» и «Поставляемая доска счетчики оборудования linux».
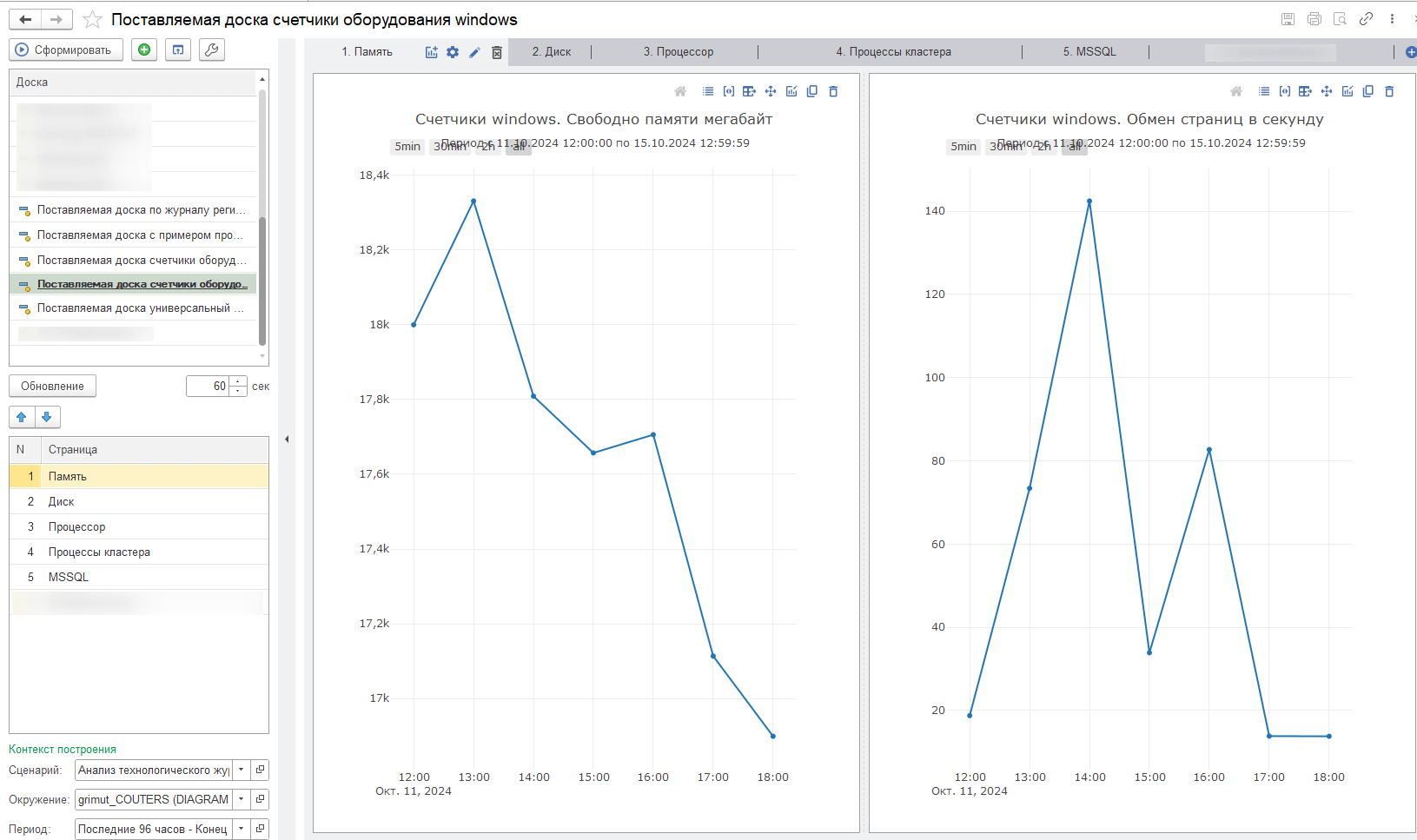
Давайте рассмотрим, как добавить на доску диаграмму со своим счетчиком, например, «Свободное пространство в tempdb».
Для этого заведем дополнительную страницу, нажав на кнопку добавления в списке страниц и укажем название:
Затем нажав на надпись «Настроить диаграмму» система предложит добавить новую диаграмму:
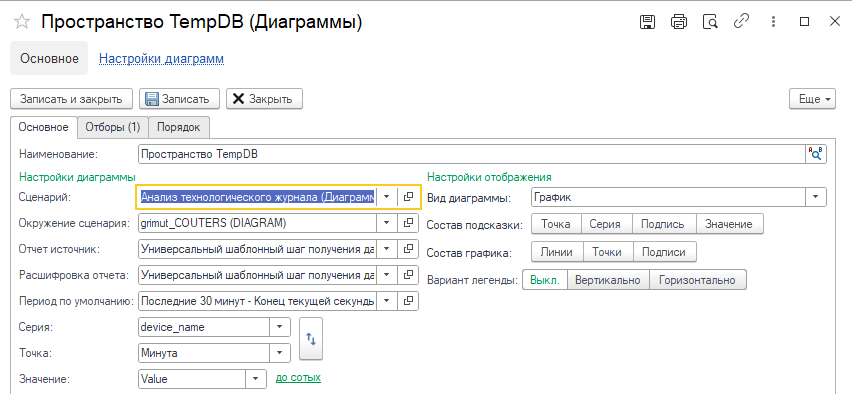
Заполним необходимые параметры:
| Реквизит | Описание | Значение |
|---|---|---|
| Наименование | Наименование диаграммы | Пространство tempdb |
| Сценарий | Сценарий, который выполняться для расчета значений | Анализ технологического журнала (Диаграммы мониторинга) |
| Окружение сценария | Окружение сценария с параметрами исполнения | <Созданное ранее наименование> |
| Отчет источник | Шаг описывающий логику получения значений для отображения | Универсальный шаблонный шаг получения данных для диаграммы из ClickHouse |
| Расшифровка | Шаг описывающий логику получения значений для расшифровки | Универсальный шаблонный шаг получения данных для диаграммы из ClickHouse |
| Период по умолчанию | Период данные за который будут отображаться значения | Последние 10 минут — Конец текущей секунды |
| Серия | Вид линии графика | device_name |
| Точка | Определение оси абсцисс | Минута |
| Значение | Определение оси ординат | Value |
| Вид диаграммы | Вид отображаемой диаграммы | График |
| Состав графика | Отображаемые элементы графика | Линии, Точки |
| Вариант легенды | Расположение легенды | Выкл. |
Далее переключимся на вкладку «Отборы» и установим отбор по названию счетчика:
Выполним запись диаграммы и вернувшись к доске система отобразит полученные данные:
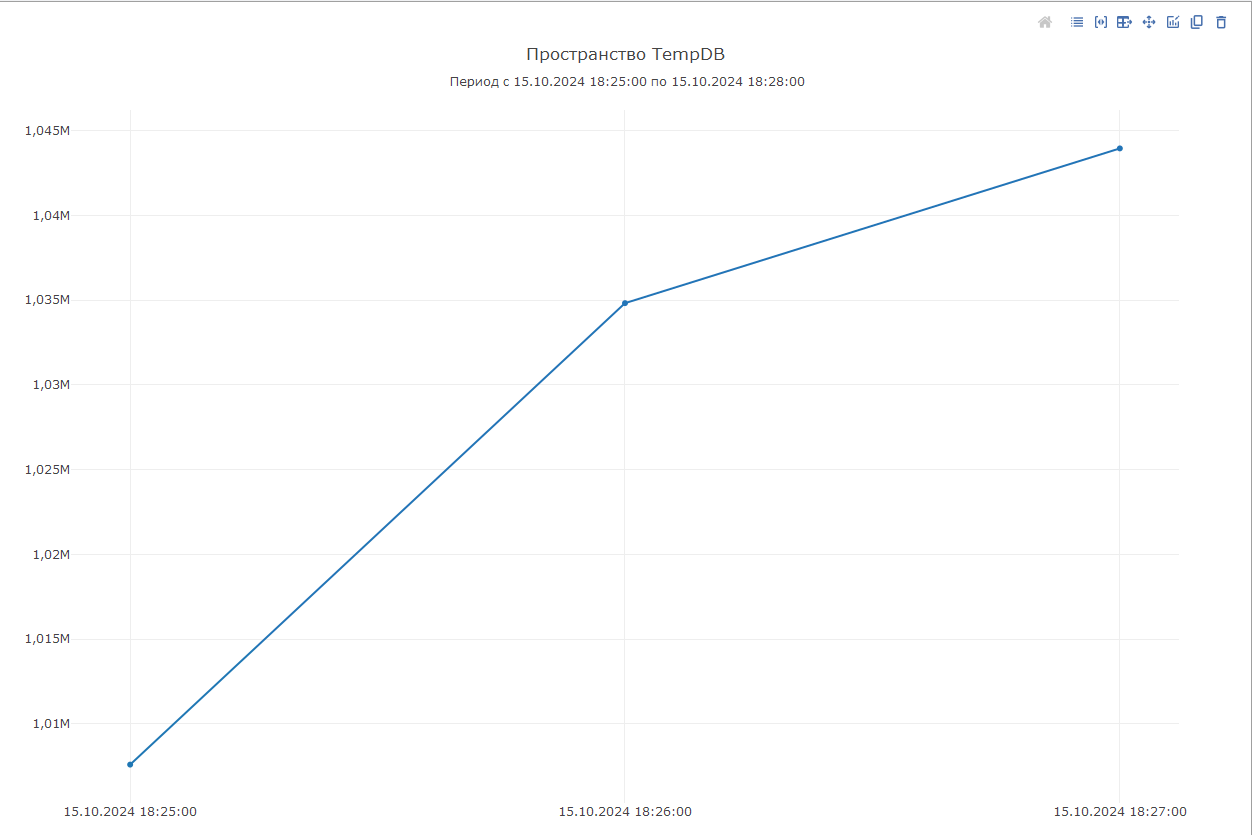
Таким образом, можно настроить диаграмму для любого счетчика, данные по которому собираются в системе.
Расследование
После того как мы подготовили все оповещения и диаграммы, давайте вернёмся к нашему первоначальному расследованию. Как уже упоминалось ранее, в момент закрытия месяца при выполнения очередного запроса у клиента начинали расти файлы TempDB до критичного объема.
Выполним операцию закрытия месяца на этой же базе, но на тестовом стенде с настроенным мониторингом.
Как и в случае клиента, выполнение запроса привело к активному росту файлов TempDB. Конфигурация «1С‑Рарус: Мониторинг производительности» обнаружила данный рост и отправила предупреждающее оповещение на электронную почту.

После обнаружения роста в ранее созданной диаграмме «Пространство TempDB» можно увидеть данную динамику роста:
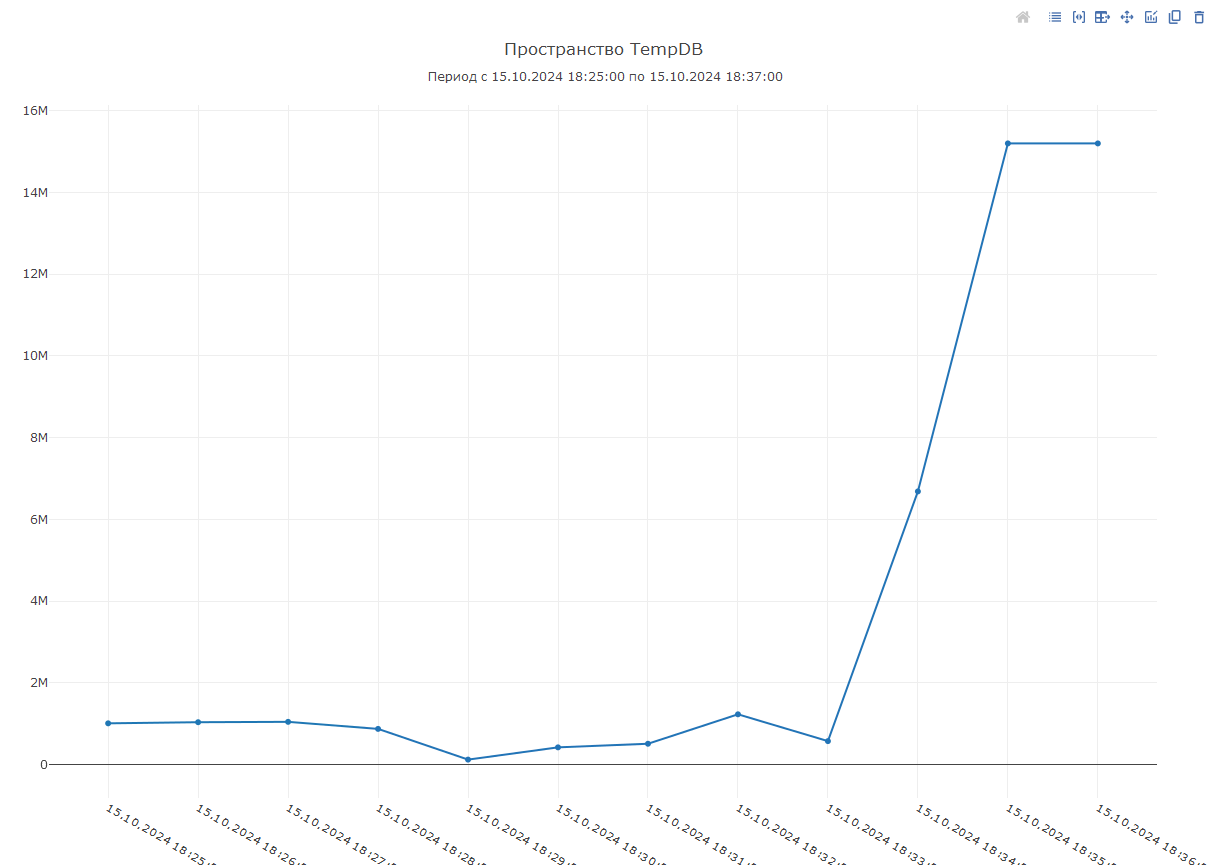
Далее перед нами появляется задача определить, а что за запрос приводит к данному потреблению. Если бы запрос мог выполниться, то данные по нему фиксировались бы в логах технологического журнала. Однако, до тех пока запрос не выполнится или его выполнение не будет прервано, событие не зафиксируется. Т. к. «наш» запрос зависает на стадии выполнения, то прийти к нему можно двумя способами.
Первый более безумный: открыть список всех событий и анализируя от крайнего VRSREQUEST прийти к контексту крайнего события. При этом надеяться, чтобы запрос был рядом.
Второй более практичный и мы им воспользуемся: обнаружить сеанс выполнения запроса и прервать его, что вызовет фиксацию событий в технологическом журнале.
Для его реализации нам потребуется определить номер сеанса, который выполняет тяжелый запрос. Это также можно сделать различными способами, но для упрощения рассказа давайте воспользуемся сервисом Activity Monitor, который предоставляет SQL Server Management Studio.
Запустив Activity Monitor, в списке выполняемых запросов видим запрос, который помещает данные во временную таблицу и при этом потребляющий память:
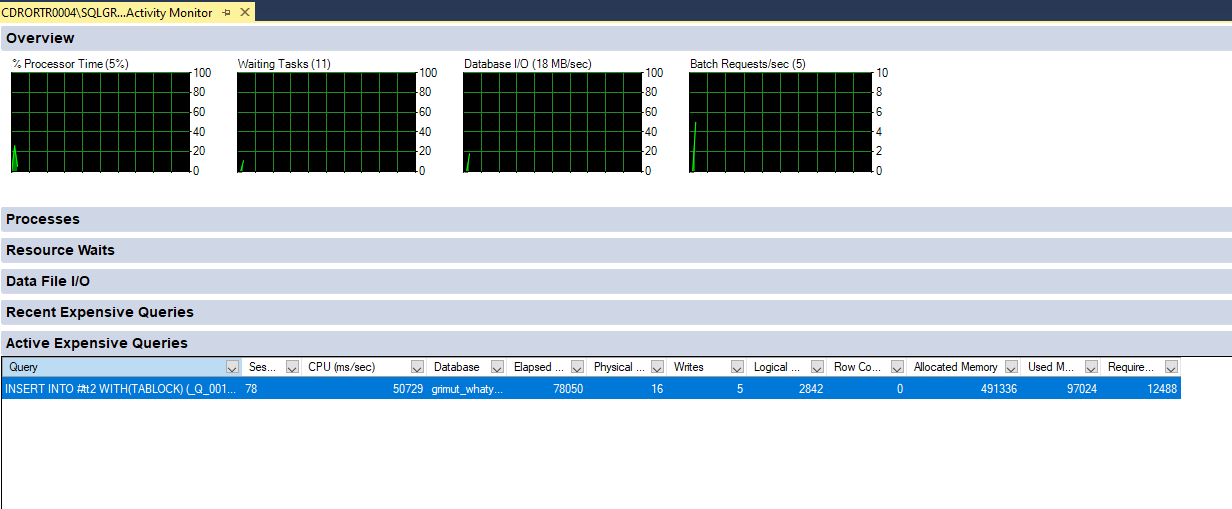
По его номеру сеанса 78 в кластере серверов 1С находим соответствующий сеанс и выполняем его принудительное завершение:

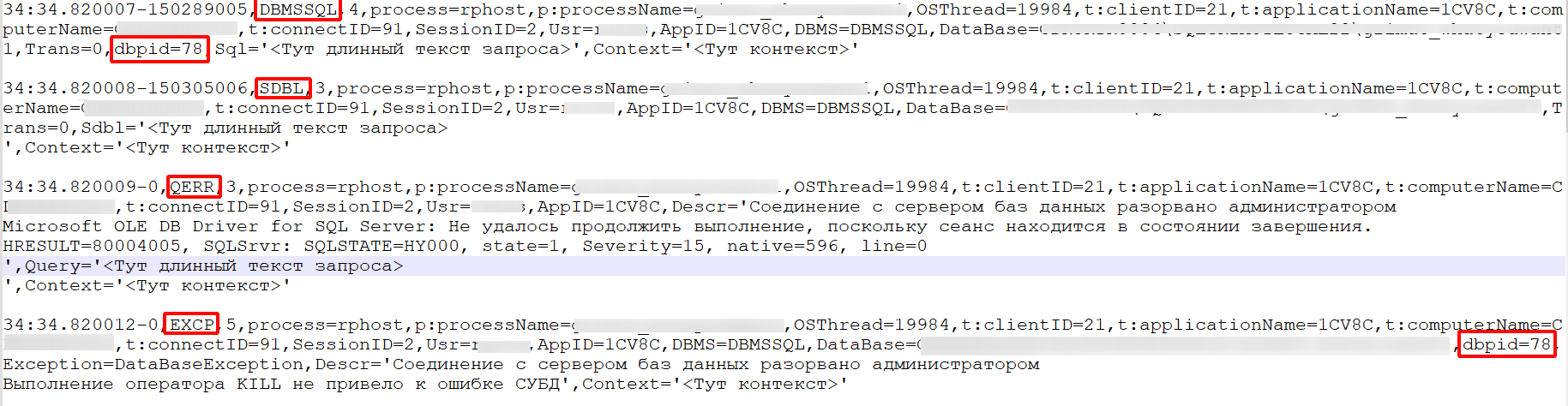
После чего платформа зафиксирует событие QERR, а также связанные с ним SDBL, DBMSSQL и EXCP:
А в сеансе закрытия месяца появится ошибка выполнения с указанным текстом завершения:
Если в конфигурации настроено получение логов технологического журнала, то можно добавить дополнительную диаграмму на доску по событию QERR:
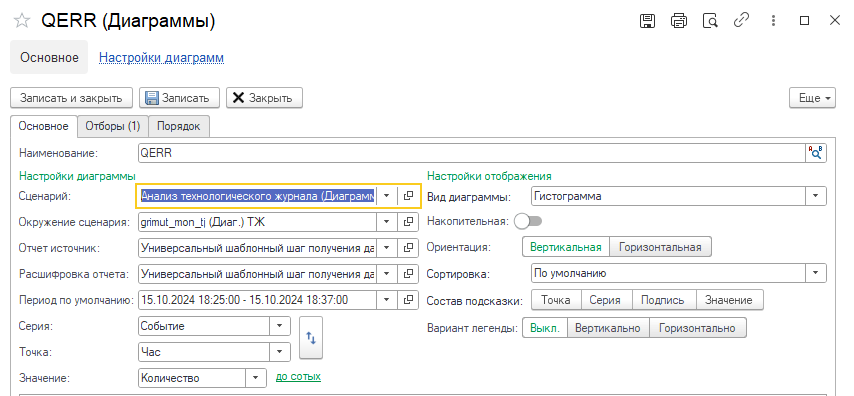
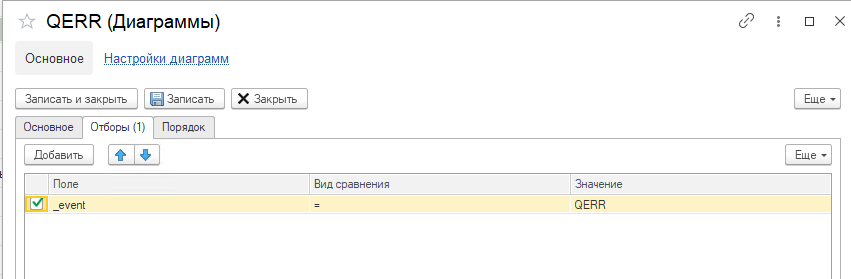
И тогда при открытии ее расшифровки можно получить контекст события и текст запроса, которые привели к росту файлов TempDB:
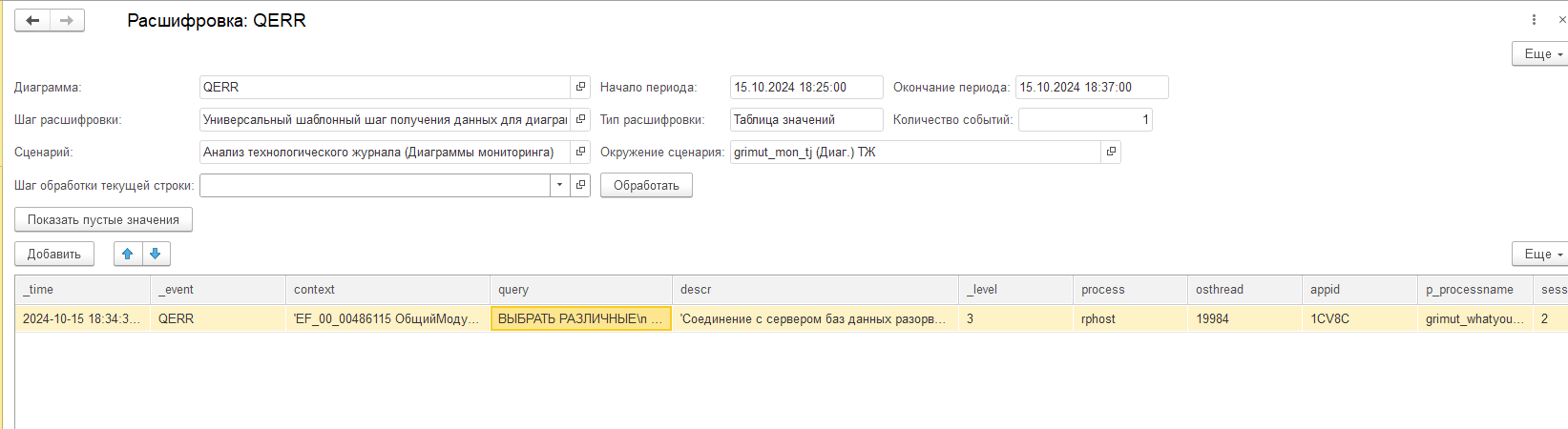
Расшифровка по событию QERR.

Текст запроса, который приводил к росту файлов TempDB.
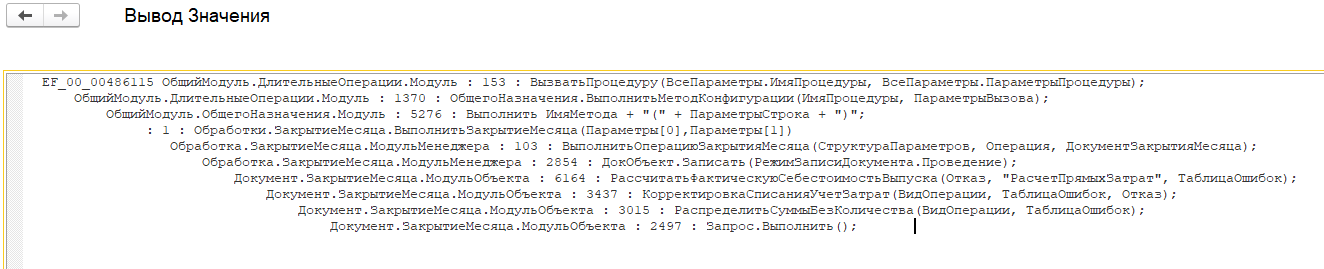
Контекст запроса, который приводил к росту файлов TempDB.
При необходимости можно также найти и преобразованный текст запроса в терминах СУБД. Для этого потребуется создать диаграмму аналогичную QERR, но по событию DBMSSQL и с отборами по полям: имя события (_event), время запроса (_time), идентификатор соединения с информационной базой (t_connectID), идентификатор соединения с клиентом (t_clientID) и идентификатор соединения с СУБД (dbpid):
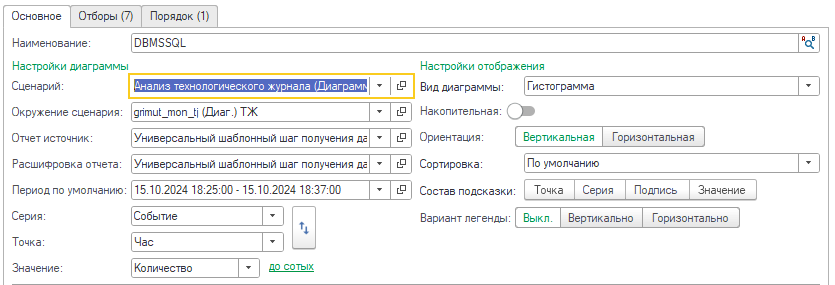
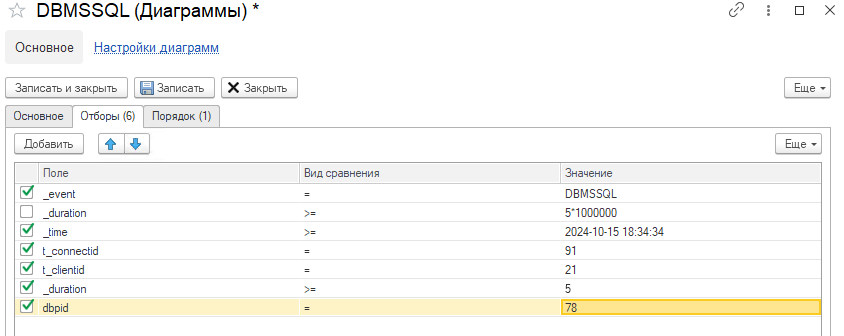
В результате расшифровки система находит событие с необходимым текстом запроса:
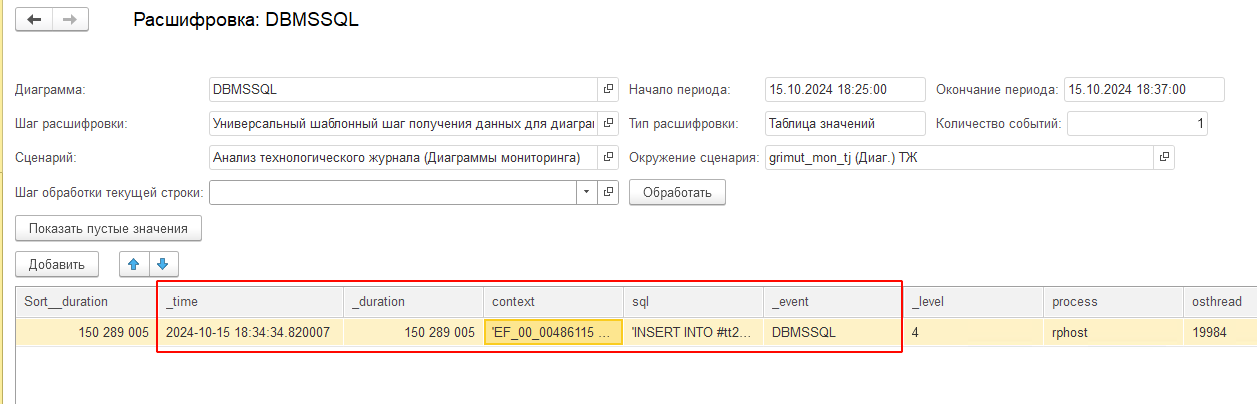
Если же перейти по предложенному контексту, то как и при основном расследовании мы приходим к запросу, в котором присутствуют множественные соединения, как временных и физических, так и виртуальных таблиц. В частности, выполняется ряд соединений с виртуальными таблицами остатков без применения отборов.
Напомним, что виртуальная таблица остатков на уровне СУБД из себя представляет вложенные запросы к таблицам движений и итогов. Потому хоть сами виртуальные таблицы могут возвращать небольшое количество данных, а вот их множественные соединения могут усложнять задачу оптимизатора по поиску оптимального плана запросов. Скорее всего, в данном случае именно это и произошло — формировался неудачный план запроса, который приводил к проблеме потребления памяти:
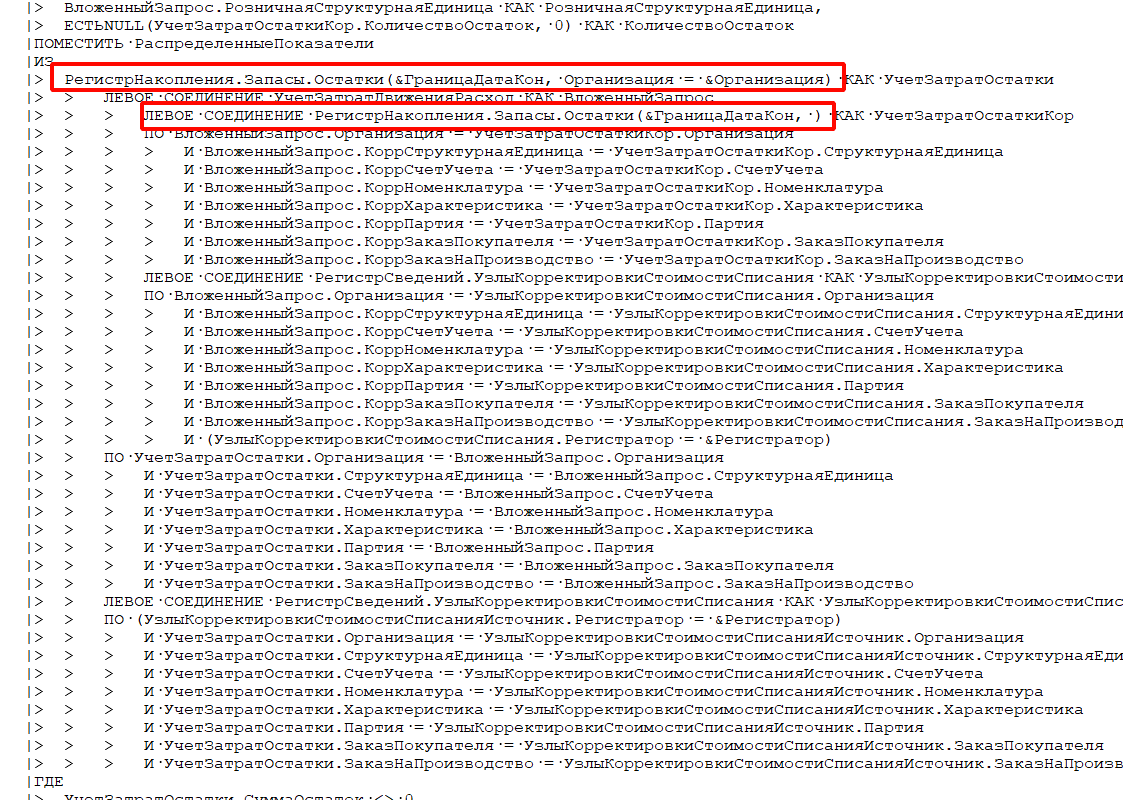
Перенос получения таблиц остатков в соответствующие временные таблицы упростил оптимизатору задачу расчета оптимального плана. Тем самым получилось избавиться от проблемы потребления памяти и повторное выполнение закрытия месяца уже не приводило к такому большому потреблению памяти и росту файлов TempDB:

Случай 3. Поиск информации по последним событиям пользователя
В расследованиях проблем важно использовать все доступные источники информации. Один из таких источников — журнал регистрации. Далее мы покажем, как с ним можно работать через «1С‑Рарус:Мониторинг производительности».
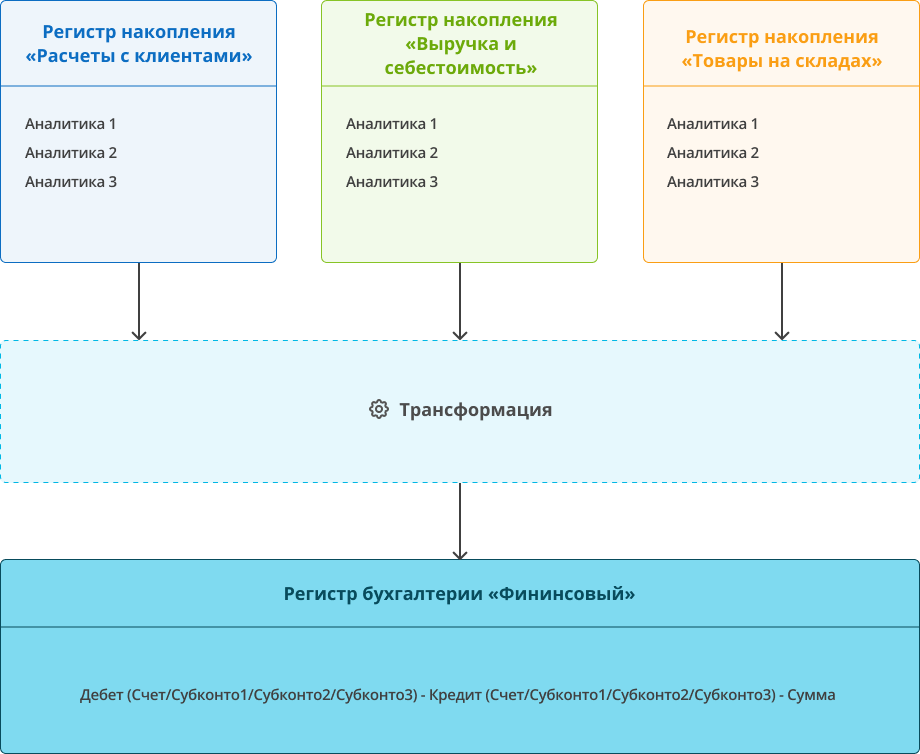
Следующий случай расследования произошел в одной из наших внутренних баз. В ней для получения консолидированных данных организован специальный процесс по преобразованию управленческих движений из разных регистров накопления, в т. н. «финансовые» движения , то есть приведенные к бухгалтерскому формату хранения с разбивкой по счетам/субконто и двойной записью. Процесс назван «трансформацией».
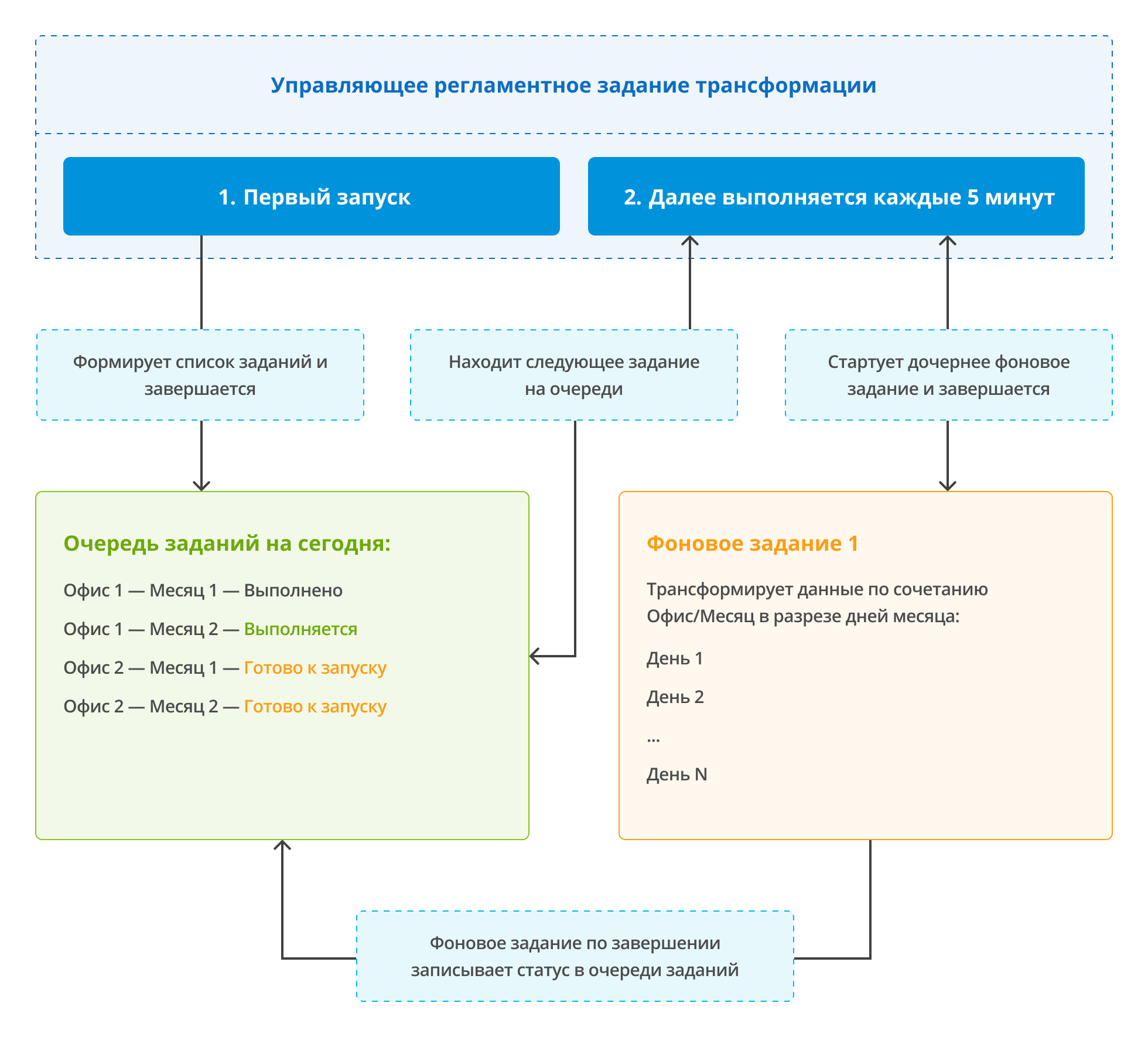
- В определенное время ночью раз в 5 минут запускается «головное» регламентное задание.
- При первом запуске оно генерирует список заданий к трансформации в специальном регистре операций в разрезе офис/месяц.
- Далее запускает первую операцию из списка в отдельном фоновом задании, указывает в регистре заданий статус «Выполняется» и само при этом завершается.
- Дочернее фоновое задание:
- Выполняет последовательно трансформацию всех движений месяца за каждый день отдельным документом.
- По завершении устанавливает для своей строки в регистре заданий статус «Выполнено» или, в случае ошибки, «Выполнено с ошибками».
- Дочернее фоновое задание:
- Повторные запуски головного регламентного задания происходят каждые 5 минут и оно проверяет статусы заданий:
- Если запущенных заданий трансформации нет, то регламент запускает следующее задание по приоритету в отдельном фоновом задании и «засыпает» ещё на 5 минут.
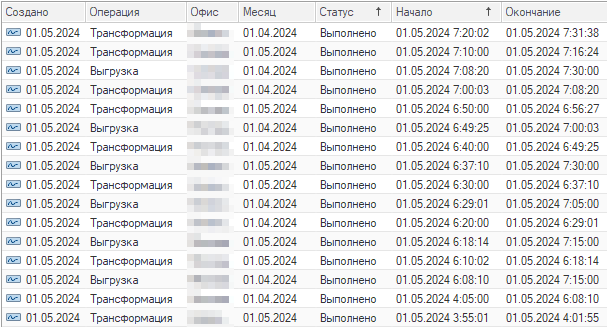
Помимо регламентного запуска, в системе есть возможность ручного запуска трансформации. И в этом случае регистр операций служит для отслеживания повторных запусков.
Проблемы при запуске ручной трансформации
К нам обратился пользователь с проблемой — он запустил ручную трансформацию, и по предполагаемым срокам она уже должна была закончиться, однако, при попытке запустить её ещё раз система выдавала предупреждение:
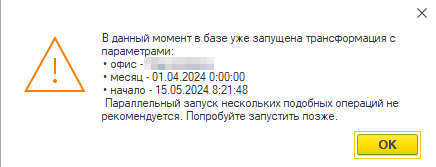
Это сработала проверка для защиты от коллизий при попытке запустить процесс с теми же разрезами.
Мы проверили регистр заданий: там процесс будто бы продолжался — статус «выполняется» и дата окончания пуста:

Следующая мысль: «А существует ли фоновое задание?».
Смотрим в обработку «Регламентные и фоновые задания» и на вкладке «Фоновые задания» его найти не удается ни в выполняемых, ни в завершенных с ошибками:
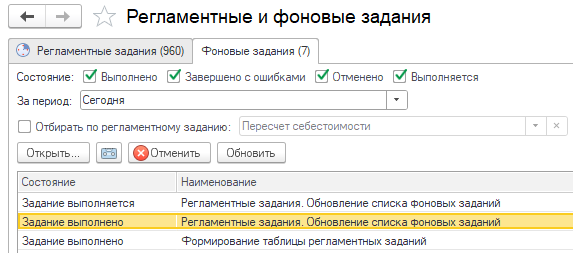
Похоже, что наше фоновое задание было завершено нештатно или «упало» на необработанном исключении, иначе в регистре заданий был бы статус «Выполнено с ошибками».
Чтобы увидеть текст ошибки можно было бы пойти в журнал регистрации и отобрать его по типу «ошибка» или посмотреть логи ТЖ по событиям EXCP.
Но выше мы упоминали, что трансформация рассчитывается за каждый день месяца отдельным специальным документом, и в нашем случае было бы хорошо помимо текста ошибки узнать, на каком конкретно дне рассчитываемого месяца мы остановились в процессе обработки.
И такая информация должна была остаться в журнале регистрации (ЖР). Поэтому наша цель была найти последние события сеанса этого фонового задания.
Поиск источника ошибки стандартными средствами (вручную)
Сначала покажем, как мы проводили расследование с помощью стандартной обработки «Журнал регистрации».
Из входящей информации у нас была по сути только дата начала фонового задания вплоть до секунды — 15.05.2024 8:21:48:

Открываем журнал регистрации и настраиваем фильтр:
- По времени — начало и конец = 15.05.2024 8:21:48.
- Событие = «Фоновое задание. Запуск».
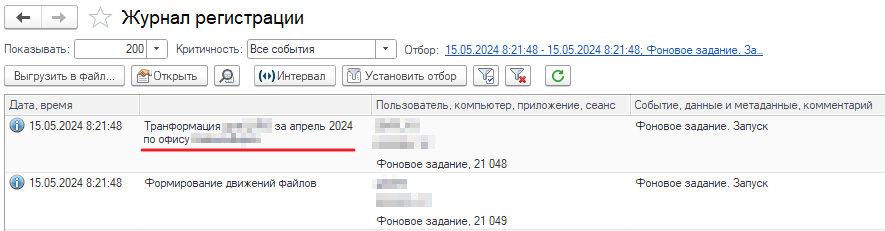
Находим наше событие с данными «Трансформация за апрель 2024...», и берем из него номер сеанса:
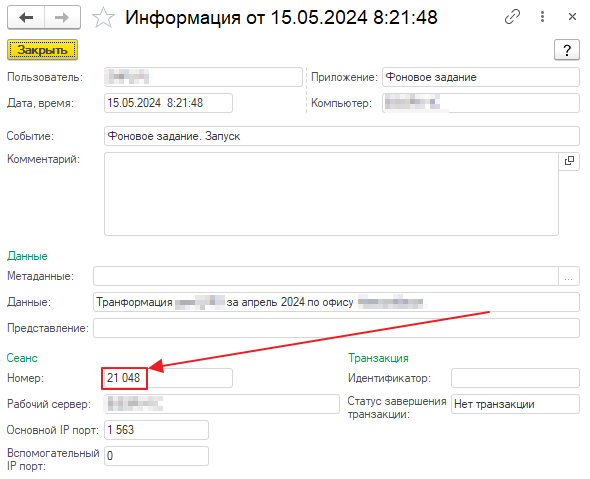
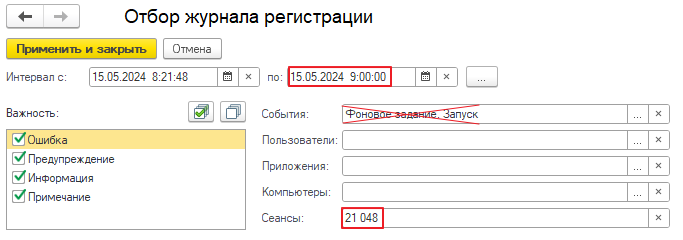
Далее изменяем отбор журнала регистрации:
- Начало периода — оставляем то же самое 15.05.2024 8:21:48.
- Окончание периода — ставим примерное время обращения пользователя, по прикидкам на этот момент фоновое задание уже не выполнялось.
- Номер сеанса = 21048.
- И убираем отбор по событиям.
Как результат получаем список событий нашего фонового задания. Если промотать его в конец, получим искомое — последние события:
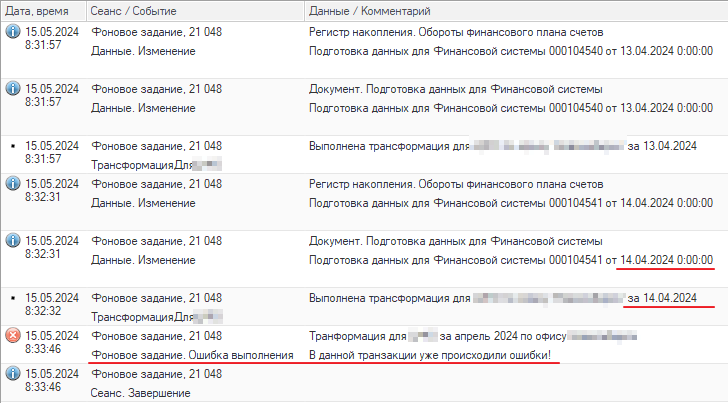
Видим ошибку, на котором упало фоновое задание, а также понимаем какой день был обработан последним — 14 апреля.
Понятно, что на этом путь не заканчивается. Ошибка «В данной транзакции уже происходили ошибки!» требует детального расследования, дальше мы бы вероятно пошли анализировать логи технологического журнала 1С. Однако, целью данной статьи не было показать всё решение в деталях, мы хотели показать способы работы с журналом регистрации при расследовании проблем.
В нашем случае попробуем расширить задачу. Основная идея расследования — получение всех событий журнала регистрации по номеру сеанса в рамках его выполнения от начала до конца и сделать это можно по любой строке журнала. Также при такой постановке нам не важно было это фоновое задание или иное приложение.
Такая задача во многом похожа на задачу получения всех событий клиент-серверного вызова из технологического журнала, о чем мы рассказывали в предыдущих статьях. Только в нашем случае всё чуточку проще, например, искать Gap пока не требуется.
Примечание
Под Gap здесь подразумевается «разрыв» во времени между событиями одного клиент-серверного вызова. Обычно это означает, что в прикладном коде исполнялись операторы, которые не были отражены в технологическом журнале. Техника поиска Gap’ов помогает найти окрестности контекста исполнения таких мест.
Расследование через мониторинг
Покажем, как эту задачу можно было бы решить через систему «1С‑Рарус:Мониторинг производительности». Рассматриваемая база подключена к «Мониторингу» и в него загружаются:
- Логи технологического журнала.
- Логи журнала регистрации.
- Счетчики оборудования.
Для расследования нам понадобятся логи журнала регистрации. Прежде, чем продолжить, расскажем, как подключить их сбор в «Мониторинге производительности».
Настройка сбора логов журнала регистрации
Выше мы уже описывали настройку подключения к «Мониторингу» сбора логов технологического журнала и счетчиков оборудования. Подключение сбора журналов регистрации делается аналогично.
Как и для сбора других логов необходимо будет установить Python, 7-zip и RabbitMQ. Выше мы это уже описывали, повторяться не будем.
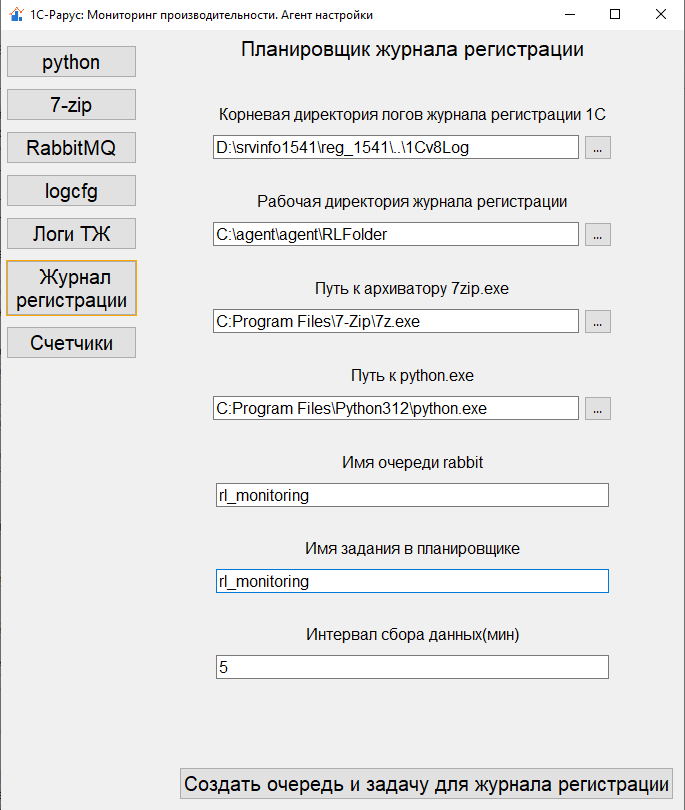
Далее необходимо запустить агент настройки на сервере, где развернута рассматриваемая база, и в этот раз нам потребуется пройти в пункт «Журнал регистрации». Настройка этой вкладки аналогична пунктам «Логи ТЖ» и «Счетчики» с уточнениями:
- В качестве корневой директории указываем путь к логам журнала регистрации в папке кластера.
- В рабочей директории будет происходить архивация логов для отправки через брокер сообщений, она должна отличаться от рабочих директорий других логов.
- Пути к архиватору и python указываем такие же как и ранее.
- Имя очереди rabbit и имя задания в планировщике должно отличаться от заданий сбора ТЖ и счетчиков.
Далее как и в предыдущих случаях в базе Мониторинга нужно подготовить дополнительные окружения для каждого из сценариев:
- «Анализ технологического журнала мониторинг (служебный)».
- «Анализ технологического журнала мониторинг (сервер)».
- «Анализ технологического журнала (Диаграммы мониторинга)».
С указанием параметра «Вид источника» в значение «Журнал регистрации»:

И настроить регулярный запуск окружения для сценария «Анализ технологического журнала мониторинг (сервер)»:
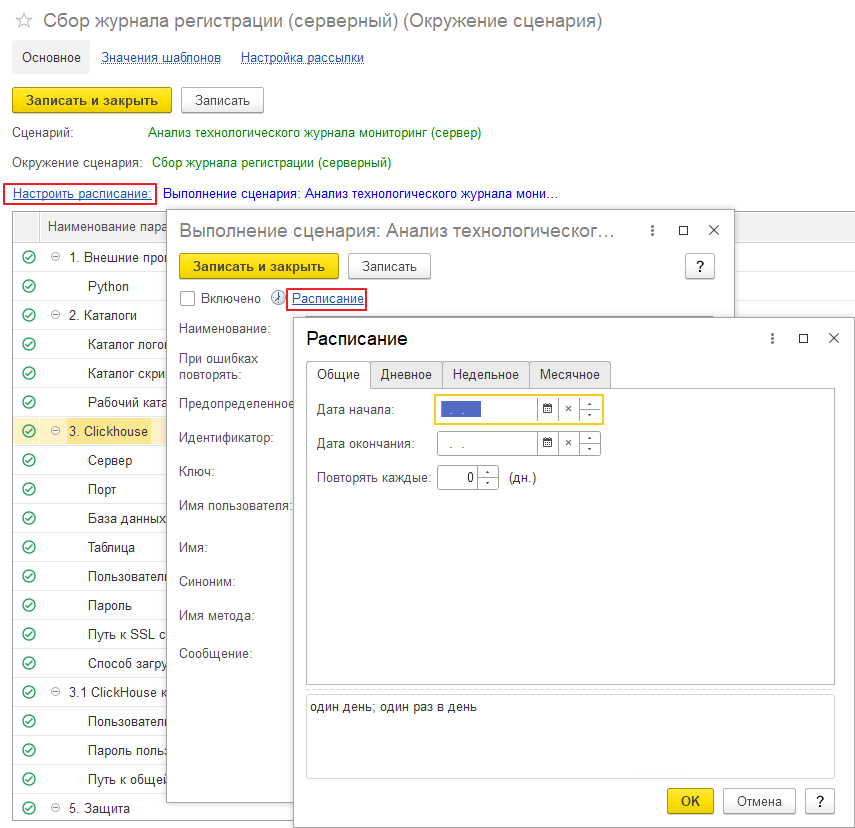
После этого настройка сбора логов завершена.
Поиск ошибки средствами «Мониторинга производительности»
Итак, сбор логов журнала регистрации настроен, можем перейти к расследованию.
Первый этап, как и при использовании обработки «журнал регистрации» — мы должны найти событие начала фонового задания. Напомним, что из исходных данных мы знаем только дату и время старта фонового задания — 15.05.2024 8:21:48:

Поэтому в нашей доске для анализа добавим новую диаграмму «Старты фоновых заданий». Заполняем все необходимые реквизиты, подробно описывать их не будем, подход такой же как в первой главе этой статьи.
Отметим только следующие:
- Серия — указываем «data» («данные»), по этому реквизиту можно будет идентифицировать наше фоновое задание.
- Точка — не принципиально, можно указать любой удобный разрез. Мы укажем «Час».
- Вид — «Гистограмма».
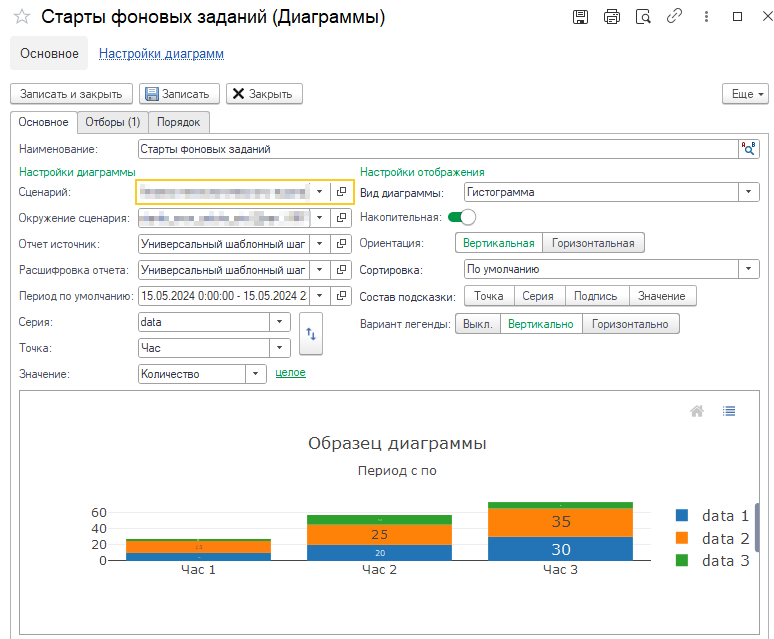
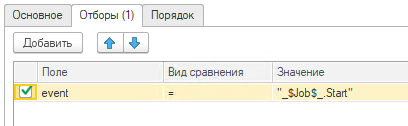
Добавляем отбор по полю «event» = «_$Job$_.Start» (оно же «Фоновое задание. Запуск»):
И формируем диаграмму:
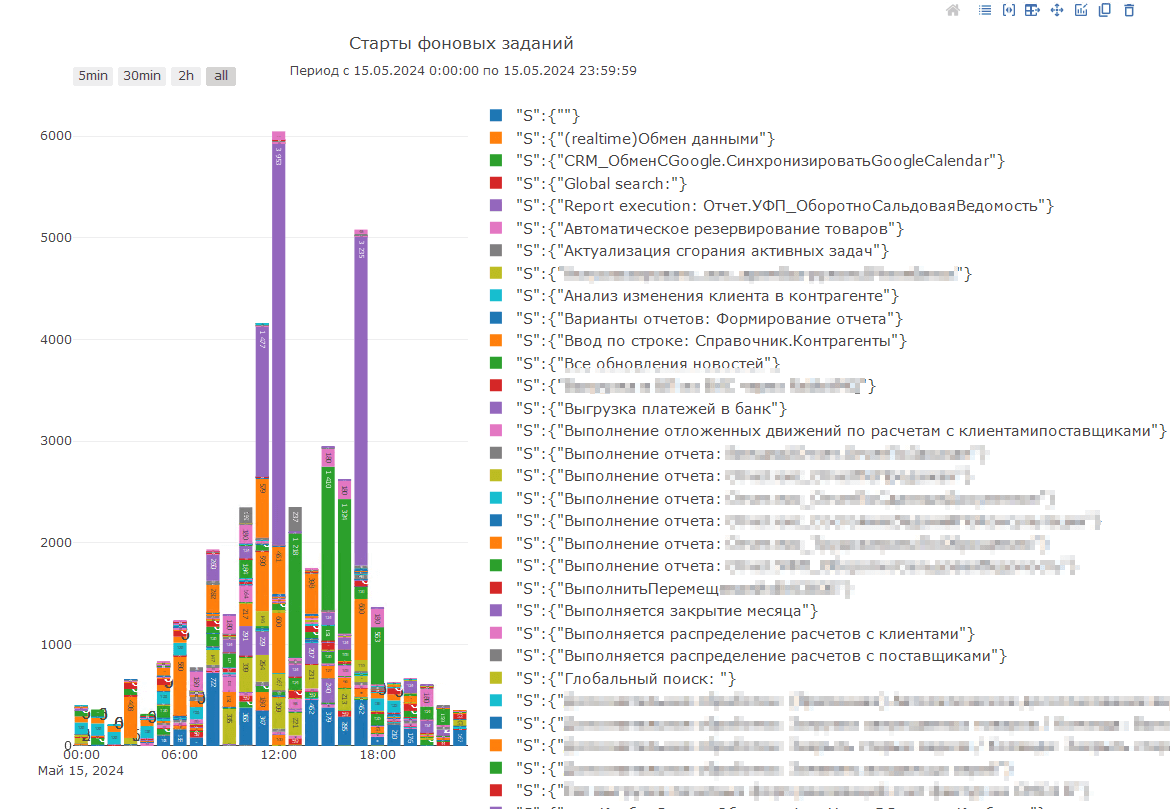
В таком виде можно оценить статистику, но нам нужно сузить поиск, поэтому в левой нижней части формы доски устанавливаем отбор по периоду по дате старта фонового задания = 15.05.2024 8:21:48, и переформируем диаграмму:
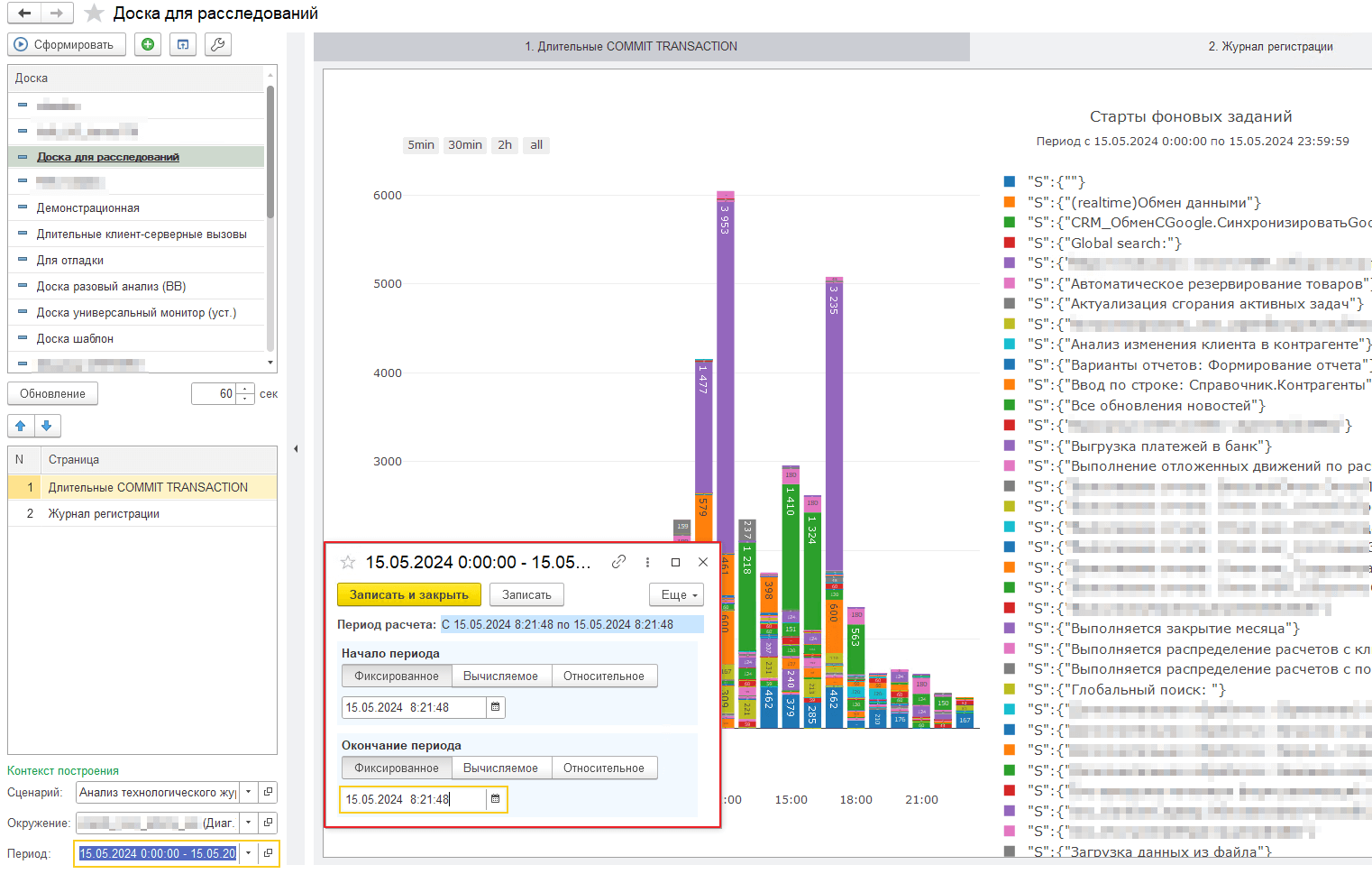
Видим за нужный час несколько событий. С искомым текстом событие одно. Проваливаемся в расшифровку:
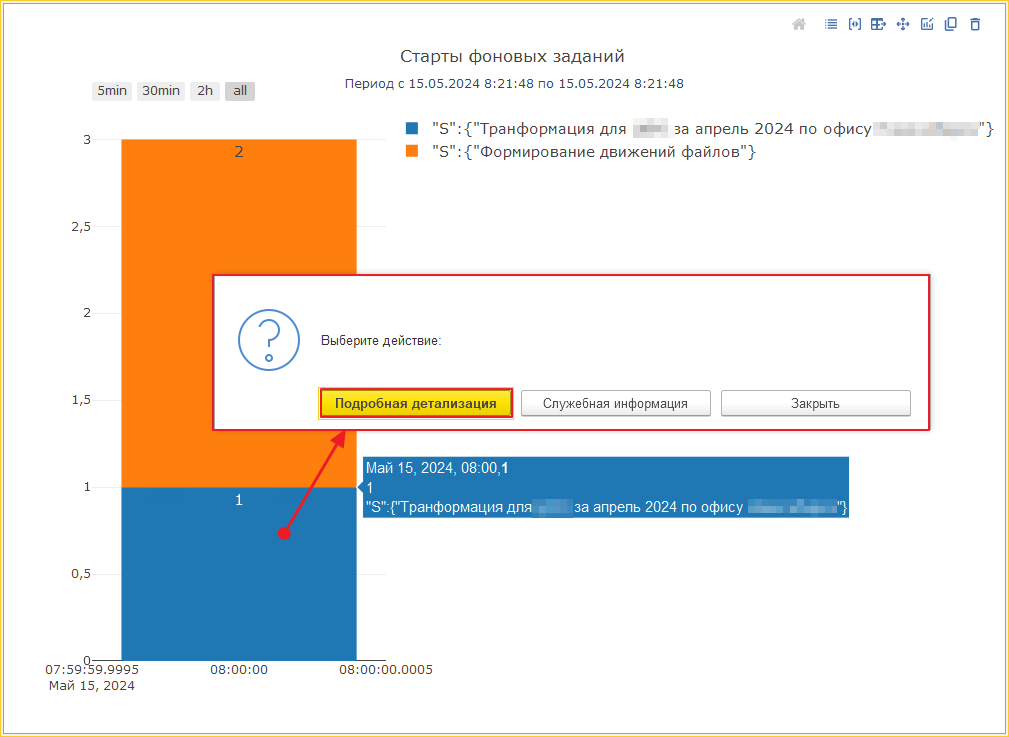
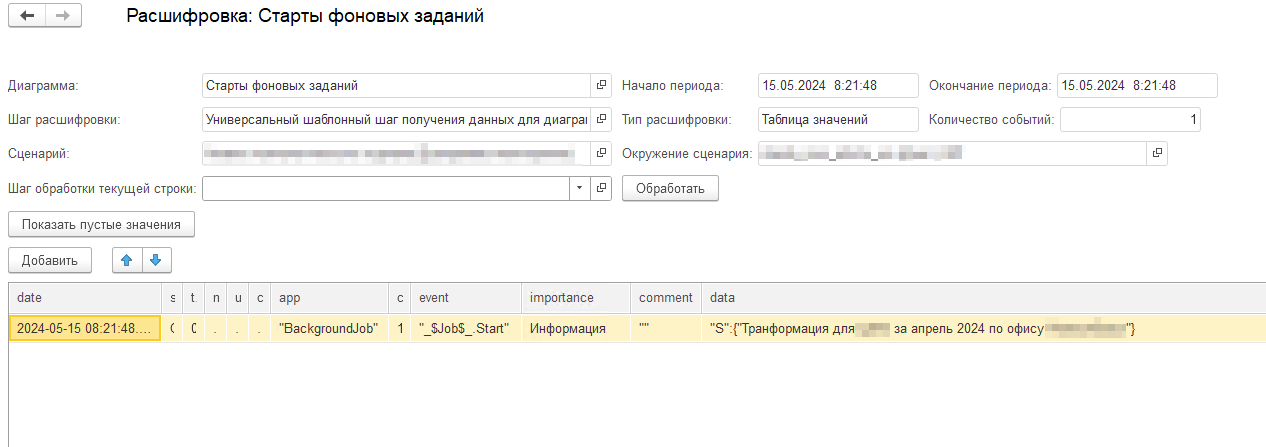
Следующий этап — нам нужно получить все события сеанса. Это уже не простая выборка с отборами, здесь нужен алгоритм, который будет состоять из трёх частей:
- Поиск границы начала сеанса.
- Поиск границы окончания сеанса.
- Выборка всех событий в рамках начала и окончания.
Для этого мы напишем специальный шаг обработки строки расшифровки.
Шаг «Все события сеанса»
На входе в алгоритм шага мы имеем универсальную структуру «ВходныеПараметры». Для шага расшифровки в нём будет поле «ПоляСтроки», содержащее структуру значений полей строки расшифровки.
Т. к. шаг будет выполняться по строке события ЖР, на входе мы будем иметь поля:
- date — дата события;
- session — номер сеанса;
- user — идентификатор пользователя;
- computer — имя компьютера;
- app — имя приложения;
- connect — номер соединения;
- event — имя события;
- importance — уровень события;
- comment — комментарий;
- data — сериализованные данные;
- metadata — сериализованные метаданные;
- data_presentation — представление данных;
- server — имя рабочего сервера;
- main_port — основной IP порт;
- help_port — вспомогательный IP порт;
- status_transact — статус транзакции;
- name_transact — представление транзакции (ID).
Нам для алгоритма понадобятся только поля date и session. Инициализируем их в отдельных переменных. Также дополнительно приведем date к типу дата, так как на данный момент в расшифровке исходное значение даты из ClickHouse мы получаем в текстовом формате:
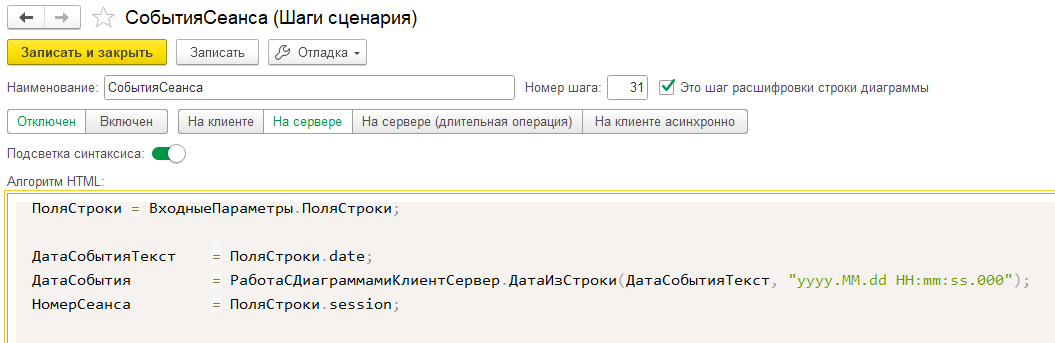
Первый блок алгоритма будет отвечать за поиск даты начала сеанса.
Для этого мы выполним следующий запрос к таблице логов ЖР.
Указываем условия по:
- Списку событий начала сеансов:
- «_$Job$_.Start» ( «Фоновое задание. Запуск»).
- «_$Session$_.Start» («Сеанс. Начало»).
- Периоду даты события:
- «Начало периода» — условно «граница» поиска, мы же не знаем, когда начался сеанс, он мог длиться и час, и день, каких-то четких рамок нет. Но чтобы ClickHouse не перебирал абсолютно все записи, разумно добавить какое-то ограничение, например, минус 10 дней. Для нашего примера пока что возьмем начало дня от даты события.
- «Окончание периода» — это дата выбранного события из строки расшифровки.
- Номеру сеанса.
И выбираем «ПЕРВЫЕ 1» строк при сортировке по дате в обратном порядке. Таким образом мы выберем первое попавшееся событие начала сеанса при просмотре времени назад:
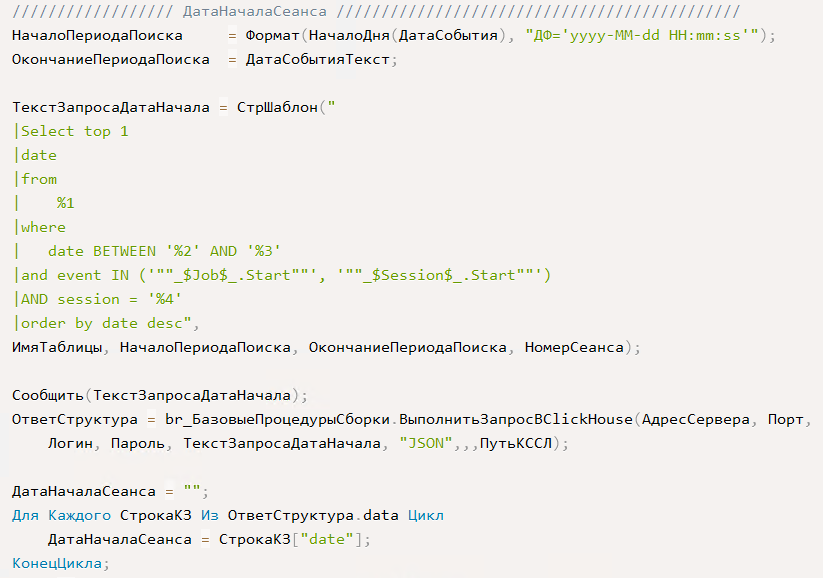
Получится запрос вида:
Select top 1
date
from
default.record_log
where
date BETWEEN '2024-05-15 00:00:00' AND '2024-05-15 08:21:48.000000'
and event IN ('"_$Job$_.Start"', '"_$Session$_.Start"')
AND session = '21048'
order by date desc
Где record_log — имя таблицы ClickHouse, в которую мы загружаем журнал регистрации.
В результате получаем фактическую дату начала сеанса = «2024-05-15 08:21:48.000000». В нашем случае, естественно, она совпадает с исходной датой события, т. к. это одно и то же событие. В других случаях это может быть не так. Здесь мы закладываем некую универсальность ,чтобы шаг мог вызываться для любого события ЖР.
Следующий блок должен определить дату конца сеанса.
Делаем похожий запрос, но с другими условиями:
- Теперь ищем события завершения сеанса:
- _$Job$_.Cancel («Фоновое задание. Отмена»).
- _$Job$_.Terminate («Фоновое задание. Принудительное завершение»).
- _$Job$_.Finish («Фоновое задание. Успешное завершение»).
- _$Job$_.Error («Фоновое задание. Ошибка выполнения»).
- _$Session$_.Finish («Сеанс. Завершение»).
- Период задаем так:
- Начало периода — это дата выбранного события из строки расшифровки.
- Окончание периода — как и в первом блоке это «граница» поиска вперед по времени, некий разумный период от даты начала. Для нашего примера возьмем конец дня.
- Номер сеанса тот же.
И выбираем первое попавшееся событие при сортировке по дате по возрастанию:

Получится запрос вида:
Select top 1
date
from
default.record_log
where
date BETWEEN '2024-05-15 08:21:48.000000' AND '2024-05-15 23:59:59'
and event IN ('""_$Job$_.Cancel""','""_$Job$_.Terminate""', '""_$Job$_.Finish""', '""_$Job$_.Error""', '""_$Session$_.Finish""')
AND session = '21048'
order by dateВ результате получаем фактическую дату конца сеанса = «2024-05-15 08:33:46.000000»
Наконец, когда у нас есть границы сеанса, мы можем выбрать все события простым запросом с отбором по периоду и номеру сеанса:
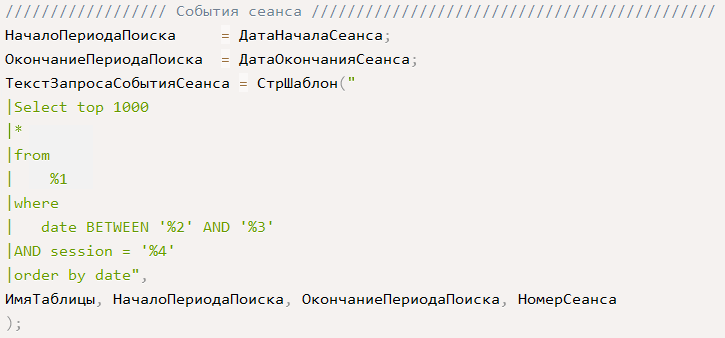
В нашем случае получится запрос вида:
Select top 1000
*
from
default.record_log
where
date BETWEEN '2024-05-15 08:21:48.000000' AND '“2024-05-15 08:33:46.000000”'
AND session = '21048'
order by dateПолученный результат запроса в виде json переносим в таблицу значений и записываем в поле «Результат» служебной структуры «ВыходныеПараметры»:

Шаг готов и мы можем продолжить расследование.
Получение всех событий сеанса и данных по ним в «Мониторинге производительности»
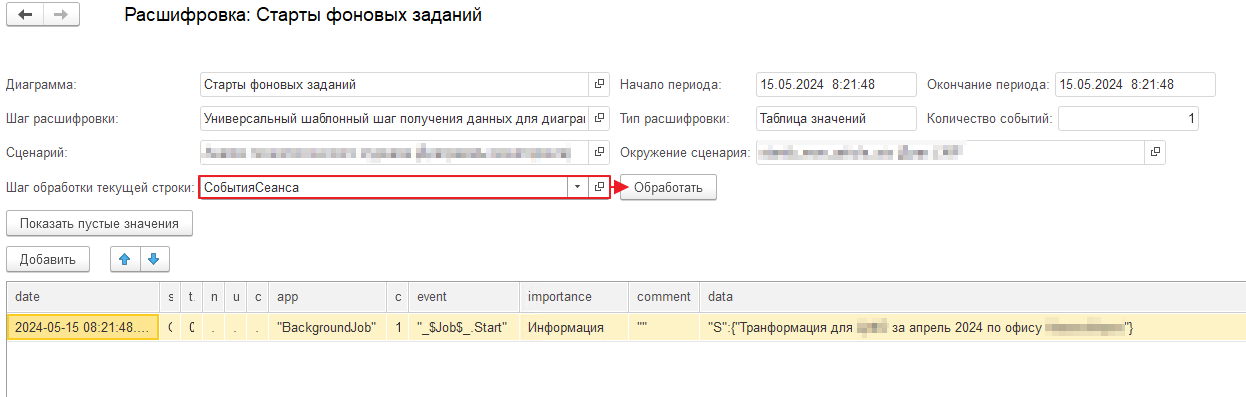
Все в той же форме расшифровки выбираем шаг обработки текущей строки — наш созданный шаг «СобытияСеанса» и нажимаем кнопку «Обработать». Получаем таблицу со всеми событиями сеанса.
В полученной таблице можно найти последнее событие с текстом ошибки, а также понять, какой день движений был обработан последним:
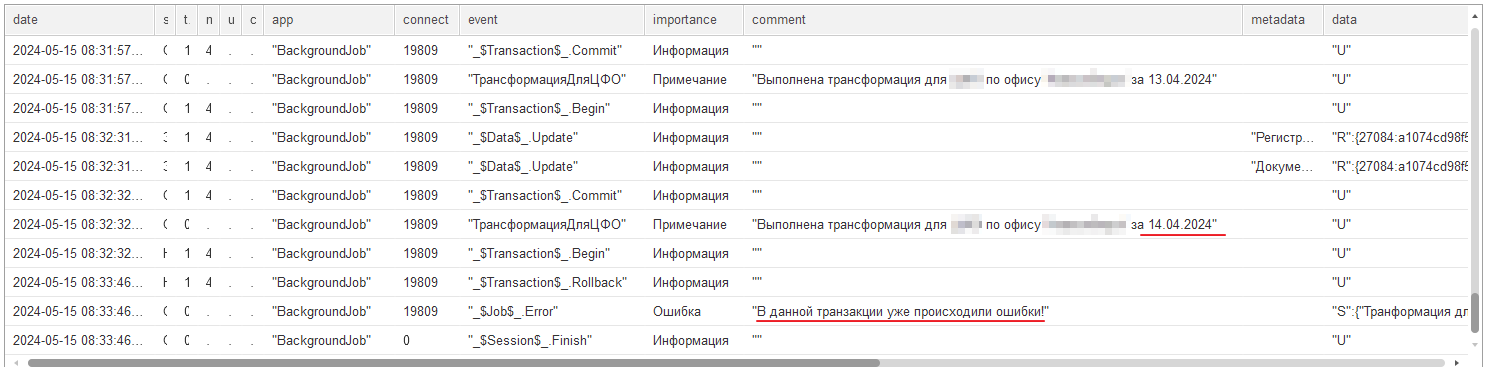
Мы пришли к тому же результату, что и в ручную. Но преимущество данного подхода — универсальность и свобода в описании любых алгоритмов. Шаг получает события по любой строке расшифровки диаграмм журнала регистрации и независим от вида приложения. И открыт для модификации.
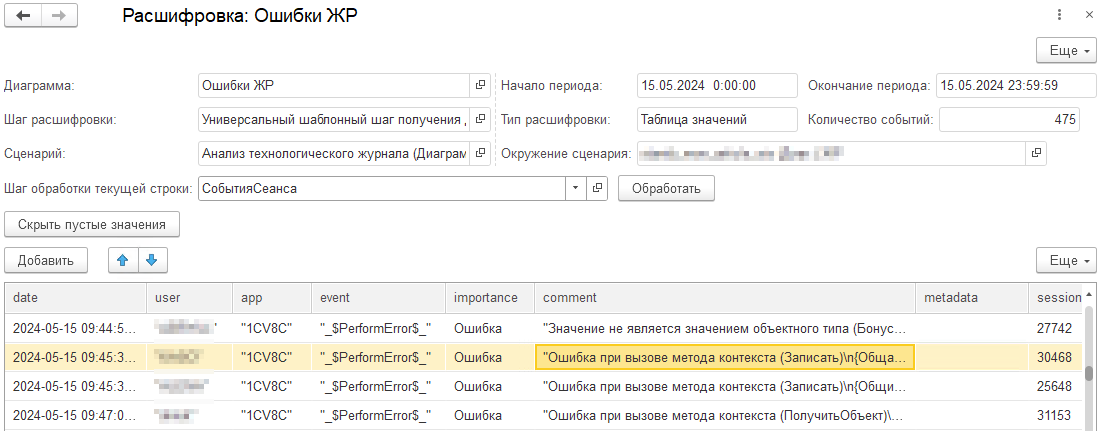
Для демонстрации универсальности написанного шага настроим другую диаграмму «Ошибки ЖР», например, по ошибкам пользователей, с группировками event и metadata:
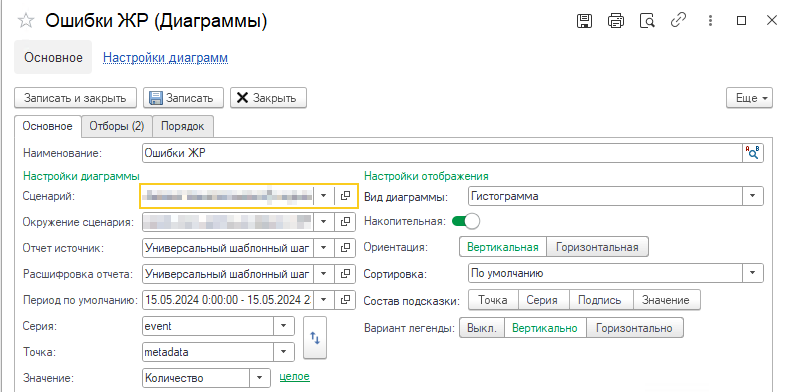
Укажем отборы:
- Importance = Ошибка.
- app <> «BackgroundJob», чтобы отсеять ошибки фоновых заданий.
Формируем диаграмму:
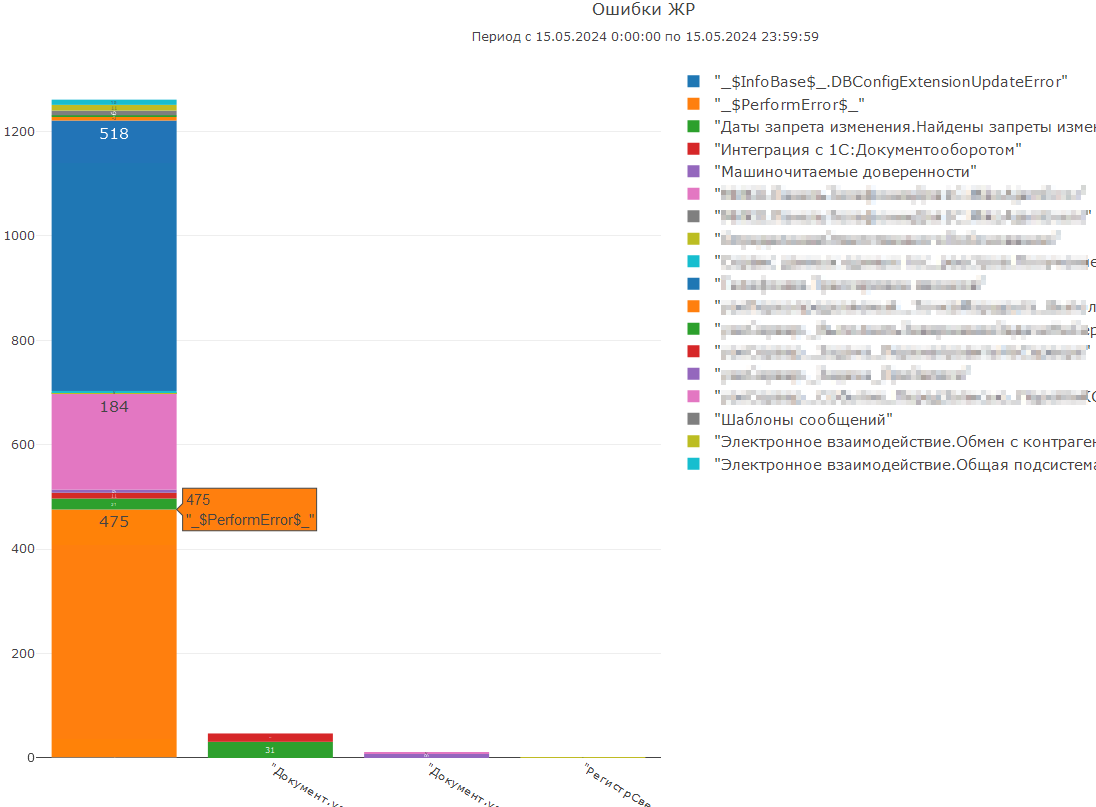
Расшифруем столбец по событию «_$PerformError$_», в котором не указаны метаданные, и увидим, к примеру, ошибку записи некоего объекта:
Точно также, как при поиске фонового задания, для понимания действий пользователя перед возникновением ошибки можно с помощью шага «СобытияСеанса» выбрать все события сеанса пользователя:

В предыдущих событиях пользователя находим событие, в котором, вероятнее всего, указан приводящий к ошибке элемент.
Заключение
Давайте подведем промежуточный итог по рассмотренным экспертным случаям и выделим в чем их ценность.
Первый случай показывает, что игнорировать «мелочи» можно не всегда. Кумулятивный эффект «мелочи» может быть больше, чем эффект от одного большого запроса, одного мощного вызова или метода в коде. Вспоминается хрестоматийный анекдот по этому случаю:

— Нискока!
— Накапайте мне триста капелек!
Второй случай показывает, как можно использовать инструмент для элегантного отслеживания счетчиков производительности, своевременного информирования, если что-то идет не так, и проведения расследования не выходя за рамки системы мониторинга. Да, ранее мы рассказывали как всё это можно сделать иначе, но усилий без постоянного мониторинга придется приложить больше.
И третий случай показывает, что «Журнал регистрации» несет порой для эксперта не меньше полезности чем логи ТЖ и счетчики производительности. А если объединить все три источника информации, то мы получаем возможность для комплексного анализа.
Описанные случаи не представляют собой конечного множества, как в части возникающих проблематик, так и подходов к расследованию. Однако, острый глаз подметит, что если следить за информационной системой на постоянной основе, то и справляться со сложностями много проще, сохраняя здоровье системы и нервы — свои и пользователей.
Это не последняя часть статьи, посвященная экспертным случаям, при расследовании которых мы пользуемся функционалом «Мониторинга производительности», поэтому следите за выходом новых статей на rarus.ru в разделе от экспертов.
От экспертов «1С-Рарус»

















