



Оглавление
- Интенсивность и важность развития систем на основе машинного обучения
- Машинное зрение в системе общественного питания. Частный случай, но с важными особенностями
- История развития систем машинного обучения и машинного зрения как частного случая
- Необходимость управления процессом
- Датасет
- Формирование инструмента управления
- Промышленная эксплуатация вносит свои коррективы. Процесс не останавливается, поэтому нельзя утверждать, что один раз собранный датасет всегда рабочий
- Участие человека добавляет шум
- Накопление данных требует оптимизации производительности операций обмена и выборки
- Собираем всё в одном месте
- Собственная система управления Машинным зрением как инструмент управления
- Учитываем особенности общепита в управлении системой машинного зрения
- Изображения как отдельные сущности, отнесенные к классу
- Разделение хранения изображений по проектам и терминалам
- Порционность блюд
- Использование типового механизма присоединенных файлов
- Платформенный сервис хранения двоичных данных — сравнительная характеристика
- Миниатюризация изображений для ускорения быстродействия
- Хэширование при формировании векторов изображений для решения задачи поиска
- Система инвентаризации изображений
- Пополнение состава и отбраковка изображений, которые не соответствуют нормальному виду класса
- Разделение изображений на активированные, деактивированные, не обработанные
- Реализация инвентаризации картинок в собственной системе управления Машинным зрением
- Выделение эталонных изображений
- Формирование «Альманаха»
- Кто делает инвентаризацию? Мы или заказчик?
- Переобучение модели машинного зрения с учётом изменения датасета
- При промышленной эксплуатации необходимо периодически переобучать модель из-за пополнения состава данных
- Пополнение датасета через валидацию изображений
- Формирование и отправка датасета на обучение из собственной системы управления Машинным зрением
- Анализ общих показателей обучения
- Анализ показателей обучения по классам
- Модель как результат обучения
- Заключение
Интенсивность и важность развития систем на основе машинного обучения
Системы на основе машинного обучения играют все более заметную роль в нашей жизни. В будущем интенсивность их использования будет только расти. Широкий диапазон областей применения наряду со способностью решать сложные задачи делает вопрос развития данных систем особенно важным. Все больше людей, руководствуясь как извечным интересом к новому и неизведанному, так и необходимостью решения практических задач, связывают свою трудовую и научную деятельность с данными системами. В этой статье мы поделимся нашим опытом работы.
Машинное зрение в системе общественного питания. Частный случай, но с важными особенностями
Одной из областей применения систем на основе машинного зрения является общественное питание. Контроль качества продукции, автоматизация процессов производства, использование распознавания в терминалах самообслуживания — вот лишь небольшой перечень задач, которые с успехом решаются в области общественного питания.

Внедрение систем на основе машинного зрения позволяет не только оптимизировать производственные процессы и повысить качество продукции, но и высвободить сотрудников для выполнения более важных задач путем оттягивания «на себя» решения некоторых рутинных задач. Конечно, полностью заменить человека и сделать производственный процесс полностью автоматизированным крайне маловероятно, но существенно оптимизировать можно уже сейчас.
История развития систем машинного обучения и машинного зрения как частного случая
Машинное обучение возникло практически сразу же, как появились первые ЭВМ. Давайте кратко проследим, какими путями шло развитие этой прикладной науки, которая агрегировала в себя такие области знаний человечества, как математика, физика, биология, машиностроение и другие.
1950-е годы — исследования в области машинного обучения начались с работы таких пионеров, можно сказать столпов, как Алан Тьюринг, который предложил концепцию «машины, способной учиться». Из-за быстрого продвижения теоретической и экспериментальной базы возникло ощущение, что до создания разумной машины — рукой подать. Но, как всегда, действительность оказалась намного интересней.
1960-е годы — очень большой подъем интереса к нейронным сетям. В 1958 году Франк Розенблатт разработал Perceptron, который мог распознавать формы на основе входных данных. Например буквы, числа. Становиться возможным практическое применение простых нейросетей. Например, при распознавании рукописных чисел на почтовых конвертах.
1970-е годы — системы, основанные на правилах, стали популярными благодаря формализациям и теории, созданной в области искусственного интеллекта. Бурное развитие теории нечетких множеств — данные понятия, немногим ранее, были впервые предложены американским ученым Лотфи Заде. Создание первых экспертных систем на основе правил.
1980-е годы — появление многоуровневых нейронных сетей и методов обратного распространения ошибки (backpropagation) дало новый импульс нейронным сетям и сделало их популярными для решения сложных задач. Также активно применяются генетические алгоритмы, оптимизационные алгоритмы. Все ждут что вот—вот и ЭВМ пройдет тест Тьюринга, и человек может уже и не работать.
1990-е годы — период зимы. Теоретическая база нейронных сетей уже довольно развита, но из-за недостаточного развития мощности ЭВМ, трудностей со сбором датасетов для обучения и других причин интерес исследователей сильно переключился к математическим методам.
2000-е годы — возврат интереса к машинному обучению случился благодаря увеличению вычислительных мощностей, доступных данных и новым алгоритмам, появлению мощных процессоров, способных сильно ускорять вычисления, а также увеличению емкости накопителей. Появляются «глубокие» нейронные сети, которые продемонстрировали выдающиеся результаты в задачах классификации изображений (например, AlexNet на конкурсе ImageNet в 2012 году).
2020-е годы — продолжается активное развитие технологий машинного обучения и машинного зрения. Мощное развитие теоретической базы для работы с вариационными автоэнкодерами, генеративными сетями, диффузионными моделями, трансформерами, большими языковыми моделями. Также GPT уже хорошо справляется с тестом Тьюринга. В общем, то что прогнозировали в 70-е годы прошлого столетия начинает уже потихоньку исполняться.
Необходимость управления процессом
Модель нужно держать под контролем
Модели машинного обучения — это объекты, которые были обучены для распознавания определенных типов шаблонов. Мониторинг и отслеживание состояния моделей являются важными задачами. Даже хорошо обученная модель с течением времени может начать деградировать по показателям качества. Например, если обучить модель распознавать блюда, приготовленные одним поваром, то при смене повара модель может выдавать худшие результаты, т. к. модель не обучена на фото блюд от нового повара. Здесь необходимо, что говориться держать состояние модели под контролем, чтобы модель была адекватна в применяемой среде.

Борьба с шумом
Шум в данных — это большая проблема при обучении любой модели. Для борьбы с ним разработаны достаточно мощные алгоритмы и теоретическая основа. Что такое шум? Вкратце, шум — это часть данных, которые не укладываются в какие — то средние рамки основного датасета. Приведем картинку, из которой станет понятно, что такое шум:
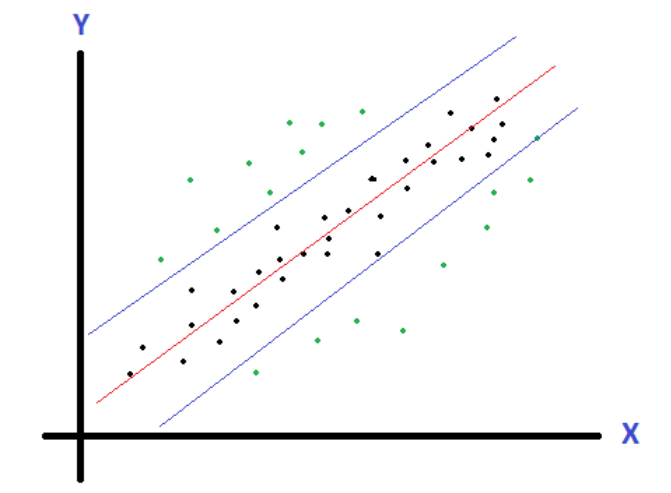
Красная линия — это среднее значение, или центр масс наших данных. Синие линии — это доверительный интервал наших данных. Доверительный интервал — это приблизительный диапазон значений, который с высокой степенью вероятности включает все данные. Черные точки — данные, которые принадлежат доверительному интервалу. А вот зеленые точки — это шум, маргиналы, которые вне нашего доверительного интервала. Этот шум при обучении модели будет мешать тренировке. И нужно от него по возможности избавляться. Очень хороший метод — расчет доверительного интервала и выкидывание тех данных, которые вне нашего доверительного интервала.
Но не все так просто. Иногда сама природа данных может быть такой, что сложно выделить шумовую природу в данных. Тогда приходится прибегать к более сложным эвристикам.
Вектор и эмбеддинг объектов
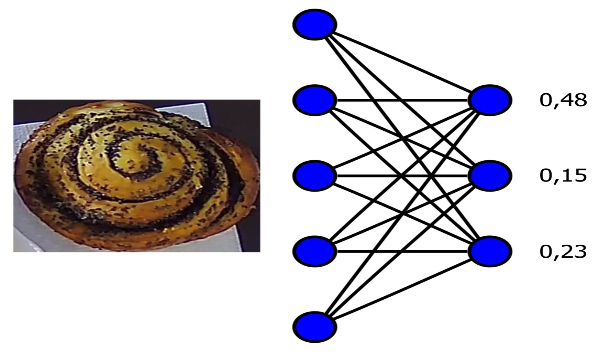
Вектор обычно ассоциируется с направленным отрезком, имеющим как длину, так и направление. Но часто в машинном обучении под вектором подразумевается набор некоторых чисел, однозначно определяющих некоторый объект. Например, картинку, слово. Набор этих чисел, или как их ещё называют — эмбеддингов объекта, является хитрой, или как говорят, интегральной характеристикой объекта. Обычно меньшего размера, чем сам объект. Например, картинка размером 1024 × 768 занимает 9437184 байт при разрядности float32. Тогда как вектор эмбеддинга может занимать всего 1024 байта. Это позволяет осуществлять быстрый поиск по так называемому хешу. Где в качестве хеша используется эмбеддинг объектов.
Модификация и восполнение данных
При работе уже обученной модели также немаловажным вопросом становится ее дообучение, чтобы модель адекватно реагировала на совершенно новые данные. Это можно хорошо иллюстрировать следующей картинкой:
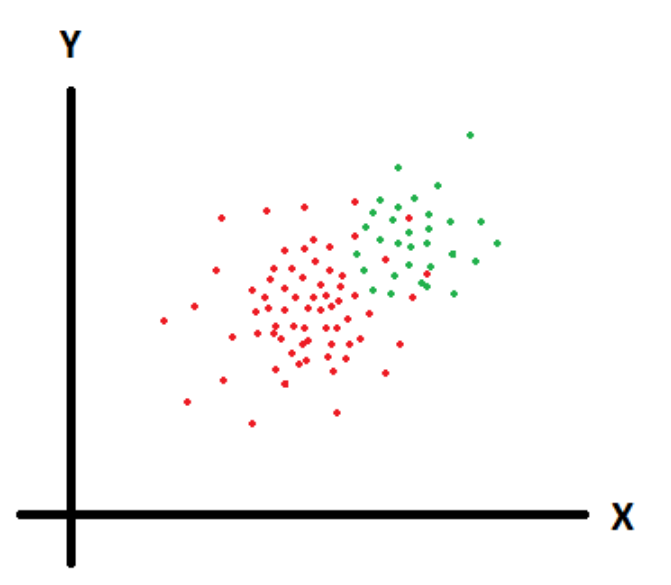
Здесь красными точками обозначены данные, на которых модель была обучена. Зелеными точками обозначены данные, которые стали «поступать» модели, скажем, через три месяца.
Например, модель была создана для того, чтобы находить блины на фото, но обучалась на фото, где блины были приготовлены поваром, который работал в летнюю смену. Через три месяца наступила осень, на объект приехал новый повар. И блины он стал готовить по-другому. В некотором пространстве признаков будет смещение координат этих признаков. Если модель не дообучать, то модель будет плохо работать на фото блинов осенью. Конечно, в процессе обучения можно собрать фото блинов и от старого, и от нового повара, но это был пример того, как можно получить так называемую смещенную оценку модели. В данном случае смещенную в сторону признаков фото блинов повара, работавшего летом.
Датасет
Всегда ли датасет «рабочий»?
Датасет в системах на основе машинного зрения — это коллекция изображений или видео, которая помогают системам машинного зрения понимать и распознавать визуальную информацию. Датасет представляет собой упорядоченный набор данных, который используется для тренировки и тестирования моделей машинного обучения.

Нет гарантии, что один раз собранный датасет будет «рабочим» всегда. Под «рабочим» мы понимаем такой датасет, на котором была обучена модель, и работающая на основании этой модели система распознавания соответствует заданным критериям эффективности — скорость, качество и другие. Данные по ходу работу системы обновляются и для получения необходимых результатов наш датасет должен соответствовать актуальному состоянию набора данных.
В чем сложности сборки датасета?
Не всегда так просто собрать адекватный датасет, который включает в себя все множество вариаций. Например, если модель распознает приготовленные блюда, то так как повар может поменяться, то и вид приготовленных блюд также может меняться. Что также накладывает требование к модели — чтобы модель корректно адаптировалась к виду приготовляемых блюд.
Производить переобучение модели на новых фото без учета «старых» данных, на которых модель была обучена ранее, не всегда хорошая идея.
Модель может забыть данные, на которых уже была обучена и будет хуже обобщать на не знакомых ей данных в режиме инференса (предсказания). Что же означает «хуже обобщать»? Это значит, что если модели «показать» данные из старого датасета, на котором модель была обучена ранее, но на котором не обучалась при обучении по новым данным, то по старым данным модель будет хуже работать, чем старая модель, обученная на старых данных.

Да и сами новые данные могут поступать последовательно и не часто, сбалансированность данных может быть под вопросом.
Например, некоторое блюдо приготовляют часто, а другое нет. Все это ставит перед исследователем ряд задач, решение которых позволит построить гибкую модель, которая адаптируется к изменчивости данных.
Формирование инструмента управления
Промышленная эксплуатация вносит свои коррективы. Процесс не останавливается, поэтому нельзя утверждать, что один раз собранный датасет всегда рабочий

Как мы знаем, рабочее внедрение всегда отличается от тестовой и даже пилотной эксплуатации. И данный случай не исключение. Непрерывный рабочий процесс, постоянно растущий объем данных разного качества, влияние человека и внешних факторов — вот лишь небольшой перечень вопросов, с которыми предстоит столкнуться при промышленной эксплуатации.
Одним из важных факторов является непрерывность рабочего процесса на объекте. Это обуславливает постоянное развитие системы, что вынуждает нас осуществлять постоянный мониторинг работы, и, по необходимости, вносить коррективы для оптимизации и улучшения работы. Одним из ярких примеров этого является постоянных рост объема данных. Причем данные эти разного качества — какие-то лучше, какие-то хуже. Ввиду этого одной из важных задач является поддержание актуального состояния датасета.
Участие человека добавляет шум

Участие человека в производственном процессе также является немаловажным фактором. Причем влияние может быть как позитивным, так и негативным. Ответственное отношение к работе, внимательность, корректное выполнение порядка работы с системой со стороны персонала могут существенно улучшить качество эксплуатации системы.
Но, к сожалению, пресловутый «человеческий фактор» и его возможное негативное влияние никто не отменял. Все мы можем допускать ошибки, как осознанно, так и нет. Возникновение «шума» ввиду деятельности человека оказывает существенное влияние на систему, причем чаще всего в негативном ключе. Анализ и нивелирование воздействия данного фактора является одной из самых важных задач, с которой мы столкнулись при эксплуатации системы.
Накопление данных требует оптимизации производительности операций обмена и выборки

Накопление данных, причем порой весьма существенное, это обычное явление при промышленной эксплуатации систем. И это может стать проблемой. Особенно в том случае, когда на этапе проектирования и отладки работа осуществлялась на объеме данных, который существенно меньше реального. В данном случае накопление данных может привести к проблемам с производительностью, и, как следствие, к необходимости проведения оптимизации работы системы.
Одной из операций, где могут возникнуть проблемы с ростом объема данных, является выборка данных. Очень часто, в случае, когда небольшой объем данных выбирается мгновенно, при получении больших блоков данных могут возникать проблемы с производительностью. С получением больших блоков данных сопряжены такие операции, как отражение состава изображений класса, групповая обработка данных при формировании сжатых изображений и установке статусов, отправка датасета на обучение и многие другие. Существуют различные подходы для оптимизации операции выборки. В нашей системе управления мы использовали разбиение большого объема данных на блоки и раздельную их обработку.
Обмен данными тоже может стать «узким» местом при возрастании объема данных. В нашей системе управления мы использовали брокер сообщения для реализации задачи обмена данными.
Собираем всё в одном месте
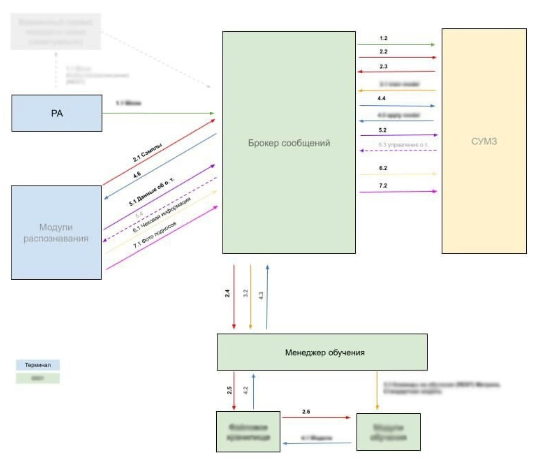
Система на основе машинного зрения, которая была реализована, имеет сложную структуру. Она состоит из различных достаточно крупных функциональных блоков, которые вполне себе могут работать самостоятельно. Это такие части, как инструмент продаж (РестАрт), модули распознавания, менеджер обучения. Стоит отметить, что указанные блоки реализованы на различном программном обеспечении, что привело к возникновению дополнительных задач синхронизации данных.
Для решения задачи синхронизации данных было принято решение использовать брокер сообщений. Использование брокера позволяет не только соединить воедино разработанные на разном программном обеспечении системы, но и обеспечить асинхронность работы систем. В качестве брокера сообщений используется RabbitMQ. Повышение надежности передачи данных достигается в том числе за счет использования механизма «обратной квитанции» Это означает, что сообщение в брокере будет храниться до тех пор, пока брокер не получит сообщение об успешной загрузке со стороны читающей данные системы.
Отдельно стал вопрос об организации управления полученной сложной системой. С одной стороны, необходимо было иметь весь набор инструментов управления в одном месте, что позволило бы не «распыляться» по разным блокам в попытках упорядочить работу системы. С другой стороны — стала все острее возникать необходимость мониторинга процесса работы системы. Как для отслеживания ошибок, там и для понимания происходящего. Для решения поставленных задач было принято решение о выделение отдельного блока управления в системе — системы управления машинным зрением.
Собственная система управления Машинным зрением как инструмент управления

Собственная система управления Машинным зрением (далее СУМЗ) является многофункциональным инструментом, который позволяет решать множество задач по управлению запуском и промышленной эксплуатацией систем на основе машинного зрения. С использованием данной системы мы решаем большой объем задач, которые раньше решить было очень проблематично, а порой и невозможно. И перечень этих задач только растет по мере эксплуатации.
К основным возможностям системы можно отнести:
- Организация процесса управления. Через управляющие команды можно регулировать процесс обучения моделей, детектора, взаимодействия с сервером обучения и многое другое.
- Накопление и обработка данных. Весь объем данных, который терминалы получают в процессе промышленной эксплуатации, поступает и хранится в системе управления. Это позволяет в случае необходимости в любой момент обратиться к данным.
- Анализ данных. Подсистема анализа данных позволяет ответить практически на любой вопрос, который может возникнуть по работе терминалов, начиная от общего состояния продаж и заканчивая причиной аномалии в определении класса в конкретном чеке.
Учитываем особенности общепита в управлении системой машинного зрения
Изображения как отдельные сущности, отнесенные к классу
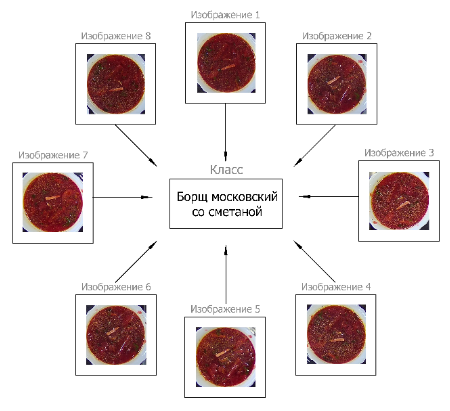
Различные изображения классов являются основной структурной единицей в системе управления машинным зрением. Именно изображения используются для решения задачи обучения моделей, на основании которых впоследствии осуществляется распознавание. Для решения данной задачи нам необходимо следить не только за количественным составом изображений, но и их качеством.
Для хранения изображений в системе управления мы используем отдельную справочную сущность. Ввиду того, что изображения мы используем для операции распознавания классов, очень важна связь изображения и класса, к которому оно относится. Хранение связи с классом позволяет выполнять групповую обработку изображений, дробление на группы и другие операции, которые будут необходимы при решении задач распознавания.
Наличие большого количества изображений по классам способствует более эффективному обучению моделей. Для этого в системе управления машинным зрением реализовано постоянное пополнение состава данных по изображениям классов. Основными источниками поступления изображений являются терминалы. При выполнении операции продажи состав изображений с подноса поступает в систему. Там же данные могут быть загружены вручную. Это необходимо для таких случаев как отсутствие связи с терминалом, загрузки начального блока данных и других.
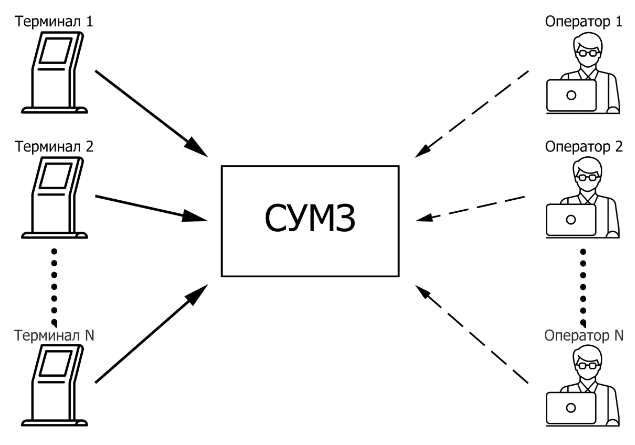
Разделение хранения изображений по проектам и терминалам
Даже при схожести классов ориентируемся на то, что картинки отличаются на каждом терминале.
Как уже отмечалось выше, промышленная эксплуатация вносит свои особенности в процесс эксплуатации систем на основе машинного зрения.
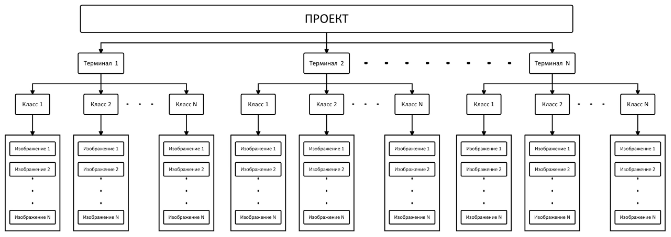
В данном случае существенным фактором является организация процесса работы на производстве, которая подразумевает наличие от одного до нескольких терминалов для каждой организации. Ввиду данной особенности было принято решение разделить хранение изображений классов в системе управления машинным зрением по проектам (они же организации) и терминалам.
Можно возразить, что, например, сосиски будут сосисками вне зависимости от того, на каком терминале мы будем их распознавать. И в этом есть доля правды. Как и верным является тот факт, что вид блюда может различаться ввиду таких причин, как порядок приготовления, рецептура, ингредиенты, правила раздачи, навыки повара и многих других.
Для повышения качества распознавания в системе управления машинным зрением мы отталкиваемся от факта, что на каждом терминале изображения классов различаются, и изображения идентичного класса с разных терминалов рассматриваются как различные.
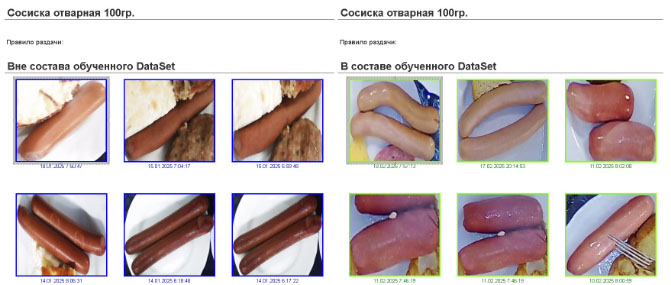
Порционность блюд
Одним из факторов, который существенно влияет на качество распознавания, является порционность блюд. Если мы предполагаем, что распознаваемое блюдо будет, например, сосиска в единственном числе, а на тарелке, две или три сосиски, то для системы идентификации это может создать трудности, так как габаритные размеры, точнее соотношение сторон, одной сосиски и трех сосисок, лежащих рядом с друг другом, будут сильно отличаться. И если у нас в обучающей выборке были только фото с одной сосиской, то фото с тремя сосисками уже в пространстве признаков будет сильно отличаться.
Это может повлечь за собой некорректное определение блюда в худшем случае, или в лучшем случае коэффициент распознавания будет меньше, чем ожидается при детекции на одной сосиске.

Использование типового механизма присоединенных файлов
Изображения храним внутри информационной базы.
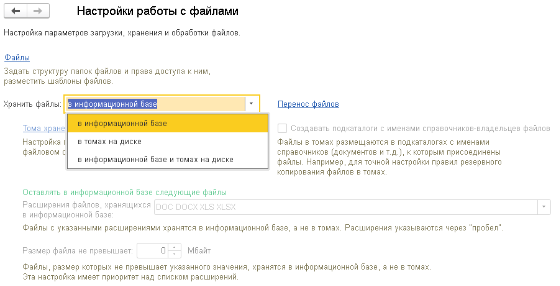
Для хранения изображений существуют различные подходы. Один из них — это хранение изображений в информационной базе 1С. При таком варианте хранения все данные файлов сохраняются при работе в СУБД. К преимуществам данного подхода можно отнести наличие всех данных в одном месте, упрощенное резервное копирование, отсутствие необходимости выполнять дополнительные настройки отдельного файлового хранилища. Однако следует учитывать и ряд нюансов, таких как возможный рост информационной базы.
Второй подход — это хранение файлов в томах на дисках. При использовании этого подхода все данные хранятся в определенных каталогах файловой системы, а в базе данных хранятся только ссылки на них. К преимуществам можно отнести масштабируемость, отсутствие ограничений по размеру файлов и снижение нагрузки на информационную базу. К недостаткам можно отнести необходимость предварительной настройки файлового хранилища (томов).
При реализации хранения в системе управления машинным зрением было принято решение о хранении файлов внутри информационной базы, что обусловлено необходимостью оперативного использования изображений и их небольшим размером.
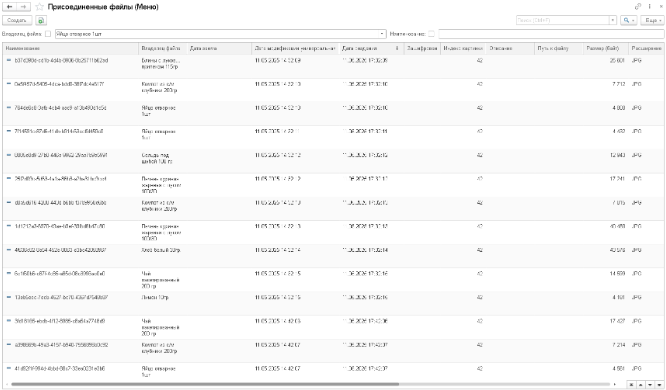
Для хранения состава изображений в системе управления машинным зрением был использован типовой механизм присоединенных файлов библиотеки стандартных подсистем. Для таких сущностей, как меню и чеки, были созданы отдельные справочники «Присоединенные файлы (Меню)» и «Присоединенные файлы (Чек)» для хранения изображений классов и подносов соответственно.
Использование типового механизма присоединенных файлов позволяет хранить файлы произвольного формата, непосредственно связанные с данными (изображение с меню, поднос с чеком), а также использовать типовой функционал для работы с данным блоком.
Платформенный сервис хранения двоичных данных — сравнительная характеристика
Хранилище двоичных данных — это специальный механизм платформы 1С, которых позволяет хранить большие двоичные данные не в информационной базе, а в специализированном хранилище. Ввиду того, что данный механизм является платформенным, мы решили рассмотреть его как вариант реализации хранения изображений классов в системе управления машинным зрением.
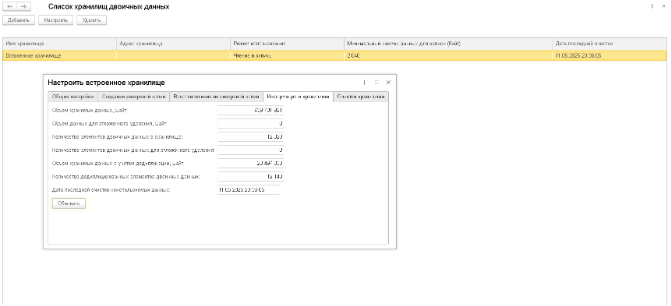
Прежде всего необходимо определить, какая операция над данными наиболее критична для нас с точки зрения производительности. Основной источник поступления изображений в систему управления — это терминалы. Изображения в основной поступают отдельными сообщениями из брокера сообщений, ввиду чего операция записи в информационную базу будет выполняться в фоновом режиме по одному элементу за одно сообщения.
Операция выборки данных более критична. В зависимости от настроек, при просмотре или инвентаризации из информационной базы за один раз может быть выбран большой объем изображений. Именно это операция с нашей точки зрения оказалась более приоритетной и была выбрана для исследования.
Как же мы проводили опыт? В сформированное встроенное хранилище мы поместили изображения одного из классов, по которому в системе управления изображениями их большое количество — порядка 15 000. Далее выполняли запрос на выборку данных на разное количество элементов — чтобы проследить производительность. Замер выполнялся на платформе версии 8.3.27.1559. Какие же результаты мы получили?
Элементов/Класс |
В хранилище двоичных данных |
В информационной базе |
|---|---|---|
100 |
0,26 с. |
0,05 с. |
500 |
1,1 с. |
0,18 с. |
1 000 |
2,4 с. |
0,35 с. |
2 000 |
4,7 с. |
0,7 с. |
5 000 |
13 с. |
2 с. |
10 000 |
23 с. |
4 с. |
Как видно из таблицы, по параметрам производительности операция выборки для изображений, помещенных в хранилище двоичных данных, уступает изображениям, которые не были помещены в хранилище. Ввиду этого на текущем этапе эксплуатации принято решения не использовать платформенный механизм хранилища двоичных данных.
Следует отметить, что платформенный механизм еще развивается и в предстоящие релизы возможно его обновление. Со своей стороны мы будем дальше отслеживать статус данного механизма и по мере обновления повторно рассмотрим возможность его использования.
Миниатюризация изображений для ускорения быстродействия
При промышленной эксплуатации состав картинок того или иного класса может пополняться с разной интенсивностью. По каким-то классам изображения приходят достаточно редко. Для других — достаточно часто. Например, хлеб в питании употребляет практически каждый из нас.
Это приводит к тому, что в системе управления машинным зрением по некоторым классам необходимо хранить и обрабатывать большой объем изображений. Одним из последствий этого могут стать проблемы с производительностью при существенном накоплении объема данных. Особенно это заметно при решении задачи визуализации изображений. Как же мы ускоряли быстродействие?

В качестве основного приема в системе управления машинным зрением мы использовали миниатюризацию изображений за счет сжатия. Для каждого изображения (класса или подноса) в системе автоматически формируется сжатое изображение, которое существенно меньше исходного по размеру при идентичных габаритах.
В местах визуализации большого объема изображений вместо оригинальных изображений показываются миниатюрные. При этом просмотр исходного изображения так же доступен через просмотр в отдельном окне. Сжатие изображений осуществляется с использованием метода resize() языка Python.
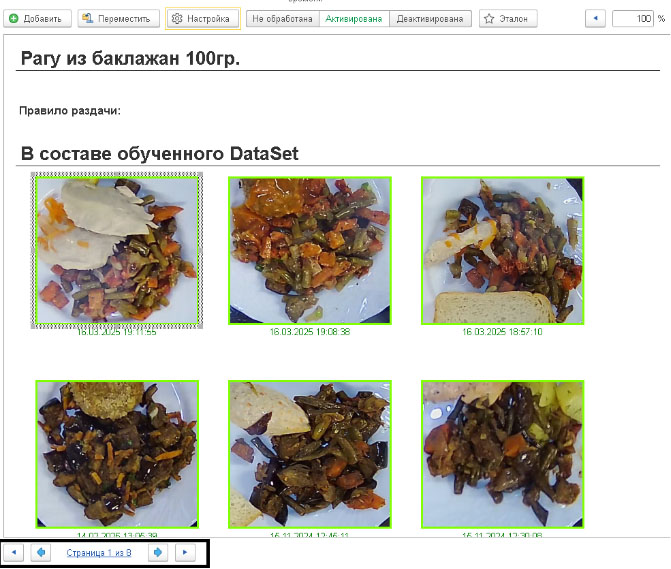
В тех местах, где это уместно, мы использовали постраничную развертку данных, или «пагинацию». Через механизм настроек определяется объем изображений, который будет виден на одной странице. Далее, используя кнопки навигации, оператор «листает» страницы и смотрит необходимый состав изображений. Это позволяет перейти от обработки полного объема изображений к частичной обработке.
Хэширование при формировании векторов изображений для решения задачи поиска
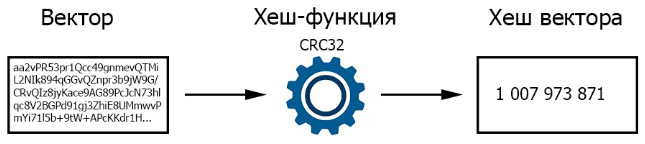
Одной из сопутствующих задач при переходе от изображений классов к векторам изображений является оптимизация операции поиска. Вектор изображения в системе управления машинным зрения представляет собой строковую величину большого объема. В результате, выполнение операции поиска «в лоб» приведет к проблемам с производительностью. Как же ускорить выполнение поиска по вектору изображения?
Для решения данной задачи в системе управления машинным зрением используется хеширование. При формировании для каждого вектора изображения расчитывается хеш-код, который фиксируется вместе с вектором. При выполнении операции поиска по вектору сначала вычисляется хеш-код вектора. Далее поиск выполняется уже по хеш-коду вектора, что значительно быстрее с точки зрения производительности. Для осуществления хеширования в системе управления машинным зрением используется алгоритм CRC32.
Система инвентаризации изображений
Пополнение состава и отбраковка изображений, которые не соответствуют нормальному виду класса
Одной из особенностей промышленной эксплуатации систем на основе машинного зрения является постоянное существенное пополнение состава изображений. Новые изображения дополняют систему актуальными данными с терминалов, что позволит своевременно выявлять изменения в классах и нивелировать негативные последствия.

Использование новых изображений при обучении моделей является очень важной задачей. Это обусловлено тем, что внешний вид класса может меняться со временем. Использование актуальных изображений при обучении способствует улучшению качества распознавания блюд.
При этом следует отметить, что полученные данные могут быть как хорошего качества, так и не очень. Низкое качество снимка, плохое освещение, наличие посторонних предметов — вот лишь небольшой список причин, по которым использование изображений может быть нежелательным при обучении модели.
Ввиду этого весьма остро встает задача отбраковки картинок, которые не соответствуют нормальному виду класса. Ведь при обучении модели важна не только актуальность изображений, но и их качество и соответствие эталонным изображениям класса.
Разделение изображений на активированные, деактивированные, не обработанные
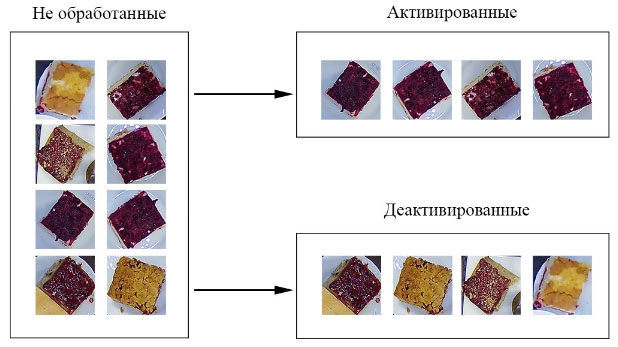
Для выполнения инвентаризации изображений, поступающих в систему управления, необходимо определить, как мы будем разделять все изображения по актуальности. Для этого мы разделили все множество изображений на следующие группы:
- Не обработанные. Изображения этой группы еще не прошли валидацию оператором. В эту группу первоначально попадают все изображения, которые пополняют систему в процессе эксплуатации. Также в эту группу необходимо относить изображения, валидацию которых необходимо повторить.
- Активированные. Изображение данной группы уже прошли валидацию оператором. В результате анализа оператор посчитал, что это «хорошие» изображения и они будут использованы при дальнейшем обучении модели.
- Деактивированные. Как и активированные, изображения данной группы уже прошли валидацию оператором. Но в результате анализа оператор посчитал, что эти изображения являются «плохими» и использоваться в дальнейшем при обучении модели они не будут.
При обучении модели используются только активированные изображения. Ввиду этого нужно отметить важность выполнения своевременной валидации изображений группы «Не обработанные». В результате изображения этой группы будут отнесены или к активированным, или к деактивированным. Это, в свою очередь, позволит использовать больше актуальных «хороших» изображений при обучении модели.
Реализация инвентаризации картинок в собственной системе управления Машинным зрением
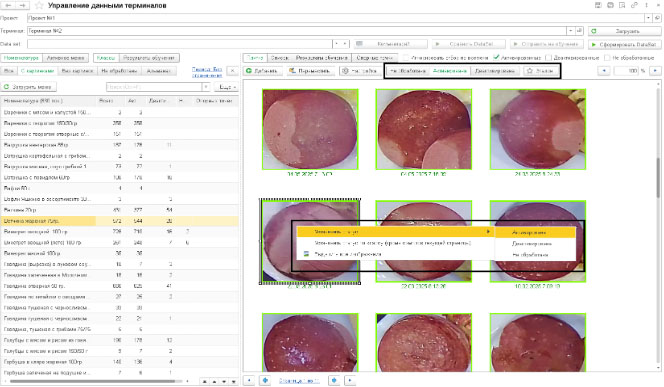
Как же мы выполняем отбраковку картинок в СУМЗ? Для решения данной задачи мы ввели систему статусов, каждый из которых соответствует группе изображений (Активирован, Деактивирован, Не обработан). Для каждого изображения, которое хранится в системе управления как присоединенный файл, ставится в соответствие «статус».
Статус изображения может меняться не только с «Не обработан» на «Активирован» или «Деактивирован». Статусы могут меняться произвольно, с любого статуса на любой. Определяющим в данном случае является корректность изображения по отношению к классу в момент проверки. Причем изображение, которое является «хорошим» сегодня, может при определенных обстоятельствах стать «плохим» завтра.
Для регулирования статусов в СУМЗ используется рабочее место «Управление данными терминалов». Предусмотрено как редактирование статуса для конкретного изображения, так и множественное изменение статусов для группы изображений.
Выделение эталонных изображений

Под эталонным изображением мы понимаем такое изображение, вид которого максимально приближен к изображению класса.
Выделение эталонных изображений позволяет решать следующие задачи:
- Определение образца для инвентаризации картинок. Оператор при выполнении инвентаризации опирается на эталонные изображения.
- Демонстрация вида блюда при изготовлении на кухне.
- Формирование альманаха.
В системе управления машинным зрением поддерживается установка до 5 эталонных блюд. Это позволяет более детально продемонстрировать корректный внешний вид блюда, что, в свою очередь, способствует более качественному решению задачи валидации. Следует отметить, что состав отнесенных к эталону изображений блюд не постоянен. Это может быть обусловлено как сменой повара, так и изменением вида блюда со временем при готовке одним поваром.
Формирование «Альманаха»
В общем смысле понятие «Альманах» подразумевает под собой сборник аналитических и практических материалов на заданную тему. В системе общественного питания понятие альманаха варьируется в зависимости от необходимых состава и глубины отражаемых данных. Мы рассматриваем альманах как инструмент отражения внешнего вида эталонных блюд и правил раздачи. Формирование альманаха существенно упростит работу не только инвентаризаторов, но и поваров.

Формирование альманаха позволяет представить в печатном виде сводный перечень определенного состава блюд для его дальнейшего использования на кухне, при подаче блюд, при контроле. Причем альманах может формироваться как в полном составе, так и частично. Это позволит не только получить его целиком при первоначальном формировании, но своевременно выполнять обновление и замену данных.
Кто делает инвентаризацию? Мы или заказчик?
Как же максимально эффективно выполнить инвентаризацию изображений? Наличие квалифицированного сотрудника, который способен эффективно визуально разделять изображения по группам способствует решению данной задачи. Соответственно первое и основное решение задачи инвентаризации — это выделение отдельного человека для этих целей.
Но что делать, есть в штате нет такого человека? Если он есть, но его занятость не позволяет эффективно и своевременно выполнять инвентаризацию? Или клиент настаивает на том, что этот процесс должны обеспечивать его специалисты? В этом случае можно предложить клиенту самостоятельно выполнять инвентаризацию, что является альтернативным вариантом решения задачи выполнения инвентаризации. Передача инвентаризации на сторону клиента позволяет не только снять с себя данную нагрузку, но и получить качественную валидацию изображений при наличии специалистов нужного уровня у клиента.
Система управления машинным зрением позволяет использовать оба варианта выполнения инвентаризации. В том случае, когда задача валидации передается клиенту, ему так же организуется доступ к инструменту выполнения инвентаризации — рабочее место «Управление данными терминала» — путем создания учетной записи с соответствующим набором прав.
Переобучение модели машинного зрения с учётом изменения датасета
При промышленной эксплуатации необходимо периодически переобучать модель из-за пополнения состава данных

Одним из факторов промышленной эксплуатации систем на основе машинного зрения является постоянное пополнение состава изображений. При запуске система не может существовать «в вакууме» и с течением времени состояние системы будет меняться. При этом можно однозначно утверждать, что внешний вид поступающих в систему изображений будет эволюционировать и претерпевать изменения. Смена повара, изменения поставщика ингредиентов, изменение навыков повара — вот лишь небольшой список причин, по который внешний вид блюда может меняться.
Негативным следствием данного фактора является тот факт, что исходный датасет, на котором первоначально была обучена модель, будет формировать все менее надежные результаты в плане распознавания. Что же делать в таком случае? Основным инструментом повышения качества операции распознавания является периодическое переобучения модели на обновленном составе датасета. Причем обновленный состав датасета будет включать как исходные, так и новые изображения. Следует отметить, что формирование обновленного датасета индивидуально для каждого терминала, что обусловлено различием изображений классов.
Пополнение датасета через валидацию изображений
Подготовка состава данных для обучения датасета в системе управления машинным зрением включает в себя два этапа.
Первый этап — это накопление данных. Существует два способа пополнения изображений того или иного класса. Первый и основной — это автоматическое поступление изображений про пробитии чеков на терминалах. При выполнении операции продажи из изображения подноса извлекаются изображение всех классов, которые входят в состав позиций чека. Далее эти изображения отправляются в систему управления машинным зрением отдельными сообщениями через брокер сообщений. Второй способ — добавление изображений классов вручную. Это резервный способ, который используется намного реже.

Валидация изображений является вторым этапом, когда мы из общего числа изображений классов исключаем нежелательные изображения. Подробнее о валидации мы уже говорили в разделе об инвентаризации данных.
Формирование и отправка датасета на обучение из собственной системы управления Машинным зрением
Процесс работы с датасетом в системе управления машинным зрением состоит из трех этапов. Прежде всего, это формирование датасета. Когда накопление и валидация изображений уже пройдены, настает время для формирования датасета.
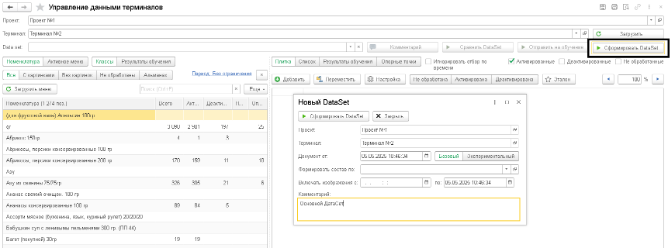
В состав датасета входят исключительно изображения, прошедшие валидацию и имеющие статус «Активирована». Следует отметить, что в системе управления машинным зрением датасет может быть сформирован как с полным составом изображений (Базовый датасет), так и с ограниченным по дате формирования набором изображений (Экспериментальный).
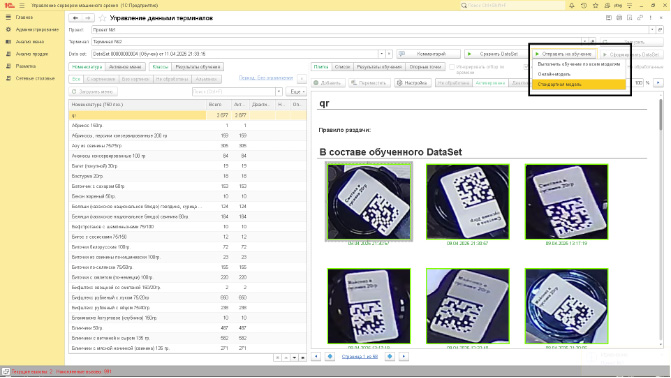
После того, как датасет сформирован, его необходимо отправить на обучение, указав модель обучения. Это является вторым этапом работы с датасетом.
Анализ общих показателей обучения
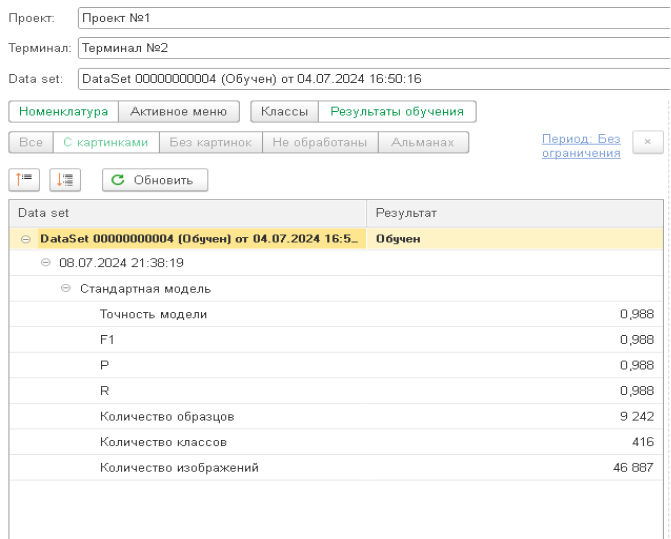
По мере выполнения обучения модели на обновлённом датасете в систему управления машинным зрением через брокер сообщения приходит сообщение об окончании обучения, которое содержит в себе несколько блоков данных. Третьим этапом работы с датасетом является анализ результатов работы. Первый блок данных — это общие метрики модели по результатам обучения.
Рассмотрим ситуацию, когда модель на основе поданных в нее данных должна вернуть оценку, относится ли изображение блюда к указанному классу. В результате модель вернет значение ИСТИНА (изображение относится к указанному классу) или значение ЛОЖЬ (изображение не относится к указанному классу).
Всегда существует ненулевая вероятность того, что модель машинного обучения ошибается при обработке поданных на нее данных. Это означает, что при сравнении полученного ответа модели с правильным, мы можем получить один из 4-х возможных вариантов:
- True Positive (TP, Истинно положительный). Модель определила, что изображение относится к указанному классу при том, что изображение реально относится к указанному классу.
- True Negative (TN, Истинно негативный). Модель определила, что изображение не относится к указанному классу при том, что изображение реально не относится к указанному классу.
- False Positive (FP, Ложно положительный). Модель определила, что изображение относится к указанному классу при том, что изображение реально не относится к указанному классу.
- False Negative (FN, Ложно отрицательный). Модель определила, что изображение не относится к указанному классу при том, что изображение реально относится к указанному классу.
Точность модели (Accuracy) — это доля правильно предсказанных классов ко всем предсказаниям:
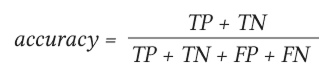
Несмотря на свою простоту и универсальность, данный показатель имеет определенные недостатки:
- Не учитывает дисбаланс классов: если один класс значительно преобладает над другим, то модель может быть смещена в ту сторону, и тогда высокая точность не будет отражать истинное качество модели.
- Не дает информацию о типе ошибок модели, например, о количестве ложноположительных и ложноотрицательных результатов, что не позволяет учитывать цену ошибки для разных классов.
- Зависит от порога классификации, изменение которого может значительно повлиять на значение точности.
Точность (Precision) показывает, какая доля предсказанных положительных примеров действительно является положительными. Данный показатель отражает способность алгоритма отличать конкретный класс от других классов:
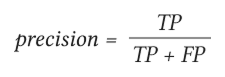
Полнота (Recall) показывает, какую долю реальных положительных примеров модель смогла правильно предсказать. Данные показатель демонстрирует способность алгоритма обнаруживать указанный класс вообще:
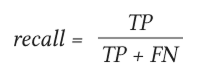
F1-мера (F1) — это среднее гармоническое отклонение между точностью (Precision) и полнотой (Recall):
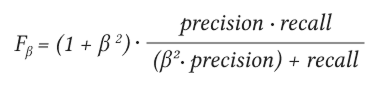
β в данном случае определяет вес точности в метрике. Мы используем β = 1, так как предполагаем, что Precison и Recall имеют одинаковую важность.
Количество классов характеризует общее количество классов, которые были переданы на обучение.
Количество изображений показывает общее количество изображений, которые были переданы на обучение.
Количество образцов показывает количество изображений, на котором происходило обучение. Количество образцов может быть меньше количества изображений — такая ситуация возникнет в том случае, когда для обучения была использована только часть от общего объема отправленных изображений.
Анализ показателей обучения по классам
Второй блок данных, получаемый с сообщением об обучении датасета — это метрики для конкретных классов.
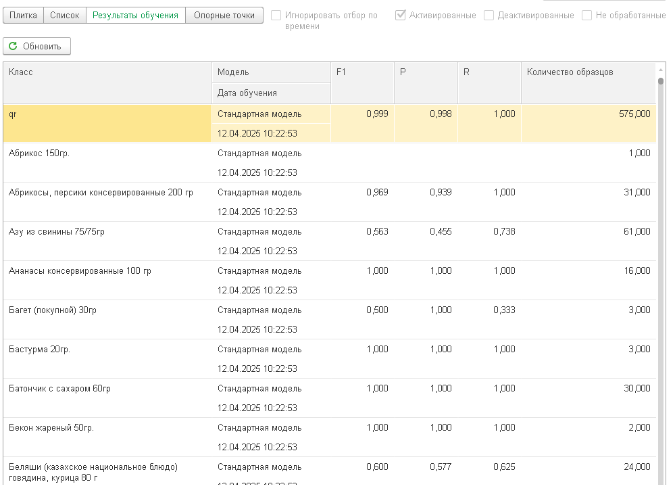
Состав метрик аналогичен общим метрикам модели. С той лишь разницей, что рассчитываются они не для всего объема изображений, а для каждого множества изображений класса.
Модель как результат обучения
Третий и основной блок данных, получаемый с сообщением об обучении на датасете — это файл модели обучения. Модель представляет собой двоичный файл большого объема. В системе управления машинным зрением хранение моделей организовано с использованием модуля присоединенных файлов библиотеки стандартных подсистем. Элемент справочника, который содержит модель, соотнесен с документом «DataSet».
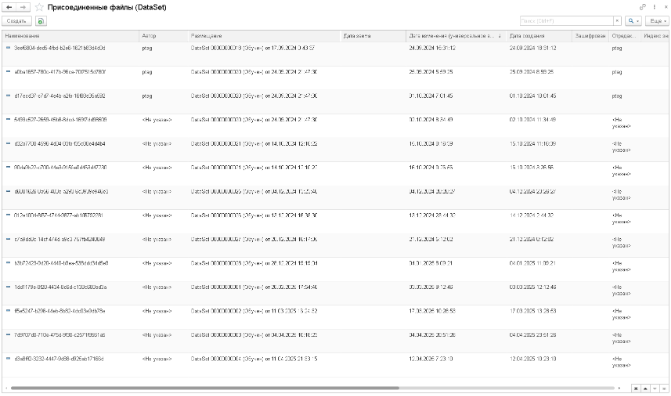
Файл обучения — это фактически память нашей модели, которая (модель) принимает решение, что за блюдо мы ей показываем. На вход модели подается фото блюда, в формате RGB (красный, зеленый, голубой). Далее картинка переводится моделью во внутренний формат (так называемый тензор) и на выходе модели мы получаем распределение вероятностей принадлежности к каждому классу. При этом сумма вероятностей по всем классам на выходе модели равна единице. Наибольшее значение вероятности дает нам предполагаемый класс блюда (булка, котлета или еще что‑то). В файле обучения содержатся веса модели.
Полученный в результате выполнения обучения на основе датасета файл модели необходим для последующей отправки на терминалы и установки его на них как модели распознавания для промышленной эксплуатации. Полученная модель позволит осуществлять распознавание данных при использовании подносов.
Заключение
Первая часть статьи наглядно показывает, что без системы управления данными технология распознавания блюд в общественном питании достаточно быстро деградирует в силу динамичности изменения процессов приготовления, эмоциональной составляющей поваров, ремонта помещения и прочих внешних факторов. Поскольку же мы имеем дело действительно с большими данными, мы должны заботиться о производительности, легкости интерпретации результатов, прозрачности происходящего.
То, о чем не было сказано в самом начале, а следовало бы, — о муках выбора, на чем реализовывать такую систему управления. Конечно, мы рассматривали разные варианты, но 1С победила всех. Платформа позволила в кратчайшие сроки создать необходимую систему управления, показала хорошие результаты по скорости и, как будет показано во второй части статьи, отлично интегрировалась с инструментами разметки и анализа результатов распознавания. В качестве небольшого частичного анонса второй части приведем пример инструмента анализа распознавания.
Об этом мы уже поговорим во второй части статьи.

От экспертов «1С-Рарус»
















