


Оглавление
- Введение
- Когда необходимо групповое перепроведение в 1С
- Когда необходимо оптимизировать групповое перепроведение
- Поиск причин замедления массового перепроведения документов
- Сложности разделения перепроведения на несколько потоков
- Схема разделения на потоки
- Механизмы параллельной обработки БСП
- Доработка группового перепроведения
- Результаты оптимизации
- Вспомогательные способы ускорения — восстановление последовательности
- Заключение
Иллюстрации в документе подготовлены с использованием демонстрационной базы с вымышленными сведениями. Совпадения с реальными данными случайны.
Введение
В решениях общественного питания и производства пищевой продукции одним из самых нагружаемых механизмов является обработка «Группового перепроведения документов». В ходе данной статьи мы постараемся ответить на вопрос, зачем вообще необходимо групповое перепроведение, а также как его можно ускорить.


Когда необходимо групповое перепроведение в 1С
Последнее время можно услышать такие лозунги компаний, как «продажа блюд по себестоимости». Звучит приятно, но всегда ли это возможно?
Представим себе ситуацию в субботу приходят ингредиенты на склад производства. Бухгалтер работает только по будням, потому документы поступления оформят только в понедельник, а готовить блюда нужно прямо сейчас, потому повар забирает ингредиенты со склада, использует в приготовлении и по факту оформляет документы «Выпуск блюд от 01.03». Тем самым количество ингредиентов по учету уходит в отрицательную область, а реальная себестоимость блюда невозможна к расчету и, как следствие, неизвестна.
| Номенклатура | Количество | Сумма | |
|---|---|---|---|
| Расход | Мука | 1 кг | 0 |
| Расход | Вода | 1 л | 0 |
| Приход | Лепешка | 5 шт | 0 |
В понедельник приходит бухгалтер и оформляет документ «Приходная накладная на 01.03» на ингредиенты.
| Номенклатура | Количество | Сумма | |
|---|---|---|---|
| Приход | Мука | 100 кг | 13000 |
| Приход | Вода | 100 л | 5000 |
Количество ингредиентов вернулось в положительную область, но себестоимость блюда так и осталась нулевой и чтобы ее пересчитать, необходимо выполнить перепроведение документов. После чего мы сможем видеть объективную картину по суммам.
| Номенклатура | Количество | Сумма | |
|---|---|---|---|
| Расход | Мука | 1 кг | 130 |
| Расход | Вода | 1 л | 50 |
| Приход | Лепешка | 5 шт | 180 |
Данное перепроведение можно попробовать провести по очереди и самостоятельно, но если используются типовые конфигурации, то удобнее использовать обработку «Групповое перепроведение документов». Они могут слегка отличаться в названиях, но смысл будет примерно одинаковый.
Пользователю необходимо будет указать период перепроведения. Затем система выполнит запрос на выборку всех документов за указанный период и отсортирует их по дате и ссылке.



Далее система по очереди возьмет каждый документ и выполнит его проведение.

Таким образом, для восстановления себестоимости пользователям необходимо выполнять операцию группового проведения, которая, в свою очередь, выполняет последовательное проведение всех документов за период.
Вроде бы логично и с задачей справляется, но такой подход будет избыточен для решения задачи восстановления себестоимости из-за отсутствия анализа необходимости проведения конкретных видов документов и операций. Например, документы поступления товаров, заказов покупателей, заказов на производство, заказов на перемещение и т. п. можно пропускать из выборки. Данные виды документов не выполняют списание ингредиентов и товаров, а также производство блюд. При этом их проведение может занимать существенное время.
Когда необходимо оптимизировать групповое перепроведение
Представим ситуацию, что пользователь решил перепровести документы за две недели. За это время в базе было зафиксировано 300 заказов покупателей, на их основании было создано 200 заказов на производство и 100 документов поступления. Итого 600 документов.
| Вид документа | Количество |
|---|---|
| Заказ покупателя | 300 |
| Заказ на производство | 200 |
| Поступление товаров | 100 |
Теперь уточним, что проведение каждого подобного документа занимает «золотую» 1 секунду. Следовательно, общее время их перепроведения займет 10 минут, а пользы от их перепроведения не будет. Исключив их из исходной выборки можно сократить общее время проведения. Ведь как пел один известный медвежонок: «Даже немножечко, чайная ложечка — это уже хорошо».
Потому одной из первых доработок в конфигурации «1С:УНФ 8. Управление предприятием общепита» была реализация функциональности «Только расходные документы», которая и выполняет подобную фильтрацию. Однако если бы все было так просто, то данная статья не случилась бы.
Следующий случай произошел на крупном предприятии общественного питания, где для автоматизации деятельности использовалась конфигурация «1С:УНФ 8. Управление предприятием общепита».
После основного внедрения прошло порядка полугода, компания была довольна и решила влить оставшиеся филиалы в единую базу. После того как в базе одновременно стало существовать 130 организаций, был зафиксирован рост длительности операции группового перепроведения документов. Что с одной стороны было ожидаемо, но позже длительность стала составлять 14 часов и перестала влезать в технологическое окно. Когда пользователи с утра начинали работать, то при создании новых документов стали появляться «тормоза», а иногда и выдаваться ошибки о блокировках. Работать в системе становилось невыносимо и надо было что-то делать.
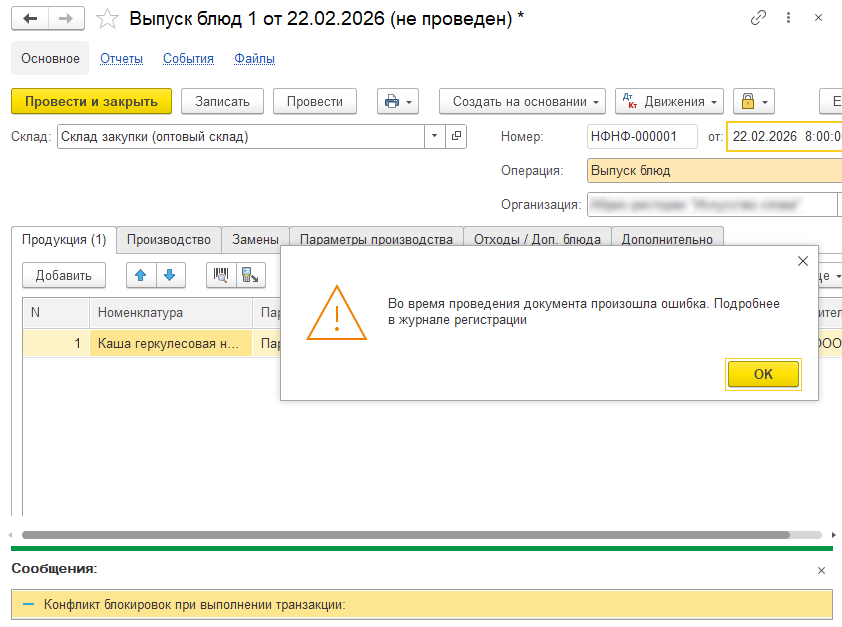
Перепроведение делали в среднем каждые три дня. За это время скапливалось порядка 20 000 расходных документов.
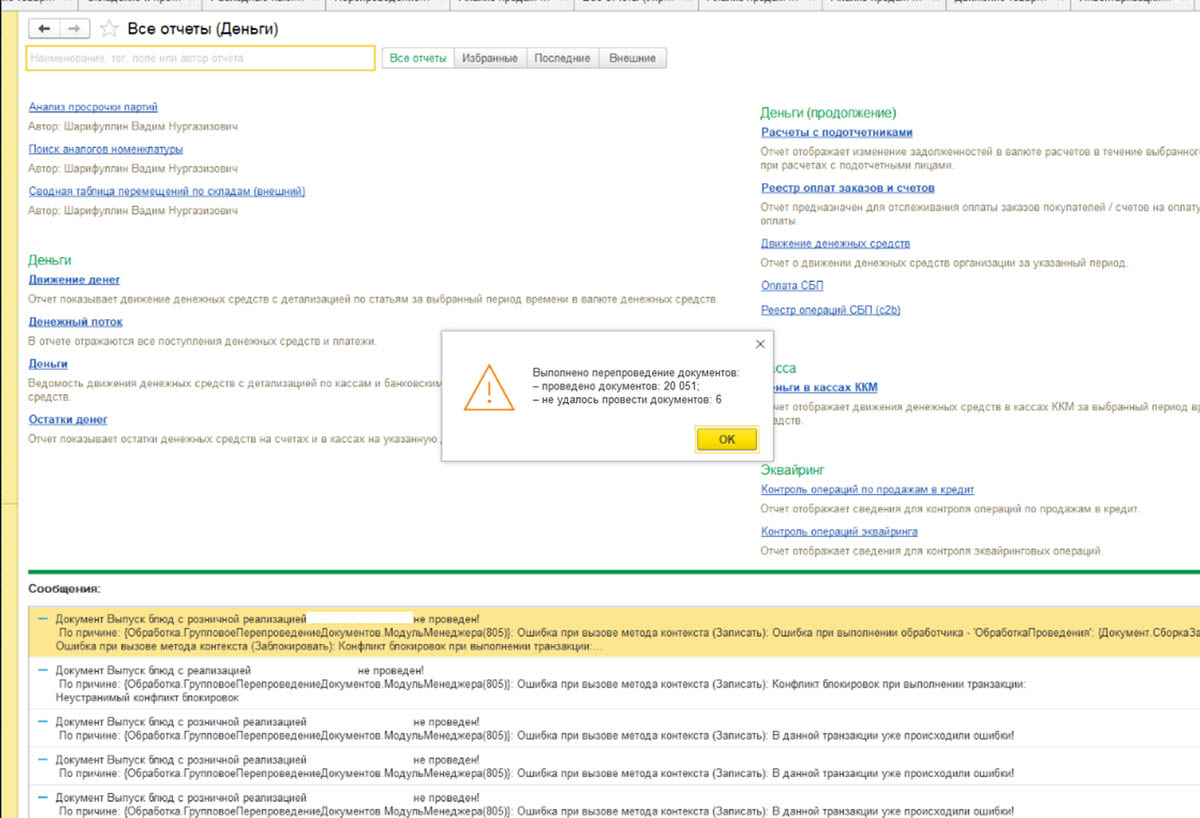
Поиск причин замедления массового перепроведения документов
Для анализа происходящего была подключена конфигурация «1С-Рарус: Мониторинг производительности», которая позволяет анализировать как логи технологического журнала, так и счетчики производительности. Подробнее как осуществлять подобную настройку мы рассказывали в статьях: часть I и часть II.
Завершив настройку и повторив эксперимент с групповым перепроведением не было выявлено запросов с длительностью более 3 секунд и длительных блокировок, которые происходили бы в технологическое окно.


При этом анализ оборудования показал, что среди всех 12 ядер нагружается лишь одно. Ведь всё проведение документов осуществляется в едином фоновом задании, которое выполняет последовательное проведение документов.

Для того, чтобы избавиться от этого было предложено разбивать единый поток проведения на несколько. Тогда даже если время проведения каждого документа увеличится из-за высокого потребления ресурсов, то общая длительность должна сократиться.
Сложности разделения перепроведения на несколько потоков

Много нас, а он один.» ©
На первый взгляд может показаться, что создание нескольких потоков это весьма простая задача. К сожалению, это не так. Еще на этапе проектирования механизма необходимо ответить на ряд вопросов. Какие задачи будут решать потоки? Как разделять? Не будут ли они пересекаться? Сколько вообще их можно создать? Как отслеживать происходящее в них?
В нашем случае требовалось выполнять групповое перепроведение документов для восстановления себестоимости. Потому ответ на вопрос какие будут решать задачи — каждый поток должен будет перепроводить выделенные ему документы. А вот ответ на вопрос, как понять какие документы кому можно перепроводить, явно заслуживает рассуждения.
Представим себе, что у нас есть неограниченное количество ресурсов и нам предстоит перепровести 10 000 документов. Если мы попробуем разделить их на 100 потоков и каждому выделим по 100 документов, то скорее всего результат будет неудачным.
Во-первых, если потоки не будут соблюдать последовательность во времени проведения, то работа будет напрасна, т. к. себестоимость только больше собьется. Во-вторых, без явного разделения пространств потоки могут начать пытаться проводить данные по одинаковым аналитикам, что может привести к блокировкам на ожидании или взаимоблокировкам. Например, если два потока начнут проводить документ реализации содержащий одинаковую номенклатуру с одного склада. Тогда для контроля себестоимости система будет вынуждена установить блокировку, а т. к. два потока это сделают одновременно, то конфликт обеспечен.
| Документ 1 от 01.01 | Регистр накопления Запасы | ||
|---|---|---|---|
| Расход | Организация 1 | Склад 1 | |
| Сгущенка банка | 5 л. | 500 руб. | |
| Документ 2 от 01.01 | Регистр накопления Запасы | ||
|---|---|---|---|
| Расход | Организация 1 | Склад 1 | |
| Сгущенка банка | 3 л. | 300 руб. | |
Таким образом, для распределения на потоки необходимо выявить такую аналитику, которая позволит выполнять проведение без пересечения данных. Для выявления таких аналитик мы рассмотрели пересечение измерений регистров по которым фиксируются движения проводимых документов. По итогу остановились на единственной аналитике — организации.
| Основные регистры | |
|---|---|
| Запасы и затраты | Организация, Структурная единица, Номенклатура, Характеристика, Партия, Заказ покупателя, Счет учета |
| Запасы на складах | Организация, Структурная единица, Номенклатура, Характеристика, Партия, Ячейка |
| Управленческий | Организация, Сценарий планирования, Валюта |
| И т .д. |
Несмотря на то, что в большинстве регистров было измерение структурной единицы, в регистре бухгалтерии «Управленческий» из пересекающихся была только организация. Так как данный регистр двигается всеми анализируемыми документами, то проведение одновременно двух документов по одной организации, даже по разным структурным единицам и номенклатуре, приведут к пересечению пространств и блокировкам.

Схема разделения на потоки
После того как мы определились с аналитиками, давайте попробуем визуализировать процесс проведения документов как ориентируемый граф, где каждый узел будет являться проводимым документом. Если мы говорим, что все документы проводятся последовательно, то данный граф будет иметь один узел на верхнем уровне и один на нижнем.

Благодаря определению аналитик данный граф уже может быть представлен не только как одна «цепь», а иметь столько начальных и конечных узлов, сколько и аналитик, в нашем случае организаций.

Данные последовательности могут быть как связанные между собой, так и полностью независимыми ветками. Например, если в базе есть документ «Передачи товаров между организациями», то для его обработки необходимо, чтобы провелись все документы до него по обеим организациям. Независимые же таких ограничений не имеют.

Вспоминая теорию графов, можно вспомнить про такое понятие как вес ребра. В данном случае его можно охарактеризовать как время проведения документа узла, которое может зависеть как от объема самих документов, так и от алгоритмов расчета. Например, документ «Закрытие месяца» может в себе содержать только шапочную информацию, но может проводиться очень долго, т. к. требует выполнения множества предварительных подсчетов и выполняет сложные последующие алгоритмы расчетов. Возможна и обратная ситуация, подобная документам заказов: когда документ даже с большим количеством строк не выполняет сложных алгоритмов и их проведение будет быстрым.

В связи с тем, что анализировать все проводимые документы на степень их сложности в момент проведения может быть неоправданно сложной задачей, мы приняли решение выбрать за характеристику веса количество строк формируемых движений по регистру себестоимости («Запасы и затраты»). Отталкиваясь от гипотезы, что в расходных документах для анализа остатка и формирования движений по большему количеству строк товаров необходимо больше времени, чем когда списываемых строк меньше.

Тогда, если у нас будут три потока по трем организациям: в первой организации 3 документа, во второй — 2, а в третьей — 1, то воспользовавшись весом ребер можно организовать оптимальное разделение на потоки. Помним, что согласно стандартам разработки 1С не следует разрабатывать решения исходя из неограниченных ресурсов. Всё-таки процессорные мощности имеют ограничения на параллельную работу.


При этом не стоит утверждать, что потоки необходимо формировать один раз в самом начале проведения и более не редактировать. Ранее мы уже упоминали ситуацию переплетения потоков из-за документа «Передача товаров между организациями». В такой ситуации происходит процесс «ожидания», пока все документы по другой организации не будут проведены.

Из-за чего возможны ситуации когда будет быстрее разбить поток на несколько и перезапустить их несколько раз. Рассмотрим пример, когда у системы есть возможность проведения только в двух потоках. В первом потоке необходимо провести два документа за 30 секунд, а во втором три за 30 секунд. Для проведения второго документа первого потока («Документ 6») необходимо дождаться проведения всех документов второго потока. Потому общее время проведения составит 50 секунд.

Если посмотреть внимательно, то можно увидеть, что в первом потоке система проводит документы только по «Организации 3», а во втором по «Организации 2» и «Организации 1». Так как «Документ 6» выполняет движения по «Организации 3» и «Организации 1», то документ по «Организации 2» никак не влияет на проведение по данным организациям и его можно перенести из второго потока в первый. Тогда второй поток будет проводится уже за 17 секунд. Следовательно общее время проведения сократится до 43 секунд. На практике подобная оптимизация может приводить и к более существенным выигрышам.

Механизмы параллельной обработки БСП
Основные правила организации потоков мы проговорили, но как их запускать с учетом ограничений?
На сегодняшний день есть множество платных и бесплатных разработок, которые позволяют решать данную задачу. При этом все они устроены примерно одинаково: есть менеджер заданий, который принимает на вход процедуру для обработки, и очередь порций данных, которые необходимо обработать. Далее менеджер анализируя доступность ресурсов запускает в фоне переданную процедуру для каждой порции данных. По завершении передает информацию инициатору.

В нашем случае конфигурация базировалась на типовой конфигурации «1С:Управление нашей фирмой», которая содержит в себе библиотеку стандартных подсистем (БСП). Начиная с версии 3.1.6.137 подсистема базовой функциональности БСП содержит в себе аналогичный механизм запуска в несколько потоков, используя механизмы длительных операций.

Для запуска в несколько потоков необходимо использовать методы: «ВыполнитьФункциюВНесколькоПотоков» и «ВыполнитьПроцедуруВНесколькоПотоков».
Т. к. при выполнении «процедуры в несколько потоков» невозможно получить результат даже через адрес временного хранилища, а в рамках нашей задачи было необходимо получать информацию о результате перепроведения документов, потому мы воспользовались именно «функцией в несколько потоков».
Ответ на вопрос почему «процедура в несколько потоков» не возвращает результат можно получить при осознании описания устройства в документации ИТС. Там сказано, что данный метод внутри себя запускает единую длительную операцию, которая и будет запускать по очереди переданные потоки, а также контролировать их состояние и выполнение. Следовательно, запущенные процессы никак не будут связаны с инициирующим сеансом. Потому их результаты будут видны только сеансу длительной операции.
Что касаемо определения доступных ресурсов, то для этого в БСП была добавлена константа «Количество потоков длительных операций», которая регулирует количество одновременно запускаемых потоков, а по сути тех же фоновых заданий. Рекомендуется устанавливать значение от 4 до 12. Стоит понимать, что реальное распараллеливание достигается за счет количества ядер процессора. Бесконтрольное увеличение данного параметра влечет скорее регресс производительности и может «положить» сервер.

Соответственно, если в очереди будет 5 потоков, а в константе установлено значение 4, то менеджер будет ожидать завершение одного из 4-х потоков, чтобы запустить 5-ый. Такое поведение может привести к увеличению длительности обработки порций. Поэтому рекомендуется изначально учитывать данную настройку при ограничении формируемых порций.

Вызов методов «ВыполнитьФункциюВНесколькоПотоков» и «ВыполнитьПроцедуруВНесколькоПотоков» идентичен. На входе они ожидают:
- Имя экспортного метода, который будет вызываться.
- Параметры выполнения в фоне, которые необходимы для вызова любых длительных операций.
- Набор параметров метода — соответствие, где ключ это идентификатор потока, а значение — массив параметров вызываемой функции (максимум 7 элементов).
Таким образом, для решения задачи запуска перепроведения в нескольких потоков мы воспользовались функцией ВыполнитьФункциюВНесколькоПотоков из БСП. В качестве имени экспортного метода мы передали функцию для обработки порции данных для проведения, а в наборе параметров передавали порции документов необходимые к проведению.
Доработка группового перепроведения
После того как мы определились с ограничениями и механизмом оставалось только взять и закодировать. Однако мы прекрасно понимали, что можем запутаться в столь хитрых правилах организации потоков, их формировании и обхода. Да и не всегда с ходу можно понять, а вообще можно ли разделить на потоки, сколько документов в них будет и т. п. Потому мы решили разработать механизм, позволяющий наглядно визуализировать весь граф потоков с перепроводимыми документами.
В качестве технологии построения графа была выбрана библиотека Vis.js, которая прекрасно справляется с подобной задачей. Про нее подробно мы рассказывали в статье.
Для формирования графа был добавлен специальный параметр запуска, который перед началом выполнения группового перепроведения анализируется, запускает формирование и сохраняет его в виде HTML-файла в указанную папку.


Казалось бы, что может быть сложного просто визуализировать полученный граф. Тем более все исходные данные уже есть, но тут мы еще раз напомнили себе насколько среда разработки отличается от продуктива. Разработчик тестировал на 6 документах, ему был прекрасно виден граф, начальный и конечный узлы.

А вот при запуске даже на 12 тысячах документов был получен огромный клубок ниток из потоков и документов, в котором было трудно увидеть начало и конец.

В первую очередь мы приняли решение разукрасить начальные узлы и узлы ожидания по разным организациям, чтобы появилась хоть какая то возможность идентифицировать разные ветки.

Далее было принято решение группировать документы, которые будут отрабатываться в едином потоке, в общие узлы, чтобы сократить количество выводимой информации. Чтобы идентифицировать узлы, в заголовок узла было выведено количество проводимых документов и вес узлов, а в подсказку спрятаны представления документов.
В результате из непонятного «клубка ниток» мы получили вполне разбираемый граф, который отвечает на все вопросы построения.


Собрав полученные знания и закрепив их визуально на графе давайте рассмотрим итоговую реализацию формированию потоков. Для начала возьмем полный список документов необходимый к перепроведению, с учетом всех пользовательских отборов и отсортированных по дате. Каждая строка в данной таблице будет представлять из себя узел графа перепроведения. Т. к. в таблице могут быть документы, зафиксированные на одну секунду, то для их дальнейшего различия сразу пронумеруем все записи.

Затем свяжем документы в запросе между собой с помощью ключа документа для выстраивания матрицы связей и образовывая дополнительные записи для определения узлов ожидания.

Для определения оптимальных порций данных выполним оценку количества записей по регистру себестоимости.

Остается дополнить таблицу «весом документа», связать документы между собой и отсортировать по дате и ссылке.

По полученной матрице связей документов можно формировать потоки. Так как потоки могут ограничиваться из-за узлов ожидания и максимального веса потоков, то их формирование будет запускаться многоитерационно пока все документы не будут перепроведены.

Полученную очередь передаем в функцию выполнения в нескольких потоках.

Если в результате проведения очереди документов всё провелось без ошибок, то переходим к следующей итерации, а иначе прерываем выполнения перепроведения.

По итогу выполнения всех итераций фиксируем общий результат перепроведения и на этом процесс перепроведения считаем завершенным.

Результаты оптимизации
После реализации механизма распараллеливания проведения документов был выполнен повторный запуск группового перепроведения 20 тысяч документов. В результате из исходных 14 часов, проведение стало выполняться за 5 часов, т. е. удалось сократить время на 65%. Данное время уже входило в технологическое окно, что полностью удовлетворило клиента.
Результат проведения в один поток:

Результат проведения в несколько потоков:

Вспомогательные способы ускорения — восстановление последовательности
Ранее мы уже упоминали, что сокращая количество проводимых документов можно ускорить и общее перепроведение документов. Тогда мы рассматривали сокращение по видам проводимых документов. Однако в ряде типовых решений представлен еще один способ сокращения документов — восстановление последовательности.
Данный механизм предполагает, что в случае если документ проводится задним числом, то начиная от проводимого документа необходимо провести все остальные последовательно. Т. е. не кто-то произвольно решит перепровести последние три дня, а лучше две недели, а то уже забыли какой документ изменяли, а система выявит это автоматически.
Механизм восстановления последовательности можно реализовывать двумя способами: с использованием платформенного объекта «Последовательности» или реализации своего аналога.

Давайте сначала рассмотрим пример использования платформенного механизма. В конфигурации «1С:Бухгалтерия предприятия» (БП) представлен как раз такой.

Объект последовательности не содержит большого количества настроек. На вкладке использования можно уточнить стоит ли перемещать границу автоматически при проведения документа или за перемещение будет отвечать разработчик. Также указывается список документов по которым происходит определение момента проведения. Например, перепровели документ «Авансовый отчет», система фиксирует его в данной последовательности и отрабатывает математику регистрации. Для уточнения математики контроля еще можно уточнить регистры, влияющие на последовательность.

На вкладке «Данные» можно указать измерения. Заполнив данные измерения, при проведении документов, появляется возможность ограничивать выборку проводимых документов по значениям. Например, в БП предлагается уточнять организацию и состояние проведения документа. При проведении двух документов по двум организациям система зафиксирует их организации в измерении и в дальнейшем будет возможность восстанавливать последовательность по каждой организации отдельно.


На уровне СУБД каждый объект последовательности представлен двумя таблицами: «Таблица регистрации» (_Seq<N>) и «Таблица границ последовательности» (_SeqB<N>).
Таблица регистрации содержит в себе записи по каждому записанному документу входящему в состав последовательности дополненный значениями измерений. По своей природе напоминает журнал документов.


Таблица границ последовательности содержит в себе границы последовательности в разрезе измерений, если измерений нет, то будет единственная запись. Записи таблицы границ отражают последний правильно проведенный документ не нарушивший ведение учета.


Момент регистрации границы настраивается в документах и может быть как автоматический при записи, так и ручной по логике разработчика.

Стоит отметить, что использование автоматического перемещения границы может привести к появлению управляемых блокировок, в чем можно легко убедиться. Для этого включим перемещение границы.

Далее настроим лог технологического журнала по событиям: TLOCK, TTIMEOUT и EXCP.
<?xml version="1.0" encoding="UTF-8"?>
<config xmlns="http://v8.1c.ru/v8/tech-log">
<log history="1" location="D:\Work\Project\Логи\6">
<event>
<eq value="TLOCK" property="Name"/>
</event>
<event>
<eq value="EXCP" property="Name"/>
</event>
<event>
<eq value="TTIMEOUT" property="Name"/>
</event>
<property name="all"/>
</log>
</config>Затем в параллельных сеансах проведем документы входящие в последовательность с едиными измерениями последовательности, но с датой меньше, чем текущая граница.
В результате фиксируем ошибку превышения времени ожидания предоставления блокировки.

Если заглянуть в лог технологического журнала, то можно найти TTIMEOUT и от него жертву и виновника, которые пересеклись на пространстве «Seq130.DIMS» устанавливая эксклюзивную блокировку по одинаковым полям «Seq130.DIMS Exclusive Fld140=36:971c74563c285c8711f1133dd9c18d37 Fld143=141:a581ea66d84493574bff0a303c7a57d7».

Если же выключить перемещение границы, то проведение пройдет штатно, т. к. система не будет пробовать устанавливать блокировку по границе.


Так же для восстановления последовательности можно использовать платформенную обработку «Проведение документов», обработки типовых решений, например, в 1С:Бухгалтерии предприятии при закрытии месяца или же написать свою обработку.



Описание метода восстановления последовательности для разработки собственной обработки.
Заключение
Для корректного расчета себестоимости блюд и выпускаемой продукции требуется выполнять перепроведение документов. Данная операция может выполняться весьма долго и даже выходить за технологическое окно.
В данной статье были рассмотрены несколько приёмов ускорения операции перепроведения, которые помогли одному из наших клиентов сократить длительность операции с 14 часов до 5 часов. В частности, был реализован механизм исключения из выборки документов, не влияющих на себестоимость, а также механизм перепроведения в нескольких потоках.
Распараллеливание перепроведения по нескольким потокам является не самой очевидной задачей и требует предварительной подготовки. В предложенной реализации рассматривалось распараллеливание по организациям, но если в компании используется только одна организация, то можно рассмотреть и альтернативные способы разделения, например, по складам.Главное не допускать пересечение пространств, чтобы избегать блокировок на ожидании и взаимоблокировок. Также важным аспектом является правильное построение графовой структуры, которая объективно дает ускорение в случае наличия узлов ожидания.
Отдельно хочется отметить, что возможна ситуация, когда потоки могут быть распределены на все ядра процессора, но обработка будет все равно медленной. Подобный случай возможен при использовании многоядерных процессоров с низкой тактовой частотой. В таких ситуациях необходимо рассматривать альтернативные способы ускорения системы.
От экспертов «1С-Рарус»











Читайте первыми статьи от экспертов «1С‑Рарус»
Вы можете получать оповещения по электронной почте
Или получайте уведомления в телеграм-боте





